面向Redis的数据序列化算法研究
2017-06-05孙杜靖李玲娟
孙杜靖,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210003)
面向Redis的数据序列化算法研究
孙杜靖,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210003)
为了解决实时计算中半结构化和非结构化数据的存储问题,借助内存数据库Redis可以存储键值型数据和支持全内存运算的优势,结合文件序列化、图像序列化、JSON序列化和Java对象序列化技术,设计了面向Redis的半结构化和非结构化数据的序列化算法。该序列化算法不仅解决了半结构化和非结构化数据无法直接存入Redis的问题,而且由于在序列化过程中实现了对这些数据的深拷贝,使得反序列化可以完美地还原初始数据。此外,序列化过程还支持通过加解密来保障数据安全。基于Storm平台的实验结果表明,所设计的序列化算法快速、有效且性能稳定。在海量数据实时计算中,无论使用哪种开发语言,将该算法与Redis数据库结合,既能利用Redis带来的高读写效率,又能存储任何半结构化和非结构化数据对象而无需重复开发代码。
Redis;序列化;半结构化;非结构化;Storm
0 引 言
大数据时代的到来使得半结构化数据、非结构化数据迅猛增长,而处理和存储这些数据的需求也日益增长。传统的关系型数据库只能存储结构化数据,并且对于高并发的数据写操作、海量数据的存储和快速查询以及服务器的横向扩展[1]显得无能为力。为了解决这些问题,NoSQL[2](Not Only SQL)技术应运而生。NoSQL主要分为四类:键值(Key-Value)存储数据库、列存储数据库、文档型数据库和图形数据库。键值存储数据库使用哈希来构建数据库,列存储数据库善于分布式存储,文档型、图形数据库顾名思义在文档型、图数据处理方面优势明显。
Redis(Remote Dictionary Server)[3]就是NoSQL中属于键值存储数据库的一个产品,并且是一个内存型数据库,全内存运算和存储使其在高并发的操作下仍能保持高性能读写,是已知性能最快的Key-Value数据库[4]。Key-Value模型的内存数据库,支持多种语言接口,如C++、C#、Java、JavaScript、Python等。Key-Value数据库利用哈希表维护Key值到具体数据(Value)的映射,通过Key值可以方便高效地查询数据[5]。Redis通过缓存数据库查询结果,减少对硬盘的访问次数,其缓存数据库全部加载在内存中进行操作,定期通过异步快照或者日志操作将数据库数据flush到硬盘上进行保存。因采用纯内存操作,每秒可以处理超过10万次读写操作,Redis性能非常高。Redis还有其他一些优势,比如提供了丰富的数据结构、支持主从复制、完善的持久化机制等等。
实时计算中需要频繁读取数据,Redis通过访问缓存数据库读取数据,可以保证计算过程中读取需求的实时响应、数据库数据的实时更新,因此Storm[6]等实时计算平台借助Redis键值存储和内存操作的优势将能够更好地完成流数据的实时处理任务。但是,采用全内存的Key-Value存储形式,Redis虽然能满足实时处理的需求,却不能直接存储和处理大量半结构化及非结构化数据,而这些数据是Storm等流式实时计算平台必须面对的。
为此,设计了面向Redis的序列化算法,并通过在Storm平台上的实现结果,证明了该算法在保证Redis高性能读写的前提下,解决实时计算中半结构和非结构化数据的存储问题。
1 面向Redis的数据序列化算法设计思想
如上所述,要充分利用Redis的优势,需要解决Redis作为键值型数据库不能直接存储和处理Storm等流式实时计算平台必须面对的半结构化及非结构化数据的问题。为解决这一问题,可以利用Redis能够存储二进制流的特性,先将半结构化及非结构化数据进行序列化,然后存入Redis中,读取后再进行反序列化,使Redis存储各种数据成为可能。基于此思路,设计了面向Redis的序列化算法,该算法考虑了半结构化数据、非结构化数据和需要保密的数据。非结构化数据的序列化包括:采用文件流的序列化和图数据序列化;半结构化数据的序列化包括:采用JSON[7]的序列化和采用Java对象的序列化。
图1给出了算法的总体思想。

图1 面向Redis的半结构化及非结构化数据序列化
数据发送端将半结构化或非结构化数据先序列化成二进制流或JSON字符串,如有敏感数据,可以将其加密,然后存入Redis数据库;数据更新时,以半结构化数据为例,Value1值会随之改变,但是存入的键Key1值不变,即Redis数据库中存入的Value1值也是实时更新的,如果数据消费者想要查看此半结构化数据,可通过事先约定好的键Key1值来获取数据,如曾经加密过,则需解密;然后将获得的二进制流或JSON字符串进行反序列化,得到原始数据。由于Redis数据库中存入的数据是实时更新的,数据消费者获取的数据也是最近存入的数据,对于实时更新的半结构化数据只采用一个KEY值进行存储的原因有三:一是通信双方可以事先规定好KEY值,无需频繁修改;二是Redis为内存型数据库,读写速率快,完全可以支持数据的实时更新和实时读取;三是若采用不同时刻不同KEY值,在实时计算中,会迅速占满内存,使Redis可能无法再存入新的数据。
2 面向Redis的数据序列化算法描述
2.1 非结构化数据的序列化
非结构化数据即为不方便用传统数据库二维逻辑表来存储的数据,包括文档、文本、图像、音频、视频等等。传统数据库通过创建一个三字段(编号number、内容描述varchar(1024)、内容blog)的表来对其进行索引,需要的人工参与量比较大,面对海量非结构化数据的存储与检索时,该方法显然不可能在较短时间内将其整理入库,数据的价值也无法很好地发挥。所设计的基于Redis的数据序列化算法采用将非结构化数据进行序列化后存入内存数据库Redis中的方案,能很好地解决此类问题,具体包括采用文件流的序列化和图数据序列化。
1)采用文件流序列化非结构数据。
对非结构化数据序列化分为两个过程:序列化和反序列化,对应的方法分别是writeObject()和readObject()。
(1)writeObject():将非结构化数据A序列化(序列化过程)。
输入:非结构化数据A,可以是文档、图像、音频、视频等等,路径P
输出:字节数组
步骤为:
①while(A更新一次)
②将A写入到底层输入流A';
③通过文件输出流将A'以字节流的方式保存到指定路径P;
④endwhile
(2)readObject():将指定路径中的对象转化为原始非结构化数据(反序列化过程)。
输入:路径P
输出:原始非结构化数据A
步骤为:
①将路径P中的对象读入原始字节流A';
②从输入流中读取数据对象类数据A';
③将A'转换成抽象Object类A;
④returnA
数据发送方通过writeObject()函数将非结构化数据序列化,然后将序列化的结果作为value存入Redis的某一路径下,数据接收方先根据数据发送方存入的key取出相应的字节流,然后通过readObject()方法,将字节流反序列化为抽象类,而原始数据类型可能是文档、图像、音频或视频,反序列化后格式不变,可将其下载到某个路径下查看,如若知道其为文档,可以将其向下转型成文件类,直接进行其他数据处理。
2)对图数据的序列化。
图像是非结构化数据的一种,视频、图像的实时计算处理过程中需要对大量照片进行存储、计算。在线系统中,在线数据的备份和恢复和对原始数据进行测试需要使用到快照[7-8],而快照由于其实时更新,并且需要被不断读取和计算,对其进行存储并保证其能被快速读取显得尤为重要。由于图数据使用频繁,频繁的文件读写会增加时间开销;另一方面,图数据占用内存过大时,所涉及的内存消耗和网络传输会很大,为了避免文件读写以减少时间开销、内存消耗和网络传输,采用如下的图像序列化方案。该方案分为两个过程:序列化和反序列化,对应的方法分别是writeImage()和byte2image()。
(1)writeObjectwriteImage():将图像转化成字节数组(序列化过程)。
输入:实时更新的某张图像A
输出:字节数组
步骤为:
①while(A更新一次)
②将图像A以某种格式(如png)写入内存;
③字节输出流捕获内存缓冲区的数据A',转换成字节数组B;
④endwhile
⑤returnB
(2)byte2image():将从Redis读取的字节数组B转化为图像(反序列化过程)。
输入:字节数组B
输出:原始图像A
步骤为:
①将字节数组B写入图像文件输出流中;
②输出流探测图像格式,并调用对应的插件进行解码,得到原始图像A;
③eturnA
数据发送方通过writeImage()方法将图像序列化,然后将序列化的结果作为value存入Redis,数据接收方先根据数据发送方存入的key取出相应的二进制流,然后通过byte2image()方法,将二进制流反序列化为图像,直接进行数据处理。
2.2 半结构化数据的序列化算法
半结构化的数据有一定的结构性,但结构变化很大,OEM[9](Object Exchange Model)是它的典型代表。由于其结构性,需要了解数据内部细节,因而不能将其看成非结构化数据,像2.1节那样将数据简单组织成一个文件;又因其数据结构变化大,也不能将其按照结构化数据处理方式存入二维表。设计了两种方法将其序列化后存入Redis数据库,一种是采用JSON(JavaScript Object Notation)数据交换格式,另一种是利用Java对象序列化技术。
1)采用JSON序列化半结构化数据。
JSON是一种轻量级的数据交换格式,是基于JavaScript Programming Language,Standard ECMA-262 3rd Edition-December 1999的一个子集。它易于机器解析和生成,因而用于在不同的编程语言之间交换数据,比如JavaScript和Java、C#间交互。
JSON主要有两种结构:对象和数组。
对象:用“{}”括起来的内容,数据结构为{key:value,key:value…}的键值对,key为对象属性,value为对应的属性值,通过“对象.key”来获取属性值,而属性值的类型可以是数字、字符串、数组或者对象。
数组:用“[]”括起来的内容,数据结构为[“java”,“c#”,“javascript”,“redis”…],通过索引进行取值,字段值的类型同样可以是数字、字符串、数组或者对象。
将半结构化的数据序列化为JSON字符串的方法是object2json(),具体的序列化过程如下:
object2json():将半结构化数据序列化,转换成JSON字符串。
输入:实时更新的半结构化数据A
输出:JSON字符串S
步骤为:
①while(A更新一次)
②if(A为空)
③S.append(“”);
④else if(A是String、Integer、Boolean、Byte等基本类型)
⑤S.append(“A”);
⑥else if(A是Object[]、List、Map、Set类型数据)
⑦调用类似于S.append(array2json((Object[]) A))的方法进行解析;
⑧else S.append(bean2json)格式化输出;
⑨return S.toString()
在Redis中,数据发送方先将半结构化数据通过object2json方法进行序列化,转换成JSON字符串,然后将该JSON字符串作为值写入特定的键中,即以(key,value)的形式写入Redis。数据接收方通过key取出相应的value-JSON字符串,再将JSON字符串通过fromObject方法转换成JSONObject,将对原始数据的解析转换成对JSONObject的解析。
将半结构化的数据序列化为JSON数据,优点是可以支持多种编程语言,并且被序列化的对象可以继续添加或者删除成员变量而不用变更object2json方法。但是,被序列化的对象必须要有无参数的构造方法和所有变量的getter和setter方法。数据接收方须知道被序列化的对象的“key”和该对象所有的成员变量,才能完全地解析JSONString。
2)采用Java对象序列化技术序列化半结构化数据。
利用Java对象序列化技术将半结构化数据序列转化为二进制字符串的方法是:writeObject()和readObject()。
(1)writeObject():由于Java中所有的对象都继承自Object类,考虑到代码的可重用性,可以利用父类Object的writeObject方法将所有不同类型的对象转换成字节数组,具体的序列化过程如下:
输入:实时更新的半结构化数据A
输出:字节数组
步骤为:
①while(A更新一次)
②A向上转型成Object类A';
③从对象流中读取对象A',写入内存;
④捕获内存缓冲区数据A',转换成字节数组B;
⑤endwhile
⑥returnB
(2)readObject()方法:利用抽象类Object类的readObject方法将字节数组转化为Object类,具体的反序列化过程如下:
输入:字节数组
输出:原始数据A'
步骤为:
①将字节数组B转化为输入流B';
②将输入流中的数据B'输入对象输入流B'';
③从流中读取对象,恢复对象状态,得到A';
④returnA'
数据发送方通过Java对象序列化技术,先将对象向上转型成父类Object类,然后通过writeObject()方法将对象序列化成二进制流,数据接收方经由readObject()方法将接收到的二进制流反序列化为抽象类Object类,然后再向下转型为原始数据类型。
2.3 对敏感数据字段进行加密
一些数据中可能存在敏感字段,比如年龄、性别、电话号码、密码等等,图像也可能涉及机密或隐私,序列化的优点是序列化之后的数据格式比较简单且统一,可以对其运用DES[10]、AES[11]、RSA[12]、MD5[13]等经典加密算法或者自定义加密算法进行加密。数据发送方将加密后的二进制流写入Redis,数据接收方需先将接收到的二进制流进行解密,再进行反序列化。即使key值被泄露,value值还需先解密才能被成功的反序列化,对于无密钥的数据拦截者而言无法获取原始数据,从而保证了数据的安全。
3 实 验
3.1 实验环境
设计了基于流计算平台Storm的实验来测试所设计的序列化算法的性能。
Storm是Twitter支持开发的一款分布式的、实时的、主从式大数据流式计算系统[14]。实时性主要体现在其可以处理流数据而非静态数据,并实时更新计算结果[6],主从架构由一个主节点Nimbus和多个工作节点Supervisor组成。Nimbus负责在集群中分发代码,分配计算任务给机器,并且监控集群状态。Supervisor负责监听分配给它的机器的工作,根据需要启动或关闭工作进程。
实验的硬件环境:内存8 GB,CPU为主频2.7 GHz的i7处理器,1个Nimbus节点、2个Supervisor节点的Storm集群。
软件环境:Storm0.9.1,JRE1.7,Zookeeper-3.4.6、redis-2.4.5。
操作系统:Centos6.4。
编程语言:Java。
3.2 序列化算法的正确性测试
(1)采用文件流序列化非结构化数据的测试结果。
将需要测试的商品号(1417,2227,3967,7237,8467,10477,10777…)序列化后存入Redis,然后反序列化写入路径Pubic/sundujing下的test_items.txt中,如图2(a)所示,文件内容如图2(b)所示,与原始数据一致。

图2 采用文件流序列化非结构化数据
(2)图数据序列化测试结果。
图数据序列化的测试情况如图3所示。对图3(a)的序列化结果为[B@17ee8b8,反序列化结果为图3(b)。

图3 图数据序列化
(3)半结构化数据序列化测试结果。
半结构化数据的序列化与反序列化以简单的商品信息ITEM为例,ITEM有商品号item_id、商品所属类目号cat_id、商品标题分词后的结果terms这三个属性。一个简单的实例item:商品号29、商品所属类目号155、商品标题分词为123950,53517,106068,59598,7503,171811,25618,147905。JSON序列化结果为item----{"item_id":"29","cat_id":"155" , "terms":"123950,53517,106068,59598,7503,171811,25618,147905"};Java对象序列化结果为[B@fa3ac1,经过反序列化后,能得到原始数据实例item。
3.3 序列化算法的效率测试
以下通过Redis存取序列化数据的性能来体现序列化算法的效率。采用用户购买记录作为数据集,如图4所示,三个字段分别为用户id、商品id、用户购买时间。将用户id作为key值,将用户购买的商品id作为value值存入对应的用户id中,用50万、100万、150万条购买记录进行测试,Redis测试所需时间如图5所示。
Redis官方声明过,Redis在极佳的情况下能达到每秒10万次读写,而在该次实验中50万条数据序列化后存入只需40 s,并且随着需处理的数据条数的增长,时间呈线性增长,不会因此导致内存激增而影响其他线程的执行,由此可以看出Redis存取序列化后的数据的性能很高且稳定。
图4 测试数据集截图
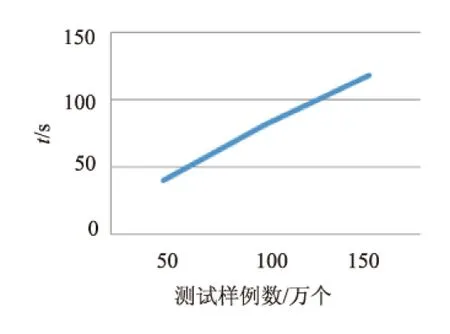
图5 Redis时效测试结果
4 结束语
基于Redis的特点和流式实时计算平台对半结构化和非结构化数据的处理需求,设计了面向Redis的数据序列化算法,借助文件序列化、图像序列化、JSON序列化和Java对象序列化技术,解决了Redis无法直接存储半结构化与非结构化数据的问题,并在流数据处理平台Storm上通过实验证明了该算法能有效解决实时计算中半结构化与非结构化数据的存储和实时读取问题。
在海量数据实时计算中,无论使用哪种开发语言,使用Redis作为数据库并采用设计的序列化算法,一方面,当需要被处理的数据很大时,能有效降低系统的内存消耗和网络传输;另一方面,不仅可以利用Redis带来的高性能读写效率,而且可以存储任何半结构化数据甚至非结构化数据对象而无须重复开发代码,所设计的序列化算法能高效地解决半结构化和非结构化数据的存储问题。
[1] 蔡金花.浅析NOSQL及使用[J].电脑知识与技术,2011,7(12):2757-2758.
[2] 宗 平,吴秀娟.基于NoSQL系统的组合索引技术研究[J].计算机技术与发展,2014,24(12):53-56.
[3] 曾泉匀.基于Redis的分布式消息服务的设计与实现[D].北京:北京邮电大学,2014.
[4] 苏翔宇.Key-Value数据库及其应用研究[C]//中国职协2013年度优秀科研成果获奖论文集(下册).出版地不详:出版者不详,2013.
[5] 罗 军,陈席林,李文生.高效Key-Value持久化缓存系统的实现[J].计算机工程,2014,40(3):33-38.
[6] Anderson Q.Storm real-time processing cookbook[M].Birmingham:Packt Publishing,2013.
[7] 张 涛,黄 强,毛磊雅,等.一个基于JSON的对象序列化算法[J].计算机工程与应用,2007,43(15):98-100.
[8] 袁晓铭,林 安.几种主流快照技术的分析比较[J].微处理机,2008,29(1):127-130.
[9] Surhone L M,Tennoe M T,Henssonow S F,et al.Object exchange model[M].[s.l.]:Betascript Publishing,2010.
[10] 李少芳.DES算法加密过程的探讨[J].计算机与现代化,2006(8):102-104.
[11] 何明星,林 昊.AES算法原理及其实现[J].计算机应用研究,2002,19(12):61-63.
[12] 陈传波,祝中涛.RSA算法应用及实现细节[J].计算机工程与科学,2006,28(9):13-14.
[13] 张裔智,赵 毅,汤小斌.MD5算法研究[J].计算机科学,2008,35(7):295-297.
[14] 李 浩,罗云彬,王志军,等.基于分布式流式计算系统的任务处理方法、系统及节点:CN,CN 103763378A[P].2014.
Investigation on Data Serialization Algorithm for Redis
SUN Du-jing,LI Ling-juan
(School of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
In order to deal with the problem of storing semi-structured and unstructured data in real-time calculation,a data serialization algorithm for Redis is designed.It takes advantage of Redis which can store key-value data and support full memory operation and uses the technologies of file serialization,image serialization,JSON serialization and Java object serialization.The algorithm can not only solve the problem that the semi-structured and unstructured data cannot be directly stored into Redis,but also enable the deserialization to restore the original data perfectly by keeping a deep copy of the data.In addition,encrypting and decrypting can be added to the serialization process to ensure the security of data.The experimental results on Storm platform show that the proposed algorithm is fast,effective and stable.In the real-time processing of massive data integration,this algorithm with Redis can not only make reading and writing highly efficient,but also store any semi-structured and unstructured data without rewriting code no matter which programming language is employed.
Redis;serialization;semi-structured;unstructured;Storm
2016-06-20
2016-09-22 网络出版时间:2017-03-07
国家自然科学基金资助项目(61302158,61571238)
孙杜靖(1992-),女,硕士研究生,CCF会员,研究方向为流数据挖掘;李玲娟,教授,CCF会员,研究方向为数据挖掘、信息安全、分布式计算。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170307.0922.086.html
TP391
A
1673-629X(2017)05-0077-05
10.3969/j.issn.1673-629X.2017.05.017
