基于M ongoDB的W eb信息采集系统应用研究
2017-07-01孙美卫
孙美卫
(泉州经贸职业技术学院,福建泉州362000)
基于M ongoDB的W eb信息采集系统应用研究
孙美卫
(泉州经贸职业技术学院,福建泉州362000)
在降低成本、效率加大的情况下如何处理海量数据,是目前急需解决的重要问题。文章首先分析如何将Web日志存储到MongDB中,然后将其直接内置到MapReduce,将分析结果存储为文件以供业务人员查询分析,最后对日志分析系统进行性能测试。测试结果表明:在挖掘Web日志数据的情况下,能将数据中的主要访问模式进行系统化更新,从而为网站的结构模式采集提供有效信息。
MongoDB;Web信息采集系统;日志分析
NoSQL是非关系型数据库的总称,产生的背景是为了适应飞速增长的互联网时代,让其数据存储信息能满足当前的数据信息需求。[1]由于该数据库的特点是数据技术的存储量较大,容易扩展,能在大量的数据使用中保持高性能的数据读写功能,灵活的使用不同的数据模式,并能在很多应用场景中得到较好应用,甚至能逐步展露头角。MongoDB是NoSQL数据库的代表,它能将数据库模型进行拆分,然后重新打乱以后将所有的存储信息都使用在不同的机器上面。自动分片机制的产生能让分布扩展得以实现,也能将数据存储在不同的集合、文档中。MongoDB可适用在多个场合中,由于自身拥有良好的拓展性能,可以对尺寸较大的文件进行保存,且存储价值不高,因此能够将更多的海量数据信息存储技术运用到互联网云计算发展领域。上述这些特点让MongoDB在Web的日志分析领域中发展得游刃有余。
1 基于MongoDB的日志分析方案的确定
互联网技术的产生在很多方面开始得到广泛应用,随之对Web的日志分析需求也出现。电子商务的发展开始受到人们的重视,相应的分析软件也就应运而生。传统的数据分析软件分别为:利用传统的日志分析软件和日志分析工具进行分析、利用数据库进行分析、利用数据关系库进行分析。我们知道传统的日志分析软件在利用日志为工具数据库的时候需要使用大规模的数据,在频繁高效的数据库建立期间,不但要有能维护日志文件,也要有能分类不同的数据库类型的功能,通过深入挖掘数据信息,使运行期间有更大的硬件平台支持其运行。分析时,若只能简单地进行日志分析,就会有大材小用之嫌;使用关系型数据库在存储上增大其扩展型和数据分析的功能,能提高数据的准确性,但也会在很多方面出现局限性,比如在庞大数据库查询时会倍感吃力。综上所述,Web服务器的瓶颈出现在日志信息异常庞大时,由于网络普及速度加快使海量信息快速增长,所以低成本且高效的处理数据库信息系统是当前研究的重要议题,如何能在降低成本、效率加大的情况下处理海量数据,是目前我们急需解决的重要问题。
根据对上述问题的探寻,本文主要是在MongoDB的Web日志分析方案使用前提下,探究有关MongoDB的高性能存储方式,通过良好的性能拓展,让Web日志分析领域的应用效果达到更佳。本系统主要是使用了线和高速缓存队伍,这可以在处理不同的并发时间时让不同类型的日志得到较好处理,应用MongoDB数据库处理所有的数据,并在数据系统中保存处理结果,系统主要功能如下:
1)对不同时间段和不同类型的日志文件进行处理
分析和处理日志之前,先要对日志进行预处理,结合文件对所需日志类型进行针对性的配置,并借助IOFileFilte来过滤日志文件的种类,处理满足日期条件的日志,然后处理与日志时间一致的文件,从而使程序扩展性、灵活性均得到有效的改善。
2)高并发的处理日志数据
日志的文件量十分巨大,能借助于Iava的线程池让缓存队伍能在高并发阶段处理大量的数据文件。比如,之前需要花费几个小时才能处理好的日志和数据,在使用该数据处理模式以后能在短时间内奏效,节约大量的数据处理时间,提高系统的运行速度。
3)高速缓存队列存储数据
经过处理的数据文件不能马上在数据库内进行保存,由于形成数据的时间各不相同,具有实时性的特点,所以直接在数据库内保存全部数据,并进行多频次读取数据,进而使数据库整体性能的发挥受到影响,所以,进行存储数据的数据库需要有高速缓存的能力,让数据能在每间隔几秒以后,又一次自动数据存储输入,从而提高数据性能。
4)可存储大数据集
大量GridFS文件系统颁布于MongoDB中,这些文件系统主要通过MongoDB的分布式存储机制借助MongoDB进行文件的处理和存储,使用这种数据库存储模式的关键是能让数据库存储具有文档存储与系统存储的双重优势,这就能在不担心容量扩展的情况下让数据库的存储量日益增加,具有大数据集的存储能力。
5)高效的日志数据分析
把所有已经处理过的数据存储到MongoDB中,再对MongoDB进行数据分析。MongoDB主要为Map Reduce提供编程模型,这能让整个模型的使用更加的灵活,也能与分片进行结合,使数据分析的效率大大提高。总之,数据处理要借助于分布式的数据库处理模式,从而能分片进行数据分析和处理,增大数据处理速度。
2 系统总体设计
本文主要是以网上购物商城的日志分析系统为主要概述对象,通过扩充商城中的日志数据,可以让数据的数量级得到大的扩充,由于大量的数据汇集,所以为日志分析带来难度。使用关系网数据库系统显然无法达到存储庞大数据的规定要求,所以本研究基于分布式关系,对数据库的处理和存储进行研究,使用MongoDB数据库能将这个问题更好的实现和解决。系统设计实现时,系统能被划分为数据采集处理系统、处理后的日志提取分析、按照业务提取结果的存储,如图1所示。

图1 网上购物商城的日志分析系统图
2.1 日志数据采集存储处理系统设计
日志的子系统采集主要的工作内容是将制定目录下的日志文件和后续的系统文件全部在系统中生成可用数据,以便于日后的业务查询和使用。日志采集系统若详细划分能直接被划分为数据选取和数据存储这两个功能项。
原始数据在受到某些因素影响的前提下会增大日志的处理复杂性,所以日志分析活动开设之前,选取数据十分必要,可以在数据选取期间消除部分不完整的数据分析环节,系统中的设计标准是日志中的每个字段都要含有有效的信息。若某行中的某个日志有缺失的情况,如请求URL或者IP地址不变时,就要直接跳过该数据,不要直接处理数据,直接将这部分数据过滤掉。[2]若该数据还有保留没有信息丢失,直接将不完整的数据过滤掉,然后对其进行数据信息的记录,这十分必要;若改行数据没有丢失,就要直接开展划分操作,关键依据为数据的具体格式,提取各域的数据,并在数据文档内进行保存处理。
海量数据是日志文件的一大显著特征,存在无效、有效文件均混杂在日志数据内的问题,为数据分析、分类带来极大的困难。结合上述特点能获悉,该系统能高效提取数据信息。故此设计出的日志采集子系统框架图如图2所示。
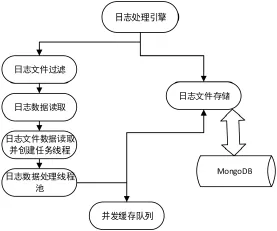
图2 日志采集子系统框架图
结合上述系统图能获悉,子系统的入口是日志处理引擎,每个功能模块都要由此进入到系统中。[3]此模块可以对所采集到的子系统进行很好的控制。在使用系统过程中可以将日志引擎进行直接引入,通过启动日志信息读取方式使信息存储效果更佳,通过利用读取日志的方式实现对日志并发性读取,通过直接性的方式处理缓存队伍下的全部日志信息,并在Mongo DB数据库系统内进行保存。
借助日志处理引擎,可以使文件读取性能得到大大提升,增强子模块初始化处理效果,改善了数据库连接效果,还提高了缓存队伍的初始化效率。
2.2 处理后的日志提取分析子系统设计
针对日志采集子系统数据,能够借助日志合并分析子系统进行深层次的处理操作,对日志中间环节进行研究,可以发现系统运用MapReduce工具对中间数据开展分析。[4]该分析方式能将日志的基本情况输入其中,然后通过MongoDB的MapReduce工具对中间数据进行细致分析。分析时需要清晰了解到日志的具体输入状况,然后在提供对应的数据分析情况下,抽取数据中的某个有价值的字段,对相应的特征值进行映射建立,对当前有效的信息和对应字段的有效数值进行针对性地获取进而进行计算。
处理日志中的数据内容,先要获取能提供数据支持的必要子数据内容,然后对数据内容进行映射和化简,找到其中需要被清理的数据字段,并将其中的不合理部分清洗掉,然后根据日志的特征借助于MapReduce进行分布式计算,利用数据访问情况,借助映射关系对数据进行二次提取,向业务提交有关数据,发送给业务提取系统。
设计中间聚合系统的关键点是要让各类业务的子系统间形成独立的系统处理模式,这样能让系统真正的做到化繁为简,有助于删除冗余的信息内容。[5]业务分析只有在专注于子系统间的独立系统分析和变更,通过扩展业务模块内容,让不同的子系统进行合并,且不修改合并后的业务需求,这样做是为提升系统的扩展性,降低模块之间的祸合度。
2.3 按业务提取结果存储设计
本系统模块中最重要的设计是提取子系统设计,这是整个业务的设计创新点所在,能根据不同的网站类别情况对日志进行处理和分析。分析后的系统能在数据简单操作的情况下进行系统生成,对全部简化分层子系统进行操作处理,提高简化信息的有效性,以小时、天或周为单位,对时间聚合体进行生成处理,按照具体情况查找不同的范围,分析和整理访问数据的类别。
二次开发子系统,结合业务实际需要,开展过滤、查询操作,基于MapReduce及Group两大模板,对应生产天、周、月的数据统计模式。[6]本业务的具体信息统计可以有如下几方面内容:访问量的数据统计、统计网站的数据和被访问人数统计、热门产品的统计、不同商品的品类统计等。
3 日志分析系统的性能测试
可以将日志分析系统运用到测试环节,系统性能测试的关键点为系统效率及存储效率测试。同常规方法进行对比能获悉,日志的高效性在这里发挥着极为重要的影响。
日志的数据量可以是l0MB、50MB、1G,对应日志使用时消耗的时间就可以被看成是1天、5天、20天。
若日志的数据量各不相同,就要借助MongoDB来保存数据,进而得知保存数据时间与耗费时间存在正比关系。[7]如果日志量相对固定,不存在改变,那么测试数据的时候就可以使用MongoDB和Shell脚本。
执行对应的数据采集系统以后,能生产预期的数据库文件,然后将原有的数据直接纳入到按小时划分的数据库之内,使用数据库的数据文件对其中的步骤进行清洗,让数据化繁为简,成功地生成中间的结果。统计时以PV为例展示中间的结果文件。具体内容如后面图3所示。
结果文档由分组和聚合结合生成,采用每小时PV统计为案例开展讲解,所生成结果如图4所示。
功能测试能得到如下的结果:第一,日志文件的数据提取能与存储一致,达到准确性;第二,日志的全部分析结果都满足精准度,是准确的,结果正常;第三,现实的数据全部内容正常;第四,PV统计中每个月与该月中每天的具体统计结果能保有一致,而UV可以在多个用户存在中的某个月份中进行多次访问,将“月”看成单位进行结果统计,这相较于“天”被看成结果的统计单位而言,整体的结果之和会小很多。[8]总之,该系统可以实现对日志数据的存储以及分析,并通过采用预期的目标统计方式实现计算结果的精准。
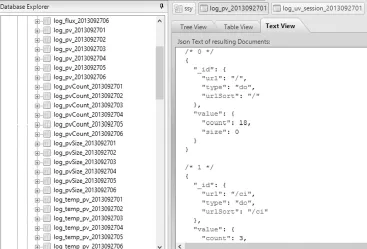
图3 分析中间结果文档内容图

图4 最终统计结果文档内容图
根据以上测试,日志量不同,数据的量正在逐渐增大,所以MongoDB的数据处理优势开始变得日渐明显。受到日志量不同的影响,运用MongoDB和Shell脚本分析数据,了解到什么情况下数据量小,两者之间的计算相差率没有太大的变化,MongoDB效果也较优;日志量增大的情况下,两者之间由于差距明显,MongoDB的执行效率要远远高于Shell脚本。[9]
在Web日志中不仅可以对用户的浏览行为进行综合分析,还可以使Web站点的结构得以改善,进而达到提升站点服务的质量,在这些方面能让具体的日志分析效果达到最佳状况。当前较为热门的电子商务网站是网络和贸易金融结合在一起的产物,所以对商务网站中的日志信息进行有效探究,能够使商务网站开发效率得到改善,同时也能够拥有与时代发展相适应的竞争优势。
[1]邹骅,刘沈.基于Web的服装销售管理系统研究[J].湖南邮电职业技术学院学报,2016(4):50-52.
[2]张恩,张广弟,兰磊.基于MongoDB的海量空间数据存储和并行[J].地理空间信息,2014(1):46-48.
[3]朱亚兴,余爱民,王夷.基于Redis+MySQL+MongoDB存储架构应用[J].微型机与应用,2014(13):3-5.
[4]梁海.MongoDB数据库中Sharding技术应用研究[J].计算机技术与发展,2014(7):60-62.
[5]雷德龙,郭殿升,陈崇成,巫建伟,吴小竹.基于MongoDB的矢量空间数据云存储与处理系统[J].地球信息科学学报,2014 (4):507-516.
[6]陈文艺,闫洒洒,宋亚红.基于MongoDB的物联网开放平台数据存储设计[J].西安邮电大学学报,2016(2):78-82.
[7]王光磊.MongoDB数据库的应用研究和方案优化[J].中国科技信息,2011(20):93-94.
[8]张文盛,郑汉华.基于MongoDB构建高性能网站技术研究[J].吉林师范大学学报(自然科学版),2013(1):123-127.
[9]王振辉,王振铎.MongoDB中数据分页优化技术[J].计算机系统应用,2015(6):243-246.
Application research ofWeb information collection system based on M ongoDB
SUNMei-wei
(Quanzhou CollegeofEconomicsand Business,Quanzhou,Fujian,China362000)
How to dealwithmassive amounts ofdata isan importantproblem thatneeds to be solved urgently under the condition of reducing costand increasing efficiency.First,the paper analyzes theways to storeWeb logs intoMongDB,and then to build it directly into theMapReduce.Theanalysis resultsare stored as files forquery and analysis.In theend,the performanceof the loganalysissystem is tested.The results show that in the case ofminingWeb log data,themain access patterns in the data can be updated systematically, and then itprovideseffective information for the structuremodeacquisition of thewebsite.
MongoDB;Web information acquisition system;loganalysis
10.3969/j.issn.2095-7661.2017.02.010】
TP311.52
A
2095-7661(2017)02-0035-04
2017-04-25
孙美卫(1975-),女,福建泉州人,泉州经贸职业技术学院讲师,硕士,研究方向:软件工程、C#应用开发、数据库技术。
