基于BP神经网络对城市空气污染数据真实性的判别
2017-07-05陈璐璐陈富媛杨鹏辉黄艳红陈梦倩
陈璐璐,陈富媛,杨鹏辉,黄艳红,陈梦倩
(1.安徽财经大学金融学院,安徽 蚌埠 233030;2.安徽财经大学统计与应用数学学院,安徽 蚌埠 233030)
基于BP神经网络对城市空气污染数据真实性的判别
陈璐璐1,陈富媛2,杨鹏辉2,黄艳红2,陈梦倩2
(1.安徽财经大学金融学院,安徽 蚌埠 233030;2.安徽财经大学统计与应用数学学院,安徽 蚌埠 233030)
目的 针对城市空气污染数据的真实性,收集并处理京津冀、长三角和珠三角地区的空气质量数据,判别数据的真实性,并给出提高空气污染数据真实性的建议。方法 使用因子分析、多元统计等方法构建BP神经网络和多元线性回归模型,利用MATLAB、SPSS和excel等软件,分析空气质量数据的波动性,得到各个城市空气污染物数据的真实性结果。结果 天津、沧州、上海、东莞等城市的空气污染数据较为真实,而保定、邢台、镇江、扬州、舟山,珠海等城市空气污染数据的不真实性严重。结论 应当注重基层环境统计工作,加强基层和媒体对统计数据的关注,完善软件技术设施。
空气质量;BP神经网络;MATLAB
空气质量始终是政府、环境保护部门和人民关注的热点问题。近期频繁爆发的雾霾危机也使得人们日益关注有关监测部门发布的空气质量指标情况。去年“两会”代表和委员纷纷指责中国部分城市伪造空气监测数据,治霾政策的制定受到来自利益相关者的阻力[1]。2016年的两会上,全国政协常委、环境保护部副部长吴晓青表示,很高兴在今年的“十三五”规划草案中看到增加了环境质量的考核指标。自中国提出空气质量数据监测以后,部分地方政府频繁曝出监测数据在改善,而环境质量却在持续恶化的新闻。地方政府大气监测数据真实性的问题逐渐受到人们的关注。
1 相关文献回顾
张锡颖等[2]从空气质量与气候的关系角度研究了这个问题。首先搜集京津冀、长三角、珠三角各个地区的气候和空气质量数据,然后对各个影响因素进行归一化处理,最后得出判别中国地方政府上报监测数据真实性的方法,并且得出数据真实性的不同类型。王妮妮[3]以空气污染类型为切入点,首先搜集上海市国控子站的日监测数据,其次对上海市空气质量进行综合评价,然后利用虹桥机场气象监测站数据对上海市的气象情况进行综合评价,最后得出上海市空气质量状况良好,并且得出了以单点位、单因子为主,多点位、单因子为辅的空气质量异常数据联合筛选体系。
2 数据的获取及假设
数据来源于中国气象局网站[4],为了便于解决问题,提出以下假设:(1)城市空气质量数据的真实性具有连续性,即这个时间段数据真实,则下个时间段数据也真实;(2)多元线性回归中随机误差项ε是一个平均值或期望值为零的随机变量;(3)解释变量的所有观测值,随机误差项的方差都是相同的;(4)忽略除了空气污染物含量外其他影响AQI的因素;(5)不考虑极端天气对空气污染物含量的影响。
3 关于BP神经网络
3.1 研究思路
以京津冀、长三角和珠三角地区代表城市不同时间的PM10、CO、NO2、SO2的4个指标作为输入数据,PM2.5作为输出数据构建BP神经网络模型;接着将该地区其他城市的PM10、CO、NO2、SO24个指标输入到前面构建的BP神经网络模型中,得到这些城市PM2.5的预测数值,通过这些预测PM2.5的数值与代表城市PM2.5真实数据比较,最后筛选出该地区空气质量数据比较真实的城市。
3.2 研究方法
BP神经网络是一种多层前反馈神经网络,一般存在等于或者大于三层神经元。BP神经网络主要包括输入层、中间层和输出层三部分,上、下层之间是全链接,而同一层的相互之间没有链接。标准的BP神经网络算法核心是“负梯度下降原理”,即BP神经网络的误差总是沿着误差降落最迅速的目标进行调整。建立空气质量污染指标数据的BP神经网络模型(图1)。
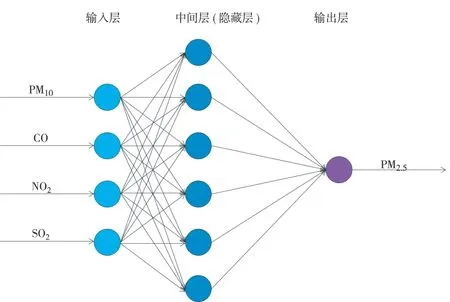
图1 空气质量污染指标数据的BP神经网络模型
3.3 结果分析
(1)分析求解京津冀地区BP神经网络模型
以唐山的空气质量数据为实际依据,将京津冀地区其他城市的空气质量污染指标数据输入到BP神经网络模型中,然后得到该地区不同城市PM2.5的预测数值,最后通过比较预测的PM2.5指标数据和实际的PM2.5指标数据,判断该城市空气质量数据的真实性。以石家庄为例,分析其数据的真实性。将数据输入到MATLAB中,可以得到石家庄空气中PM2.5指标的预测值,并绘出石家庄空气中PM2.5指标的预测值与实际值的变化趋势(图2)。
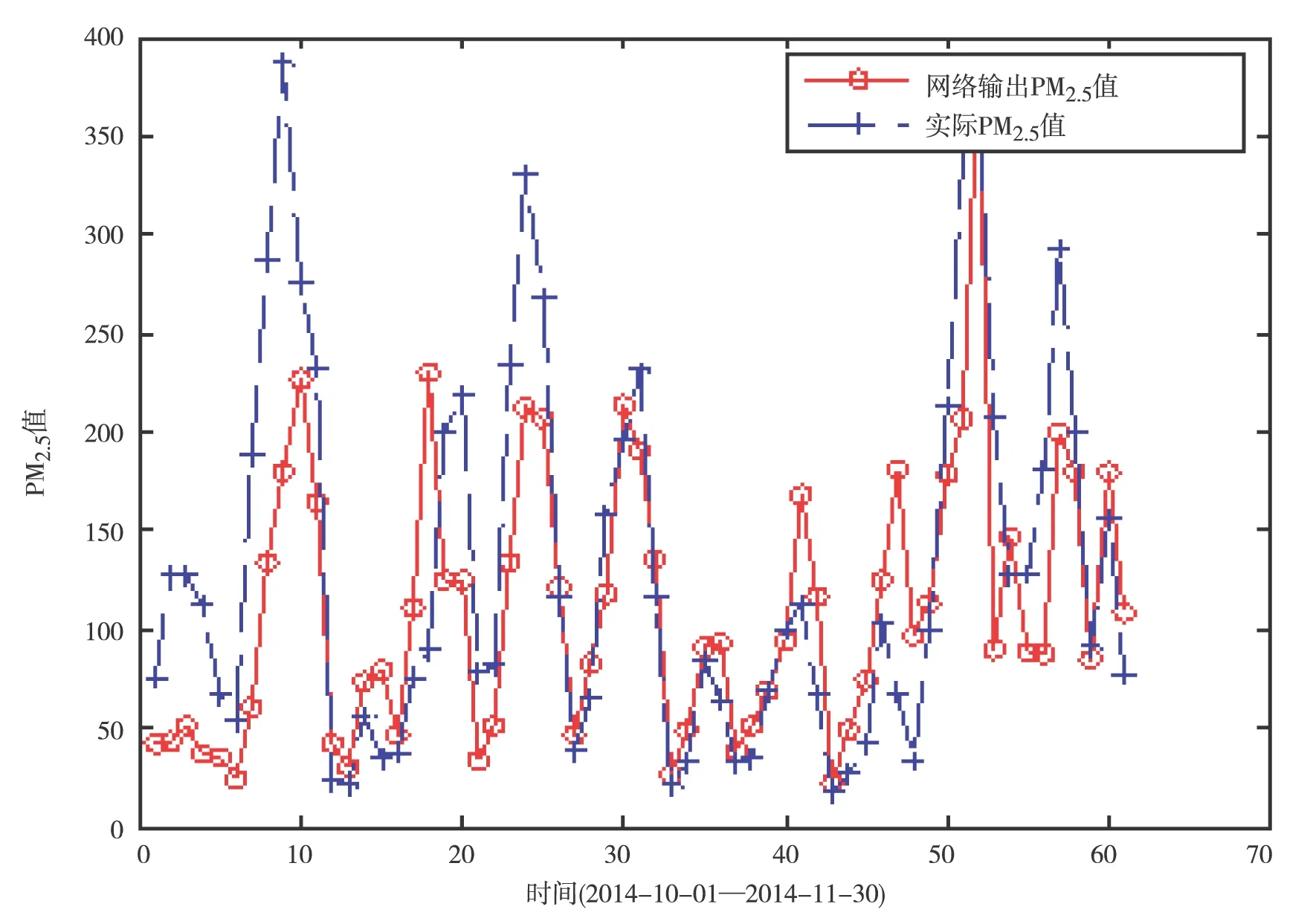
图2 石家庄空气中PM2.5指标预测值与实际值变化趋势的对比图
从图2可以看出,两条曲线的变化趋势大体相同,前面一段时间真实性较低,接着后面一段时间数据真实性提高,再后来真实性又降低了,通过BP神经网络计算所得的石家庄空气质量数据与真实数据之间的误差平方和为264 794。同理将京津冀地区其他城市的空气质量数据输入到已构建好的BP神经网络模型中,得到每个城市空气质量数据与真实数据的误差平方和(表1)。

表1 京津冀地区各个城市误差平方和(error)
从表1可以看出,京津冀地区保定、邢台、张家口的空气质量数据与实际值的误差平方和过大,即空气质量数据明显不真实。北京、石家庄、廊坊、秦皇岛、衡水、邯郸和承德的空气质量数据较为真实。天津和沧州这两个城市的误差平方和较小,因此这两个城市的空气质量数据是真实的。
(2)求解长三角地区BP神经网络模型
以南通的空气质量数据为参照数据,将长三角地区其他城市的空气质量污染指标数据输入到BP神经网络模型中,然后得到该地区不同城市PM2.5的预测数值,最后通过比较预测的PM2.5指标数据和实际的PM2.5指标数据,判断该城市空气质量数据的真实性。以嘉兴为例,分析其数据的真实性。将数据输入到MATLAB中,可以得到长三角地区嘉兴空气中PM2.5指标的预测值,并绘出嘉兴空气中PM2.5指标的预测值与实际值的变化趋势(图3)。
图3可以看出两条曲线的变化趋势大体相同,前面一段时间真实性较高,中间一段时间数据真实性降低,再后来真实性又提高了,通过BP神经网络计算所得的嘉兴空气质量数据与真实数据之间的误差平方和为11 806。同理将长三角地区其他城市的空气质量数据输入到已构建好的BP神经网络模型中,得到每个城市空气质量数据与真实数据的误差平方和(表2)。

图3 嘉兴空气中PM2.5指标预测值与实际值变化趋势的对比图
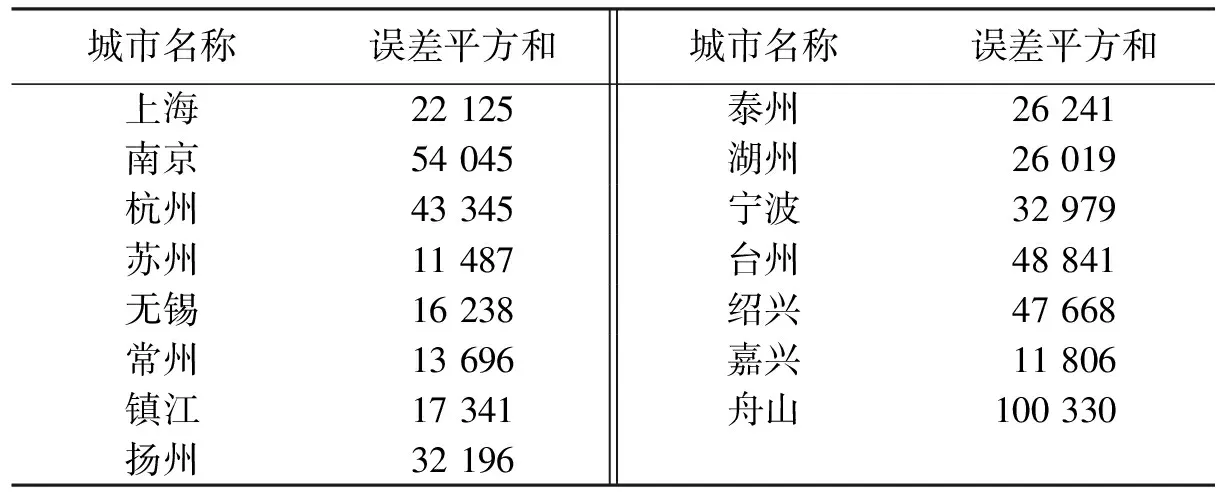
表2 长三角地区各个城市误差平方和(error)
由表2看出,长三角地区舟山的空气质量数据与实际值的误差平方和较大,即空气质量数据明显不真实。上海、南京、杭州、苏州、无锡等城市的空气质量数据与真实值之间的误差平方和较小,即这些地区的空气质量数据可认为是真实的。
(3)分析求解珠三角地区BP神经网络模型

图4 珠海空气中PM2.5指标预测值与实际值变化趋势的对比图
以珠海的空气质量数据为参照数据,将珠三角地区其他城市的空气质量污染指标数据输入到BP神经网络模型中,然后得到该地区不同城市PM2.5的预测数值,最后通过比较预测的PM2.5指标数据和实际的PM2.5指标数据,判断该城市空气质量数据的真实性。以珠海为例,分析其数据的真实性,具体数据输入到MATLAB中,可以得到珠三角地区珠海空气中PM2.5指标的预测值,并绘出珠海空气中PM2.5指标的预测值与实际值得变化趋势(图4)。

表3 珠三角地区各个城市误差平方和(error)
从图4可以看出,两条曲线的变化趋势基本相同,前面一段时间真实性较高,中间一段时间数据真实性降低,再后来真实性又提高了,最后一段时间数据的真实性又降低,通过BP神经网络计算所得的嘉兴空气质量数据与真实数据之间的误差平方和为24 956。同理将珠三角地区其他城市的空气质量数据输入到已构建好的BP神经网络模型中,得到每个城市空气质量数据与真实数据的误差平方和(表3)。
从表3可以看出,珠三角地区深圳、珠海、江门、肇庆的空气质量数据与实际值的误差平方和较大,即空气质量数据较为不真实。惠州、中山、佛门和江门的空气质量数据与真实值之间的误差平方和较小,即这些地区的空气质量数据可认为较为真实。东莞的误差平方最小,即东莞的空气质量数据是真实的。
4 城市空气污染数据的真实性判别
4.1 研究思路
用SPSS进行因子分析,利用污染物之间的相关性减少污染物变量的个数,进行降维处理,然后建立多元线性回归模型,对各个城市的AQI指数进行预测,最后进行误差分析及拟合优度检验,比较确定空气质量数据的真实性。
4.2 研究方法
因子分析是指研究从变量群中提取公共因子的统计技术,可以在许多变量中找出隐藏的、具有代表性的因子,还可以用来检验变量间关系的假设。因子分析是一种十分实用的降低变量维数的方法。因子分析的主要步骤有:①确认待分析的原始变量是否适合作因子分析;②构造因子变量;③利用旋转方法使因子变量具有可解释性;④计算每个样本的因子变量得分。
因子分析模型中,假定每个原始变量由两部分组成:共同因子和唯一因子。共同因子是各个原始变量所共有的因子,解释变量之间的相关关系。唯一因子是每个原始变量所特有的因子,表示该变量不能被共同因子解释的部分。原始变量与因子分析时抽出的共同因子的相关关系用因子负荷表示。
因子分析最常用的理论模式如下:
Zj=aj1F1+aj2F2+aj3F3+…+ajmFm+Uj(j=1,2,3,…,n,n为原始变量总数)
可以用矩阵的形式表示为Z=AF+U。 其中F称为因子, 由于它们出现在每个原始变量的线性表达式中(原始变量可以用Xj表示, 这里模型中实际上是以F线性表示各个原始变量的标准化分数Zj), 因此又称为公共因子。 因子可理解为高维空间中互相垂直的m个坐标轴,A称为因子载荷矩阵,aji(j=1,2,3,…,n,i=1,2,3,…,m)称为因子载荷, 是第j个原始变量在第i个因子上的负荷。 如果把变量Zj看成m维因子空间中的一个向量, 则aji表示Zj在坐标轴Fi上的投影, 相当于多元线性回归模型中的标准化回归系数;U称为特殊因子, 表示原有变量不能被因子解释的部分, 其均值为0, 相当于多元线性回归模型中的残差[6]。 其中, ①Zj为第j个变量的标准化分数; ②Fi(i=1,2,…,m)为共同因素; ③m为所有变量共同因素的数目; ④Uj为变量Zj的唯一因素; ⑤aji为因素负荷量。
4.3 结果分析

表4 因子负荷矩阵
将数据导入SPSS中,得到这5个变量的因子负荷矩阵(表4),将因子负荷矩阵旋转,得到旋转后因子负荷散点图,如图5所示。从因子负荷散点图中可以直观地看出,决定各因子的变量,在散点图中,如果变量对应的点正好落在某坐标轴上,则说明该变量值在该坐标轴对应的因子上有负荷;如果该点落在圆点附近,则说明因子负荷较小;如果该点落在坐标轴顶端,则说明因子负荷较大。由图5可以得出,第一个因子的变量为SO2,第二个因子的变量为PM2.5。
求解出京津冀、长三角、珠三角3个地域空气污染数据真实性较强的3个城市分别为唐山、嘉兴、广州,根据因子分析结果,选取污染物SO2、PM2.5和AQI指数,用Excel筛选出3个城市从2014年10月1日到2014年11月30日的满足条件的数据,建立多元线性回归模型。对京津冀、长三角、珠三角3个地域空气污染数据真实性较强的3个城市唐山、嘉兴、广州的数据用MATLAB进行多元线性回归,得到3个城市的AQI与PM2.5、SO2的多元线性回归方程:
y1=25.0182+1.1280x1-0.0031x2
y2=18.3732+1.1455x1+0.0035x2
y3=10.3960+1.2133x1+0.1371x2

图5 旋转后的因子负荷散点图


图6 三个区域各个城市误差平方和
由图6可以看出,京津冀地区的误差平方和最大,故北方地区的空气污染物数据的真实性较差,长三角地区和珠三角地区误差相对差别不大,因此南方这两个地区的空气污染物数据真实性较好。
从图6可以看出,京津冀地区的保定、邢台两个城市的数据不真实性较本地区严重,长三角地区的镇江、扬州、舟山3个城市的数据较本地区不真实性严重,珠三角地区珠海的数据较本地区不真实性严重。
5 建 议
根据城市空气污染数据的真实性判别分析结果,针对空气污染数据真实性问题,提出以下建议。
1)重视基层环境统计工作,强化人员配置,提高统计人员的思想意识,把统计工作放在首要位置,认真对待,耐心负责,同时设置专职统计的各项岗位,挑选业务能力强、掌握统计学相关知识的专业人才担任统计相关工作,加强对统计人员专业知识和职业道德的教育,努力提高基层统计人员的综合素质和能力。
2)加强基层和媒体对统计数据的监测,随着社会的发展和人民群众监督意识的加强,公众参与统计工作的诉求也越来越强,对加大环境信息公开的范围和力度都有所上升。政府通过鼓励各大门户网站或者地方媒体对各级政府公布的统计数据进行监督检验,来提高统计数据的真实性。要加强基层环保监测能力,使统计数据能够反映真实的情况,建立统计各部门的沟通机制,有序高效的将统计数据分配给各部门,每个部门互相监督,避免“越位”现象发生。
3)完善软件技术设施,定期培训和检测,要进一步完善软件建设,加强统计人员统计软件技术的培训和学习教育,并定期对软件的正确性进行检测和维修,使统计人员工作效率得以提高,统计的真实性得以加强。
[1]百度百科.空气污染数据判别[EB/OL].[2016-10-02].http://www.docin.com/p-1549177813.html.
[2]张锡颖,曲红伟.城市空气污染数据的真实性判别及分析研究[J].科技经济导刊,2016(11):123-124.
[3]王妮妮.上海市空气质量监测数据的规律研究及在数据审核中的应用[D].上海:东华大学,2010.
[4]司守奎,孙玺菁.数学建模算法与应用[M].北京:国防工业出版社,2015.
[5]姜启源,谢金星,叶俊.数学模型[M].北京:高等教育出版社,2015.
[6]杨桂元,朱家明.数学建模竞赛优秀论文评析[M].合肥:中国科学技术大学出版社,2014:1-70.
[7]卓金武.MATLAB在数学建模中的应用[M].北京:北京航空航天大学出版社,2014:20-54.
[8]赵家刚,李世友.多元线性回归模型的研究与应用[J].科技信息,2009(16):61-62.
[9]王丰效,周伟萍.灰色多元线性回归方法的改进及应用[J].重庆理工大学学报,2012,26(08):113-116.
[10]苏变萍,曹艳平.基于灰色系统理论的多元线性回归分析[J].数学的实践与认识,2006,36(08):219-222.
[11]马健,盛魁.基于遗传BP神经网络组合模型的中药销售预测研究[J].河北北方学院(自然科学版),2013,29(04):15-20.
[12]潘婷,杨鹏辉,张依一,等.京津冀地区空气污染的分析与评价[J].河北北方学院(自然科学版),2016,32(07):31-37.
[13]刘权,杨鹏辉,刘润茜,等.蚌埠市空气中PM2.5形成与扩散的研究[J].河北北方学院(自然科学版),2016,32(07):35-42.
[责任编辑:王荣荣 英文编辑:刘彦哲]
Discrimination of Authenticity of Urban Air Pollution Data Based on BP Neural Network
CHEN Lu-lu1,CHEN Fu-yuan2,YANG Peng-hui2,HUANG Yan-hong2,CHEN Meng-qian2
(1.School of Finance,Anhui University of Finance and Economics,Bengbu,Anhui 233030,China; 2.School of Statistics and Applied mathematics,Bengbu,Anhui 233030,China)
Objective For the truthfulness of urban air pollution data collected and processed in Beijing-Tianjin-Hebei,Yangtze river delta and Pearl river delta,the authenticity of the data was judged,and some suggestions were given for the improvement of air pollution data authenticity.Method The factor analysis and multivariate statistical methods were used to construct the BP neural network and multivariate linear regression model.MATLAB,SPSS and EXCEL softwares were used to analyze the volatility of air quality data,obtaining the authenticity of the urban air pollution data results.Results The data of Tianjin,Cangzhou,Shanghai,Dongguan and other cities air pollution were real,but the air pollution data of Baoding,Xingtai,Zhenjiang,Yangzhou,Zhoushan,Zhuhai and other cities had serious inauthenticity.Conclusion Attention should be paid to the basic environment statistical work,the grass-roots and the media focus on statistics,and software technology facilities should be improved.
air quality;the BP neural network;MATLAB
国家自然科学基金项目:“3-流猜想,Fulkerson-覆盖及相关问题”(11601001)
陈璐璐(1996-),女,安徽安庆人,安徽财经大学金融学院在读学生,研究方向:金融学。
杨鹏辉(1981-),女,安徽财经大学统计与应用学院讲师,硕士,研究方向:应用数学与数学建模。
Q 948.116
A
10.3969/j.issn.1673-1492.2017.07.008
来稿日期:2016-11-03
