基于多数据源的知识图谱构建方法研究
2017-06-09吴运兵阴爱英林开标余小燕赖国华
吴运兵,阴爱英,林开标,余小燕,赖国华
(1. 福州大学数学与计算机科学学院,福建 福州 350116; 2. 福州大学至诚学院,福建 福州 350002; 3. 厦门理工学院计算机与信息工程学院,福建 厦门 361024; 4. 台湾元智大学资讯学院,台湾 桃园 32003)
基于多数据源的知识图谱构建方法研究
吴运兵1,阴爱英2,林开标3,余小燕1,赖国华4
(1. 福州大学数学与计算机科学学院,福建 福州 350116; 2. 福州大学至诚学院,福建 福州 350002; 3. 厦门理工学院计算机与信息工程学院,福建 厦门 361024; 4. 台湾元智大学资讯学院,台湾 桃园 32003)
针对多数据源的融合应用,构建了基于多数据源的知识图谱. 首先,对不同领域内的数据源构建相应本体库,并将不同本体库通过数据融合映射到全局本体库; 然后,利用实体对齐和实体链接方法进行知识获取和融合; 最后,搭建知识图谱应用平台,提供查询和统计等操作. 在实体对齐方面,利用传统的基于相似性传播实体对齐方法,获得良好的实体对齐效果; 在实体链接方面,提出了基于约束嵌入转换的预测推理方法,实验结果表明,在预测准确率上取得较好的结果.
知识图谱; 本体构建; 数据融合; 实体对齐; 实体链接
0 引言
在大数据时代背景下,随着海量数据的出现以及多数据源融合交叉应用,传统的数据管理模式以及查询方式受到一定的制约. 近年来,知识图谱(knowledge graph)[1]作为一种新的知识表示方法和数据管理模式,在自然语言处理、 问题回答、 信息检索等领域有着重要的应用. 知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系; 其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构[2].
随着谷歌知识图谱的发布,知识图谱的构建与应用研究引起了学术界和工业界的广泛关注. 在国内,知识图谱的构建与研究已取得许多重要的研究成果[3-7]. 现有的行业领域知识图谱通常采用手工构建方式,缺乏统一的构建方法,且这类知识库目标是特定行业领域,因此,其描述范围极为有限. 针对这些问题,本研究提出一个多数据源融合的知识图谱构建流程,并对关键技术进行研究,包括数据源的获取、 领域本体库的构建、 全局本体库的构建、 实体对齐、 实体链接以及应用平台的搭建. 将不同领域知识库进行融合成一个知识图谱,旨在构建语义一致、 结构一致的多数据融合知识图谱,实现对不同领域内的知识进行查询和展示,从而提高了数据查询效率.
1 知识图谱构建过程
知识图谱构建是知识图谱得以应用发展的前提,涉及实体抽取和实体之间关系的建立,同时还需要很好地组织和存储抽取的实体与关系信息,使其能够被迅速的访问和操作[8]. 知识图谱构建过程通常可以分成两步: 知识图谱本体层构建和实体层的学习[5]. 本体层构建通常包含术语抽取、 同义词抽取、 概念抽取、 分类关系抽取、 公理和规则学习; 实体层学习则包含实体学习、 实体数据填充、 实体对齐和实体链接等.
知识图谱的构建方法通常有自顶向下和自底向上两种[2]. 所谓自顶向下的方法是指先构建知识图谱的本体,即从行业领域、 百科类网站及其它等高质量的数据源中,提取本体和模式信息,添加到知识库中; 而自底向上的方法是指从实体层开始,借助于一定的技术手段,对实体进行归纳组织、 实体对齐和实体链接等,并提取出具有较高置信度的新模式,经人工审核后,加入到知识图谱中. 然而,在实际的构建过程中,并不是两种方法孤立单独进行着,而是两种方法交替结合的过程. 本研究在构建多数据源的知识图谱时采用两种方法的结合,首先采用自顶向下的方式来构建本体库,然后采用自底向上的方式进行提取知识来扩展知识图谱.
基于多种数据源的融合技术,构建相应的知识图谱,具体过程如图1所示. 图1中是从多种不同的数据源,如各个领域中的结构化、 半结构化和非结构化数据,构建相应的领域本体库,然后将它们映射为全局本体库,接着对这些领域知识图谱通过知识获取和数据融合构造知识图谱,最后通过搭建相应的应用平台,方便对知识图谱进行查询与更新.
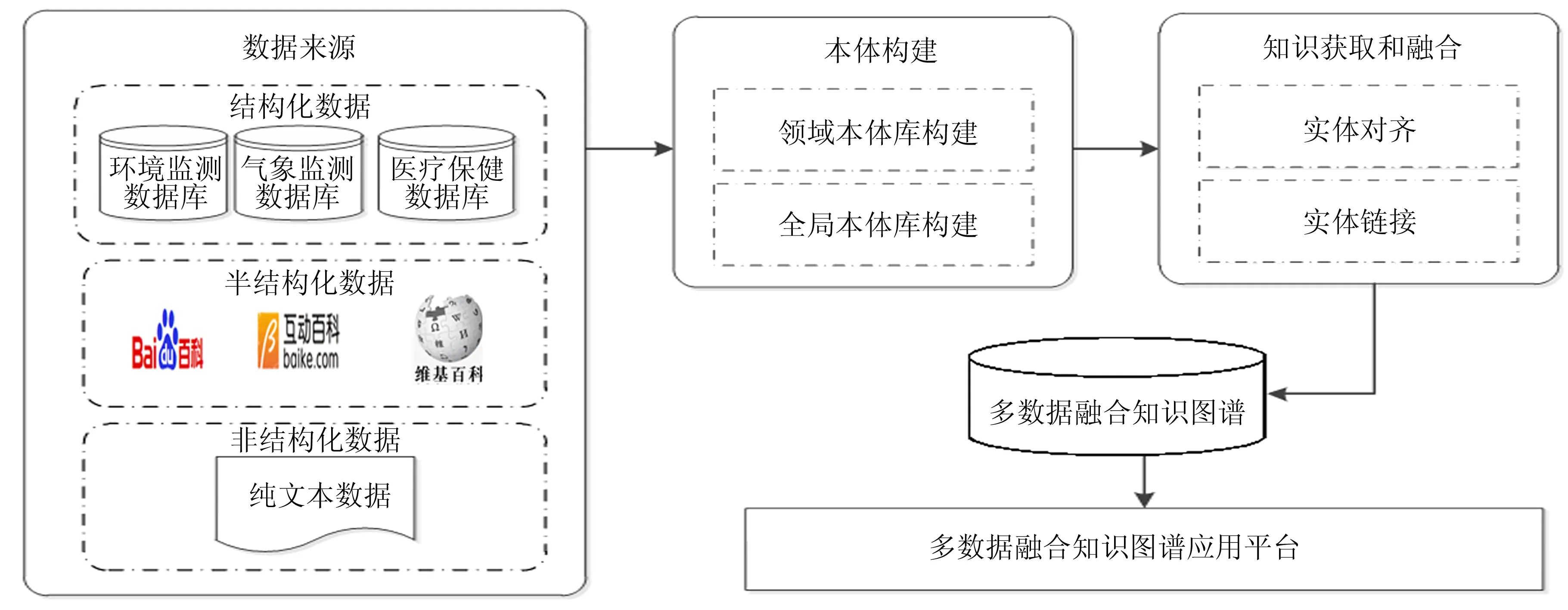
图1 多数据融合的知识图谱构建过程Fig.1 Knowledge graph based data fusion model
2 多数据源融合的知识图谱构建
为了能充分利用不同领域的知识,实现不同领域内数据快速查询,本研究在融合多种数据源的情况下,构建了多数据源的知识图谱. 首先针对不同领域构建各自领域本体库; 然后通过相似性检测、 冲突解决等规则,将不同领域本体映射成全局本体库; 最后为了对各个领域知识库的实体统一以及预测出缺失的实体,进行实体对齐和实体链接实验,丰富和拓展所构造多数据融合的知识图谱.
2.1 数据源
用于构建知识图谱的本体库数据源可以来源于结构化数据、 半结构化数据和非结构化数据,以及现有的一些通用知识图谱库等. 本研究用于构建本体库的数据源如下所示.
1) 结构化数据. 主要来源于关系数据库,如: 医疗保健数据库(national health insurance research database)、 环境监测数据库(environment)、 气象监测数据库(meteorological)等.
2) 半结构化数据. 主要来源于: 地理位置信息数据(geographic information data)、 病人病历卡数据(disease description)、 相关环境与气象数据(the knowledge about environment and meteorological)等.
3) 无结构化数据. 数据主要来源于文本资料的数据,如医疗保健的病历描述文件等.
除了上述用到的数据源外,还借助于百度百科、 互动百科和维基百科等网站数据,为后续扩充本体数据提供有效数据源.
2.2 本体库构建
本体(ontology)是对概念进行建模的规范,是描述客观世界的抽象模型,以形式化方式对概念及其之间的联系给出明确的定义[2]. 本体定义了知识图谱中的数据模式,因而,本体构建研究的成果能在很大程度上辅助知识图谱的构建[5]. 针对不同的应用领域和不同的需求,本体构建的方法也有所不同. 本研究利用OWL(web ontology language)从多种数据源中构建相应的领域本体库,然后通过映射成全局本体库.

图2 从关系数据中构造领域本体库过程 Fig.2 The structure of ontology construction from relational database
1) 领域本体库构建. 其主要数据源是来自于环境监测数据库、 空气污染检测数据库和医疗健保数据库. 除此之外,也利用相关领域的网站数据等. 下面重点介绍从关系数据库中获取领域本体库的过程,如图2所示.
首先,领域内的关系数据库是针对特定领域而创建的,该数据库包含了领域内的表达方法和具体应用的详细信息,因此,可以从领域的关系数据库中抽取出关系模式,分析关系数据库中表的信息和字段信息,建立相应的概念模型.
其次,由于关系模式包括表与字段之间的关系,以及表与表之间的联系,而本体库则是包括概念与概念之间的关系、 概念与属性间的联系. 因此,要利用一定的规则将关系模式映射为本体模型. 通过设计一系列转换规则,如: 将关系模式中的表名转换为本体中的概念名; 表与表间的关系转换为本体中的概念与概念的关系; 将关系模式中的字段名转换为本体的属性名等. 可以获得领域本体模型.
最后,对领域本体模型进行评估和校验. 该部分重点是对所构造的领域本体模型进行检验,查看是否满足本体库的构建原则,本体模型中的术语是否正确,本体模型中的概念及其关系是否完整等. 通过对本体模型评估后,可以建立领域内的本体库.
为了能详细解释上述过程,选取医疗保健数据库中的部分表转换成相应的本体概念及属性来进行描述. 关系数据库具有完整的数据模式,包含完整的表结构和完整性约束条件. 将数据库中的关系名转换为本体中的概念,部分字段名转换为本体中的属性,具体如下:

将字段名转换为属性名的OWL语言:〈owl:ObjectPropertyrdf:ID=“HospitalID”〉〈owl:DatatypePropertyrdf:ID=”PatientID”〉〈rdfs:domainrdf:resource=“#Doctor”/〉〈rdfs:rangerdf:resource=“#Hospital”/〉︙

将关系名转换为本体概念的OWL语言:〈owl:Classrdf:ID=“Patient”/〉〈owl:Classrdf:ID=“PediatricPatient”/〉〈owl:Classrdf:ID=“Doctor”/〉〈owl:Classrdf:ID=“Inpatient”/〉〈owl:Classrdf:ID=“Hospital”/〉︙
另外,为了扩充和完善领域本体库,需要对非关系型的数据进行采集和填充. 本研究对行业领域内的半结构化数据进行结构化处理,对相应百科网站通过网页爬虫技术获取相应的知识,并将半结构化数据转换成结构化数据,最后利用上述关系数据转换成本体的规则进行转换. 而对无结构数据,由于其知识覆盖度广,抽取难度较大,本研究采用了人工抽取的方法进行提取知识.
为此,根据各个领域的需求不同,构建了三个领域内的本体库,分别是: 环境监测领域本体库(environment),气候监测领域本体库(meteorological)及医疗保健领域本体库(medical).

图3 全局本体库构建过程Fig.3 The process of global ontology construction
2) 全局本体库构建. 为了能便于构建多数据融合的知识图谱,需要将多个领域内的本体库进行融合,构建全局本体库, 其过程如图3所示. 在上述构建的领域本体库基础上,通过相似性检测和冲突解决等规则,将多个领域的本体库融合在一起组成了全局本体库. 其步骤如下:
首先,对不同领域内的本体可能存在一些相同或相似的概念和属性的情况,采用相似性检测规则对它们进行检测. 如: 语义相似性检测、 概念相似性检测、 属性相似性检测、 数据格式相似性检测等. 通过这些相似性检测,能将不同领域内的相同或相似本体进行统一,但还不能解决它们之间的冲突.
其次,采用冲突解决规则对上面存在的相似概念或属性等问题进行解决. 通过冲突解决规则可以消除概念的歧义,剔除冗余和错误概念,从而保证全局本体库的质量. 主要是对上述存在相似的概念或属性进行消除,使其达到统一,并合并为全局本体.
最后,将剩余的领域本体经过冲突解决和实体消岐等处理,映射到全局本体库,与各个领域本体库相结合,从而实现全局本体的构建. 现阶段,本研究在全局本体库中共建立了35个概念和96个属性.
通过对上述三个领域本体库进行分析研究,发现在三个领域本体库中存在着一些相同的实体名. 因此,可以通过这三个领域本体库内相同的实体进行连接映射,融合成全局本体库. 比如: 环境监测领域本体库(environment)、 气候监测领域本体库(meteorological)及医疗保健领域本体库(medical)都有geographical(地理位置)和date(时间). 把这些相同的实体名通过相似性检测和冲突解决等过程,将它们映射成全局本体库中的实体,具体映射关系如表1所示.

表1 部分实体映射关系表
2.3 实体对齐
实体对齐(entity alignment)[9]也称为实体匹配或实体解析,是判断相同或不同数据集中的2个实体是否指向真实世界同一对象的过程. 实体对齐能够发现不同知识库中具有不同实体名称,但却代表着现实世界中同一事物的实体,将这些实体进行合并,且用具有唯一标识对该实体进行标识,最后将该实体添加到相应的知识图谱中. 如: “中国移动”和“移动通信”等不同实体名称,其可能都是表示“中国移动通信集团公司”这个实体,通过实体对齐可以将这些不同名称规约到同一个实体. 不同知识库的实体对齐过程如图4所示[9]. 即在给定不同的知识库,通过先验对齐数据以及调整参数和相关外部资料的作用下,进行实体匹配的算法计算,最终得到实体间的对齐结果.
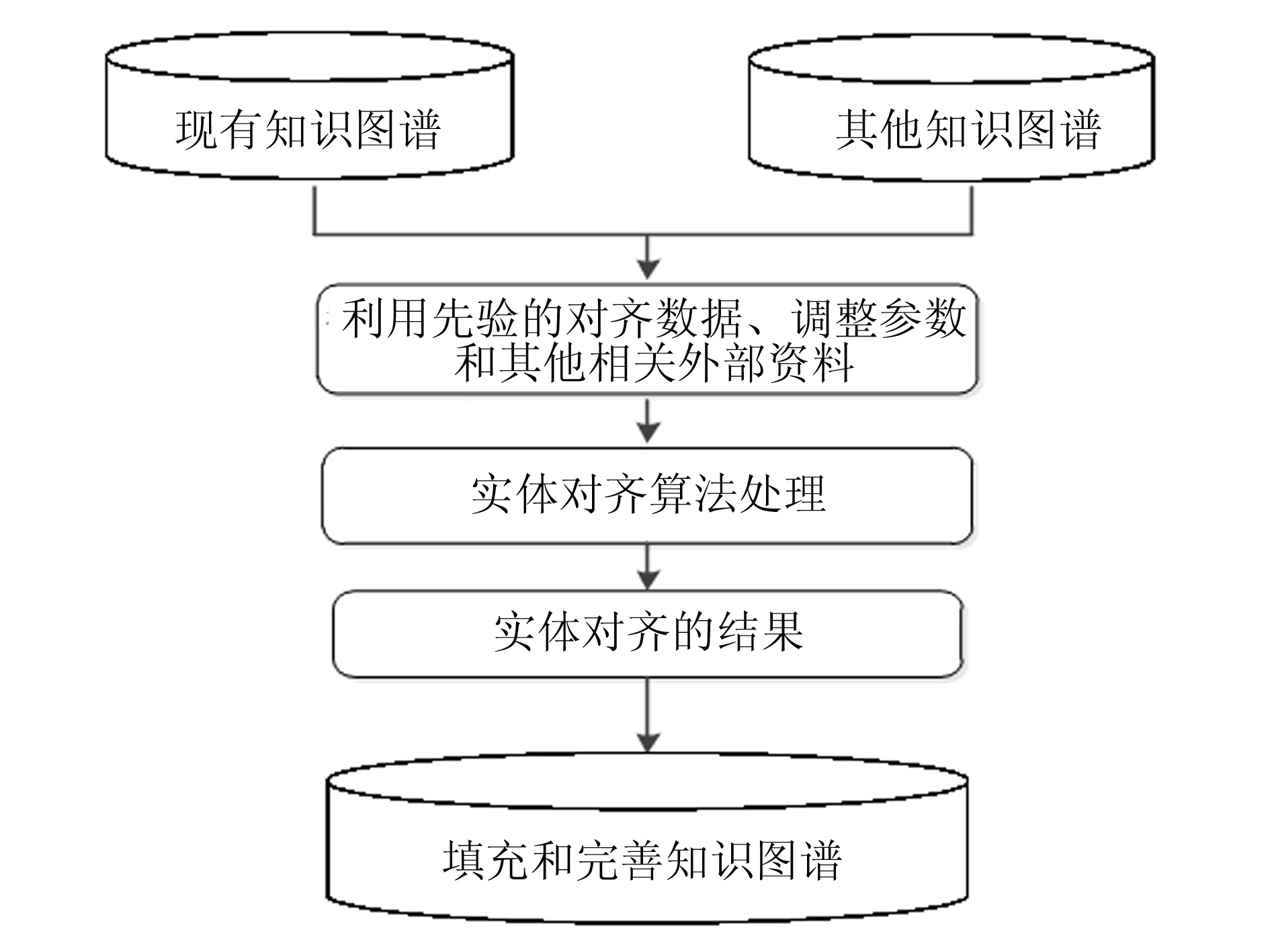
图4 不同知识库实体对齐过程 Fig.4 Process of entity alignment of different knowledge bases
虽然本研究在构建全局本体库时,针对不同领域内本体库的实体做了实体消岐处理. 然而,这里的实体对齐是为了丰富和拓展知识图谱,从现有的通用知识图谱及其相关的资料中,利用实体对齐方法,提取实体及实体间的关系来填充知识图谱.
本研究实体对齐的基本过程如下: 1) 对于开放链接数据及行业领域的百科数据中实体,进行提取得到了实体的同义名称集合; 2) 通过实体对齐的方法,将这些实体与上述构建的知识图谱中的实体进行匹配,把结果作为实体合并的候选实体集; 3) 将这些候选实体集中的实体,通过比对它们的上层概念,如果具有相同的上层概念,则将它们合并为一个实体.
采用基于相似性传播实体对齐方法[9-11],该算法将实体对齐问题看成是一个全局匹配评分目标函数的优化问题进行建模,属于二元分类问题,可通过贪婪优化算法求得其近似解[10]. 实验结果表明,其具有较高的准确率和召回率,分别为88.4%和74.6%.
2.4 实体链接
实体链接(entity linking)[12-13]是指从文本中抽取得到的实体对象,将其链接到知识图谱中对应的正确实体对象的操作[14]. 而实体链接预测是指在给定的知识图谱中,预测出缺失的实体间的关系,从而丰富和拓展知识图谱. 其基本思想是首先根据给定三元组的头(尾)实体和关系,从知识图谱中或其它相关文本数据中选出一组候选实体对象,然后通过实体链接预测算法,计算出正确的尾(头)实体,并将得到的三元组添加到相应的知识图谱中. 现阶段有关知识图谱实体链接预测算法较多(详见文[8, 15-17]),常用的有: 基于向量嵌入转换算法、 基于张量分解算法、 基于路径推理算法、 结合文本推理算法等.

图5 基于约束向量嵌入转换算法流程图Fig.5 The figure of embedding translation based on constraint
本研究提出了基于约束向量嵌入转换算法,获得较好的实体链接预测结果,算法流程如图5所示. 其基本思想是: 将知识图谱中的实体和关系,通过嵌入(embedding)方式投影到低维向量空间,并在向量空间中通过向量平移转换操作,计算头、 尾实体及关系在向量空间中的损失函数值,实现头尾实体的关系链接. 而基于约束嵌入转换算法,是在原有向量嵌入转换算法的基础上[18],增加了关系语义约束条件,使得所预测出实体间的关系要满足关系的语义类型. 如: 对于关系“出生于”,其头实体通常是人或动物,而尾实体通常是时间或地点.
通过对现有知识图谱的实体链接预测,利用HITS@10(%)(即排在正确实体前10%)的评价指标[18],本研究能达到92.8%的预测性能,同时对预测的结果进行正确性评价. 即对预测出新三元组的准确率进行评估,本研究结果能达到88.7%的准确率. 因此,本研究算法能适用于所构建知识图谱的实体链接预测,从而达到知识图谱的学习能力. 具体实验结果如表2所示. 表2是该算法在不同数据集上的实体链接预测的HITS@10的性能,以及该算法在不同数据集中的实体链接三元组预测准确率.

表2 HITS@10性能
3 应用平台搭建
知识图谱是利用信息可视化技术构建的一种知识之间的关系网络图[6]. 为了能更好展示和使用多数据源融合的知识图谱,本研究开发了一个知识图谱应用服务平台. 平台采用Neo4j作为图的存储数据库,以Bootstrap前端网页框架设计布局,并使用D3.js数据驱动的可视化套件实现实体与关系的动态展示效果. 该平台能够从全局层面对融合多个数据源的数据进行管理和使用. 主要功能有: 1) 融合多种数据源的基本信息,为用户提供高级数据搜索、 统计、 分析等服务; 2) 实体链接预测,对知识图谱中可能存在着缺失的实体与实体间的关系进行链接,实现丰富和拓展知识图谱; 3) 知识图谱实体关系网络的可视化,实现概念、 属性、 实例等多个维度的知识图谱展示,将知识图谱中的实体之间的关系通过可视化的形式展示出来.
本研究简单截取两幅图对平台功能进行简单说明. 图6表示该知识图谱平台中有关医疗保健方面的概念、 属性间的关系,其主要用于展示在医疗保健中各个概念节点的关系. 从图中可以便于查询某次的医疗保健活动中所涉及到相关联的一些实体和属性,如: 住院病历卡、 医疗服务、 处方细节、 以往治疗方案等. 而图7是表示统计分析展示,通过输入查询在某种气候情况下,某个医院的住院情况,可以展现出某个医院的住院情况分布. 这样可以合理地选择相应医院进行就诊,以免出现医院病房的短缺现象,同时,也可以分析在某种气候环境下,哪种疾病发生率较高,可以提醒人们注意当出现某种气候时,要适当地进行预防某种疾病的产生.
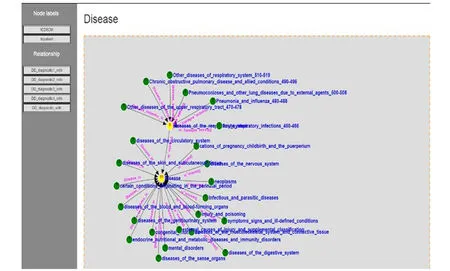
图6 医疗保健知识图谱展示

图7 某种气候环境下某地区某天的住院情况
4 结论
本研究提出一种基于多数据融合的知识图谱构建过程,并对整个过程中所涉及的方法加以描述,旨在构建语义一致、 结构一致的多数据融合知识图谱.
通过构建不同领域内的本体库,将不同领域的本体库,通过数据融合和映射技术构建全局本体库,实现各种数据源语义关系一致的知识图谱. 在实体对齐方面,总结了不同对齐方法,并描述实体对齐的过程,同时利用传统的基于相似性传播实体对齐方法,获得良好的实体对齐效果. 在实体链接方面,在前期研究工作基础上,提出了基于约束嵌入转换的预测推理方法,实验结果表明,所提出的方法能达到88.7%的预测准确率,取得较好的预测结果. 为了方便对数据查询及直观了解数据间的联系,搭建了知识图谱应用平台,在该平台上可以实现多数据的查询,提高了数据查询效率.
现阶段知识图谱的构建在我国还处于发展初期,许多技术及知识获取的算法还有待改善和发展. 本研究所构建多数据源融合的知识图谱还存在很多不足,比如构建知识图谱的数据源仅限定于某个地区的数据,应该寻求更多的数据源来扩展知识图谱; 如何建立知识图谱的自动更新机制; 如何维护和存储知识图谱等. 在下一步工作中,将收集更为广泛的数据源填充知识图谱,同时将进一步研究自动更新和存储知识图谱.
[1] PUJARA J, MIAO H, GETOOR L,etal. Knowledge graph identification[C]//International Semantic Web Conference. Berlin: Springer, 2013: 542-557.
[2 ]刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
[3] 肖仰华, 张可尊, 汪卫. 一种面向图书的阅读领域知识图谱构建方法: 103488724A[P]. 2014-01-01.
[4] 金贵阳, 吕福在, 项占琴. 基于知识图谱和语义网技术的企业信息集成方法[J]. 东南大学学报(自然科学版), 2014, 44(2): 250-255.
[5] 胡芳槐. 基于多种数据源的中文知识图谱构建方法研究[D]. 上海: 华东理工大学, 2015.
[6] 王巍巍, 王志刚, 潘亮铭, 等. 双语影视知识图谱的构建研究[J]. 北京大学学报(自然科学版), 2016, 52(1): 25-34.
[7] 鄂世嘉, 林培裕, 向阳. 自动化构建的中文知识图谱系统[J]. 计算机应用, 2016, 36(4): 992-996.
[8] 吴运兵, 杨帆, 赖国华, 等. 知识图谱学习和推理研究进展[J]. 小型微型计算机系统, 2016, 37(9): 2 007-2 013.
[9] 庄严,李国良,冯建华. 知识库实体对齐技术综述[J]. 计算机研究与发展, 2016, 53(1): 165-192.
[10] 徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J]. 电子科技大学学报, 2016, 45(4): 589-606.
[11] LACOSTE-JULIEN S, PALLA K, DAVIES A,etal. SIGMa: simple greedy matching for aligning large knowledge bases[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 572-580.
[12] 刘峤, 钟云, 李杨, 等. 基于图的中文集成实体链接算法[J]. 计算机研究与发展, 2016, 53(2): 270-283.
[13] SHEN W, WANG J, HAN J. Entity linking with a knowledge base: issues, techniques, and solutions[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(2): 443-460.
[14] LI Y, WANG C, HAN F,etal. Mining evidences for named entity disambiguation[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 1 070-1 078.
[15] NICKEL M, MURPHY K, TRESP V,etal. A review of relational machine learning for knowledge graphs[J]. Proceedings of the IEEE, 2016, 104(1): 11-33.
[16] 刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 247-261.
[17] 刘康, 张元哲, 纪国良, 等. 基于表示学习的知识库问答研究进展与展望[J]. 自动化学报, 2016, 42(6): 807-818.
[18] BORDES A, USUNIER N, GARCIA-DURAN A,etal. Translating embeddings for modeling multi-relational data[C]//Advances in Neural Information Processing Systems. Nevada:[s.n.], 2013: 2 787-2 795.
(责任编辑: 林晓)
Knowledge graph construction method based on multiple data sources
WU Yunbing1, YIN Aiying2, LIN Kaibiao3, YU Xiaoyan1, LAI K Robert4
(1. College of Mathematics and Computer Science, Fuzhou University, Fuzhou, Fujian 350116, China; 2. Zhicheng College, Fuzhou University, Fuzhou, Fujian 350002, China; 3. School of Computer and Information Engineering, Xiamen University of Technology, Xiamen, Fujian 361024, China; 4. Department of Computer Science and Engineering, Yuan Ze University, Taoyuan, Taiwan 32003, China)
To improve the application of multi-source data fusion, this study constructs a knowledge graph-based data fusion model. This model firstly constructed corresponding domain ontology for each special field, and then consolidated all domain ontology into a global ontology. After that, it retrieved and fused knowledge from the global ontology by entity alignment and linking methods. At last it built an application platform of knowledge graph with friendly interfaces to execute query and statistics, etc. Besides that, this model improved the result of entity aligning by adopting traditional similarity detection approach. And experiment results also demonstrated its good prediction accuracy by proposing a constraint based embedding model in entity linking process.
knowledge graph; ontology construction; data fusion; entity alignment; entity linking
10.7631/issn.1000-2243.2017.03.0329
1000-2243(2017)03-0329-07
2016-10-11
林开标(1980-),讲师,主要从事数据挖掘和人工智能方面研究,kblin@xmut.edu.cn
福建省中青年教师教育科研资助项目(JAT160077); 福建省中青年教师教育科研资助项目(JAT160658); 福建省科技计划资助项目(2016R0095); 福建省教育厅科技资助项目(JA14243); 对外科技合作与交流资助项目(E201402300)
TP391
A
