中文微博舆情分类中一种改进的特征选择方法
2017-06-27林伟
林 伟
(福建警察学院侦查系, 福建福州 350007)
中文微博舆情分类中一种改进的特征选择方法
林 伟
(福建警察学院侦查系, 福建福州 350007)
通过微博情感分析掌握网络舆情动态是网络数据挖掘的研究热点,特征选择是基于内容的微博舆情分类的重要环节。为有效提取微博数据的特征,分析CHI特征选择算法应用在微博舆情分类中的特点及不足,给出一种改进的特征评估函数,并进一步用基于蚁群聚类的方法消除微博特征间的冗余。实验结果表明,改进的算法能够有效提高微博舆情分类的效能。
中文微博; 微博舆情; 特征选择; 蚁群聚类
0 引言
随着互联网技术的快速发展,人们对现实生活中突发事件的关注度不断提高,网民通过网络发表情感鲜明的言论并相互影响渗透。网络舆情是指网民在网络虚拟社会空间领域通过网络语言或其他方式,围绕当前社会的热点或普遍关注的话题所表达情感、态度和意见的集合[1]。而微博做为网民主要的社交平台之一,具有自主性、即时性、互动性等特点深受网民青睐。截至2016年6月,根据中国互联网络信息中心发布的第38次《中国互联网络发展状况统计报告》显示,我国微博用户规模2.42亿,同比增长18.6%,在网民中的渗透率达34%,同比增长3.4个百分点。微博日活跃用户增至1.05亿,人均月使用次数达到了52次。微博在追踪热点、发表热点评论、关注兴趣话题等方面都是用户的首选平台[2]。为此,通过机器学习算法对微博进行舆情分类,掌握网络舆情动态,对微博上带有恶意、煽动及攻击性言论及时监控是网络数据挖掘的研究热点[3]。
特征选择是基于数据挖掘的微博舆情分类重要环节,常用的特征选择算法一般采用某种特征评估函数来计算特征与类的关联度。本文分析特征选择评估函数CHI在微博舆情分类中的特点及不足,给出一种改进的特征评估函数。然而评估函数只度量了特征与类的关系,并没有考虑特征之间的关系,在实践中发现,冗余特征同样对微博舆情分类产生负面的影响。为此,进一步用基于蚁群聚类的方法消除微博特征间的冗余,以便更有效地提取微博训练样本集的特征。
1 特征选择分析及改进
1.1 微博预处理
微博是非结构化的字符文本,计算机无法直接计算,需用向量空间模型转化为可处理的数据向量模式。一条微博(micro-blog)采用切词分词算法预处理后,用向量空间模型描述为:m=
1.2 特征选择
基于内容的微博舆情分类构成微博的词汇向量维数往往相当大,过大的向量维数不但会增加计算量,还会影响舆情分类的准确率,从原始的特征集合中按照一定的准则选出对分类贡献最大的N个特征,即特征选择。在文本分类领域中常用的特征选择方法有文档频率(DF)、信息增益(IG)、互信息(MI)、χ2统计(CHI)等。文献[5]对这种常见文档分类中的特征选择算法进行了详细比较,文献[6]对IG和CHI进行了改进,提出一种集合CHI和IG的特征选择方法,下面分析CHI在微博舆情分类中存在的不足。
χ2统计就是计算特征词t与类别的相关程度,如果一个特征词t的χ2统计值越大,就表明该特征词对分类的贡献越大。如有N篇微博,情感类别分为“正面”与“负面”,假设有特征词“坑爹”,其在微博样本集中的出现情况如表1所示:

表1 特征词“坑爹”在微博训练集中的分布数
那么,计算特征词“坑爹”(t)与类别“负面”(ci)的CHI值为:

(1)
χ2统计的缺点在于:只统计了微博特征词的文档频率,而忽略了微博特征词的词频。如假设有100篇微博,特征词“坑爹”在99篇中都出现了10次以上,而特征词“讨厌”在100篇中都只各出现了一次,用χ2统计进行特征选择时很有可能因为特征词“坑爹”的计算值较小被筛掉,而保留特征词“讨厌”,这显然有失科学。在本研究中采用词频的方法对这种情况进行修正。
如训练微博样本类别为ci,ci中的微博样本集表示为Mi=
(2)
然而,由于微博表达的口语化及随意性,一些分布高度不均匀的特征词,如“748”(音译词“去死吧”)虽可能在“负面”情感类别的微博样本中只少数出现,但其所表达的情感倾向明确,理应为“负面”情感类别的候选特征。基于χ2统计的特征选择可能会因出现次数太少而被筛选掉,在本研究中用互信息量对分类贡献大的特征词给予权重修正。
在特征选择中,互信息用来表示特征与类别的关联程度,若特征“748”(t)在“负面”情感类别微博中的出现在概率高,而在“正面”情感类别微博中的出现概率低,那么该特征将获得较高的互信息,计算公式为[7]:
MI(ti,cj)=H(ti)-H(ti|cj)
(3)
其中,

(4)

(5)
综合以上分析新的χ2统计计算公式为:
NCHI=χ2(t,ci)×MI(t,ci)×γ
(6)
2 特征蚁群聚类
因这种评估函数在一定程度上只度量了特征和类之间的关系,忽略了特征之间依赖的关系,本研究进一步用基于蚁群聚类(Ant Algorithm Custering)方法消除特征间冗余。
聚类就是通过一定的算法按数据之间的相似度对数据进行归类,使得数据类内具有较高的相似性,而类间具有较大程度的差异性。蚁群算法是一种源于大自然的仿生类算法,由意大利学者Dorigo最早提出,主要是通过模仿蚂蚁群体之间的信息传递而达到在图中寻找优化路径的随机率型算法,是一种模拟进化算法[8]。蚁群聚类的基本思想是:将待聚类的物体随机分散在一个二维网格上,在空间内虚拟蚂蚁以随机方式移动,当蚂蚁遇到一个待聚类物体时,将物体拾起并继续随机移动,若运动路径附近的物体与背负的物体相似时,将其放在该位置,然后继续移动,最终堆积而成的大堆为聚类结果[8-9]。应用到微博特征聚类基本步骤如下:
(1)初始化相关参数(蚂蚁个数、最大迭代次数、参数kp、kd、α)
(2)将特征随机分布在网格上,每一个网格只容纳一个特征。同时将一定数量的蚂蚁也分配到网格上,蚂蚁初始状态为空载。
(3)计算群落相似性:计算特征对象ti与周围特征对象之间的相似度f(ti),计算如下:

(7)
其中α表示群落的相似系数,反应了聚类簇的数量以及算法的收敛速度,s表示蚂蚁邻居周边的半径,d(ti,tj)表示两个特征的相关性,其计算公式为[10]:

(8)
(4)计算拾起或放下。计算拾起:如果一只蚂蚁在某一时刻的状态为空载且在r位置上有特征对象ti根据公式(9)计算拾起特征对象的概率。

(9)
计算放下:如果一只蚂蚁在某一时刻负载有特征对象ti且r位置上无特征对象,根据
公式(10)计算放下特征对象的概率。

(10)
(5)收敛:如果算法达到最大迭代次数,算法结束,相似的或相关的特征会聚集在一起。
3 实验分析
3.1 实验数据
实验数据集来源分别为新浪开放平台公开的API抓取的中文微博样本集[7]和我们自己收集的部分私人微博,通过微博样本的人工标注,实验数据的样本结构如表2所示。实验结果采取10次交叉验证方法,结果取平均值。从正面微博和负面微博中各取300条作为测试样本,其余的作为训练样本。
3.2 评价指标
为了有效评价微博情感分类性能的好坏,我们选取常用F-SCORE作为性能评测指标 ,计算公式为:
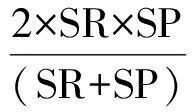
(11)



表2 微博样本结构
3.3 分类模型
用K最邻近算法(K Nearest Neighbor,KNN)为微博舆情分类的分类器。计算待分类微博Mj与微博训练集所有样本Mi的情感相似度,用向量夹角余弦公式表示:

(12)
微博舆情分类的任务就是把待分类微博划分到情感倾向隶属度最大的类别。
3.4 实验流程
实验中切词分词工具选用中科院NLPIR汉语分词系统(2013版),开发平台为Visual Stdio.net 2015,用C++语言在Windows环境下实现,实验流程如图1所示:

图1 微博舆情分类流程
3.5 实验结果分析
3.5.1 NCHI与CHI特征选择比较分析
按照图1所示的实验流程将实验分为两个阶段。(1)训练阶段:首先用中科院NLPIR汉语分词系统(2013版)对训练微博样本集分别进行去停用词、切词分词等预处理工作得出微博的原始特征空间。然后从原始特征空间中采用传统的CHI算法、加入词频及互信息的CHI算法(NCHI)分别选择最优的N个特征子集构成特征向量。(2)测试阶段:对训练微博样本集进行预处理后,用特征子集构成特征向量空间模型并采用KNN算法对测试微博样本集进行分类比较实验。在不同特征数下的F值结果如表3所示,从表3可以看出,特征维数从500每次递增500至特征数达3 500,在同样的的特征维数下,NCHI相比CHI的F值各有2个百分点左右的提升。当特征维数为2 500时,NCHI的F值达到峰值85.55。实验结果表明:(1)NCHI因针对微博的特点对CHI进行了修正,在相同的特征维数下,微博情感分类效果得到提高。(2)当特征维数达到一定数量时,不同的特征选择算法在某一特征数F值会达到峰值,说明增加特征维数不仅会增加分类计算的复杂性,还会因为噪声特征项的增加影响分类效果。

表3 NCHI与CHI特征选择F值比较
3.5.2 经蚁群聚类NCHI-AAC与NCHI比较分析
实验2按实验1基本步骤重复。在训练阶段用NCHI算法进行特征选择,筛选出原始特征空间的特征子集。由实验1得出,特征数为2 500时NCHI的F值达到峰值,因此我们取特征数为2 500,为消除特征子集中特征可能存在的冗余,我们进一步用文中的蚁群聚类算法对特征子集空间进行特征聚类,实验结果如表4所示。从表4可以看出,经NCHI特征选择的特征子集空间经蚁群聚类特征维数从2 500约简至1 975,虽然特征维数减少,但准确率和召回率确得到不同程度的提高,证实了冗余特征的存在及NCHI-AAC算法的有效性。

表4 NCHI-AAC与NCHI准确率、召回率比较
4 结语
采用机器学习算法对微博的情感性进行分类,是微博舆情分类的有效方法,特征选择是基于内容的微博舆情分类的重要环节。本文分析χ2统计应用在微博舆情分类中存在的不足,用词频和互信息的方法对其进行了修正,给出一种改进的特征评价函数。在此基础之上进一步采用蚁群聚类消除特征之间的冗余。实验结果表明,新的评价函数和经蚁群聚类算法特征选择算法可以有效地改善特征子集的质量,提高微博舆情分类的效果。
[1] 曾润喜,陈强,赵峰.网络舆情在服务型政府建设中的影响与作用[J].图书情报工作,2010(13):115-119.
[2] CNNIC. 中国互联网发展状况统计报告[EB/OL].(2016-10-12)[2017-03-25].http:∥www.idcps.com/news/20161012/92421.html.
[3] 单月光.基于微博的网络舆情关键技术的研究与实现[D].成都:电子科技大学,2013.
[4] 林伟.基于多特征提取的中文微博舆情分类研究[J].中国人民公安大学学报,2016(4):53-56.
[5] YANG Y, PEDERSEN J O. A comparative study on feature selection in text categorization[C]∥Proceeding of the 14th International Conference on Machine Learning, 1997:412-420.
[6] 王光,邱云飞,史庆伟.集合CHI与IG的特征选择方法[J].计算机应用研究,2012(7):2454-2456.
[7] 成卫青,唐旋. 一种基于改进互信息和信息熵的文本特征选择方法[J].南京邮电大学学报,2013(10):63.
[8] 张赛楠.蚁群文本聚类算法的研究与应用[D].长春:吉林大学,2013.
[9] 郑方.蚁群文本聚类算法的研究与应用[D].西安:西安电子科技大学,2013.
[10] 王连喜,蒋盛益.一种基于特征聚类的特征选择方法[J].计算机应用研究,2015(5):1305-1308.
[11] 张志琳,宗成庆.基于多样化特征的中文微博情感分类方法研究[J].中文信息学报,2015(7):134-143.
(责任编辑 于瑞华)
福建省教育厅基金项目(JAT160561);2017年福建省高校杰出青年科研人才培育计划资助项目。
林 伟(1983—),男,福建人,硕士,讲师。研究方向为网络安全、数据挖掘、信息化侦查。
D035.3
