基于主题模型的资源选择算法*
2017-06-21董守斌谢一帆袁华陈建豪
董守斌 谢一帆 袁华 陈建豪
(华南理工大学 计算机科学与工程学院∥广东省计算机网络重点实验室, 广东 广州 510006)
基于主题模型的资源选择算法*
董守斌 谢一帆 袁华†陈建豪
(华南理工大学 计算机科学与工程学院∥广东省计算机网络重点实验室, 广东 广州 510006)
在具有多个真实搜索引擎的联邦检索环境下,基于小文档的资源选择算法由于难以估计每个搜索引擎的真实网页数量,因此准确率较低.针对这个问题,文中提出了基于主题模型的资源库描述方法,利用LDA主体模型获取每个资源库的描述词;在此基础上提出新的资源选择算法,结合垂直领域权重和词向量计算资源库和查询请求之间的相关度,并根据相关度大小获取最终资源选择结果.实验结果表明,基于主题模型的资源选择算法能很好地提高资源选择效果,可有效应用于分布式搜索引擎的联邦检索环境.
分布式检索;资源选择;主题模型;垂直领域;词向量
资源选择是典型分布式检索系统需要解决的主要问题之一[1].当给定一个查询和一个文档资源库集合,资源选择意在判断和选择出与该查询相关的资源库.资源选择方法可用于不同的信息检索应用,如聚合搜索、桌面搜索、联邦检索等.
早期的资源选择算法将每个资源库看成一篇大文档,然后使用标准的信息检索模型计算出查询与资源库的相关性,如CORI方法[2]和CVV方法[3]等.这种将资源库看做大文档的方法消除了资源库中文档与文档的差异性,一定程度上影响了资源选择的效果.而ReDDE[4]、ReDDE.Top[5]、Approx.CiSS[6]、CRCS[7]、SUSHI[8]和GAVG[9]等类ReDDE方法则是利用建立的资源库的中央索引库,根据查询获得的索引库结果,使用一定的方法估计资源库中包含的相关文档的数目,从而获得与查询相关的资源库列表.但这一类方法需要先对资源库进行抽样,利用抽样文档建立中央索引库.而在实际的分布式检索环境下,这些资源库真实的网页数量是难以准确估计的.此外,某些分布式检索环境会要求每个查询至少选择出若干资源库数目,而由于此类方法需要通过查询中央索引库获取资源库列表,因此有可能出现资源库数量不满足要求的情况.陈志敏[10]提出了结合资源库对应网站的PageRank[11]、市场份额和部分日志统计信息来衡量资源库重要性,将其反馈到查询与资源库的相关性评分;该方法取得一定效果,但核心部分仍为类ReDDE方法.
在现代分布式检索系统中,各个资源库根据其自身内容的不同分属于不同的主题领域,称之为垂直领域.每个垂直领域包含相似类型的信息和一系列与该垂直领域相关的资源库.如垂直领域“software”包含了软件领域的相关网页和软件类型的资源库[12],如GitHub和SourceForge等.
为解决传统类ReDDE方法的不足,文中提出了一种全新的资源选择算法.该方法与传统的类ReDDE方法不同点在于,不需要构建中央索引库和估计原始资源库的网页数量,仅基于资源库和查询词自身信息进行研究.该算法需要解决两个问题:一是如何对资源库进行描述;二是如何判断资源库于查询请求之间的相关度.针对第1个问题,文中提出了基于主题模型的资源库描述方法;针对第2个问题,文中提出了一种新的资源选择算法框架,在垂直领域权重和资源库描述的基础上,结合词向量技术计算资源库与查询请求之间的相关度.
1 基于主题模型的资源选择算法
1.1 基于主题模型的资源库描述
主题模型能够刻画一篇文档的潜在主题,并得出与主题关系最紧密的相关词汇和相关度.一个资源库拥有内容纷繁多样的海量文档,因此,可以认为资源库具有不同的主题分布.如果将资源库看做一篇大文档,同样可以使用主题模型来刻画出资源库的主题分布以及主题关键词汇分布.用资源库的主题分布下各个主题的关键词汇来作为该资源库的描述,既能够体现资源库主题的多样性,也能够体现资源库描述的准确性.文中提出基于LDA[13]主题模型的资源库描述方法,包括以下两个步骤:
(1)对每个资源库进行LDA主题模型的训练,得出资源库的k个主题以及主题-关键词分布;
(2)选取k个主题下各n个关键词汇作为资源库的关键词描述.
图1为资源库训练LDA模型示意图.该方法首先对资源库内所有的文档进行分词、去除停用词等预处理,将预处理后的文档集作为LDA模型的训练数据输入.LDA模型通过吉布斯采样[14]方法对资源库相关信息进行采样训练,最终输出该资源库的主题分布以及主题对应关键词列表以及这些关键词与主题之间的相似度大小,主题数同词汇数可事先设定.在LDA训练后,选取每个主题排名前n的关键词汇作为该资源库的描述信息.获取的资源描述信息可用于后续资源选择算法的计算.
1.2 资源选择算法RS_LDA
对基于垂直领域的分布式检索系统的资源选择来说,资源库与查询词之间的相关性不仅取决于资源库描述信息同查询词之间的相关性,还和其所属的垂直领域和查询词之间的相关性有关.若对一个资源库来说,它所属的垂直领域若属于与查询词相关的垂直领域, 那么该资源库与该查询词相关联的可能性将增大,因此在计算资源库分数时,要考虑垂直领域的权重的影响.
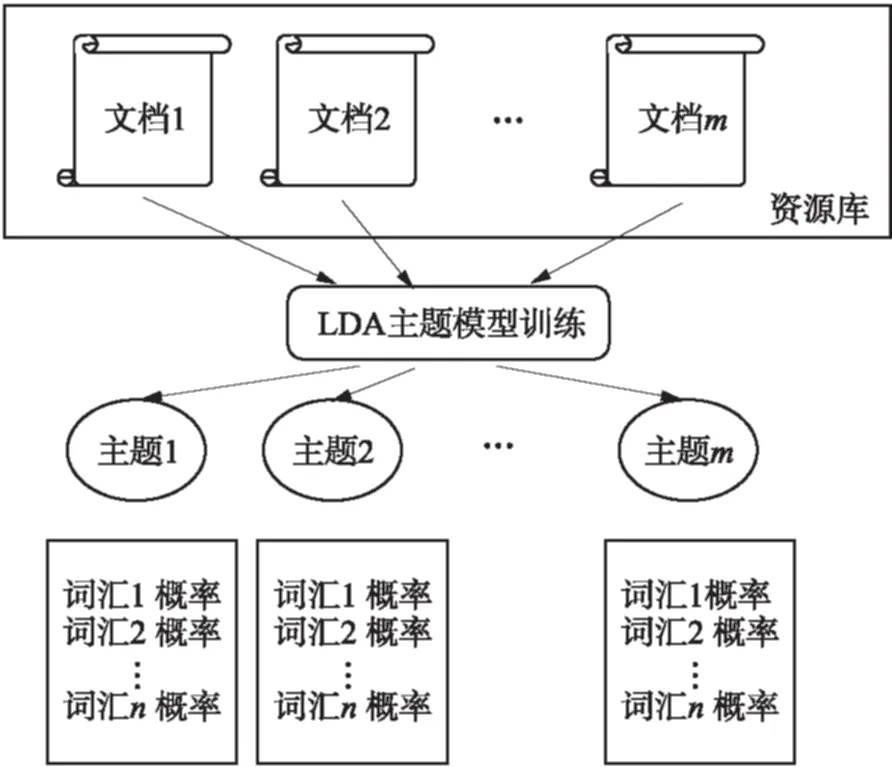
图1 基于LDA主题模型的资源描述
若一个词项越频繁出现在一个垂直领域中,那么它越能够作为该垂直领域的代表性词项,借鉴频繁词项排序FTR模型[15],用一个词项在垂直领域的词汇排序表中的排序位置来判断两者之间的相似度.因此文中采用词权重TF- IDF[16]方法衡量词汇的重要性,并以该值对每个垂直领域中的所有词汇进行排序,形成每个垂直领域的特有词汇排序表,然后利用词向量Word2Vec[17]方法获取查询词的扩展词汇,用查询词的扩展词汇在垂直领域的词汇排序表中的排序位置来判断两者之间的相似度.在此基础上计算资源库对应的垂直领域权重:若该资源库属于与查询词相关的垂直领域,那么该资源库和查询词的相关性更大,则赋予该资源库更高的权重.
基于上述问题的讨论,文中提出了基于LDA资源描述的资源选择算法RS_LDA,具体包括以下几个步骤:
(1)通过词向量Word2Vec方法获取查询词的扩展词汇集合Q={qk,k=1,2,…,C},C是扩展词个数,用rqk表示某扩展词汇qk在垂直领域Vi的词汇排序表中所在的排序位置,则可计算扩展词汇qk的权重wqk:
(1)
(2)设资源库Ri(i∈{1,2,…,F})的所属垂直领域为Vi,F是资源库个数.计算所有的查询词扩展词汇所在位置并求和,作为查询词q与垂直领域Vi的相似性分数:
(2)
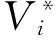
(3)通过LDA模型训练出资源库Ri的主题分布Topict,t∈{1,2,…,G},以及主题描述词汇Verbaltj,j∈{1,2,…,H},G是主题数,H表示每个主题下选取的关键词汇个数.计算词汇vtj权重:
(3)
式中,rvtj表示词汇vtj的排名.
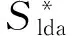
(4)
式中的w2v_sim(qk,vtj)指用Word2Vec计算的扩展词汇qk和资源库主题关键词汇vtj的相似值.
(5)
RS_LDA资源选择算法的具体描述如下.
输入:查询词q,待排序的资源库列表,
ListR={Ri,i=1,2,…,C}
输出:资源选择结果列表
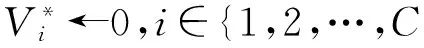
∥初始化所有资源库的垂直领域权重
Q={qk,k=1,2,…,C}←Word2Vec(q)
∥查询词扩展
forqkinQ
wqk←根据式(1)计算扩展词汇权重
end for
forRiin ListR
sim(q,Vi)←根据式(2)计算查询与垂直领域的相似度
if sim(q,Vi)大于阈值T

end if
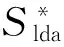

end for
2 实验结果与分析
2.1 实验设置
实验使用的数据集为FedWeb2014数据集[18],该数据集是从149个真实的搜索引擎通过抽样搜索获取的.实验对75个查询词进行资源库选择实验,待选择的资源库数即为149个.每个资源库中包含大致40 000个网页,这些网页摘要信息保存在FW14- sample- search数据集合中,可用于训练资源库的LDA模型和Word2Vec模型.数据集提供资源库与24个垂直领域之间的映射关系.实验先针对每个资源库的网页摘要进行预处理并作为LDA模型训练的输入数据集,获得每个资源库的LDA主题-词汇分布及TF-IDF词汇排序表.实验同样使用Word2Vec模型对输入的查询词进行扩展,选取C个查询扩展词并记录其与查询词之间的相似度值.
2.2 RS_LDA资源选择算法参数实验
2.2.1 不同主题数和不同关键词汇数下的实验结果
对于RS_LDA资源选择算法而言,LDA模型选取不同的主题个数和不同的主题关键词汇,都会对结果产生不一样的影响.本实验针对选取不同主题个数G和不同主题词汇数H的情况进行实验,使用nDCG@20的值作为测评指标,并取LDA主题个数G的区间在{2,4,6,8,…,18,20}内,LDA主题关键词汇H的范围在{5,10,15,20,25,30,35}内,同时固定其他参数值:a为1.7,C为10,权重因子α值和β值均为1,阈值T设置为0.8.实验结果如图2所示,横坐标为不同主题数G,纵坐标为nDCG@20值,RS_LDA@H曲线表示当H取不同值的时候,资源选择的效果变化趋势.
由图2可见,对LDA词汇数H为20、25、30、35的曲线来说,在主题数由2升至8或10的范围内,随着主题数的增加,曲线不断上升;当主题数大于10时,曲线随着主题数的增加不断下降.而对于LDA词汇数为5、10、15的曲线来说,随着主题数的增加,曲线趋势在缓慢增长中.因此可以推断,资源选择算法RS_LDA的准确率或许和主题数G与各主题下关键词汇数H的乘积有关,即选取的总LDA词汇个数相关.同由图2可知,最大值出现在主题数为8、LDA词汇数为30的情况下,在该参数值下资源选择算法RS_LDA获得最高效率,为 0.524 4.
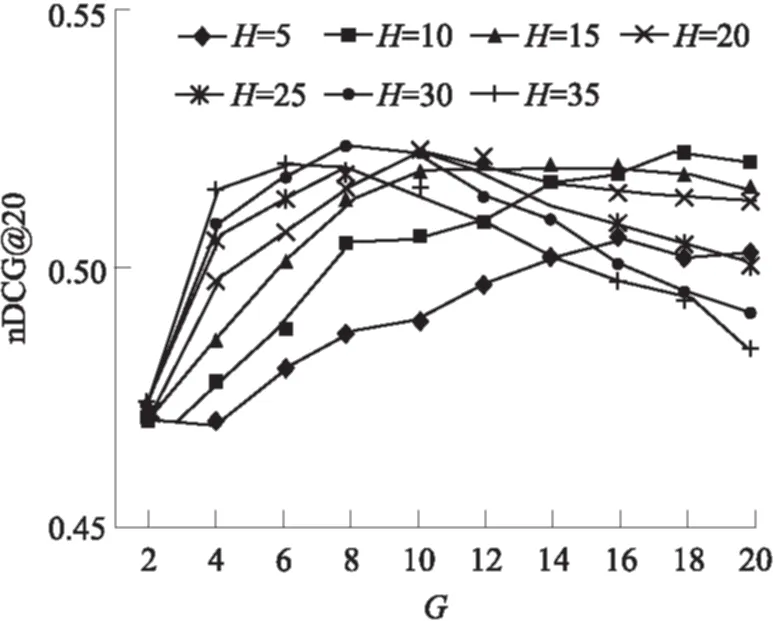
图2 不同主题数G和关键词数H下的效果对比
2.2.2 不同权重参数下的实验结果
资源选择算法中有两个重要的权重参数α和β.本实验在{0.1,0.2,0.3, …, 0.9,1.0}范围内设置α和β,并使用nDCG@20作为测评指标,观察在不同α、β参数值设置下,RS_LDA算法准确率的变化情况.该实验固定其他参数值:a为1.7,H取值30,G取值8,C取值10,阈值T设置为0.8.表1为RS_LDA算法在不同参数设置下的nDCG@20值.由表1可知,当α、β取值分别为0.7、0.8时,RS_LDA取得最好效果(为0.540).由此可知,RS_LDA算法的最终分数融合部分,略青睐于LDA权重所带来的准确度信息.

表1 在不同权重参数α和β下的nDCG@20值
1)该数值是指β的数值.
2.2.3 不同扩展词汇数下的实验结果
查询词的扩展词汇个数C也是影响实验结果的一个因素.本实验研究不同C值对资源选择的影响情况.固定其他参数的取值:a为1.7,H为30,G为8,资源选择算法的α和β的比值分别设置为0.7、0.8.将C的取值范围固定在{5,10,15,20,25,30,35,40}内,观测最终结果的变化情况.本实验同样使用nDCG@20作为评价指标.实验结果如图3所示.

图3 不同C值下资源选择算法效果对比
Fig.3 Performance comparison in resource selection for diffe-rentC
由图3可见,随着C取值的不断增大,资源选择算法RS_LDA的nDCG@20值不断下降,当C值取5时,资源选择算法的效果最好.因此,对于资源选择算法来说,C值取5时,获得最佳效果.
2.3 对比实验与分析
文中选取了CRCS(e)资源选择算法[10]的最优结果,以及TREC FedWeb2014资源选择任务中ICTNET团队[14]提出的ICTNETRS这一最优资源选择算的结果与RS_LDA资源选择算法的资源选择效果进行比较.结果如表2所示.表中,nP为归一化查准率,@5表示取前5个排序结果进行统计.
可以看出,文中提出的资源选择算法在nDCG@ 20值、nDCG@10值和nP@5上均超过了其他算法,

表2 不同资源选择算法的对比
包括最优算法ICTNETRS.
由于LDA主题模型的训练以及Word2Vec的词向量训练均可以离线进行,在线计算开销是比较小的.因此可说明文中提出的资源选择算法在分布式检索资源选择中的可行性、高效性和准确性.
3 结语
传统的类ReDDE方法由于需要利用中央索引库进行资源库抽样估计,在资源库真实网页数目估计和待补充资源库问题上会带来一定的准确度损失.对此,文中提出了基于主题模型的资源选择算法.该算法通过LDA主题模型的离线训练得出资源库描述,并结合词向量技术进行资源选择.通过实验证明,基于主题模型的资源选择算法能够有效提高资源选择的准确率,与以往算法比较有较大的性能提升,是准确有效的.下一步工作是将资源选择算法应用于分布式检索系统中,基于资源选择算法评估资源查询的有效性,以提高分布式检索结果融合的效果.
[1] NGUYEN D,DEMEESTER T,TRIESCHNIGG D,et al.Federated search in the wild [C]∥Proceedings of CIKM’12.Maui:ACM, 2012.
[2] CALLAN J P, LU Z, CROFT W B. Searching distributed collections with inference networks [C]∥Proceedings of International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM, 1995:21- 28.
[3] YUWONO B, LEE D L. Server Ranking for Distributed Text Retrieval Systems on the Internet [C]∥Proceedings of 5th International Conference on Database System for Advanced Applications.Melbourne:Wohd Scientific Press,1997:41- 49.
[4] SI L, CALLAN J. Relevant document distribution estimation method for resource selection [C]∥Proceedings of the 26thInternational ACM SIGIR conference on Research and Development in Information Retrieval.Toronto:ACM, 2003: 298- 305.
[5] ARGUELLO J, CALLAN J, DIAZ F. Classification- based resource selection [C]∥Proceedings of the 18th ACM conference on Information and Knowledge Management. Hong Kong:ACM, 2009:1277- 1286.
[6] MARKOV I, CRESTANI F. Theoretical, qualitative, and quantitative analyses of small- document approaches to resource selection [J]. ACM Transactions on Information Systems (TOIS), 2014, 32(2):9.
[7] SHOKOUHI M. Central- rank- based collection selection in uncooperative distributed information retrieval [M]. Berlin, Heidelberg:Springer,2007.
[8] THOMAS P,SHOKOUHI M.SUSHI:scoring scaled samples for server selection [C]∥Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval.Boston:ACM,2009:419- 426.
[9] Arguello J.Federated search for heterogeneous environment [D].Pittsbargh:Carregie Mellon University,2011.
[10] 陈志敏. 联邦检索系统的关键技术研究与实现 [D]. 广州:华南理工大学, 2015.
[11] PAGE L, BRIN S,MOTWANI R, et al. The PageRank citation ranking:Bringing order to the web [R].Stanford:Stanford InfoLab, 1999.
[12] THOMAS D, DOLF T, DONG N, et al. Overview of the TREC 2014 federated web search track [C]∥Proceed-ings of the 23rd Text Retrieval Conference (TREC).Maryland:National Institute of Standards and Technology,2014:1- 11.
[13] BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3:993- 1022.
[14] STUART G,DONALD G. Stochastic relaxation,Gibbs distributions, and the Bayesian restoration of images [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1984, PAMI- 6(6):721- 741.
[15] GUAN F, ZHANG S,LIU C,et al. ICTNET at federated web search track 2014 [C]∥Proceedings of the 23rd Text Retrieval Conference (TREC).Maryland:National Institute of Standards and Technology,2014.
[16] SALTON G,BUCKLEY C. Term-weighting approaches in automatic text retrieval [J]. Information Processing & Management, 1988, 24(5):513- 523.
[17] ZHANG D, XU H,SU Z,et al.Chinese comments sentiment classification based on word2vec and SVM perf [J]. Expert Systems with Applications,2015,42(4):1857- 1863.
[18] U.S. lommerce Department. Text REtrieval Conference[EB/OL].[2015- 10- 06]. http:∥trec.nist.gov/.
Resource Selection Algorithm on the Basis of Topic Model
DONGShou-binXIEYi-fanYUANHuaCHENJian-hao
(School of Computer Science and Engineering//Computation & Computer Network Laboratory of Guangdong Province, South China University of Technology, Guangzhou 510006, Guangdong, China)
In the federated search environment with multiple real search engines, the small- document approach, which is inefficient in estimating the accurate number of indexed files in the process of resource description, may result in poor performance of resource selection methods. In order to solve this problem, a resource library description method on the basis of topic model is proposed, which adopts LDA topic model to obtain the description word of each resource library. Then, a new resource selection algorithm is proposed, which combines with both vertical weight and word vector to calculate the correlation between resource library and query request, and to obtain the final resource selection results according to the correlation. Experimental results show that the proposed resource selection algorithm on the basis of topic model improves the performance of resource selection and can be effectively applied in the federated search environment of distributed search engines.
distributed search; resource selection; topic model; vertical domain; word vector
2016- 11- 27
广东省自然科学基金重大基础研究培育项目(2015A030308017);教育部中国移动科研基金资助项目(MCM20150512) Foundation items: Supported by the Significant Fundamental Cultivate Project of Guangdong Province Natural Science Foundation(2015A030308017)and the Scientific Research Joint Funds of Ministry of Education of China and China Mobile(MCM20150512)
董守斌(1967-),女,博士,教授,主要从事信息检索与高性能计算研究. E-mail:sbdong@scut.edu.cn
†通信作者: 袁华(1969-),女,博士,副教授,主要从事信息检索研究. E-mail:hyuan@scut.edu.cn
1000- 565X(2017)03- 0048- 06
TP 391
10.3969/j.issn.1000-565X.2017.03.007
