面向快递信息的个性化隐私保护研究
2017-06-05刘建昆康海燕
刘建昆,康海燕
(北京信息科技大学 信息安全系,北京 100192)
面向快递信息的个性化隐私保护研究
刘建昆,康海燕
(北京信息科技大学 信息安全系,北京 100192)
随着电子商务的高速发展,快递信息安全成为快递行业中面临的重要问题.目前,快递行业个人信息存在2种情况:一种是流通的快递单数据信息;另一种是快递数据库存储的数据信息(发布).针对后者的隐私信息泄露问题,提出了面向快递信息的个性化隐私保护方法.首先,在寄件时,客户选择敏感属性的敏感决策值;然后,快递企业根据敏感决策值计算敏感约束值;最后,根据敏感约束值对敏感属性进行概化处理.实验表明,相比于k-匿名方法,实现了个体选择隐私约束的权利,满足了个性化隐私保护需求,能够有效防止一致性攻击.
快递信息;隐私保护;k-匿名;个性化
随着电子商务的迅速发展,快递行业迎来了迅猛发展时代.快递行业是现代发展最快的服务业之一,改变了企业生产、运作方式和人们生活、消费模式.2015年,中国网络购物用户规模达到4.13亿,较2014年底增加5 183万人,网络零售交易额3.88万亿元[1],同比增长33.3%.同年,快递业务量达到140亿件,居世界第一,表明大量的个人隐私信息通过电商平台和快递单流动着.2015年10月,李克强总理主持召开国务院常务会议,推进“互联网+快递”,发展农村电商,确定促进快递业发展的措施[2].2015年11月,公安部等15部门为了整治寄递物流安全风险隐患,快递包裹实施实名制的措施[3],实名制的实施表明,快递公司的数据库将存储大量的个人隐私信息数据.近来不断出现快递信息隐私泄密事件,引发社会公众的信息危机.快递行业如何保证个人隐私信息不被泄露,受到人们的质疑.因此,为了快递行业的可持续发展,快递信息的隐私保护研究显得十分迫切.
电子商务的发展使大量的数据存在于网络上,无害的数据被大量收集后,也会暴露个人隐私[4].Mayur等[5]研究了为保护电子商务中客户隐私实施的政策及它的改进.Mubarak等[6]通过调查隐私问题、数据安全和探索因素更深入地理解客户的感知隐私和安全,分析了电子商务中隐私设计和客户感知隐私和安全这2个方面.目前,国内对于快递行业中客户的隐私保护措施层出不穷,多方面体现出国家和电商保护个人隐私安全的关注和重视.郝增亮等[7]在对快递服务中消费者网络购物信息泄漏危害分析的基础上,从企业内外及宏观和微观等多个角度,探讨了民营快递企业消费者信息泄漏的成因,针对问题根源提出了防范消费者信息泄漏风险的措施.肖锭[8]在对快递行业客户信息泄露主要内因进行分析的基础上,谈到了快递行业客户信息泄露主要因素,提出了防范消费者信息泄露风险的措施.钱莹[9]从当前快递单泄漏顾客个人信息所引发的安全性问题,提出了相应的对策.韦茜等[10]提出了一种新型k-匿名模型对快递信息进行匿名处理,此方法随机打破记录中属性值之间的关系来匿名数据.她们还利用RSA算法在快递员在递送包裹阶段对用户的信息进行保护.
在电子商务环境下,本课题通过对快递业务流程中所涉及的电子商务中网商、快递企业、个人等引起的隐私信息泄露的多方面进行分析,从中总结快递过程中隐私信息泄露的问题.现阶段,在技术方面,快递隐私信息泄露主要存在2种情况:根据数据信息存在的形式,快递信息分为数据库存储信息和流通的数据信息,第1种情况,数据库存储信息,电商和快递企业都拥有存储客户信息的数据库.第2种情况,流通的隐私信息泄露,即快递单上的信息(包括姓名、地址和手机号等).针对这2种情况对快递信息进行隐私保护研究,防止个人隐私信息泄露.以上总结了快递信息隐私泄露的问题,为保护客户的个人隐私信息,从技术方面对快递信息隐私泄露问题进行保护,有以下2种设想:1)基于k-匿名技术的快递数据库信息隐私保护;2)基于加密QR码的快递单信息隐私保护.电子商务下的快递业务流程如图1.
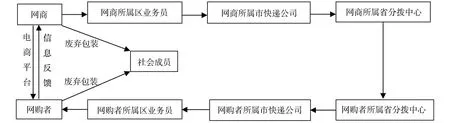
图1 电子商务下的快递业务流程Fig.1 Express business process under electronic commerce
本文主要针对快递中心数据库信息隐私泄露问题进行研究,提出了个性化k-匿名的方法,从客户和企业的角度,均衡两者的意愿对客户的隐私信息进行保护.
1 基于个性化k-匿名的快递数据库信息隐私保护方法
1.1 k-匿名模型
数据匿名化所处理的原始数据,一般是数据表格的形式:表中任意一条数据信息对应1个个体,一列数据信息对应个体一个属性,且每个属性包含多个不同的属性值.原始数据属性的划分,通常有3类:标识符、准标识符和敏感属性[11].
k-匿名模型[14]要求发布的任何一条数据l,在准标识符上至少有k-1条相同的属性值数据信息,是以准标识符属性损失一部分信息为代价,从而实现个人隐私信息保护.k-匿名模型在某种程度上,不仅保护了个人的隐私信息,而且也保护了数据的科研性,但是若用户具有准标识符和敏感信息关联的先验知识,就会加剧敏感属性的信息泄露.针对敏感属性信息泄露问题,原始的k-匿名没有相应的保护机制,且也没有考虑敏感属性的敏感程度.
已有的快递信息隐私保护是针对收件人隐私信息而言,为了更好地了解已有的保护方法存在的不足,先对快递流程进行分类,将快递流程分为商家对客户(B2C)和客户对客户(C2C)2类.B2C的特点是以电商平台为媒介,快递流程环节多,涉及人员增加,客户隐私信息泄露风险大.C2C的特点是以电商平台或快递企业在线平台媒介,快递流程环节相对B2C较少,涉及人员也较少,客户隐私信息泄露风险小.现有的方法没有具体分类处理客户的隐私信息,针对电子商务平台泄露客户隐私信息没有考虑全面.快递数据库涉及的主要信息:快递单号、身份证号、邮编、姓名、手机号、地址及寄递物品的名称、性质、数量等,B2C和C2C快递信息分类见表1.

表1 B2C信息表Tab.1 B2C information table
表2列出了快递单上客户的基本信息,快递单号以申通为例,申通单号一般由12位数字组成,目前常见以268*、368*、468* 等开头,其中收件人手机号、住址都设定为敏感信息即多敏感属性,寄件人和收件人家庭详细地址不具体列出.
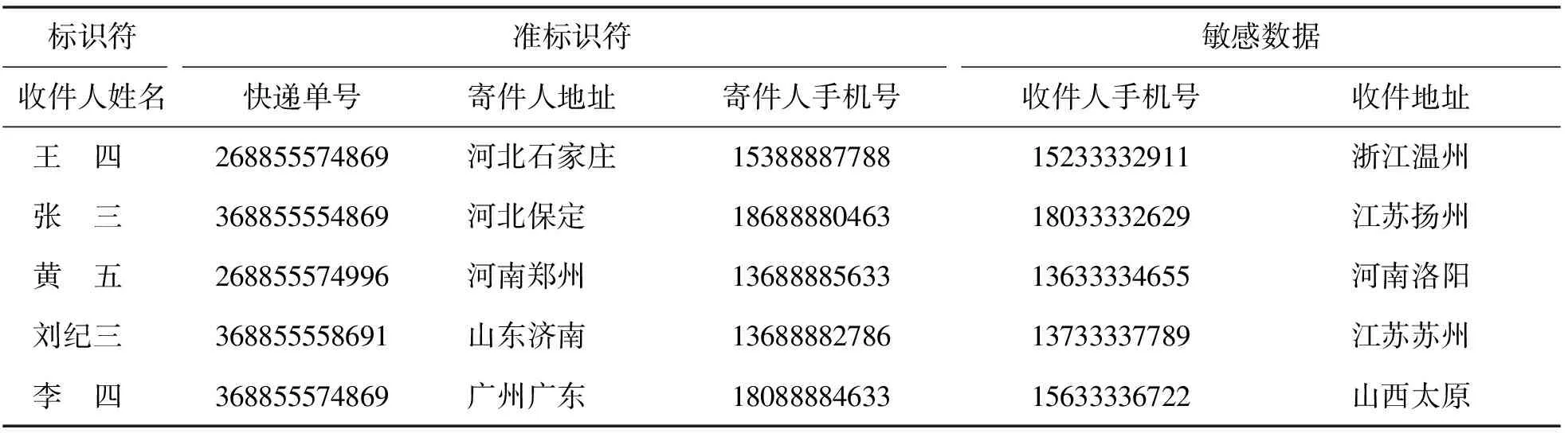
表2 快递单基本信息Tab.2 Express information
表3中的*代表任意信息.由于k-匿名模式的简洁性和适用于多种算法的属性,使它在数据发布中变得非常流行.若用一般的k-匿名进行保护,只能对快递单号、身份证号、邮编、姓名等隐私信息进行有效保护,客户的敏感信息,如手机号、地址等不能有效地防止泄露.
1.2 个性化k-匿名相关概念
针对已有的个性化隐私保护技术不能同时兼顾个体隐私保护需求和敏感属性值的个性化隐私保护两方面的要求,本文主要研究能够同时兼顾两者的个性化k-匿名.为更好地准确描述,给出以下相关定义.
定义1 数据提供者:给指定数据库提供了数据记录的个体.

表3 采用一般k-匿名的示例Tab.3 General k-anonymous sample
定义2 数据发布者:将收集的数据向公众发布的实体.
定义3 非数值敏感属性数值化:将数据记录条中敏感属性值的描述型词句转化为有指定意义的数值称为非数值敏感属性数值化.
定义4 敏感属性决策数值:数据提供者决定其提供的数据信息中敏感属性值的敏感程度,且敏感程度高低由决策数值表示,称为敏感属性决策数值,由z来表示.决策数值采用数值来表示,数值越大,敏感度越强;反之,数值越小,敏感度越低.
把原始数据集看作一个q,q中的敏感属性s的取值集合记作{si,i=1,2,…,n}的敏感属性决策值z.当z=1,表示个体i认为自身的敏感属性值敏感度高,要求采取高度的隐私保护;z=-1,表示个体i认为自身的敏感属性敏感度低,不用采取隐私保护;z=*或z=0,表示个体i不确定敏感属性敏感度没有给出相应的敏感属性决策值或认为自身的敏感属性敏感度一般.
定义5 敏感属性个性化隐私保护的正域、负域和边界域:按照粒化理论,对论域Q进行粒度划分,将满足敏感属性决策值z=1的数据集作为个性化隐私保护正域;将满足敏感属性决策值z=-1的数据集作为个性化隐私保护负域;将满足敏感属性决策值z=0或z=*的数据集作为个性化隐私保护边界域.
定义6 敏感属性隐私保护约束值:根据数据提供者的敏感属性决策值,数据发布者来决定发布数据中敏感属性值出现频率的约束度,用D来表示.
对于z=0或z=*的个体,用50%的概率要求保护个体的隐私信息,因为其自身对敏感属性值的重视程度一般或不能确定,则敏感属性值si的敏感属性隐私保护约束值Di的计算方法定义为
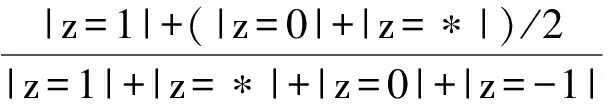
(1)
定义7 敏感属性概化:用函数f来表示敏感属性概化.把敏感属性值域S内的数值st,且st∈S′,用集合S′替换,即f(st)=S′,S′∈S.
用包含st概括性更高的概念值代替st的过程称为对敏感属性值的概化.例如,“河北省”是比“沧州市”、“邢台市”、“保定市”等更为广泛的概念值.
显然,敏感属性值概化的目的是为了提高数据的不确定性,不同层的概念之间自然形成了一种概念结构层次树,所以可以用上一级代替下一级来实现敏感属性值概化的目的.图2是一种概念层次结构树的示例.

图2 地址泛化树Fig.2 Address generalization tree
1.3 个性化k-匿名算法设计
本文通过个性化k-匿名技术对快递数据库进行隐私保护,即体现客户(收件人和寄件人)对敏感属性同一敏感值的不同保护需求,这是局部的“个性化”;又体现企业对敏感属性的不同敏感值保护程度的差异性,这是整体的“个性化”,实现了根据不同的匿名需求进行差异化的隐私保护,整个过程不仅考虑了数据提供者的要求还满足了数据发布者的需求,保证了数据的可用性.
和已有方法划分敏感属性值不同,根据快递信息,把一条快递信息一分为二进行保护.表4列出了快递数据库中收件人的基本信息,其中寄递物品的名称、性质、数量暂不考虑,收件人手机号、住址都设定为敏感信息即多敏感属性.
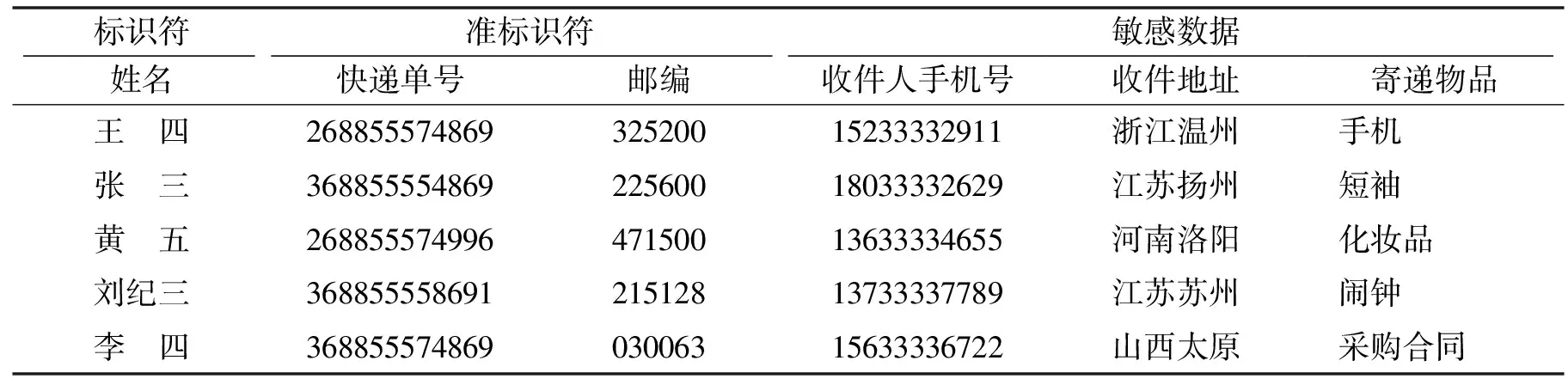
表4 快递数据库收件人基本信息Tab.4 Express database recipient information
表5列出了快递数据库中寄件人的个人信息,其中寄件人性别和年龄是在身份证里提取的信息,寄件人的手机号、住址都设定为敏感信息即多敏感属性.

表5 快递数据库寄件人基本信息Tab.5 Express database sender information
快递数据库采用个性化k-匿名策略实现数据匿名化的流程见图3,根据整体快递业务流程,对客户的隐私信息分2个步骤进行隐私保护.根据客户(收件人和寄件人)选择的敏感属性决策值计算敏感属性值出现频率的约束度,再根据敏感约束值对客户的敏感信息进行概化,最后,对匿名处理后的数据进行发布.
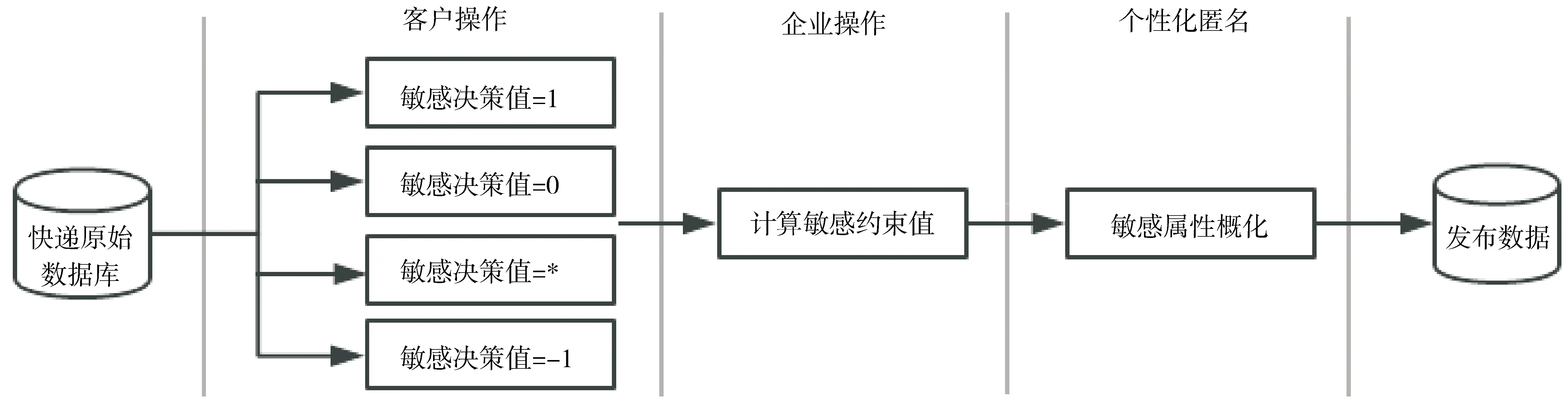
图3 个性化匿名流程Fig.3 Personalized anonymity
对于要进行隐私保护的数据集,根据敏感属性决策值对数据集的敏感属性进行个性化隐私保护空间划分,这样隐私敏感属性就有了准确的保护级别:隐私保护负域的级别最低,隐私保护边界域隐私保护级别比较高,而隐私保护正域隐私保护级别最高.
算法描述:
输入,T敏感属性值概念层次树,Q待匿名组,匿名约束k,敏感值频率约束上限值α.
输出,匿名后的组.
步骤1 将数据集的敏感属性聚类划分为3种个性化隐私保护空间.
步骤2 根据组内敏感属性的决策值计算敏感约束值d(st).
步骤3 计算组内敏感属性的概率p,
叶子节点
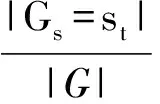
(2)
中间节点

(3)
步骤4 优先深度遍历T,当遍历到结点st时,
1)若为叶子节点
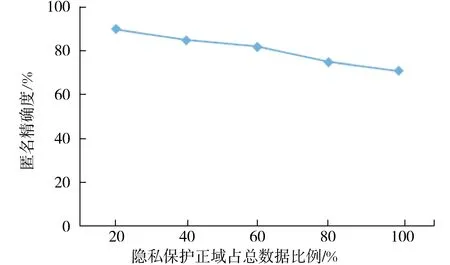
如d(st) 2)若非叶子节点(中间节点) 若子节点均未泛化,继续遍历.否则把当前子树作为一个叶节点,转1). 步骤5 返回泛化结果,否则若根节点需泛化则返回空. 实验对个性化k-匿名进行了分析和比较,分别从匿名精确度和披露风险两方面来比对.在实验中,通过数据集的大小和改变约束度的强弱来评估、检查算法的效用. 2.1 实验环境 硬件环境:处理器Intel(R) Core(TM) i3-2310M,内存2 GB.实验平台:Windows 7(×64),开发环境:Eclipse+MySQL.实验数据:顺丰快递客户资料的数据集,总共5 000条记录. 2.2 测试与分析 测试(正域下的精确度实验):采用个性化的方式对实验数据进行发布,按照不同的准标识符属性维度和隐私保护正域比例对发布后数据集进行查询,其结果见图4,图5. 图4 准标识符属性个数对精确度的影响Fig.4 Accuracy versus the quasi-identifier dimension 图5 正域占数据集比例对精确度的影响Fig.5 Accuracy versus the proportion of positive region 测试结果分析:分析图4可知,准标识符属性的个数越多,正域比例相同情况下,对算法的精确度影响越大,信息损失量相应的增加.图5表示准标识符属性的个数为2时,个性化隐私保护正域即个体认为自身的敏感属性值敏感度高的数据集所占总数据集比例的变化对个性化k-匿名算法精确度的影响,分析得出,当隐私保护正域所占比例变化时,个性化k-匿名仍能达到较高的匿名精度,这是由于算法执行过程中对隐私保护正域和边界域的数据在未能达到个性化k-匿名时,可以从下一级的隐私保护域中得到相应的数据来进行数据域的扩充,从而确保实现个性化k-匿名算法. 披露风险度量:攻击者通过发布的数据集信息与其他相关背景知识链接后能够得到隐私信息的概率,表示了隐私信息披露风险的高低. 数据持有者为0,对于数据q∈Q,敏感属性值是s,令Sp表示“在背景知识K下攻击者获得关联关系(o,s)”的事件,那么隐私信息披露风险,r(s,K)为 r(s,K)=Pr(Sp) (4) 传统的匿名保护方法中,数据发布者对数据集设定阈值α∈(0,1),要求所有敏感数据的敏感属性值的隐私披露风险不能大于α,则称α为此数据集的披露风险.使用个性化算法后,则要对每一条记录设定对应的隐私信息披露风险值.根据敏感属性隐私保护约束值的定义,要求等价类数据集中任一敏感属性值si出现的频率都不超过αi,其中αi=1-di,则个性化的隐私信息披露风险可定义为向量α=(α1,α2,…,αn). 快递引起的信息泄露越来越受到人们的关注,如何保护网购人群的个人隐私安全再次引起人们的重视.本文在快递数据库信息匿名中,提出了面向快递信息的个性化隐私保护方法.实现了个人决定隐私约束的权利,满足个性化隐私保护定制的需求,能够有效防止一致性攻击,保护了信息的隐私性.但是对于快递隐私信息,不仅快递数据库信息需要保护,而且对于快递单隐私信息的保护也至关重要.快递单信息随着快递业务流程的递延有可能产生新的风险,且风险会随流程而累积.因此,下一步工作将处理快递单隐私信息泄露问题. [1] 中国互联网络信息中心.2015年中国网络购物市场研究报告[EB/OL].(2016-06-22)[2016-06-30]http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/dzswbg/201606/P020160622616579052961.pdf.. [2] 国务院.部署加快发展农村电商促进快递业发展[EB/OL].(2015-10-14)[2015-10-21].http://money.163.com/15/1014/18/B5TJ062H00252G50.html. [3] 公安部.全面落实寄递物流活动实名登记[EB/OL].(2015-10-22)[2015-10-25].http://news.sina.com.cn/c/nd/2015-10-22/doc-ifxizwsi5513351.shtml.. [4] VIKTOR M S,KENNETH C.Big Data:a revolution that will transform how we live,work,and think[M].Boston:Houghton Mifflin Harcourt,2013. [5] MAYUR S D,THOMAS C R,KIRAN J D.E-commerce policies and customer privacy[J].Information Management & Computer Security,2003,11(1):19-27.DOI:10.1108/09685220310463696. [6] MUBARAK A I,ZYNGIER S,HODKINSON C.Privacy by design and customers’ perceived privacy and security concerns in the success of e-commerce[J].Journal of Enterprise Information Management,2013,26(6):702-718.DOI:10.1108/JEIM-07-2013 -0039. [7] 郝增亮,张燃燃.民营快递服务中消费者信息泄漏风险与防范研究[J].物流技术,2012,31(9):55-63.DOI:10.3969/j.issn.1005-152X.2012.05.018. HAO Z L,ZHANG R R.Study on risk of consumer information disclosure of private express services and its prevetion[J].Logistics Technology,2012,31(9):55-63.DOI:10.3969/j.issn.1005-152X.2012.05.018. [8] 肖锭.快递行业客户个人信息安全防范研究[J].物流科技,2013,36(5):61-63. XIAO D.Safe guard research on customer information in express industry[J].Logistics Sci-Tech,2013,36(5):61-63. [9] 钱莹.电子商务背景下快递业的信息泄漏问题及对策探究[J].电子技术,2013,42(7):27-29.DOI:10.3969/j.issn.1000-0755.2013.07.009. QIAN Y.Information disclosure problem and countermeasures in express industry under electronic commerce background[J].Electronic Technology,2013,42(7):27-29.DOI:10.3969/j.issn.1000-0755.2013.07.009. [10] 韦茜,李星毅.基于K-匿名的快递信息隐私保护应用[J].计算机应用研究,2014,31(2):555-557.DOI:103969/j.issn.1001- 3695.2014.02.056. WEI Q,LI X Y.Express information protection application based onK-anonymity[J].Application Research of Computers,2014,31(2):555-557.DOI:103969 /j.issn.1001-3695.2014.02.056. [11] 周水庚,李丰,陶宇飞,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-861.DOI:10.3724/ SP.J.1016.2009.00847. ZHOU S G,LI F,TAO Y F,et al.Privacy preservation in database applications:a survey[J].Chinese Journal of Computer,2009,32(5):847-861.DOI:10.3724/ SP.J.1016.2009.00847. [12] 韦茜,王晨,李星毅.基于RSA算法的快递信息隐私保护应用[J].电子技术应用,2014(7):58-60.DOI:10.16157/j.issn.02587998.2014.07.029. WEI Q,WANG C,LI X Y.Express information privacy protection application based on RSA[J].Application of Electronic Tech-nique,2014(7):58-60.DOI:10.16157/j.issn.02587998.2014.07.029. [13] 严璞.基于手机二维码的物流管理信息系统设计与实现[D].武汉:华中科技大学,2011. YAN P.Design and implementation of a logistics management system based on 2D barcode[D].Wuhan:Huazhong University of Science and Technology,2011. [14] SWEENEY L.K-anonymity:a model for protecting privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge- Based Systems,2002,10(05):557-570. [15] 杨晓春,王雅哲,王斌,等.数据发布中面向多敏感属性的隐私保护方法[J].计算机学报,2008,31(4):574-587. YANG X C,WANG Y Z,WANG B.Privacy preserving approaches for multiple sensitive attributes in data publishing[J].Chinese Journal of Computers,2008,31(4):574-587. [16] 兰丽辉,鞠时光,金华,等.数据发布中的隐私保护研究综述[J].计算机应用研究,2010,27(8):2823-2827.DOI:10.3969/j.issn.1001-3695.2010.08.004. LAN L H,JU S G,JIN H.Survey of study on privacy-preserving data publishing [J].Application Research of Computers,2010,27(8):2823-2827.DOI:10.3969/j.issn.1001-3695.2010.08.004. [17] 刘明,叶晓俊.个性化K-匿名模型[J].计算机工程与设计,2008,29(2):282-286. LIU M,YE X J.Personalizedk-anonymity[J].Computer Engineering and Design,2008,29(2):282-286. [18] 王平水,王建东.匿名化隐私保护技术研究综述[J].小型微型计算机系统,2011,32(2):248-252. WANG P S,WANG J D.Survey of research on anonymization privacy-preserving techniques [J].Journal of Chinese Computer Systems,2011,32(2):248-252. (责任编辑:孟素兰) Research on personalized privacy protection for express information LIU Jiankun,KANG Haiyan With the rapid development of e-commerce,express information security has become an important issue.Currently,there are two kinds of personal information in the express industry,one stored in the express sheet,the other stored in the express database.The leakage problem of express database privacy information is discussed in the paper.This paper presents a method of personalized privacy protection for express information.First,in mailing,customers choose sensitive decision value.Then,according to the sensitive decision value express company calculates a sensitive constraint value.Finally,it generalizes the sensitive attribute based on the sensitive constraint values.Compared to thek-anonymous method,experiments here show that the method realizes the right of individuals to determine the privacy constraints,meet the needs of personalized privacy protection and effectively prevents the consistency of attacks. express information;privacy protection;k-anonymity;personalized 2016-12-06 国家自然科学基金资助项目(61370139);北京市社会科学基金项目(15JGB099);实培计划科研项目 刘建昆(1990—),女,河北石家庄人,北京信息科技大学在读硕士研究生,主要从事物流信息安全方向研究. E-mail:1543627085@qq.com 康海燕(1971—),男,河北石家庄人,北京信息科技大学教授,博士,主要从事网络安全与隐私保护研究. E-mail:kanghaiyan@126.com 10.3969/j.issn.1000-1565.2017.03.012 TP391 A 1000-1565(2017)03-0294-082 实验与分析

3 总结
(Department of Information Security,Beijing Information Science and Technology University,Beijing 100192,China)
