基于关联规则挖掘技术的学生数据分析系统的设计与实现
2017-05-13宋丽萍韦建国
宋丽萍,韦建国
(阜阳职业技术学院工程科技学院,安徽 阜阳 236000)
基于关联规则挖掘技术的学生数据分析系统的设计与实现
宋丽萍,韦建国
(阜阳职业技术学院工程科技学院,安徽 阜阳 236000)
数据挖掘技术的发展,使高校积累的大规模的数据得到了很好的利用.数据挖掘有很多研究方向,关联规则挖掘就是其中之一.对关联规则挖掘算法Apriori算法进行了分析和优化,对比了优化Apriori算法与原算法的性能,结果表明,优化后算法效率显著提高.基于Web技术和SQL Server2005,并采用优化的Apriori算法,设计并实现了一个学生数据分析系统;系统具有数据导入、数据预处理、数据挖掘等功能.
数据挖掘;关联规则;Apriori算法;系统
近年来随着高等学校扩招规模的进一步加大,国内各高校在校生人数不断上升,这无疑给高校的教学和管理工作带来新的挑战,如同其他领域一样,高校的教学和管理积累了大量的数据资源,比如教学、图书档案、招生就业、教学科研等.若能从这些累积的数据中挖掘出一些具有参考意义的信息,将有助于高校的教学和管理.本文以我校积累的大量学生数据为研究对象,对关联规则算法Apriori算法进行优化,并利用优化的算法设计并实现了一个关联规则挖掘系统.
1 关联规则挖掘
数据挖掘是对有用的信息内容进行深层次的分析与挖掘,而关联规则挖掘是非常重要的挖掘技术之一.关联规则反映的是一个事物与其他事物之间的相互关联性,如果事物之间存在有关联规则,那么通过其他事物就能够预测到其中一个事物[1].
2 关联规则挖掘步骤
(1)设定最小支持度,在数据库D中求出出现频率高的频繁项集;
(2)设定最小置信度,频繁项集产生强关联规则,产生的规则要满足最小支持度和最小置信度[2].
3 Apriori算法
关联规则挖掘的第一步是求频繁项集,也是关键的一步,要提高挖掘算法的总体性能,就要从提高频繁项集的效率入手.Apriori算法是众多关联规则挖掘算法中最经典且最具影响力的算法,该算法使用宽度优先的查找策略,基于候选项集来产生频繁项集,由频繁项集产生关联规则[3].
① 设初始候选集C1,k=1;
②在Lk中计算出每一个项集的支持度,并筛选出支持度大于Smin的项集,形成频繁项集Lk;
③ 如果Ck=θ,置L1={L1,L2,…,Lk}后终止,否则,对Lk的频繁项集进行自然连接运算Lk▷◁Lk,得项为k+l的候选集Ck+l;
④ 置k=k+1,转步②.
而在其中有两个重要步骤是最关键的,即为连接步和剪枝步.设k-1次扫描数据库D产生大小为k-1的频繁项集为Lk-1,从频繁项集Lk-l产生所有项为k的候选项集.
连接步:通过Lk-l与自身连接得到一个项为k的候选项集集合Ck.连接的规则为:如果
{il1,il2,…,ilk-2,is}∈Lk-1,
{il1,il2,…,ilk-2,it}∈Lk-1,
则
{il1,il2,…ilk-2,is}▷◁{il1,il2,…ilk-2,it}=
{il1,il2,…ilk-2,is,it}∈Lk,
项为k的候选集就是Ck=Lk-1▷◁Lk-1.
剪枝步.剪枝步是从连接得到的候选集中剪去不会产生频繁项集的候选项,形成新的候选集.设c∈Ck是k项集,若c的k-1个元素组成子集Ck-1,Ck-1不属于Lk-1,则从Ck中将c剪除.
在Apriori算法中,执行过程是基于多次扫描事务数据库来实现的,根据Apriori性质我们知道,频繁项集的所有子集必须都是频繁的.一旦从事务数据库D中求出频繁项集,由此产生的强关联规则是直截了当的,对于置信度计算如下:其中条件概率用项集支持度计数表示:
Confidence(A→B)=P(A|B)=support-count(A∪B)/support-count(A)
其中:项集A∪B的事务数用support-count(A∪B)表示,项集A的事务数用support-count(A)表示.
4 Apriori算法的优化思想
Apriori算法虽然操作简单但还存在一些缺点,因为每次产生候选项集都要扫描一遍事务数据库D,因此数据量比较大时,产生的候选项集是比较庞大的,对于计算机的运行时间和空间是一种大的挑战,另外每次寻找k频繁项集,都需要扫描一遍数据库,会产生很大的I/O负载.
在从候选项集产生频繁项集的过程中,有这样一个性质:一个项集如果是频繁项集当且仅当它的所有的子集都是频繁的.如果Ck中某个候选项集中有一个(k-1)-子集不属于Lk-1,那么这个项集可以被修剪掉而不再被考虑,利用这种修剪策略来减小候选项集Ck的大小,可以显著地改进生成所有频繁项集算法的性能[4].
5 算法性能比较
为了比较算法优化前与优化后的性能,进行了数值实验,首先给出一个进行实验评估的数据库:测试所用的数据来源于UCI数据集中的ThyroidDisease(甲状腺疾病)数据库,该数据库有7200条记录.实验使用MATLAB7.0软件,在CPU为2.4GMHz,内存为2G的计算机上完成的.
首先比较在最小支持度相同的情况下,规模不同的数据集挖掘的时间性能.此处将最小支持度设为10%,数据选取数据集中的前500条、1500条、4500条、7000条记录,利用这些数据比较Apriori算法在优化前与优化后生成所有频繁项集所用的时间.其比较结果如图1所示:

图1 相同最小支持度下的运算时间图
从图1可以看出,在不同规模的事务数据集下,优化后的Apriori算法所使用的运算时间均低于优化前的算法,这说明提高了运行效率,同时对于数据量比较小的数据库,优化前与优化后的算法运算时间差距不是很明显;但随着数据量的增加,两种算法的运算时间的差距越来越明显.
再次比较在不同的最小支持度下生成频繁项集的时间性能.数据采用数据集中全部的7200条记录,设定最小支持度分别为1%,5%,10%,15%,20%.其比较结果如图2所示.

图2 不同最小支持度下的运算时间图
图2说明了在相同的数据规模和不同的最小支持度下优化的Apriori算法的执行时间都比原算法的时间短,优化的Apriori算法运行效率高于原Apriori算法.当最小支持度比较大时,优化前与优化后没有明显的区别,但当最小支持度较小时,优化的Apriori算法效率有明显提高[5].
6 系统设计与实现
(1)系统的设计
本系统的设计目的主要有以下两点:一是为高职学校的学生管理工作提供帮助,二是为高职学校学生的就业提供参考.本系统的设计是为了适应当前高职教育的发展以及就业发展而设计的分析系统模型[6].
在进行数据挖掘之前,我们需要建立一个行之有效的数据挖掘过程模型,而数据挖掘过程模型主要有两种,一是Fayyad数据挖掘过程模型,二是CRISP-DM数据挖掘过程模型[7].本系统采用的是Fayyad数据挖掘过程模型,如图3所示:
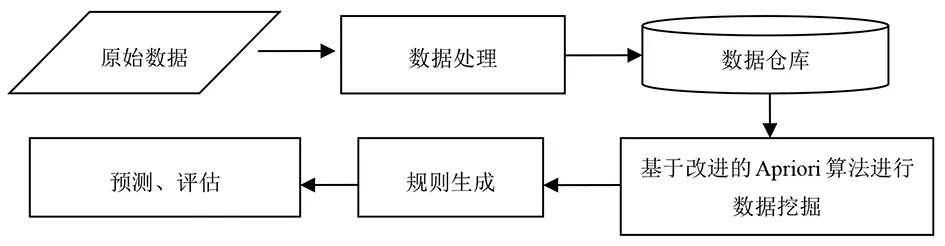
图3 Fayyad数据挖掘过程
(2)系统的实现
系统挖掘所利用的学生数据信息来自多个部门,本系统主要是由DTS(DataTransformationServices)抽取出同构的或异构的学生数据信息,对于采集到的这些数据信息,利用DTS完成数据选择,删除无用的数据[8].
根据高职院校学生的特点,使用优化的Apriori算法,通过对最小支持度和最小置信度进行选择后得到关联规则结果.
系统基于Web技术和SQLServer2005开发完成的可视化的交互式程序界面,较容易集成,确保用户在操作方面的简单方便.
图4 系统首页
图5 登录系统后截图
以下是本系统设计的主要功能模块的功能介绍:
系统管理模块.利用本模块,用户可以对设计的系统进行必要的管理操作.
学生信息管理模块.利用此模块,用户能够对学生的基本信息、学习成绩、就业信息等进行查询,还能进行添加、删除、修改等必要的数据管理操作.
数据预处理模块.本模块可按照用户设定的条件来选择合适的数据预处理的方法,将大量的学生信息进行数据预处理的操作.比如数据信息的离散化、数据泛化等各项处理.
数据挖掘模块.此功能模块是本系统中最重要的一个模块,利用本模块可以进行关联规则挖掘,挖掘出与相关专业学生就业联系紧密的因素.
报表打印模块.在实现信息查询结束后,使用“打印报表”模块,用户可以对系统挖掘产生的各项学生信息进行直接打印.
(3)关联规则挖掘实例
系统针对阜阳职业技术学院2010级护理专业学生数据进行处理和分析,数据表包括学生基本信息情况表、学生成绩表、技能鉴定成绩表、学生就业情况表,存储了采集到的学生所有的信息数据,表中已经将缺考、休学学生的数据记录已经去掉,形成了760条护理专业学生的有效记录.进入学生信息分析系统后,单击“数据预处理”这个按钮,系统会自动进行数据的处理,包括对数据信息的离散化、数据泛化、缺失数据的填充、删除冗余数据和成绩的综合处理等.在对数据进行预处理之后,就可以进行关联规则挖掘了.挖掘需要设定最小支持度和最小置信度,设定的最小支持度值越高,挖掘出的相关的规则就越少,挖掘过程也就越快.点击“关联规则挖掘”按钮, 进入“关联规则挖掘”界面,在页面中输入最小支持度为20%、最小置信度为55%,经过挖掘后,得到的结果如图6.
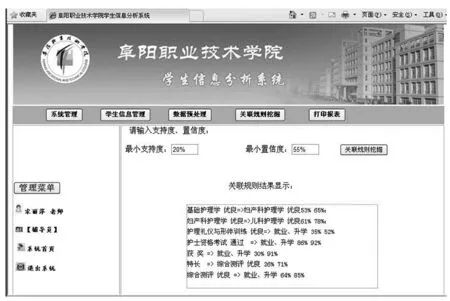
图6 护理专业关联规则挖掘结果
(4)关联规则挖掘结果的验证及预测
上面对护理专业的学生的就业数据进行了关联规则挖掘,现在利用其中的部分关联规则对我校2013年护理专业的毕业生的就业情况进行对比分析,并测验我们得出的关联规则用于预测的准确性.
①综合测评分数高的学生的就业情况

图7 综合测评高的就业情况示意图

图8 获奖学生的就业情况示意图
在2013年毕业的760名护理专业的毕业生中,综合测评成绩高的有310名,其中有271名学生就业或升学,所占比例为87.42%,见图7.这一数据比较符合以上采用的学生数据挖掘出来的规则:综合测评 优良=> 就业、升学 64% 85%中的数据值85%,这一方面说明了我们挖掘出来的关联规则的准确性,另一方面也说明了综合测评成绩好的学生更容易就业或升学.为了提高学生毕业以后就业的竞争力,学校就业部门应该针对性地多开一些与就业相关的活动或讲座,如职业生涯规划、面试技巧、就业指导课程等,也应对其进行相关技能的培养,以提高他们的综合素质.
②获奖学生的就业情况
在2013年的护理专业的毕业生中,人工统计出来的获奖的有165名,其中有152名学生就业或升学,所占比例为92.12%,见图8.这一数据也接近于以上采用的学生数据挖掘出来的结果:获 奖 => 就业、升学 30% 91%中的数据值91%,这说明了获奖的同学更受用人单位的欢迎,因此辅导员可以鼓励更多的学生多参加一些校级、省级或国家级的信息技术大赛,多参加一些活动,让更多的学生获得奖项,以增强他们的就业能力,当然这些需要他们努力学习,掌握相应的技能才行.
通过以上的预测结果来看,虽然这个准确率并不能使人完全满意,但是综观我国高职院校的研究现状,这个准确率相对来说还是比较可靠的,这说明预测效果具有一定的可信度,可以作为高职院校教学和就业管理工作改革的参考.
7 小结
本文分析了数据挖掘之中经典的关联规则挖掘算法Apriori算法的优缺点,并对其进行了优化,利用实验验证了该算法优化前与优化后在效率上的提高,并依此建立了适用于高职院校学生就业的数据挖掘模型.利用优化的Apriori算法实现了高职院校学生信息分析系统,同时选用我校护理专业的毕业生信息进行了关联规则挖掘,并利用实际就业情况进行了预测验证,说明了预测效果具有一定的可信度.这些证明了学生信息可以被挖掘并进行应用,但在选择关联规则挖掘算法和应用数据库的规模方面还有待于进一步的改善.
[1]况莉莉.关联规则在高校图书馆读者数据处理中的应用研究[D].合肥:合肥工业大学硕士学位论文,2010.
[2]张娅妮.数据挖掘技术在就业指导中的应用研究[J].淮海工学院学报:自然科学版,2013,(2):32-34.
[3]宋丽萍.关联规则挖掘在图书馆生态化建设中的应用[J].阜阳职业技术学院学报,2014,(2):26-27.
[4]王伟.关联规则中的Aprioir算法的研究与改进[D].青岛:中国海洋大学硕士学位论文,2012.
[5]麦丞程.基于Apriori算法的关联规则挖掘系统设计与实现「J].电脑编程技巧与应用,2015,(11):33-35.
[6]齐金鹏.数据挖掘模型可视化研究与其应用实例[D].吉林:吉林大学硕士学位论文,2004.
[7]刘木林,朱庆华.基于Hadoop的关联规则挖掘算法研究——以Apriori算法为例[J].计算机技术与发展,2016,(7):2-5.
[8]陈海宇,郭晓伟.数据挖掘在高职院校就业指导中的应用研究[J].湖南工程学院学报:自然科学版,2011,(2):56-59.
(责任编校:晴川)
Design and Realization of Student Data Analysis System Based on Association Rule Mining Technology
SONG Liping, WEI Jianguo
(College of Engineering Science and Technology, Fuyang Vocational and Technical College,Fuyang Anhui 236000, China)
The development of data mining technology makes good use of large-scale data accumulated in colleges and universities. There are many research directions in the field of data mining, one of which is association rule mining. This paper analyzes and optimizes the Apriori algorithm, an algorithm of association rule mining, and compares the performances of the optimized Apriori algorithm with the orginal algorithm, which proves the efficiency of optimized Apriori algorithm. Based on the web technology and SQL Server 2005, the paper designs and realizes a system of association rule mining, which adopts the optimized Apriori algorithm and can achieve the functions of data import,data pre-processing, data mining and so on.
data mining; association rule; Apriori algorithm; system
2016-12-19
安徽省高校自然科学研究重点项目“关联规则在高职学生就业数据处理中的应用研究”(批准号:KJ2016A561);安徽省高校自然科学研究重点项目“校园网络安全过滤关键算法研究”(批准号:KJ2016A563);安徽省高校人文社会科学重点研究项目(批准号:SK2016A0688)阶段性成果.
宋丽萍(1984— ),女,安徽阜阳人,阜阳职业技术学院工程科技学院讲师,硕士.研究方向:数据挖掘.
TP391
A
1008-4681(2017)02-0058-04
