供应链视角下中小企业融资风险评估
2017-06-05常州工程职业技术学院经贸学院付彬
常州工程职业技术学院经贸学院付彬
供应链视角下中小企业融资风险评估
常州工程职业技术学院经贸学院付彬
本文基于供应链融资风险特点,建立融资信用评估指标体系。从商业银行的视角出发,来剖析中小企业的融资风险,包括用来反映融资企业状况的相关指标,同时采用定量指标来反映相关因素,然后通过基于PCA的logistic回归模型以及支持向量机进行建模分析。研究发现,两个模型在进行融资信用评估时都表现较为良好,但是支持向量机在预测企业是否违约方面更加准确。同时,SVM模型可以有效地控制第一类错误的发生概率,这对于商业银行来说尤为关键,因此商业银行采用SVM模型进行供应链融资风险评估是具有可行性的。
风险评估 logistic回归 支持向量机
一、引言
随着经济的不断发展,中小企业面临的市场竞争也越来越激烈。企业不得不快速发展,因此融资成为企业不可缺少的一环。对于中小企业而言,由于自身规模限制无法承受金融市场上高额的融资费用,因此非常依靠商业银行的贷款这一渠道来获取资金。但很多中小企业由于缺乏足够的资产抵押、财务信息不够透明、经营水平不高等原因,无法达到商业银行的融资标准而很难获得融资。同时,对于商业银行而言,在面对财务状况良好、抵押资产充分的大型企业和财务透明度较差的中小企业时,自然会更倾向于向大型企业提供信贷支持,这种逆向选择使得中小型企业从传统融资渠道获得授信支持更加困难。
供应链融资自然地就产生了,它可以为与供应链中核心企业有着紧密联系的中小企业实现一种更加有效地融资手段,同时对于商业银行而言,它们在实现风险有效可控的情况下提供了新的业务拓展点。对于传统融资手段而言,商业银行将融资主体进行独立的信用评价,根据其发展状况、财务状况、担保情况等来判断是否可以发放贷款。在供应链融资的情况下,商业银行可以根据供应链中核心企业的资信情况的评估以及评估对于核心企业所处的供应链的实际贸易情况,来分析融资对象的资信状况。在供应链快速发展的今天,商业银行应该不断完善供应链风控体系,提高供应链融资的服务效率,同时保证发放贷款的资金风险安全,为中小企业的快速成长提供更好的融资渠道,同时实现自身新的盈利增长点。
二、供应链融资风险特点
供应链融资与商业银行传统信贷在多方面有着较大的差异,供应链融资建立在供应链的基础之上,它突破了商业银行传统的信贷视角,在融资过程中的参与主体更加多样化,引入了物流企业、监管企业等主体。因此,供应链金融融资风险有着自身独特的特点。
(一)信用评估对象转变在传统商业银行融资额过程中,商业银行主要着重于个体企业的财务状况,信贷基础主要是企业在生产销售中的存货、应收账款和应付账款。商业银行在供应链金融视角下,不再将目光仅仅局限于个体的企业的信用状况,而是针对供应链核心企业的资信实力的评估,以及评估对于核心企业所处的供应链的实际贸易情况,可以对供应链上的其他企业进行融资评价。
(二)信用风险较为集中传统的融资渠道中,银行的信用评估对象通常为单个企业,信用风险的来源也只有独立的企业。但供应链融资中,银行的资信对象从传统的独立企业个体转为对整体供应链授信,信用风险来源于一整条供应链。因此若供应链中的某个企业一旦产生信贷危机,会沿着供应链将信用风险传播,影响到供应链上的其他企业通过供应链进行信贷活动。
(三)还款资金密封自偿资金密封性指的是银行发放给资信对象的款项有指定的用途,从流程设计上确保这一点的实现。融资企业和商业银行签订融资协议时,会规定这笔款项的具体用途,保证银行的款项不挪作他用。而自偿性指的是银行回收借款的来源是企业在供应链中产业的稳定的现金流。例如银行在生产过程中沉淀的存货作为抵押物进行供应链融资,那么存货的销售收入可以作为稳定的还款来源。或者是融资企业针对供应链上某核心企业的应收账款作为基础申请的融资,这笔款项由于来源于中小企业与核心企业的交易,较为有保障。银行针对供应链中的现金流、信息流以及物流状况进行监控,可以将信用风险掌握在可控范围内。
三、供应链融资视角下中小企业融资风险评估指标体系
(一)供应链融资信用评估相关影响要素分析
(1)行业背景。供应链金融中资信考察对象为整体供应链,因此融资企业的行业背景会在较大程度上影响资信风险状况。供应链融资的三种模式中,作为融资基础的应收账款、应付货款、企业存货,在很大程度上都与整个行业走势相关。商业银行更倾向于将资金融给行业发展前途较好的企业,行业整体走势较好时,企业的货款、货物流转更加流畅,它违约的风险性自然而然会下降很多。
(2)融资企业状况。供应链金融中借款主体的企业状况,仍然是需要着重分析的一环。商业银行较为关注融资企业的经营现状以及财务状况和历史信用记录,从这些可以判断出企业的还款能力、经营水平等等,从而判断融资企业的违约可能性大小。经营状况良好,收入稳定,信用评级较高的企业当然更容易得到银行的授信。
(3)核心企业状况。核心企业作为供应链中的核心,融资主体一般而言都是与核心企业关系较为紧密的中小企业。商业银行在进行授信时,非常关注核心企业的财务指标、经营现状等等,从而判断中小企业是否有稳定的还款来源。当核心企业规模较大,运营稳定时,其上下游的中小企业更容易获得商业银行的授信。
(4)供应链状况。供应链的稳定是银行授信的基础。若核心企业与融资中小企业关系不能长久保持稳定的话,银行建立在供应链上的融资以及授信等一系列就变得非常不牢固,中小企业违约风险会大幅增加。
(二)供应链融资信用评估指标初选本文基于国内相关研究文献,结合传统商业银行信用风险评估的一些传统指标,并考虑到部分指标的可得性,按照上述因素分类,筛选出本文的基本评估指标。
(1)行业背景指标选取。一是宏观经济状况。微观企业运行始终处于整体的宏观经济背景之中,国家经济发展状况良好,对供应链整体的行业有较大的推动作用。在整体宏观走势良好情况下,银行也更加愿意为企业授信。二是行业发展趋势。供应链都处在某个具体的行业之中,若整体行业发展良好,那整个供应链运转起来也就会更加顺畅高效。对商业银行而言,新兴且有发展潜力的行业里的供应链更受到青睐。若整体行业呈落后、衰退趋势,供应链的融资风险势必会增大。
(2)融资企业状况指标选取。一是企业基本状况。企业的基本状况反映了企业融资时来自内部的风险大小,主要是包括了企业的内部管理水平、企业员工的素质水平以及企业整体的发展规模。企业管理水平越高,企业的未来收益预期也就越好,银行也就越愿意授信。企业规模越大,在竞争中越容易占得先机,因而信用风险越小。二是企业盈利能力。企业在负债之后,企业的盈利是能够偿还贷款的基础。对于风险管理而言,企业的盈利能力是非常重要的一个方面,需要全面考量。企业的盈利能力主要是通过一些企业的财务指标来反映的,如净资产收益率、销售利润率等。三是企业经营水平。无论任何情况下,对企业授信后都将依靠未来的经营活动作为还款,因此,企业的经营水平实质上在决定企业的信用风险方面有着举足轻重的作用,在反映企业的经营水平上主要是选取了应收账款周转率、存货周转率等相关指标。四是企业偿债能力。融资企业的偿债能力直接决定了企业是否能到期按时归还信贷资金,选取可以反映企业偿债能力的财务指标,如利息保障倍数、速动比率等。五是企业信用记录。企业的历史信用记录可以从侧面一定程度上反映企业的信用风险,因此历史上是否存在逾期账款未归还的情况,需要纳入到考虑的范围内。
(3)核心企业状况指标选取与供应链状况指标选取。核心企业的指标选取供应链状况指标选取与融资企业的选取类似。如表1所示:
(三)供应链融资信用评估指标筛选通过供应链融资信用评估指标的初选,得到32个三级指标。这些指标中有很多属于相近的财务指标,多少会存在一定的相关性,将进行相关系数的检验,剔除一些指标,同时,由于本文数据均来自同一时间段的同一地区的相关数据,因此宏观经济发展状况以及行业发展趋势在样本中几乎没有任何变化,因此将剔除宏观经济现状A1、行业政策法律A2、现状行业发展现状A3、行业竞争情况A4等指标。
(1)数据来源。本文的数据来源于2013~2015年41家重庆市汽车行业的中小企业,主要的定量数据来源于《中国企业财务信息分析库》,主要定性数据来源于重庆统计局对于重庆汽车行业中小企业的供应链调查。
(2)指标相关性分析。本文初选得到的供应链融资信用评估指标,大多数来源于供应链上的财务指标,且指标数目较大,容易存在指标之间的相关系数较大的问题,引起多重共线性的问题。所以将对指标做相关性分析,从高度相关的指标中筛选一些指标。
(3)鉴别力分析。在进行统计评估指标体系建立时,需要考虑到指标的鉴别力,即该指标是否能够反映出各个个体之间的差异。若指标在不同的样本之间,呈现一致的走势的话,那么该指标在评价体系中起到的影响较小,就应该删除。通常使用变差系数来对鉴别力进行分析比较:

表2 融资信用评估指标相关性检验
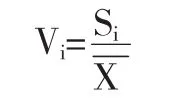

表3 融资信用评估指标鉴别力分析
(四)供应链融资信用评估指标体系建立通过以上初选步骤,筛去一些相关指标,最后采纳的变量指标有22个,具体如表4所示。
四、供应链金融背景下中小企业融资信用风险实证研究
在建模时,一般首先会考虑使用线性回归的相关方法。本文的因变量是一个分类变量,因此无法采用线性回归的方法。所以考虑使用分类算法对模型进行回归,本文将使用Logistic模型以及SVM模型两种分类算法,对二分类自变量进行建模分析。
(一)信用风险模型的建立
(1)基于Logistic模型的建立。Logistic回归是一种比较成熟的二分类算法,在商业银行的信用评估中应用得较为广泛。它的因变量是一个离散的二分类变量,取值为0或者1,在本文中针对供应链金融的融资风险信用评估,将因变量Y设为融资企业到期还款情况,将到期还款为1,到期违约未还款为0。本文构建的供应链融资信用评估指标体系,总共有21个变量。

表4 融资信用评估指标
统计局在对供应链进行调查时,定性指标采用的是5分的打分制模式,从1到五分,对其也先做标准化处理,将其转变为0.2、0.4、0.6、0.8、1分。同时,由于企业的规模波动的数量级较大。对其进行对数变换,生成新的变量后,再进入模型。
一是主成分分析。由于建立的指标体系中的指标多达22个,若直接进行Logistic回归很可能会造成多重共线性等相关问题,因此先对所有数据进行主成分分析达到降维和减少多重共线性的目的。用Spss对数据进行主成分分析时,首先要确定其KMO值的大小,若KMO≥0.6,反映模型可以做因子分析。若KMO≤0.5,则模型不大适合进行因子分析。用Spss对上述数据做的KMO分析值,为0.678≥0.6,说明模型适合进行主成分分析。
Spss中抽取的主成分默认是其特征根大于1为标准的。将本文数据输入Spss,特征根大于1的主成分为前面8个,根据上面的主成分得分系数矩阵以及主成分的特征根矩阵,可以得到每个主成分的计算方法:

将因子数据进行正交旋转得到的旋转成分矩阵如表5所示。
F1主要解释的是来自变量,x2、x5、x6、x7,体现了融资企业的盈利情况与经营状况。F2主要解释的是来自变量,x11,体现了融资企业的信用记录状况。F3主要解释的是来自变量,x1、x18、x19,体现了融资企业与核心企业间供应链的关系情况。F4主要解释的是来自变量,x13、x14,体现了核心企业的经营情况。F5主要解释的是来自变量,x10、x11、x17、x22,体现了核心企业的信用记录以及偿债能力。F6主要解释的是来自变量,x8、x9,体现了融资企业的短期偿债能力。F7主要解释的是来自变量,x4,体现了融资企业的应收账款的流动性。F8主要解释的是来自变量,x13,体现了融资企业的业务增长情况。
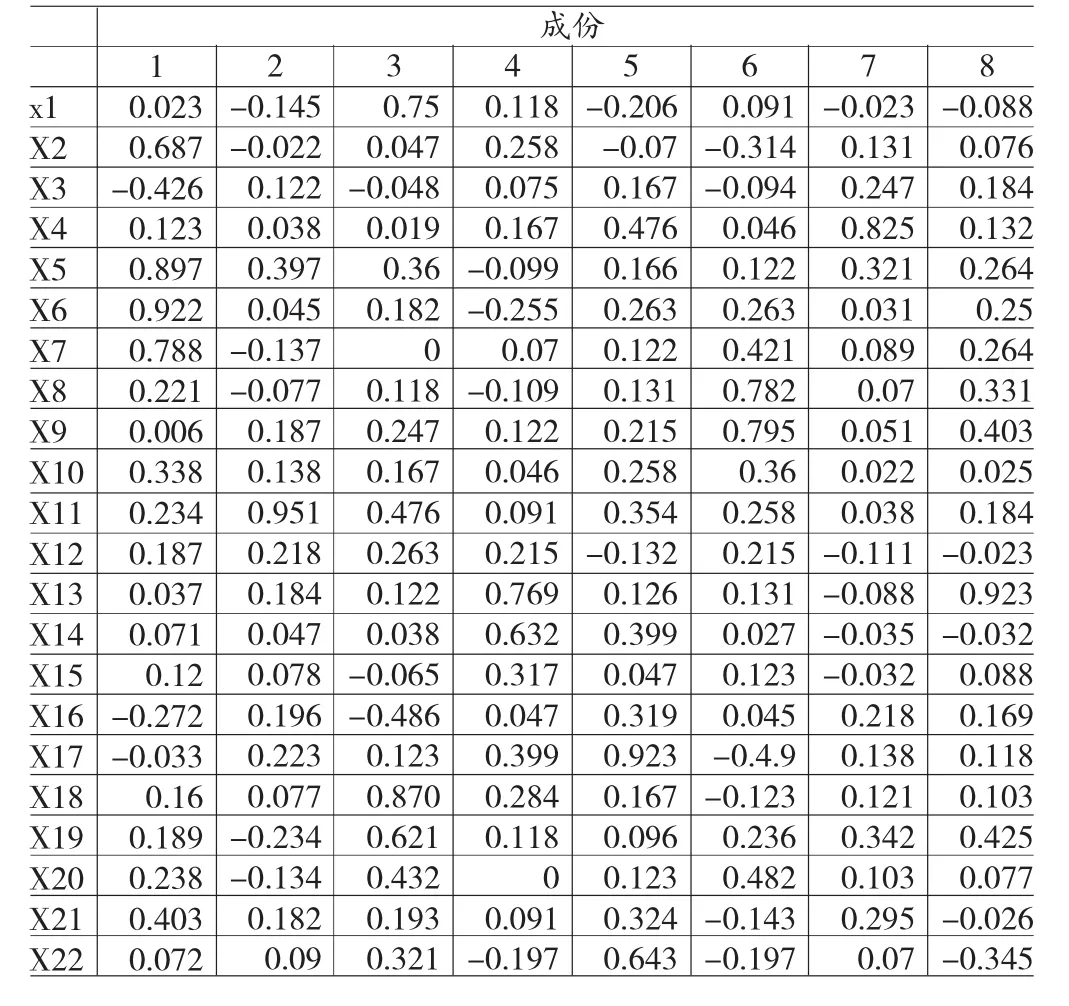
表5 旋转成分矩阵
二是Logistic回归。根据上文中得到的Fl到F8与22个变量之间的线性表达式,可以计算出八个主成分的得分情况。将八个主成分与因变量中小企业历史信用违约记录状况放入到Logistic回归模型中,进行回归。回归过程中采用向前逐步迭代的方法,一直迭代计算到对数的似然比稳定为止。回归结果如表6所示。

表6 方程中的变量
a.在步骤1中输入的变量:F3
b.在步骤2中输入的变量:F8
c.在步骤3中输入的变量:F5
d.在步骤4中输入的变量:F1
F1,F3,F5,F8的四个主成分变量在置信度为5%下,都为显著,因此最后的Logistic估计得回归模型为:

将模型带入到总体样本中,进行预测,预测结果如表7。
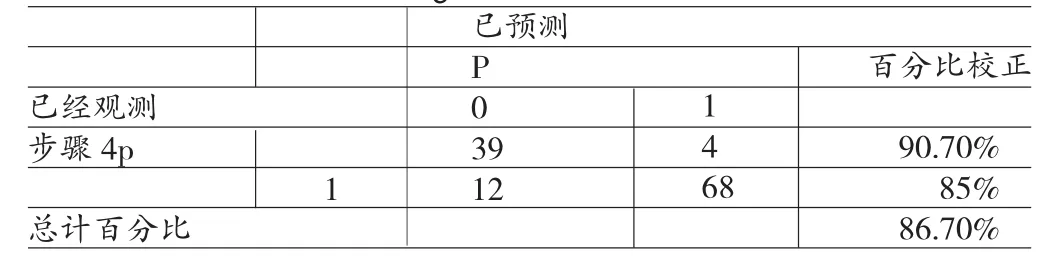
表7 Logistic回归预测结果
判断的准确率达到86.70%,对于违约企业的预测准确率达到90.70%,对于信用良好的企业达到85%。
(二)基于SVM的模型的建立
(1)数据预处理。在数据收集后,对数据进行初步的处理是统计建模分析中必不可少的一环。收集到的原始数据由于量纲的不同以及数量级的巨大差异,若直接进入模型之中进行拟合,势必会影响模型最后的拟合效果。因此,首先将对所有的数据进行标准化处理。数据标准化的具体计算公式如下:
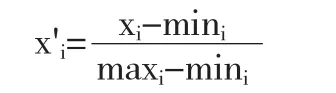
(2)训练样本集与测试样本集划分。将标准化的数据重新加入到模型之中。在训练样本集中,将因变量Y设定为中小企业历史信用违约记录状况,当Y=1时表示企业没有信用违约记录即企业每次都按时还款,当Y=-1时,表示企业有过信用违约记录即存在过逾期未按时归还的款项。本文总体样本数据规模为123个,选取其中82个作为训练样本集,另外的41个作为测试样本集。
(3)核函数选取。SVM在对于线性不可分的数据处理时,选择核函数是较为重要的一点,它决定了将数据以一种怎样的方式映射到高维特征空间之中。核函数主要分为线性核函数和非线性核函数。在上文中,已经介绍了主要的三种非线性核函数,Poly函数、RBF函数、Sigmoid函数。关于各个核函数之间的差异以及使用范围,目前学术界还没有一个确切的定论,本文将分别使用四个核函数进行拟合,寻找最优核函数。同时利用交叉验证,进行参数选择,取得最优化的惩罚因子c,核函数中的参数,再利用最优核函数以及最优参数进行拟合。本文使用matlab软件对数据进行处理建模,使用台湾大学林智仁教授等人开发的libsvm包进行SVM建模分析。在分别使用四种核函数对原数据进行拟合后,得到的四种核函数进行模型拟合的结果对比如表8所示。
核函数为线性函数的建模分析结果中,迭代次数为109次,nSV为35次。Poly函数作为核函数时,nBSV较大,向量数目较多容易影响模型拟合效果。RBF函数作为核函数时,尽管迭代次数多与poly以及Sigmoid函数,但仍在可接受范围内,同时其nBSV较小,且判决函数的偏置项b很小,可以有较好的拟合效果。对于Sigmoid作为核函数的拟合效果而言,其nBSV也较大,容易使判别分析误差增大。因此本文将选取非线性核函数中的RBF函数作为拟合函数,进行后面继续的分析。
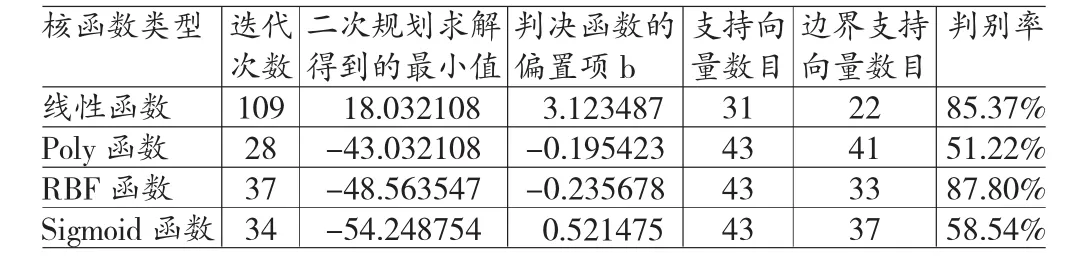
表8 核函数结果对比
(4)参数寻优。利用libsvm软件包进行交叉验证时,其原理是将训练样本集均为m个子集,每次选取m-1个子集进行训练作为训练样本集,同时剩下的那个子集作为测试样本集,重复m操作,取m次操作的平均准确率作为结果。本文按照交叉验证后,寻得的最优参数为:惩罚系数c=512,核函数中参数=0.00077135.
(5)建模分析。选用得到的最优参数,同时将核函数选为RBF函数,进行建模分析,可以发现,模型的分类判别率为92.6829%。
五、研究结论
本文应用了两种供应链融资风险评估模型,对于文中的实证数据进行了研究:一是基于PCA的Logistic回归;二是支持向量机(SVM)。得到的模型预测正确率以及对应的第一类、第二类错误率如表9所示。

表9 Logisic回归模型与SVM模型结果对比
在本文中,第一类错误指的是企业融资信用风险较大,而被模型判定为可以进行授信。而第二类错误指的是企业有能力偿还贷款,却被模型判定为融资信用风险较高。在实际操作中,对于商业银行而言,如何控制住第一类错误率是商业银行应该首先考虑的问题,同时在此基础上逐渐减小第二类错误,让中小企业的融资困难的状况得到改善。从表9中可以看出,在采用同样的供应链融资信用风险评估指标体系下,SVM的模型表现要好于logistic,无论是样本结果的预测率还是对第一类错误率的控制。这表明支持向量机在商业银行对于中小企业进行融资信用风险评估的时候,是一个非常良好的工具。
[1]王帅、杨培涛:《黄庆雯基于多层次模糊综合评价的中小企业信用风险评估》,《财经理论与实践》2014年第5期。
(编辑成方)
