基于HITS算法的双语句对挖掘优化方法
2017-06-01姚建民周国栋
刘 昊,洪 宇,姚 亮,刘 乐,姚建民,周国栋
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
基于HITS算法的双语句对挖掘优化方法
刘 昊,洪 宇,姚 亮,刘 乐,姚建民,周国栋
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
识别和定位特定领域双语网站,是基于Web自动构建特定领域双语语料库的关键。然而,特定领域双语网站之间的句对质量往往差异较大。相对于原有基于句对文本特征识别过滤质量较差句对的方法。该文从句对的来源(即特定领域双语网站)出发,依据领域权威性高的网站往往蕴含高质量平行句对这一假设,提出一种基于HITS算法的双语句对挖掘优化方法。该方法通过网站之间的链接信息建立有向图模型,利用HITS算法度量网站的权威性,在此基础上,仅从权威性高的网站中抽取双语句对,用于训练特定领域机器翻译系统。该文以教育领域为目标,验证“领域权威性高的网站蕴含高质量句对”假设的可行性。实验结果表明,利用该文所提方法挖掘双语句对训练的翻译系统,相比于基准系统,其平均性能提升0.44个BLEU值。此外,针对HITS算法存在的“主题偏离”问题,该文提出基于GHITS的改进算法。结果显示,基于GHITS算法改进的机器翻译系统,其性能继续提升0.40个BLEU值。
统计机器翻译;特定领域机器翻译;特定领域双语网站;权威性
1 引言
面向特定领域的统计机器翻译(Statistical Machine Translation, SMT)系统往往受制于目标领域双语语料的不足,难以充分学习相应的领域翻译知识和语言现象,导致翻译性能普遍偏低。目前,借助检索技术,从大规模Web数据中自动挖掘特定领域双语语料,并用以扩展翻译系统双语训练集的相关研究较多[1-3]。通常,基于Web自动挖掘特定领域双语语料的方法包含三个关键步骤: 1)识别和定位特定领域双语网站; 2)识别平行网页对; 3)抽取平行句对。其中,识别和定位特定领域双语网站是基于Web自动挖掘特定领域双语语料的前提和关键。然而,自动获取的特定领域双语网站之间句对质量往往差别较大。Rarrick等[2]指出,英语、日语和德语等语言中,自动获取的平行网页中15%的网页是由机器翻译产生(表1)。此类质量较差的句对,无法为机器翻译系统提供有效的翻译知识,甚至成为噪音。

表1 机器翻译页面所占比重
目前,解决上述问题的方法包括: 1)判定双语句对是否由机器翻译产生[4-5]; 2)利用句对的双语特征和领域特征构造模型,评价句对的平行性和领域性[6-7]等。上述方法仅从句对的文本特征评价句对质量,忽略句对的来源信息;此外,上述方法需抽取目标领域网站集合中蕴含的所有句对,实现较为复杂,效率较低。例如,刘昊、洪宇等[8]指出,在电子器件领域共获取领域双语网站18 944个。
针对上述问题,本文提出基于HITS算法的双语句对挖掘优化方法。这一方法的设计源于如下经验性的发现:
• 特定领域双语网站中,双语句对的质量与该网站在目标领域的权威度直接相关;
• 目标领域权威度高的网站,其所含双语句对的质量较高,反之亦然。
如图1所示,图(a)和图(b)表示的平行网页来源于北京大学官方网站;图(c)和图(d)表示的平行网页来源于山东省实验中学官方网站。通过观察发现,仅从用词的角度分析,北京大学官方网站中蕴含的单词“delegation”、“outline”较山东省实验中学的单词“guests”、“introduce”,用词更为专业,领域性更强。假设选取教育领域为目标领域,则上述两个网站均可被认定为目标领域双语网站。但由于网站之间双语句对质量的差异,由其所训练翻译系统的性能应存在较大差异。相对地,图1中所示的北京大学更权威,其网站中的双语句对质量较好。此例说明,特定领域双语网站中,句对的质量与该网站在目标领域的权威度具有较大关系。
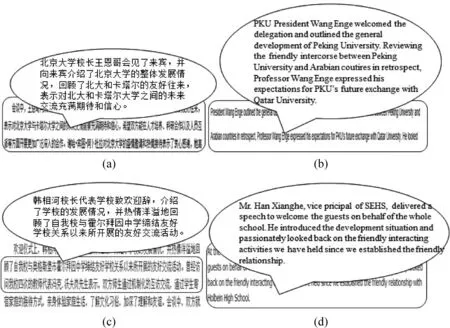
图1 双语平行网页实例
针对上述现象,本文从句对的来源(即特定领域双语网站)出发,依据“领域权威性高的网站蕴含高质量平行句对”这一假设,提出一种基于HITS算法评价特定领域双语网站权威性,进而获取高质量双语句对的方法。本文开展了如下工作:
• 验证利用HITS算法评价网站权威性的有效性;
• 验证本文所提“领域权威性高的网站蕴含高质量平行句对”的假设;
• 验证本文所提基于HITS算法的双语挖掘优化方法的有效性。
本文组织形式如下: 第二节介绍相关工作;第三节介绍HITS算法;第四节概述结合HITS算法的双语句对挖掘方法框架;第五节详述本文所提基于HITS算法的双语挖掘优化方法;第六节给出实验设置及结果分析;第七节总结全文并展望未来工作。
2 相关工作
基于Web自动获取大规模双语语料的方法可分为以下三类: 1)基于双语网站自动获取双语语料。比如,Resnik等[1]开发的STRAND系统,该系统利用双语网站的语言标识作为启发式信息,获取平行网页对。Nie等[2]开发了PTMiner系统,该系统进一步利用网页html的结构信息实现平行网页对之间的句子对齐。Ma和Liberman[9]开发的BITS,利用双语词典,计算两部分文本之间内容的互译度,提高了文本对齐的质量。叶莎妮、吕雅娟等[10]提出自动发现双语网站中URL命名规律的方法。2)基于混合网页自动获取双语语料。Jiang等[3]提出一种基于自适应模板挖掘双语句对的方法。冯艳卉、洪宇等[11]提出一种从搜索引擎返回结果的网页中获取双语混合网页的方法3)利用可比较语料库挖掘双语平行语料。Smith等[12]提出一种排序模型在可比较文本中抽取平行句对。Bharadwaj等[13]利用SVM分类器在Wikipedia中抽取平行句对。面向特定领域双语资源获取方面,当前研究相对较少。Pecina等[14]提出一种基于聚焦爬虫的特定领域双语语料获取方法。刘昊、洪宇等[8]提出一种基于全局搜索和局部分类的特定领域双语网站识别方法。然而,基于Web自动获取的领域双语网站中句对的质量往往差异较大。质量差的双语句对无法为翻译系统提供有效的领域翻译知识和语言现象,甚至成为噪音。
针对上述特定领域双语网站质量不平衡问题,解决方法大致可分为两类: 1)机器翻译句对识别。Rarrick等[4]提出一系列双语平行性特征,通过此类特征识别机器翻译产生的句对。Arase等[5]提出一系列单语特征,用于识别机器翻译产生的句对。2)双语句对选择。黄瑾,吕雅娟等[15]提出基于信息检索的统计机器翻译训练数据的选择和优化方法。Yasuda等[16]和Foster等[17]提出利用目标领域语言模型困惑度计算双语句对质量的方法。Axelrod等[18]分别计算特定领域和通用领域的语言模型困惑度,并利用其差值评价句对质量。Duh等[19]探索应用神经网络语言模型计算困惑度。Liu等[7]提出一种结合翻译模型和语言模型评价句对质量的方法。现有解决方法仅从句对内部特征出发考虑句对的质量,且难以有效融合句对平行性和领域性特征;若目标领域双语网站集合较大,利用上述方法,需抽取网站集合中蕴含的所有句对,实现较复杂,效率较低。
本文所提基于HITS算法的双语句对挖掘优化方法,从句对的来源(即特定领域双语网站)出发,基于“领域权威性高的网站蕴含高质量句对”的假设,利用网站之间的链接信息,对网站权威度进行评价。最终,仅从权威度高的目标领域双语网站中抽取句对,训练特定领域机器翻译系统,从而有效解决上述特定领域双语网站质量不平衡的问题。
3 HITS算法
本文根据网站之间的链接关系,利用HITS算法评价网站领域权威度,HITS算法由Kleinberg等[20-21]提出。HITS算法可有效利用网页之间的链接关系挖掘隐含信息(如: 权威度等),具有计算简单且效率高的特点。
算法概述如下:
Hub值(表征网站的枢纽度)和Authority值(表征网站的权威度)是HITS算法最基本的两个概念,通过Hub和Authority指标,HITS能够对网站的枢纽度和权威度进行估计。下面首先给出HITS算法的基本概念*基本概念的定义源自维基百科,链接地址为“http://en.wikipedia.org/wiki/HITS_algorithm”。和应用场景:
• “Hub”页面,Hub值高的网页,是指包含很多指向高质量“Authority”页面链接的网页,即枢纽度高的网站。
• “Authority”页面,Authority值高的页面,是指与某个领域或者话题相关的高质量网页,即权威度高的页面;
HITS算法的应用场景如下图2*图2示例来源于博客“http://blog.csdn.net/hguisu/article/details/8013489”。所示,输入查询为: “Topautomobilemakers”,返回结果如图所示。其中“CarRanking”、“CARMANUFACTURERWEBSITES”为“Hub”页面(高枢纽度页面),“Ferrai”、“Flat”、“Ford”等为“Authority”页面(高权威度页面)。

图2 “Hub”和“Authority”页面实例

图3 Hub和Authority权值计算
HITS算法每次迭代时,Authority值和Hub值的计算方法如图3所示,图中A(i)表示网页i的Authority值(权威度),H(i)表示网页i的Hub值(枢纽度)。图3中,网页1被网页2、网页3和网页4所指向,并且网页1又分别指向网页5、网页6和网页7。则在HITS算法的每一轮迭代中,网页1的Authority值等于网页2、网页3和网页4(所有指向网页1的网页)的Hub值之和,网页1的Hub值等于网页5、网页6和网页7(所有网页1指向的网页)的Authority值之和。
4 结合HITS算法的双语句对挖掘方法框架
本文提出的基于HITS算法的双语句对挖掘方法框架如图4所示,共包含两个主要模块,分别为网站质量评价与双语句对抽取,主要功能和组成如下:
• 网站权威度排序: 用于获取专门从事某领域工作的专业性很强句对质量很高的网站,即“领域专家网站”。基本组成包括领域网站集合构建、集合扩展、HITS排序。Authority值高的网站即专门从事某领域工作的专业性很强,权威度很高,句对质量较好的网站。
• 双语句对抽取: 用于在权威度高的双语网站中获取双语平行句对。基本组成包括平行网页对识别、平行句对抽取。本文利用Ma和Liberman[9]所提方法实现双语平行句对抽取。并将双语句对用于扩充特定领域机器翻译系统训练集。

图4 方法框架图
5 基于HITS算法的双语挖掘优化方法
5.1 构建特定领域双语网站集合
首先,利用刘昊、洪宇等[8]所提特定领域双语网站识别方法,构建特定领域双语网站集合,作为根集合(Root Set)。其次,在根集合(Root Set)的基础上进行扩展,扩展原则为: 凡是与根集合网站有链接关系(包括链入和链出两种关系)的网站都被添加到扩展集合(Base Set)。扩展集合仍为有向图。
根集合(Root Set)和扩展集合(Base Set)的对应关系如图5所示, 其中,节点1、节点2和节点3表示利用特定领域双语网站识别方法,获得的目标领域双语网站,本文将此类网站集合作为根集合(Root Set)。其次,依据扩展原则将节点4-9加入根集合(Root Set),形成扩展集合(Base Set)。具体的链接关系如黑色箭头所示。
5.2 利用HITS算法优化网页挖掘
本文根据网站之间的链接关系,利用HITS算法进行迭代,得到网站的Authority值和Hub值。其基本算法如下,对任意网站p,每次迭代时Authority值和Hub值可由式(1)(2)计算:
(1)
(2)
其中,auth(p)和hub(p)分别表示网站p的Authority值和Hub值,网站qi(i=1,2,…,n)表示指向p的网站,网站qj(j=1,2,…,m)表示p所指向的网站。算法收敛后,根据Authority值对根集合网站排序,并将排序结果返回。HITS算法的伪代码如表2所示:

表2 HITS算法伪代码

续表
5.3 利用GHITS算法优化网页挖掘
HITS算法仅考虑网站之间的链接关系,忽略了网站中的内容信息,使得在HITS算法迭代过程中经常出现主题偏离问题。主题偏离问题是指,当扩展集合中包含部分与查询无关的网站,且这部分网站之间的互链关系较多时,HITS算法可能为根集合中与目标领域相关度较小的网站赋予较高的Authority值排名。针对此问题,范聪贤、徐汀荣等[22]提出将基于超链接的信息检索方法与内容相关性分析方法相结合的GHITS算法。
本文利用GHITS算法优化网页挖掘,具体描述如下:
• 首先,依照5.1节中所提方法构建目标领域双语网站集合,并利用网站之间的链接关系建立有向图模型,用符号G(V,E)表示。其中,V表示特定领域双语网站节点的集合,E表示节点之间有向边的集合。

(3)
对任意网站p,每次迭代时Authority值和Hub值可由式(4)、式(5)计算。
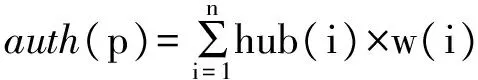
(4)
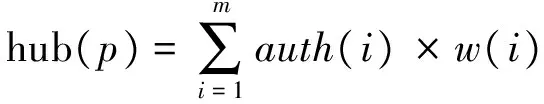
(5)
• 最后,GHITS算法迭代收敛后(收敛条件为: ‖at-at-1‖+‖ht-ht-1‖<ε,其中at表示第t次迭代后网站p的Authority值,ht表示第t次迭代后网站p的Hub值,ε为人为设定参数),根据Authority值对根集合网站排序,并将排序结果返回。GHITS算法的伪代码如表3所示:

表3 GHITS算法伪代码
5.4 双语平行句对抽取
本文采用基于网页结构和内容互译度的方法识别平行网页对。该方法首先基于URL地址的结构相似性获取候选平行网页对,其次,计算候选平行网页e和c之间的互译度,通过设定阈值,过滤非平行网页对,平行网页互译度的计算如式(6)所示。
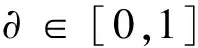
(6)
其中,Scb(e,c)表示基于网页内容的互译度,具体计算如式(7)所示;Sstruct(e,c)表示基于网页结构的互译度,具体计算如式(8)所示;∂为权重系数,实验中设为0.5。
(7)
(8)
Length(e)表示网页e中包含的单词个数;对于Translate(we),通过检索双语词典,如果网页e中单词we在网页c中存在翻译项,则Translate(we)的值为1,否则为0。ComSeq(etag,ctag)表示标签序列etag与ctag的公共子序列。
6 实验和结果分析
本实验分为三个部分: 1)验证HITS算法在评价网站领域权威性时的有效性; 2)验证“领域权威性高的网站蕴含高质量句对”的假设; 3)验证基于HITS和GHITS算法优化的双语句对挖掘方法的有效性,并与Liu等[7]所提方法进行对比。
6.1 实验设置
• 语料配置
本文选择教育领域为目标领域。首先,在2014年中国大学排行榜*http://www.cuaa.net/cur/2014/xjindex.shtml中随机抽取30个双语平行网站,建立对应根集合(Root Set)的有向图模型。其次,在根集合(Root Set)的基础上进行扩展,扩展集合(Base Set)仍为有向图,本文所构建的扩展集合中包含57个网站(获取到有效链接的数量为: 15,150个)。利用5.4节所提双语平行句对抽取方法,在根集合(Root Set)的双语网站中抽取双语平行句对。
为验证本文所提“权威度高的网站蕴含高质量双语句对”的假设,以及基于HITS和GHITS算法优化的双语句对挖掘方法的有效性,本文利用挖掘所得高质量领域双语平行句对,扩充机器翻译系统训练集,构建特定领域中到英基于短语的机器翻译系统。系统的训练语料设置如下:
1) 翻译模型训练数据由通用领域双语语料(规模100k,来源于机器翻译系统NiuTrans中发布的双语语料*http://www.niutrans.com/NiuTrans.ch.html)和利用HITS(GHITS)优化算法挖掘所得领域双语句对构成;
2) 语言模型训练数据取自本地英语单语语料(规模为: 10k句);
3) 开发集源于人工标注教育领域双语语料(规模为1k),对应4个参考集;
4) 测试集(1,2,3,4)源于人工标注教育领域双语语料(规模为2k,2k,2k,2k),对应4个参考集。
机器翻译系统的环境配置如下: 词对齐工具使用GIZA++[23],语言模型为三元,参数训练方法使用最小错误率[24]训练,系统采用对数线性模型进行特征融合。
• 系统设置
本文分别设置如下系统进行实验:
1) HITS_TopN: 利用基于HITS的网页挖掘优化算法,对6.1节所提教育领域双语平行网站(数量为: 30)进行句对质量排序;将排序Top-N网站中的双语句对和通用领域双语语料合并,作为翻译模型训练集,训练所得系统;
2) HITS_TailN: 将句对质量排序Tail-N网站中的双语句对和通用领域双语语料合并,作为翻译模型训练集,训练所得系统;
3) GHITS_TopN: 将句对质量排序Top-N网站中的双语句对和通用领域双语语料合并,作为翻译模型训练集,训练所得系统;
4) TM_LM_Method: 利用Liu等[7]所提双语句对选择方法,对6.1节所提教育领域双语平行网站(数量为: 30)所包含的全部句对进行排序,将排序Top-M的双语句对和通用领域双语语料合并,作为翻译模型训练集,训练所得系统。
本文设置N=10,M=N×4k=40k(设定M为40k,以保证TM_LM_Method系统与其他系统的训练集规模一致);利用基于HITS和GHITS的网页挖掘优化算法迭代时,设定参数ε=1.0×10-10作为迭代结束阈值。
• 评价标准
本文利用基于HITS的网页挖掘优化算法,对6.1节所提教育领域双语平行网站进行句对质量排序,并将网站排序结果与2014年中国大学排行榜数据进行对比,以验证HITS算法在评价网站领域权威性时的有效性。本文采用信息检索中的NDCG值作为评价标准,具体阐述如下:
将2014年中国大学排行榜的排名结果作为理想排序,将Top1-6排序结果的相关度设为31(25-1),Top7-12排序结果的相关度设为15(24-1),Top13-18设为7(23-1),Top19-24设为3(22-1),Top25-30设为1(21-1)。在第r位的NDCG值NDCG@r的计算公式如式(10)所示。
(10)
其中,r(j)表示第j个文档的相关性,Nr为归一化参数,使得最优排序的NDCG@r的值始终为1。本文采用BLEU-4[25]作为机器翻译系统性能的评价标准,BLEU-4的计算如式(11)所示。

(11)
其中,output-length表示翻译系统输出结果的长度,reference-length表示参考集中对应句子的长度,presicioni表示基于i元文法的准确率。
6.2 结果分析
本文利用基于HITS的网页挖掘优化算法,对6.1节所提教育领域双语平行网站(数量为: 30)进行句对质量排序,并将网站排序结果与2014年中国大学排行榜排名结果(30所大学的相对排名)进行比较,如表4所示。

表4 排序比较
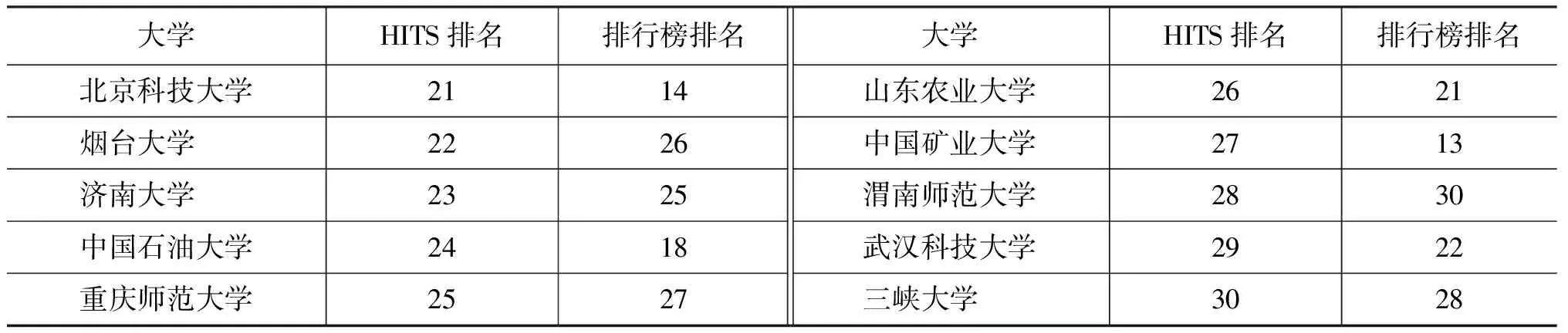
续表
本文采用信息检索中的NDCG值评价两排序结果的一致性,具体结果如图6所示。

图6 排序结果比较
由表6可得,基于HITS的网页挖掘优化算法对网站权威性的预测结果与真实数据之间具有一定程度的一致性(NDCG值均在80%以上,当r值取30时,NDCG值最高为95%;当r值取5时,NDCG值最低为83%)。但仍存在一定误差,原因在于: 基于HITS的优化算法仅考虑网站之间的链接信息,而真实的大学排名则融合更多因素予以考虑。但本文所提基于HITS的优化方法更具通用性,在很多其它领域(如: 电子器件、环保领域等),网站真实排名往往难以获取,由此说明本文所提基于HITS的网页挖掘优化方法在预测网站权威度时的有效性。
为验证本文所提“领域权威度高的网站蕴含高质量双语句对”的假设,以及基于HITS和GHITS算法优化的双语句对挖掘方法的有效 性,本 文 利 用
挖掘所得高质量领域双语平行句对,扩充机器翻译系统训练集,构建中到英的特定领域机器翻译系统。并与Liu等[7]所提双语句对选择方法进行对比。统计机器翻译系统在各测试集下未登录词数量统计如表5所示。

表5 机器翻译未登录词数量统计
统计机器翻译系统在各测试集下的性能如下表6所示。

表6 机器翻译系统性能
通过观察表6数据,HITS_TopN在4个测试集中的平均BLEU值(20.41%),较HITS_TailN(BLEU值为19.02%)提升个1.39个BLEU值;且由表5可知,翻译系统的训练语料在4个测试集下覆盖度大致相同(未登录词OOV的个数大体一致),该数据现象表明,HITS_TopN系统BLEU值提升的原因在于语料的质量,即领域权威度高的网站中所蕴含的双语句对,包含更多有效的领域翻译知识和语言现象。由此,证明本文所提“领域权威度高的网站蕴含高质量句对”的假设。
另一方面,通过观察表6数据,HITS_TopN在四个测试集的平均BLEU值(20.41%),较Tm_Lm_Method提升0.44个BLEU值。且由表5可知,翻译系统的训练语料在四个测试集下覆盖度大致相同(未登录词OOV个数大体一致),该数据现象表明,本文所提基于HITS网页挖掘优化算法与当前基于句对内部特征的双语句对选择方法相比,性能基本一致。但基于句对内部特征的双语句对选择方法需抽取目标领域网站集合中的全部句对,实现较为复杂;本文所提方法,实现简单效率,效率较高。从而,进一步证明本文所提基于HITS算法方法双语挖掘优化方法的有效性。
最后,通过观察表6数据,发现GHITS_TopN在四个测试集中的平均BLEU值,较HITS_TopN系统提升0.40个BLEU值,较Tm_Lm_Method提升0.84个BLEU值。且由表5可知,翻译系统的训练语料在4个测试集下覆盖度大致相同(未登录词OOV的个数大体一致),该数据现象表明表6中,GHITS_TopN系统BLEU值提升的原因在于语料质量。由此,验证本文所提基于GHITS的双语句对挖掘优化方法的有效性。
综上所述,本文所提基于HITS算法的双语挖掘优化方法,从句对的来源(即特定领域双语网站)出发,有效地利用网站之间的链接信息,判定句对的质量。与基于文本特征的句对质量评价方法相比,该方法无需抽取网站集合中蕴含的所有双语句对,实现简单,效率较高。权威性高的网站蕴含的句对,其领域性和平行性均较好,因此本文所提方法可以有效地融合领域性和平行性用于评价句对的质量。此外,本文所提方法适用于任何领域,具有很好的通用性。
7 总结与展望
本文针对特定领域双语网站句对质量不平衡的问题,提出一种基于HITS算法优化双语网页挖掘,并获取高质量双语句对的方法。该方法通过网站之间的链接信息建立有向图模型,利用HITS算法度量网站的权威性,在此基础上,仅从权威性高的网站中抽取双语句对,用于训练特定领域机器翻译系统。
本文以教育领域为目标,通过实验验证所提“领域权威性高的网站蕴含高质量句对” 的假设,且利用本文所提方法构建的特定领域机器翻译系统较对比系统,平均性能提升0.44个BLEU值,从而验证本文所提方法的有效性。针对HITS算法存在的“主题偏离”问题,本文提出基于文本和链接信息相结合的GHITS改进算法。实验中,基于GHITS算法的翻译系统性能继续提升0.40个BLEU值。
在未来工作中,将尝试更多评价网站权威度的方法(如PageRank等),并尝试句对的文本信息和来源信息相结合,提出更有效的高质量双语句对挖掘方法。
[1] Resnik Philip. Parallel strands: A preliminary investigation into mining the web for bilingual text[M]. Springer Berlin Heidelberg: 1998.
[2] Chen Jiang, JianYun Nie. Automatic construction of parallel English-Chinese corpus for cross-language information retrieval[C]//Proceedings of the 6th conference on Applied natural language processing(ANLC). 2000: 21-28.
[3] Long Jiang, Shiquan Yang, Ming Zhou et al. Mining Bilingual Data from the Web with Adaptively Learnt Patterns[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP(ACL-IJCNLP). Suntec, Singapore, 2009, 2: 870-878.
[4] Rarrick, Spencer, Chris Quirk, et al. MT detection in web-scraped parallel corpora[C]//Rroceedings of The Thirteenth Machine Translation Summit(MT Summit XIII). Xiamen, China, 2011, 422-429.
[5] Arase, Yuki, Ming Zhou. Machine Translation Detection from Monolingual Web-Text[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics(ACL). Sofia, Bulgaria, 2013: 1597-1607.
[6] Munteanu, Dragos Stefan, Daniel Marcu. Improving machine translation performance by exploiting non-parallel corpora[J]. Computational Linguistics, 2005, 31(4): 477-504.
[7] Le Liu, Yu Hong, Hao Liu. Effective Selection of Translation Model Training Data[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics(ACL). Baltimore, Maryland, USA, 2014, 569-573.
[8] 刘昊,洪宇,刘乐等. 基于全局搜索和局部分类的特定领域双语网站识别方法[C]//第二十届全国信息检索学术会议(CCIR). KunMing, China, 2014.
[9] Ma, Xiaoyi, and Mark Liberman. Bits: A method for bilingual text search over the web[C]//The eighth Machine Translation Summit(MT Summit VIII). 1999: 538-542.
[10] 叶莎妮,吕雅娟,黄赟等. 基于Web的双语平行句对自动抽取[J]. 中文信息学报, 2008, 22(5): 67-73.
[11] 冯艳卉,洪宇,颜振祥,姚建民,朱巧明. 基于搜索引擎的双语混合网页识别新方法[J]. 中文信息学报, 2011, 25(1): 71-78.
[12] Smith, Jason R., Chris Quirk, et al. Extracting parallel sentences from comparable corpora using document level alignment[C]//Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics(NAACL). LOS ANGELES, USA, 2010, 403-411.
[13] Bharadwaj, Rohit G., and Vasudeva Varma. Language independent identification of parallel sentences using Wikipedia[C]//Proceedings of the 20th International Conference Companion on World Wide Web(WWW). Hyderabad, India. 2011, 11-12.
[14] Pavel Pecina, Vassilis Papavassiliou. Towards Using Web-Crawled Data for Domain Adaptation in Statistical Machine Translation[C]//Proceedings of the 15th Conference of the European Association for Machine Translation. Leuven, Belgium, 2011, 297-304.
[15] 黄瑾,吕雅娟,刘群. 基于信息检索方法的统计翻译系统训练数据选择与优化[J]. 中文信息学报, 2008, 22(2): 40-46.
[16] Keiji Yasuda, Ruiqiang Zhang, Hirofumi Yamamoto, et al. Method of selecting training data to build a compact and efficient translation model[C]//Proceedings of the International Joint Conference on Natural Language Processing(IJCNLP). Hyderabad, India, 2008: 655-660.
[17] Foster, George, Cyril Goutte, et al. Discriminative Instance Weighting for Domain Adaptation in Statistical Machine Translation[C]//Proceedings of the Empirical Methods in Natural Language Processing(EMNLP). Massachusetts, USA, 2010: 451-469
[18] Axelrod, Amittai, Xiaodong He, et al. Domain adaptation via pseudo in-domain data selection[C]//Proceedings of the 2011 Conference on Empirical Method in Natural Language Processing(EMNLP). Scotland, UK, 2011, 355-362.
[19] Kevin Duh, Graham Neubig, Katsuhito Sudoh,et al. Adaptation Data Selection using Neural Language Models: Experiment in Machine Translation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics(ACL).Sofia, Bulgaria, 2013, 678-683.
[20] Jon M. Kleinberg. Authoritative sources in a hyperlinked environment[J]. Journal of the ACM (JACM), 1999, 46(5): 604-632.
[21] Brin, Sergey, and Lawrence Page. The anatomy of a large-scale hypertextual Web search engine[J]. Computer networks and ISDN systems, 1998, 30(1): 107-117.
[22] 范聪贤, 徐汀荣, 范强贤. Web 结构挖掘中 HITS 算法改进的研究[J]. 微计算机信息, 2010 (3): 160-162.
[23] Franz Joset Cch, Hermann Ney. A systematic comparison of various statistical alignment models[J]. Computational Linguistics, 2003,29(1): 19-51.
[24] Och, Franz Josef. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics(ACL). Association for Computational Linguistics, 2003, 160-167.
[25] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association for computational linguistics(ACL). Association for Computational Linguistics, 2002: 311-318.
HITS-Based Optimization Method for Bilingual Corpus Mining
LIU Hao, HONG Yu, Yao Liang, LIU Le, YAO Jianmin, ZHOU Guodong
(Provincial Key Laboratory of Computer Information Processing TechnologySoochow University, Suzhou, Jiangsu 215006, China)
Identifying and locating domain-specific bilingual websites is a crucial step for the Web-based bilingual resource construction. However, the quality of sentence pairs varies among different bilingual websites. In contrast to the existing method focusing only on the sentence internal features, we explore the sentence pairs' origin information for identifying and filtering the low-quality sentences pairs. We hypothesize that, if a website is authoritative in the target domain, it tends to contain more high-quality sentence pairs. Thus, we propose a HITS based optimization method for mining domain-specific bilingual sentence pairs. In this method, we first construct a directed-graph model based on the link-info among the websites. Secondly, we propose a HITS based method for evaluating the authority of websites. Finally, we only extract the sentence pairs from the authoritative websites, and use them to enlarge the training-set of our machine translation system. Experimented on the education domain, our system achieves improvements of 0.44% BLEU score compared with existing method. A further proposed GHITS method achieve additional improvements of 0.40% BLEU score.
statistical machine translation; specific-domain machine translation; specific-domain bilingual websites; authority; HITS

刘昊(1990—),硕士研究生,主要研究领域为统计机器翻译,自然语言处理。E⁃mail:liuhao19900412@gmail.com洪宇(1978—),博士后,副教授,主要研究领域为话题检测、信息检索和信息抽取。E⁃mail:tianxianer@gmail.com姚亮(1993—),硕士研究生,主要研究领域为统计机器翻译,自然语言处理。E⁃mail:yaoliang310@163.com
2015-02-04 定稿日期: 2015-05-10
国家自然科学基金(61373097, 61272259, 61272260, 90920004);教育部博士学科点专项基金(2009321110006, 20103201110021);江苏省自然科学基金(BK2011282);江苏省高校自然科学基金重大项目(11KJA520003);苏州市自然科学基金(SH201212)
1003-0077(2017)02-0025-11
TP391
A
