基于多任务学习的多姿态人脸重建与识别
2017-05-24欧阳宁马玉涛林乐平
欧阳宁, 马玉涛, 林乐平
(1.认知无线电与信息处理省部共建教育部重点实验室(桂林电子科技大学),广西 桂林 541004; 2.桂林电子科技大学 信息与通信学院,广西 桂林 541004) (*通信作者电子邮箱lin_leping@163.com)
基于多任务学习的多姿态人脸重建与识别
欧阳宁1,2, 马玉涛2, 林乐平1,2*
(1.认知无线电与信息处理省部共建教育部重点实验室(桂林电子科技大学),广西 桂林 541004; 2.桂林电子科技大学 信息与通信学院,广西 桂林 541004) (*通信作者电子邮箱lin_leping@163.com)
针对当前人脸识别中姿态变化会影响识别性能,以及姿态恢复过程中脸部局部细节信息容易丢失的问题,提出一种基于多任务学习的多姿态人脸重建与识别方法——多任务学习堆叠自编码器(MtLSAE)。该方法通过运用多任务学习机制,联合考虑人脸姿态恢复和脸部局部细节信息保留这两个相关的任务,在步进逐层恢复正面人脸姿态的同时,引入非负约束稀疏自编码器,使得非负约束稀疏自编码器能够学习到人脸部的部分特征;其次在姿态恢复和局部信息保留两个任务之间通过共享参数的方式来学习整个网络框架;最后将重建出来的正脸图像通过Fisherface进行降维并提取具有判别信息的特征,并用最近邻分类器来识别。实验结果表明,MtLSAE方法获得了较好的姿态重建质量,保留的局部纹理信息清晰,而且与局部Gabor二值模式(LGBP)、基于视角的主动外观模型(VAAM)以及堆叠步进自编码器(SPAE)等经典方法相比,识别率性能得以提升。
多任务学习;姿态恢复;局部细节信息;自编码器;共享参数
0 引言
人脸识别在证件验证、刑侦破案、视频监控、入口控制等安全领域有着广泛的应用,一直是计算机视觉领域中的研究热点。研究者们将人脸识别方法应用到了可控[1]和非可控环境[2-3]中,且均取得了重大进展,但是无论在哪一种环境中,由姿态变化引起的识别性能降低仍是一项巨大的挑战。
近年来,为了解决由姿态变化带来的识别问题,研究者们主要集中在运用2D和3D方法两大类。Zhang等[4]提出基于人脸表达的非统计方法,通过连接局部Gabor二进制模式(Local Gabor Binary Pattern, LGBP)映射图的所有局部区域中的直方图来将人脸图像建模为直方图序列;Asthana等[5]通过3D姿态归一化方法,提出全自动姿态不变人脸识别方法,该方法利用基于视角的主动外观模型(View-based Active Appearance Model, VAAM)将3D模型匹配到2D图像中;Ho等[6]提出一种利用马尔可夫随机场(Markov Random Field, MRF)从非正面人脸图像重建虚拟正面人脸角度的方法。随着深度学习研究的发展,基于深度学习的人脸姿态恢复取得了很大的进步。Zhu等[7]利用深度卷积网络(Deep Convolutional Network, DCN)在特征提取层中将任意姿态和光照的人脸图像编码成脸部身份保留(Face Identity-Preserving, FIP)特征,然后通过重建层将FIP特征解码成没有光照和角度的正脸;而在文献[8]中,他们又在多层感知器(MultiLayer Perceptron, MLP)的基础上,提出一个多视角感知(Multi-View Perceptron, MVP)的深度神经网络。上述两种方法都获得了较好的人脸姿态重建效果。文献[7]中的DCN含有3个局部连接层和2个池化层,而文献[8]中的MVP含有3层只有确定神经元以及3层既有确定神经元又有随机神经元共6层的网络结构。它们需要训练和微调较多的权值参数,要求硬件配置具有强大的计算能力。此外,深度自编码网络(Deep Auto-Encoder, DAE)[9]是将多姿态人脸图像通过多个隐含层直接映射成正脸图像,而Kan等[10]针对由姿态差异引起的脸部外表变化比由身份差异引起的变化大的问题,提出了堆叠步进自编码器(Stacked Progressive Auto-Encoder, SPAE)的人脸重建方法,该方法通过建模侧脸和正脸之间复杂的非线性变换,用一种浅层步进自编码的方式将较大姿态的人脸图像逐步映射成较小姿态的图像,直至角度为0°。这种方法相比卷积神经网络和3D等方法方便简单,训练参数少,而且取得了很好的正脸重建效果;但是在某种程度上,这种方法会使得恢复出的正脸图像的局部细节信息不清晰,导致识别率降低。
针对以上方法中的不足,本文运用多任务学习(Multi-task Learning, MtL)[11-12]方法联合考虑人脸姿态恢复和脸部局部信息保留这两个相互制约但是又相关的任务,在堆叠自编码器的基础上,提出了基于多任务学习的多姿态人脸重建与识别方法,即多任务学习堆叠自编码器(Multi-task Learning Stacked Auto-Encoder, MtLSAE)。MtLSAE方法在使用堆叠自编码器步进逐层恢复正面人脸姿态的同时[10],又引入基于部分特征表达的非负约束稀疏自编码器[13],来保留输入数据的局部特征信息,从而提高输入数据的重建质量。然后通过在编码过程中共享参数,将姿态恢复和局部信息保留这两个互相有着制约关系的任务又联系到了一起。最后将重建出来的正面人脸图像通过Fisherface[14]方法进行降维,再用最近邻分类器进行识别。实验仿真结果显示,用本文方法重建出来的人脸图像不仅消除了姿态误差,而且脸部的局部纹理信息更清晰,获得了较好的姿态重建质量,并且与其他针对姿态变化的人脸识别方法相比,识别率有了较大的提升。
1 基于多任务学习的人脸姿态重建
1.1 多任务人脸重建框架
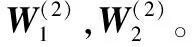
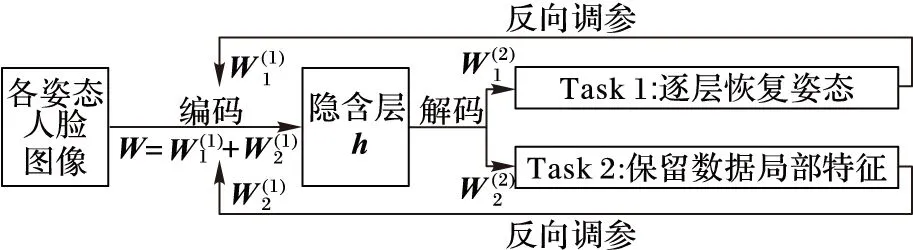
图1 多任务学习结构
1.2 自编码器
自编码器(Auto-Encoder,AE)[9]是一种尽可能复现输入信号的无监督神经网络,由编码器和解码器两部分组成,它使用反向传播(BackPropagation,BP)算法,使目标值等于输入值,即:
(1)
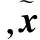
编码过程:AE的编码过程是将输入向量x∈Rdx通过编码函数f(x)映射到隐含层h∈Rdh中,即:
h=f(x)=sf(W1x+b1)
(2)
其中:W1∈Rdh×dx,b1∈Rdh×1,dx和dh分别是输入数据的维数和隐含层节点个数。
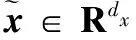
(3)
其中:W2∈Rdx×dh,b2∈Rdx×1。上述公式中的sf和sg分别是编码器和解码器的激活函数,它是sigmoid函数、双曲正切函数或是rectifier函数[15],本文使用sigmoid激活函数,其表达式如下:
s(t)=sigmoid(t)=(1+e-t)-1
(4)
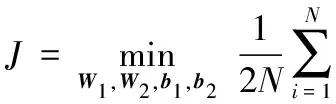
(5)
其中,N是训练样本的数量。这样,整个AE通过不断迭代更新参数来减小误差,从而能够更好地提取输入层的特征。
2 人脸重建MtLSAE方法
MtLSAE人脸重建方法由预训练和微调两部分组成,图2为整个多任务学习堆叠自编码器的网络结构,由三个AE堆叠而成,前一个AE训练得到的共享隐含层特征h作为后一个AE的输入,如此堆叠三个AE。整个网络结构简单,便于实现。其中图2(a)是多任务学习人脸重建结构图,图2(b)是网络微调结构图。
2.1 多任务网络预训练学习过程
在预训练过程中用多任务学习方法来学习姿态恢复和局部信息保留这两个任务,通过在编码过程中共享参数,整个模型能够得到很好的人脸重建效果。模型总的损失函数如式(6)所示:
J=Jpose+αJlocal
(6)
其中:Jpose表示图2任务1中堆叠步进自编码器的损失函数,Jlocal表示图2任务2中非负约束稀疏自编码器的损失函数,α用来权衡两个任务的相对重要程度。
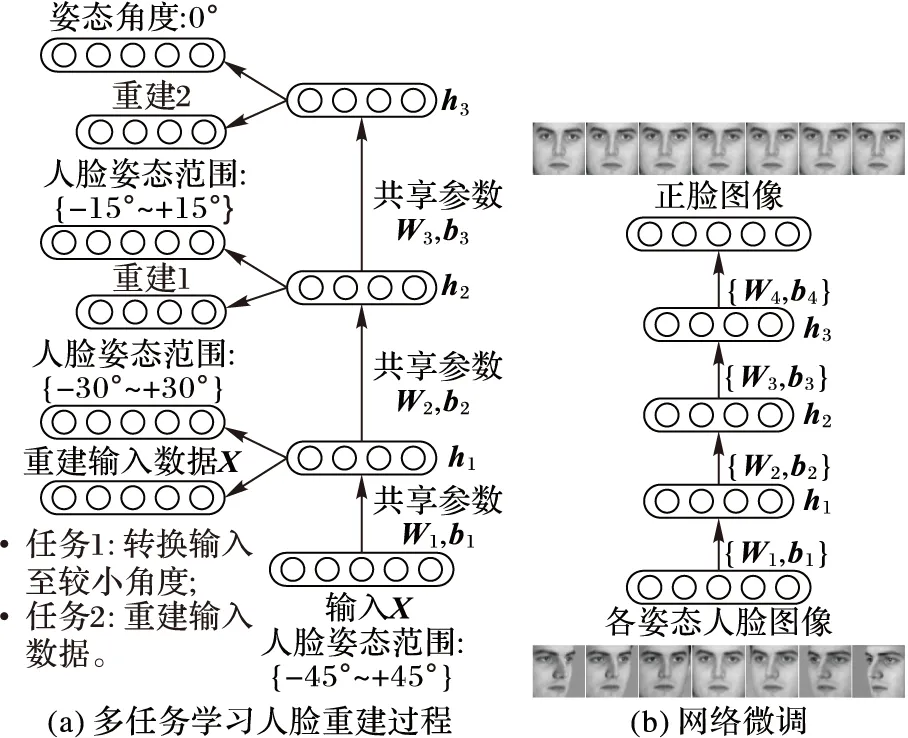
图2 多任务学习堆叠自编码器网络结构
在任务1中,有角度p1~pk,其中pk>pk-1>…>p1>0,与此对称的角度为-pi(i=1,2,…,k),以p0表示正脸姿态,所以共2k+1种姿态。将各姿态的图像作为第一层AE的输入,在输出时候将-pk和pk角度的图像分别映射到-pk-1和pk-1,其余角度分别映射到本身;接着将第一层AE学习到的隐含层特征h1作为第二层AE的输入,且在解码时将所有-pk-1和pk-1角度的图像再依次映射到-pk-2和pk-2,以此类推,不断堆叠和映射,使得最后一个自编码器的输出图像角度全为p0,整个过程通过步进的方式逐步消除了角度误差。每一层AE的重建误差通过均方误差来建立,如式(7)所示:
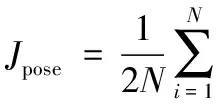
(7)
其中:xlarger表示每一层AE中带有较大姿态的人脸图像的输入,f(·)表示每一层AE的编码函数,g(·)则是解码函数,xsmaller表示每一层AE期望映射的较小姿态的图像,N是训练样本个数。
在任务2中,主要任务聚集在图像局部信息的保留。通过非负约束稀疏自编码器,来约束AE中的权值W,使其为非负。对权值使用了非负约束时,只有部分权值是非零的,因此,权值会变得稀疏,从而输入数据在编码过程将被分解为一些稀疏的部分,而在解码过程又将这些稀疏部分组合到一起来重建输入数据,整个过程提高了稀疏性和重建质量。第二个任务的本质是重建输入数据,损失函数如式(8)所示:
Jlocal=JAE+λJwd+βJsparse
(8)
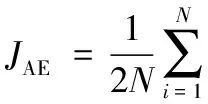
(9)
(10)
s.t.Wjk<0
(11)
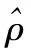
(12)
上述的两个任务通过总的损失函数J来建立,通过最小化误差函数J,使用梯度下降法来更新网络参数,公式如下所示:
(13)
(14)
其中,η>0是学习速率。本文使用共轭梯度(ConjugateGradient,CG)优化算法来求解总的目标函数式(6)的最小值点。CG通过一系列线搜索来找到误差函数最小值的方向,自动调整学习速率以得到合适的步长,最终能够使W、b快速收敛到一个局部最优解[18]。
2.2 网络微调学习过程
网络微调结构图如图2(b)所示,由一个输入层、三个隐含层以及一个输出层构成。在预训练之后,网络中的权值和偏置向量有了初始值,在微调阶段,以各姿态的人脸图像作为输入,以正脸姿态的图像作为期望输出,从而对网络进行微调,且通过最小化式(15)的损失函数来训练网络。
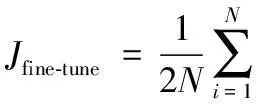
(15)
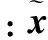
通过预训练和微调过程,本文将输出层重建出来的人脸图像通过Fisherface对其进行降维,最后用最近邻分类器来识别。
3 实验仿真与结果分析
本文在MultiPIE数据库[19]上验证了MtLSAE算法的有效性。该数据库包含337个人共754 204张不同姿态、表情、光照的人脸图片,这些图片在不同时期采集得到且存储于四个文件中,每个文件中每个人有15种姿态,在同一个姿态下又包含20种不同的光照。本文选取MultiPIE数据库的一个子集,包含-45°~+45°角度范围内的7种姿态,姿态间的角度间隔为15°。所选取的人脸图像均在正常光照条件下成像,并具有正常表情。图像大小对齐裁剪为40×32,同时选取四个文件中前200个人中的198人共4 046张图片作为训练图片,其余的137个人中选取90人共1 659张图片用来做测试;在测试集中选取正脸图像为参考图像(Galleryimages),其余各姿态为测试图像(Probeimages)。
实验中选取局部Gabor二值模式(LGBP)、深度自编码器(DAE)、基于视角的主动外观模型(VAAM)、马尔可夫随机场(MRF)、堆叠步进自编码器(SPAE)进行识别率对比实验,而且还与SPAE方法进行了细节图的对比,以验证本文方法的性能。实验中总的损失函数式(6)和非负约束稀疏自编码器的损失函数式(8)中的参数α、λ、β的选取以及隐含层节点个数的设置通过交叉验证[20]的方法来获得,即为了选择好的模型,设置不同的参数取值在训练集上训练模型,从而得到不同的模型,在测试集上评价各个模型的测试误差,从而选出性能指标最好的模型。本文经交叉验证,取经验值α=0.05,λ=0.001,β=0.01。在自编码器中,如果隐含层节点个数过少,网络不具有良好的学习能力和信息处理能力;反之,节点个数过多,不仅会大幅度增加网络结构的复杂性,而且网络在学习过程中更易陷入局部极小点,从而使网络的学习速度变得很慢。对此,比较了不同节点数对网络性能的影响,如表1所示。
从表1中可以看出,当隐含层节点数均为2 500时,网络性能最好,原因在于节点数过多,学习到的隐含层特征含有过多的冗余信息,会降低网络的学习效率;反之,由于姿态恢复是非线性的变换,节点数太少时,人脸重建图像又不能得到更好的表达,也会降低网络性能。所以本文中,隐含层节点个数设置为2 500。
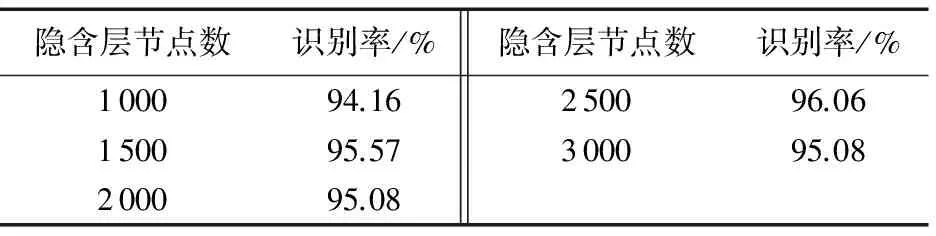
表1 不同隐含层节点数对应的平均识别率对比
本文方法的各姿态重建效果如图3所示,图4为本文方法和SPAE方法的细节效果图对比,表2为各方法的识别率对比,表3是不同姿态重建方法的结构相似度(StructuralSIMilarityindex,SSIM)对比。从图3中可以看出,本文方法重建出的正脸图像不仅保持了个体内在的形状和结构特性,而且对于戴眼镜以及脸部有胡子的人脸图像原图,在正脸重建过程中这些信息都得以很好地保留,这说明本文方法对保持局部纹理信息具有一定的作用,在人脸姿态重建过程中不会丢失太多脸部局部信息。在图4(a)和图4(b)中,本文方法重建出的人脸图像保留的眼镜边框更清晰,而且从视觉观测上来看,图(a)嘴和人中穴处的胡子与图(b)的眉梢都要比SPAE的结果清晰,细节纹理信息保留更全面;同样在图4(c)中,虽然SPAE看起来较平滑,但是在嘴唇下面的胡子处丢失了细节信息,而MtLSAE看起来保留的细节信息更多;在图4(d)中,MtLSAE的眉毛明显要比SPAE的清晰,且眉弓的角度更明显,视觉效果好。由于本文中的图像均选取为40×32大小的低分辨率图像,所以图4中的对比图像是在放大的情况下得到的,虽然放大后的图像整体看起来模糊,但是仍然可以对比出细节信息。
表2为在MultiPIE数据库上不同姿态重建方法识别率对比。从表中可以看出,当姿态角度很小时,如在±15°,除了LGBP算法以外,各算法的性能均很好,识别率都有很大的提升;当姿态角度增大时,即在±30°和±45°时,上述各算法的性能都有所下降,虽然本文方法在±45°也下降了一些,但是整体而言仍要高于其他方法,保持了较高的识别率。表3是当姿态角度为-45°、-30°、+30°、+45°时,MtLSAE方法与SPAE方法的重建正脸图像与原始正脸图像SSIM对比结果。从表3中可以看到,MtLSAE算法在+30°与+45°时的SSIM优于SPAE方法,-45°时两种方法的SSIM大致相当。可见即便姿态角度偏转较大时,MtLSAE算法仍可以获得不错的重建效果,且重建后的图像可以保持较好的人脸结构特性;与SPAE方法相比,SSIM稍为占优。

图3 用MtLSAE算法从各姿态重建出来的正脸图像与原图像对比
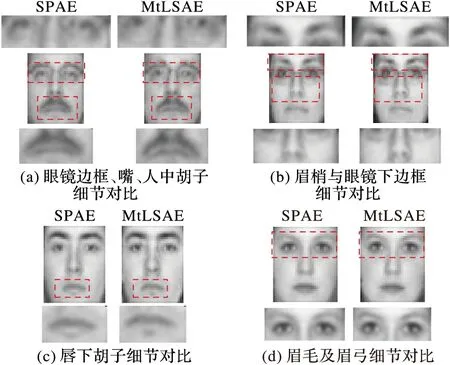
图4 SPAE方法与本文MtLSAE方法的细节对比
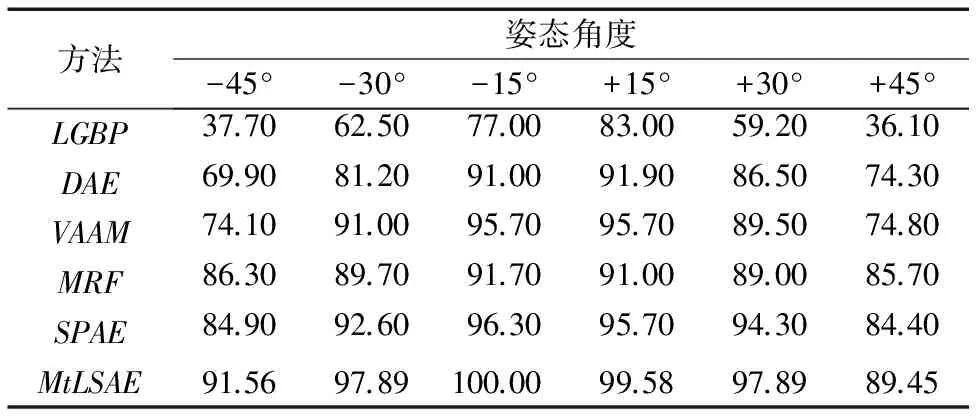
Tab. 2 Comparison of recognition rate for different posturesrestructured by different methods on MultiPIE database%
通过上述实验结果分析,本文MtLSAE算法重建出来的正脸图像,不仅消除了姿态变化带来的误差,而且在姿态恢复过程中使得人脸的局部纹理信息更清晰,结构特性保持较好,且性能优于对比的其他算法,取得了较好的成果。
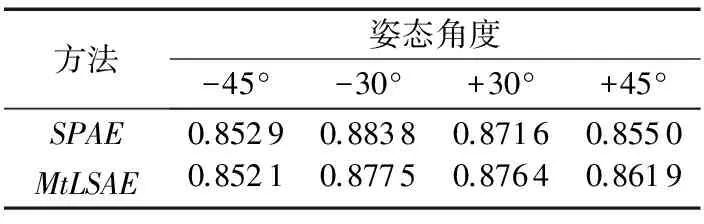
表3 不同姿态重建方法的SSIM对比
4 结语
本文提出了基于多任务学习堆叠自编码器的人脸重建与识别方法,该方法运用多任务学习机制,在通过堆叠自编码器逐层恢复人脸姿态的同时,学习非负约束稀疏自编码器,从而使得在每一层网络中,姿态变化减小的同时又保留了这一层输入数据的局部信息。这两个相关但又相互制约的任务通过在编码过程中共享参数来学习整个网络,使得在堆叠自编码器的顶层重建出来的人脸图片,不仅消除了姿态差异,还保留了脸部的局部信息。实验结果显示,本文方法取得了很好的人脸重建效果,一定程度上提高了人脸重建质量,达到了预期效果。未来的研究工作将寻求更好的重建方法,同时考虑光照和表情在姿态重建中的影响,融合多种影响识别性能的因素来重建人脸,以此进一步提高识别率;同时也要考虑参数的优化设置,如权重衰减参数和稀疏惩罚因子对重建效果的影响。
)
[1]TANX,TRIGGSB.Enhancedlocaltexturefeaturesetsforfacerecognitionunderdifficultlightingconditions[J].IEEETransactionsonImageProcessing, 2010, 19(6): 1635-1650.
[2]HUANGGB,RAMESHM,BERGT,etal.Labeledfacesinthewild:adatabaseforstudyingfacerecognitioninunconstrainedenvironments[R].Cambridge:UniversityofMassachusetts, 2007: 49.
[3]GÜNTHERM,COSTA-PAZOA,DINGC,etal.The2013facerecognitionevaluationinmobileenvironment[C]//ICB2013:Proceedingsofthe2013InternationalConferenceonBiometrics.Piscataway,NJ:IEEE, 2013: 1-7.
[4]ZHANGW,SHANS,GAOW,etal.LocalGaborBinaryPatternHistogramSequence(LGBPHS):anovelnon-statisticalmodelforfacerepresentationandrecognition[C]//ICCV’05:ProceedingsoftheTenthIEEEInternationalConferenceonComputerVision.Washington,DC:IEEEComputerSociety, 2005, 1: 786-791.
[5]ASTHANAA,MARKSTK,JONESMJ,etal.Fullyautomaticpose-invariantfacerecognitionvia3Dposenormalization[C]//ICCV’11:Proceedingsofthe2011InternationalConferenceonComputerVision.Washington,DC:IEEEComputerSociety, 2011: 937-944.
[6]HOHT,CHELLAPPAR.Pose-invariantfacerecognitionusingMarkovrandomfields[J].IEEETransactionsonImageProcessing, 2013, 22(4): 1573-1584.
[7]ZHUZ,LUOP,WANGX,etal.Deeplearningidentity-preservingfacespace[C]//ICCV’13:Proceedingsofthe2013IEEEInternationalConferenceonComputerVision.Washington,DC:IEEEComputerSociety, 2013: 113-120.
[8]ZHUZ,LUOP,WANGX,etal.Multi-viewperceptron:adeepmodelforlearningfaceidentityandviewrepresentations[C]//NIPS2014:AdvancesinNeuralInformationProcessingSystems.Cambridge,MA:MITPress, 2014: 217-225.
[9]BENGIOY.LearningdeeparchitecturesforAI[J].FoundationsandTrendsinMachineLearning, 2009, 2(1): 1-127.
[10]KANM,SHANS,CHANGH,etal.StackedProgressiveAuto-Encoders(SPAE)forfacerecognitionacrossposes[C]//CVPR’14:Proceedingsofthe2014IEEEConferenceonComputerVisionandPatternRecognition.Washington,DC:IEEEComputerSociety, 2014: 1883-1890.
[11]SHIELDSTJ,AMERMR,EHRLICHM,etal.Action-affectclassificationandmorphingusingmulti-taskrepresentationlearning[J/OL].arXivpreprintarXiv:1603.06554, 2016 〖2016- 03- 21〗.https://arxiv.org/abs/1603.06554.
[12]ARGYRIOUA,EVGENIOUT,PONTILM.Multi-taskfeaturelearning[C]//NIPS2006:AdvancesinNeuralInformationProcessingSystems.Cambridge,MA:MITPress, 2007, 19: 41-48.
[13]HOSSEINI-ASLE,ZURADAJM,NASRAOUIO.Deeplearningofpart-basedrepresentationofdatausingsparseautoencoderswithnonnegativityconstraints[J].IEEETransactionsonNeuralNetworksandLearningSystems, 2015, 27(12): 1-13.
[14]BELHUMEURPN,HESPANHAJP,KRIEGMANDJ.Eigenfacesvs.fisherfaces:recognitionusingclassspecificlinearprojection[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 1997, 19(7): 711-720.
[15]NAIRV,HINTONGE.RectifiedlinearunitsimproverestrictedHoltzmannmachines[C]//ICML-10:Proceedingsofthe27thInternationalConferenceonMachineLearning.Haifa:Omnipress, 2010: 807-814.
[16]GRAVELINESC.Deeplearningviastackedsparseautoencodersforautomatedvoxel-wisebrainparcellationbasedonfunctionalconnectivity[D].Ontario,Canada:TheUniversityofWesternOntario, 2014: 1-76.
[17]LEEH,EKANADHAMC,NGAY.SparsedeepbeliefnetmodelforvisualareaV2 [C]//NIPS2007:AdvancesinNeuralInformationProcessingSystems.Cambridge,MA:MITPress, 2008: 873-880.
[18]NGA,NGIAMJ,FOOCY,etal.UFLDLTutorial[EB/OL]. (2013- 04- 07) 〖2016- 08- 26].http://deeplearning.stanford.edu/wiki/index.php/Gradient_checking_and_advanced_optimization.
[19]GROSSR,MATTHEWSI,COHNJ,etal.TheCMUmulti-pose,illumination,andexpression(Multi-PIE)facedatabase,TR- 07- 08 [R].Pittsburgh:CMURoboticsInstitute, 2007.
[20] 李航.统计学习方法[M].北京:清华大学出版社,2012:14-15. (LIH.StaticalLearningMethods[M].Beijing:TsinghuaUniversityPress, 2012: 14-15.)
ThisworkispartiallysupportedbytheNaturalScienceFoundationofChina(61362021, 61661017),theNaturalScienceFoundationofGuangxi(2013GXNSFDA019030, 2014GXNSFDA118035),theScientificandTechnologicalInnovationAbilityandConditionConstructionPlanofGuangxi(1598025-21),theScientificandTechnologicalDevelopmentProjectofGuilin(20150103-6).
OUYANG Ning, born in 1972, M. S., professor. His research interests include digital image processing, intelligent information processing.
MA Yutao, born in 1991, M. S. candidate. Her research interests include face recognition, deep learning.
LIN Leping, born in 1980, Ph. D. Her research interests include pattern recognition, intelligent information processing, image signal processing.
Multi-pose face reconstruction and recognition based on multi-task learning
OUYANG Ning1,2, MA Yutao2, LIN Leping1,2*
(1.KeyLaboratoryofCognitiveRadioandInformationProcessing,MinistryofEducation(GuilinUniversityofElectronicTechnology),GuilinGuangxi541004,China; 2.SchoolofInformationandCommunication,GuilinUniversityofElectronicTechnology,GuilinGuangxi541004,China)
To circumvent the influence of pose variance on face recognition performance and considerable probability of losing the facial local detail information in the process of pose recovery, a multi-pose face reconstruction and recognition method based on multi-task learning was proposed, namely Multi-task Learning Stacked Auto-encoder (MtLSAE). Considering the correlation between pose recovery and retaining local detail information, multi-task learning mechanism was used and sparse auto-encoder with non-negativity constraints was introduced by MtLSAE to learn part features of the face when recovering frontal images using step-wise approach. And then the whole net framework was learned by sharing parameters between above two related tasks. Finally, Fisherface was used for dimensionality reduction and extracting discriminative features of reconstructed positive face image, and the nearest neighbor classifier was used for recognition. The experimental results demonstrate that MtLSAE achieves good pose reconstruction quality and makes facial local texture information clear; on the other hand, it also achieves higher recognition rate than some classical methods such as Local Gabor Binary Pattern(LGBP), View-Based Active Appearance (VAAM) and Stacked Progressive Auto-encoder (SPAE).
multi-task learning; pose recovery; local detail information; auto-encoder; sharing parameter
2016- 08- 01;
2016- 09- 07。
国家自然科学基金资助项目(61362021,61661017); 广西自然科学基金资助项目(2013GXNSFDA019030,2014GXNSFDA118035);广西科技创新能力与条件建设计划项目(桂科能1598025- 21); 桂林科技开发项目(20150103- 6)。
欧阳宁(1972—),男,湖南宁远人,教授,硕士,主要研究方向:数字图像处理、智能信息处理; 马玉涛(1991—),女,内蒙古乌兰察布人,硕士研究生,主要研究方向:人脸识别、深度学习; 林乐平(1980—),女,广西桂平人,博士,主要研究方向:模式识别、智能信息处理、图像信号处理。
1001- 9081(2017)03- 0896- 05
10.11772/j.issn.1001- 9081.2017.03.896
TP391.3
A
