抑制背景噪声的LDA子话题挖掘算法*
2017-06-21李静远丘志杰刘悦程学旗任彦
李静远 丘志杰 刘悦 程学旗 任彦
(1. 中国科学院 计算技术研究所∥中国科学院 网络数据科学与技术重点实验室,北京 100190;2. 国家计算机网络应急技术处理协调中心,北京 100029)
抑制背景噪声的LDA子话题挖掘算法*
李静远1丘志杰1刘悦1程学旗1任彦2
(1. 中国科学院 计算技术研究所∥中国科学院 网络数据科学与技术重点实验室,北京 100190;2. 国家计算机网络应急技术处理协调中心,北京 100029)
专题文章集合是一些拥有相似背景知识的文章集合.为了更好地从专题文章集合内部的复杂信息关联中高效挖掘子话题信息,文中提出了抑制背景噪声的线性判别分析(LDA)子话题挖掘算法BLDA,通过预先抽取专题文档集合的共同背景知识、在迭代过程中重设关键词的产生等方式提高子话题抽取的准确程度.在微信公众账号文章上的系列实验证明,BLDA算法针对有共同背景的专题文章集合的聚类结果显著优于传统的LDA算法,其中主题召回率提高了170%,Purity聚类指标提高了143%,NMI聚类指标提高了160%.
子话题挖掘;线性判别分析;背景噪声抑制
话题的挖掘与分析一直是自然语言处理领域的一个重要研究方向,在舆情分析等领域具有广泛的应用.由在线社交网络的快速发展引发的网络信息爆炸,使得普通用户在快速生成的巨量信息面前显得无所适从,因此当前对在线社交网络上的信息表示普遍出现了分类化与精细化趋势,信息分布更加细致紧凑,如微博中的HashTag等标签机制,以及微信公众账号的相似公众号专题文章集合机制等.对于这部分专题信息进行更精细化的文章聚类整理的应用需求不断地增大,对专题文章的进一步子话题挖掘成为了目前工业界和学术界关心的热点问题.
传统的话题分析方法使用文本聚类和主题模型等策略,这些策略具有普适性,但是对于分类后的更加细致紧凑的专题文章的话题挖掘效果却不尽如人意.最普遍的现象是,普通的话题挖掘方法对于具有相同背景的文章集合的辨识度不高,产生的话题结果区分度受限.当前子话题分析的主流方法聚焦于找出专题内部差异化的主题信息,这部分工作的主要内容就是在某些拥有大的共同背景的文章中找出文章之间的差异性,每一个差异主题形成一个子话题,并找出每个子话题的代表关键词.正是由于这些文章之间有一个公共的背景,所以子话题分析与话题分析的工作存在实质上的区别,例如使用线性判别分析(LDA)主题模型(以下简称LDA主题模型)进行子话题分析,由于所有的文章都存在一个相似的背景,所以使用LDA主题模型不能够彻底地将信息进行细致的分割,有些不同的子话题的文章有可能会因为有共同的背景知识,而使得他们的差异性被淹没,捕获的主题信息和主题词由于相似度过高而被纳入同一个主题下.
以某微信公众账号发布的文章集合为例,文中收集了报道领导人在2016年2月至3月间相关工作的3 487篇文章,它们中有与反腐廉政相关的,也有与台湾问题相关的,还有与食品安全相关的,也有与政府工作相关的等等.这些文章有很多的公共的背景知识:直接使用GibbsLDA++工具进行子话题分析的结果可以发现,其中有很多挖掘出的主题关键词词组,它们之间的相似程度非常高,几乎每一个主题中都包含了“中国”、“经济”、“发展”等字样.若使用Jaccard- Distance来度量主题关键词词组的差异性,其平均主题差异性只有0.125 6.
目前关于子话题、衍生话题的系统性研究工作还较少,相关的文献亦较为不足.文中提出一种针对专题文章集合进行子话题挖掘的算法BLDA,从语料组成结构考虑并融入去除背景噪声的思想,扩展了LDA算法,该方法支持学习文章间的共同背景知识,同时获取到差异化的子话题信息.
近年来国内外都针对话题挖掘算法展开了相关的研究,并取得了一定的进展,其中热点话题的挖掘算法可以归结为两类.第一类是使用分类和聚类的算法进行热点话题挖掘.Yang等[1]提出了组平均聚类算法以改进层次聚类算法,进行回顾式话题发现.Chaubet[2]研究了如何利用DBSCAN算法检测比较流行的话题,最终的实验效果并未能够达到预期的程度.Alex等[3]提出了Single- pass的聚类算法,这种算法非常适合于在线的话题检测,在较低的算法时间复杂度上能够给出可接受的话题挖掘结果.
第二类方法是传统的话题模型,使用LDA模型[4]直接针对微博消息建立话题模型,从而抽取相关的话题信息.Ramage等[5]提出了一个半监督的学习模型L- LDA,可以用来学习用户的兴趣分布.Asuncion等[6]在分布式算法基础上提出了改进的LDA以及层次化的狄里克雷过程(HDP),可以使用它来进行话题分析.Blei等[7]提出了一个新的话题模型,这个模型是相关主题模型(CTM),它通过正态分布建模话题之间的相关性.Sankaranarayanan等[8]设计并且实现了一个面向新闻的话题挖掘系统,称为TwitterStand,可以用它来捕捉时下热门的Twitter话题新闻.有人研究通过分析微博内容自动产生有关微博的内容总结,这也是话题挖掘的一种研究方法.譬如Sharifi等[9]采用单个句子来总结微博话题,帮助用户快速地理解热门话题.在此基础上,Inouye[10]提出使用多个句子代表一个话题的方法,主要是为了克服单个句子对话题信息表达不够的缺陷.
李劲等[11]提出了基于特定领域的中文微博热点话题挖掘系统(BTopicMiner),他们认为为了解决微博信息固有数据稀疏性问题,可以先使用文本聚类的方法将内容相关的微博消息合并为微博文档;同时他们认为微博之间的跟帖关系蕴含了话题的关联性,并以此为依据,在传统的LDA主题模型上进行扩展以建模微博之间的跟帖关系;最后利用互信息(MI)计算被抽取出的话题的话题词汇用于热点话题推荐.
然而,以上研究没有聚焦于已分类的专题内部的子话题的进一步分析工作,亦即未关注背景相同文档集合的进一步细分.与笔者研究目标最相近的工作为周学广等[12]所提出的基于依存连接权vsm的子话题检测跟踪方法,其采用的领域词典加权、时间阈值衰减等核心思路适合于在限定信息领域内快速发现热点;但对于非限定领域的应用场景,由于无法大规模构建未知领域词典,该方法无法应用.文中提出了去背景噪声的LDA子话题挖掘算法BLDA,引入背景计算模块,可在无领域限定的情况下进行差异化的子话题挖掘.
1 BLDA算法
1.1 融入去背景噪声的Gibbs采样过程
LDA最初被应用于文档的主题模型的分析,LDA是一个产生式模型,笔者认为每一篇文档都是由多个主题构成的,并且每个词语的生成过程都是先生成主题然后再根据主题生成这个词语,假设一篇文档有K个主题,那么一个词语的生成过程可能就有K条路径,首先随机地在这K个主题中选取一个主题,然后根据这个主题的词分布向量来生成这个词语.原始的LDA认为文档中的主题信息分布符合多项式分布,同时主题中的词语分布也是符合多项式分布的,为了降低过拟合的可能性,LDA给这两个分布都添加了一个符合Dirichlet分布的共轭先验,此处M代表文档的总数,K代表主题的个数.
LDA的原始论文使用变分-EM算法估计未知参数,之后有研究者使用Gibbs Sampling[13]策略实现了对LDA未知参数的估计.Gibbs Sampling是马尔科夫链蒙特卡洛方法(MCMC)中用来获取一系列近似等于指定多维概率分布观察样本的算法.若w是可以观察到的已知变量,α和β是经验超参数,其他的变量z、θ和φ都是未知的隐含变量,N代表文章中的单词个数,由此可以写出所有变量的联合概率分布:
p(wi,zi,θi,φ|α,β)=

(1)
其中,α产生主题分布θ,主题分布θ确定具体的主题,β产生词语分布φ,词语分布φ确定词.因此联合分布为:
p(w,z|α,β)=p(w|z,β)p(z|α)
(2)
式(2)中的第1项因子代表根据主题和词分布的先验参数去进行词语采样,第2项因子代表根据主题的先验参数进行主题采样的过程.两个因子可以独立计算.
第1项因子p(w|z,β)可以根据确定的主题z和先验分布β取样得到的词语分布φ产生,如式(3)所示:
(3)
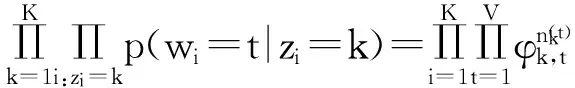
(4)
式中:t代表单词的全局id;k代表主题下标;V代表词汇表的大小.考虑到φ是由超参数为β的Dirichlet分布生成的,所以可以对φ进行积分,然后得到真实分布:
p(w|z,β)=∫p(w|z,φ)p(φ|β)dφ=
其中,nz是主题为z的词频向量,每一项都代表该词语的出现频次.
使用相同的方法可以得到第2项因子的计算公式:
p(z|α)=∫p(z|θ)p(θ|α)dθ=
其中:m代表文档下标;nm代表第m篇文档的主题分布向量,每一项代表该主题在文档中出现的频次.
将两个部分结合起来就可以得到p(z,w)的联合分布概率:
(7)
有了联合分布之后,就可以通过联合分布来计算在给定可观测变量w下隐变量z的条件分布p(z|w),如式(8)所示,αk代表超参数的第k项,实现时依据经验值设定,βt亦是如此.
(8)
从式(8)中可以对每个单词的每个主题概率进行计算,然后对这K个路径采样.以上步骤是GibbsSampling算法的关键,有了以上的采样结果之后就可以计算最后面的文档主题矩阵和主题单词矩阵.
去背景化的LDA与原始的LDA算法存在的一个重要的区别就是去背景化的LDA认为一个词语有可能来自背景语料也可能来自于差异化的主题模型中,背景语料词语分布情况在主题模型的迭代过程中不会发生变化,背景语料的词语分布情况可以提前通过对整体语料的统计而计算出来,而差异化的主题模型的词语的概率分布则需要在后面的更新迭代的过程中计算出来.根据式(8)可以得到原始的LDA的一个词语生成的过程,如图1所示.这个图中每一个词语在采样的过程中可以有K条路径.图中d代表文档,z代表主题,不同的主题下标1至K代表不同的主题,w代表生词的词语.
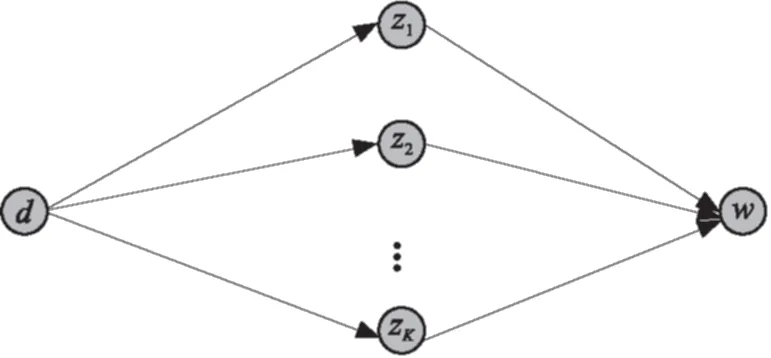
图1 文档-主题-词的生成路径
但是去背景噪声的LDA的采样过程将发生变化,采样的路径中多了一条来自背景主题的可能路径.具体的可以参考图2.可以看出文档d在对词语进行采样的过程中,要先进行一次掷骰子,可以考虑这个过程为一次伯努利实验,根据掷骰子的结果判定这个词语的主题采样过程,并根据投掷骰子的结果进行采样策略的选择.最后笔者可以对K+1条路径直接进行概率计算,然后进行采样.
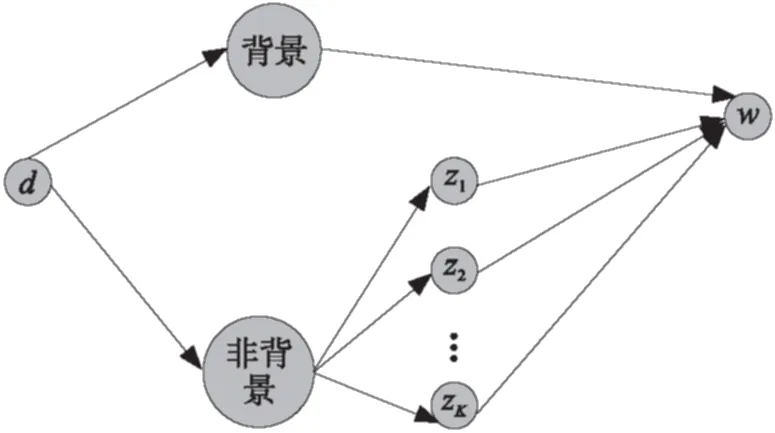
图2 考虑背景噪声的词语生成过程
1.2 BLDA算法

表1 BLDA参数释义
背景模块中的单词分布向量f需要在BLDA算法开始迭代之前进行统计,最简单的方法是直接统计所有单词出现的个数,维护一个V维的词频向量列表,然后加入平滑项,最后归一化.这部分知识只需要再统计一次,后面就不会再发生改变了.
BLDA算法的关键就是认定文档的内容有可能来自背景知识,也可能来自差异化的话题之中.重新设定产生词语的过程:
(2)分别计算这个词语来自背景语料的生成概率和这个词语来各个自差异化的子话题之中的生成概率;
(3)设定规则.如果这个词语来自背景语料的生成概率超过某个阈值,那么直接认为这个词语来自背景语料,那么这个词将在后续计算文档的主题概率和主题的词语概率的过程中被忽略.否则,如果背景语料生成这个词的概率不超过某个阈值,就将背景生成路径也加入采样路径.其中单词各个主题的概率值和背景模块概率值计算公式如式(9)和式(10)所示,归一化计算公式如式(11)和式(12)所示,其中b表示背景模块.
p(zi=k|z,w)=
(9)
p(zi=b|z,w)=φt
(10)
(11)
(12)
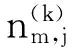
2 实验结果与分析
为了验证BLDA算法的有效性,使用BLDA算法学习专题文章集合的子话题信息,挖掘出能够充分代表该子话题的主题信息.实际上就是要验证两个方面的效果:BLDA算法的主题挖掘能力、以及BLDA算法的主题聚类能力.实验数据取自于微信公众账号发表的文章,从2016年2月25日到2月28日的所有的包含政治家等相关词汇的文章作为我们的训练语料,将实验数据人工标注为20个类别,总共包含3 487篇文档.
2.1 BLDA主题挖掘能力结果分析
文中针对该语料将分别使用普通的LDA算法和BLDA算法运行,观察这两种算法在上面标注数据集合上的主题挖掘结果,并且提供客观的评价指标,比较两种算法针对专题文章的主题挖掘能力.
BLDA算法抽取的主题关键词的结果如表2所示,由于篇幅有限,这里只给出了前12个主题关键词列表.笔者通过直接观察BLDA算法抽取的主题关键词词组,发现不同的主题之间的关键词关联性很小,后面笔者会给出更加细致化的量化分析结果.

表2 BLDA算法抽取的主题关键词结果
本实验的结果通过人工评判的方式对所抽取的主题关键词进行分析,评判的标准是主题召回率:每次试验时不同的模型都会分别给每个主题20个关键词,当作是该主题的代表,通过人工分析判定这20个关键词能否代表一个主题信息,然后去评判能够召回多少原始的主题信息.
可见,针对这批有相同背景的语料,BLDA的主题召回率比LDA的主题召回率平均提高了很多,并且随着迭代次数的增加,BLDA的平均主题召回率也会相应的提高,直到趋近收敛.从实验结果中也可以分析得出,背景化模块对于主题发现有很大的帮助作用,算法的主题平均召回率相比于LDA的主题召回率提高了170%.
第2个主题关键词的评判标准是,不同主题关键词词组之间的差异化信息量,这个也是笔者使用去背景化思想的最主要目的.这个指标比较不好测试,文中设定使用平均相似度s作为指标:
(13)
其中的关键词词组相似度信息的计算方法就是计算它们之间的同现词的比例,这种相似度的统计就是Jaccard相似度[14].在参数设定与前一组实验一致的情况下,BLDA和LDA在300、400、500和600次迭代后的平均相似度依次分别为:0.125 439、0.121 930、0.113 158、0.124 561,以及0.772 220、0.759 357、0.714 327、0.637 719.可见,BLDA抽取的关键词词组的平均相似度明显低于LDA抽取的结果,平均相似度平均降低了495%,这主要是因为背景模块的信息在最终的统计过程中被剔除,留下了差异化比较大的话题信息.
2.2 BLDA聚类能力结果分析
从聚类的结果来评判聚类结果是聚类的最直接的评价指标,Purity方法[15]是极为简单的一种聚类评价方法,只需计算正确聚类的文档数占总文档数的比例:
(14)
式中:Ω={ω1,ω2,…,ωk},是聚类的集合,ωk表示第k个聚类的集合;C={c1,c2,…,cJ},是文档集合,cJ表示第J个文档.
Purity指标的优点是方便计算,它的值在0~1之间,完全错误的聚类方法值为0,完全正确的方法值为1.同时,Purity方法的缺点也很明显,它无法对退化的聚类方法给出正确的评价,设想如果聚类算法把每篇文档单独聚成一类,那么算法认为所有文档都被正确分类,那么Purity值为1.
另一方面,一种能在聚类质量和簇数目之间维持均衡的指标是NMI[15],它的定义如下:
(15)
式中,H函数代表概率分布的信息熵,I是互信息.
(16)
其中p(ωk∩cj)、p(ωk)和p(cj)分别是一篇文档属于ωk∩cj、ωk和cj的概率,而第2个等式是对前半部分进行了最大似然估计(MLE)后的结果.这种评价指标能够综合聚类结果的类别数和类别质量.LDA与BLDA算法在300、400、500、以及600次迭代后的NMI结果为:0.278 553、0.271 216、0.314 051、0.326 884,以及0.795 688、0.745 267、0.767 683、0.771 896.可见,BLDA的聚类结果指标NMI平均提高了160.2%.
NMI指标的值越高说明聚类算法的效果越好,BLDA算法的NMI指标远远地优于LDA算法的NMI指标.LDA算法随着迭代次数的增加,NMI指标持续缓慢地提升,但是BLDA算法的NMI指标却没有持续缓慢的提升,相反还出现了指标值振荡的情况,笔者猜测这有可能与背景模块的引入有关.
与上面的评价指标不同的另外一个评价指标可以将聚类看成是一系列的决策过程,即对文档集上所有的N(N- 1)/2个文档对进行决策.当且仅当两篇文档相似时,笔者将它们归入同一簇中,TP决策将两篇相似文档归入一个簇,而TN决策将两篇不相似的文档归入两个不同的簇,在此决策过程中会犯两类的错误:FP决策会将两篇不相似的文档归入同一个簇,而FN决策会将两篇相似的文档归入不同簇.RI计算的是正确决策的比率:
(17)
上面提到的RI是最基本计算方法,其中FN和FP拥有相同的权重,有时候将相似的文档分开比将不相似的文档归成一类更严重.所以可以使用F值来度量聚类的结果,并通过设定不同的γ来调整对FN的惩罚力度,P代表准确率,R代表召回率.
(18)
文中取定调节因子为1的情况下,分别计算得到BLDA和LDA在300、400、500和600次迭代之后的F值(RI系统的一种变种):0.710 955、0.658 759、0.691 712、0.689 664,以及0.252 222、0.219 044、0.285 863、0.283 995.
文中采用Purity准确率、NMI和RI系数这3个指标来验证BLDA算法,发现其在实际应用中的聚类结果比原始的LDA算法的聚类结果更加合理.实验结果也定量地给出了BLDA算法的有效性证明和解释.
3 结论
文中提出了一种抑制背景噪声的LDA子话题挖掘算法BLDA,能够通过预先抽取专题文档集合的共同背景知识,在迭代的过程中重设关键词的产生方式提高子话题抽取的准确程度.这一方法能够分离不同子话题之间的关联性,从而有效解决有共同背景知识的专题文章的集合的子话题挖掘难题.
通过对微信公众账号专题文章集合的实验证明,BLDA算法对拥有公共背景知识的专题性文章具有很好的分析能力,使用BLDA算法能够更加准确地挖掘差异化的主题信息,BLDA算法的主题召回率相比于原始的LDA算法平均提高了170%,同时使用BLDA能够得到更加有效的聚类结果,BLDA算法的Purity指标相比于LDA算法提高了143%,NMI指标提高了160.2%.
[1] YANG Y, PIERCE T, CARBONELL J G, et al. A study of retrospective and on-line event detection [C]∥Proceedings of the 21st SIGIR Conference on Research and Development in Information Retrieval. Melbourne:ACM,1998:28- 36.
[2] CHAUBET J. Detecting trending topic on chatter [D]. Stockholm:Master of Science Thesis in Information and Communication Technology, Royal Institute of Technology, 2011.
[3] ALEX N, HAMMER B, KLAWONN F, et al. Single pass clustering for large data sets [C]∥Proceedings of the 6th International Workshop on Self- Organizing Maps.Westfalen:Bielefeld University, 2007:1- 6.
[4] BLEI D M, Ng A Y, Jordan M I. Latent dirichlet allocation [J]. Journal of Machine Learning Research,2003,2003(3):993- 1022.
[5] RAMAGE D, DUMAIS S T, LIEBLING D J. Characterizing microblogs with topic models [C]∥Proceedings of International Conference on Weblogs and Social Media, ICWSM.Washington:Association for the Advancement of Artificial Intelligence,2010:130- 137.
[6] ASUNCION A U, SMYTH P, WELLING M. Asynchronous distributed learning of topic models [C]∥Proceedings of the 22nd Annual Conference on Neural Information Processing Systems.Vancouver:DBLP, 2008:81- 88.
[7] BLEI D M, LAFFERTY J D. A correlated topic model of science [J]. Annals of Applied Statistics,2007,1(1):17- 35.
[8] SANKARANARAYANAN J, SAMET H, TEITLER B E, et al. TwitterStand:news in tweets [C]∥Proceedings of ACM Sigspatial International Symposium on Advances in Geographic Information Systems. Seattle, Washington:ACM,2009:42- 51.
[9] SHARIFI B, HUTTON M A, KALITA J. Summarizing microblogs automatically [C]∥Proceedings of Human Language Technologies:the 2010 Conference of the North American Chapter of the Association for Computational Linguistics. Los Angeles:ACL,2010:685- 688.
[10] INOUYE D.Multiple post microblog summarization [R]. Colorado:University of Colorado at Colorado Springs,2010.
[11] 李劲, 张华, 吴浩雄,等. 基于特定领域的中文微博热点话题挖掘系统BTopicMiner [J]. 计算机应用, 2012,32(8):2346- 2349. LI Jin, ZHANG Hua, WU Hao-xiong, et al. BTopicMiner:domain-specific topic mining system for Chinese microblog [J]. Journal of Computer Applications, 2012, 32(8):2346- 2349.
[12] 周学广, 高飞, 孙艳. 基于依存连接权vsm的子话题检测与跟踪方法 [J]. 通信学报,2013,34(8):1- 9. ZHOU Xue- guang, GAO Fei, SUN Yan. Sub- topic detection and tracking based on dependency connection weights for vector space model [J]. Journal of Communications,2013, 34(8):1- 9.
[13] GELFAND A E. Gibbs sampling [J]. Journal of the American Statistical Association,2000,95(452):1300- 1304.
[14] Jaccard index [OL]. (2016- 04-20)[2016-11- 05].en.wikipedia.org/wiki/Jaccard_index.
[15] LUOLEICN. 聚类的一些评价手段[OL].(2010- 03- 09)[2016-11- 05].blog.csdn.net/luoleicn/article/details/5350378.
LDA Subtopic Detection Algorithm with Background Noise Restraint
LIJing-yuan1QIUZhi-jie1LIUYue1CHENGXue-qi1RENYan2
(1.Institute of Computing Technology∥Key Laboratory of Network Data Science and Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. National Computer Network Emergency Response Technical Team Coordination Center of China, Beijing 100029, China)
Special article set is a collection of articles with common background knowledge. In order to more effectively detect the subtopics form special article set with complex information correlation, an LDA subtopic detection algorithm with background noise restraintnamed BLDA is proposed, which improves the precision of subtopic detection from article set by firstly extracting the common background knowledge and then reproducing the keywords in each iteration step. By a series of experiments on a set of WeChat documents from public accounts, it is proved that the detection results obtained by BLDA are much better than those obtained by LDA, with a topic recall rate increment of about 170%, a Purity index increment of 143% and a NMI index increment of 160%.
subtopic mining; linear discriminant analysis; background noise restraint
2016- 12- 07
国家自然科学基金资助项目(61303244,61572473,61572469,61402442,61402022,61370132);国家242信息安全计划项目(2015F114) Foundation items: Supported by the National Natural Science Foundation of China(61303244,61572473,61572469,61402442,61402022,61370132) and the National 242 Project of Information Security (2015F114)
李静远(1982-), 男, 高级工程师,主要从事在线社会网络信息传播与信息安全研究.E-mail:lijingyuan@ict.ac.cn
1000- 565X(2017)03- 0054- 07
TP 393.09
10.3969/j.issn.1000-565X.2017.03.008
