电力设备监测数据的流式计算与动态可视化展示
2017-05-11李莉朱永利宋亚奇
李莉,朱永利,宋亚奇
(华北电力大学控制与计算机工程学院, 河北省保定市 071003)
电力设备监测数据的流式计算与动态可视化展示
李莉,朱永利,宋亚奇
(华北电力大学控制与计算机工程学院, 河北省保定市 071003)
电力设备监测数据的实时分析和可视化展示是智能电网建设的重要内容。以Hadoop为代表的传统数据处理模型不能满足业务时延要求。提出基于阿里云流计算(Stream Compute)的电力设备监测数据流式计算与动态可视化展示方法,并应用Stream Compute的上下游服务搭建了用于电力设备监测数据的时频分析和可视化展示的应用系统。试验测试表明,所搭建的系统整体的处理延迟被控制在s级,能够满足电力设备在线监测及实时数据展示的性能要求。
在线监测; 大数据; 流计算; 数据可视化;阿里云
0 引 言
随着电网状态检修全面推广实施,输变电设备状态监测系统进入了全面建设阶段,诸多先进的传感器技术也被应用到构建坚强智能电网的实践中。智能电网中的传感器数量庞大、种类繁多,在发电、输电、变电、配电和用电领域的广泛使用产生了以指数级增长的数据,呈现出数据量大、生成速度快、价值密度低、处理速度快等特点,迫切需要新的处理技术去应对存储和计算方面的挑战。
以Hadoop[1]为代表的传统大数据处理技术使用MapReduce[2]编程框架实现并行计算,主要用于海量数据的批量处理。其特点是数据规模大、吞吐量高、实时性差,因此很难满足电力设备监测数据的实时展示和在线计算等时效性要求较高的计算任务[3]。
流式计算[4]框架主要用于流式数据处理,相对于Hadoop MapReduce和Spark等批量计算框架,具有事件触发和响应时间短等特点,事件触发和响应时间可达到s级,甚至ms级,主要的应用场景包括实时数据仓库[5]、流式数据处理[6-7]、设备在线监测[8]、故障诊断[9]、舆情监控[10]、智能交通[11-12]、实时报表[13]等场景。流式大数据技术在电力行业中的应用相对较少,研究成果大都是基于开源的Apache Storm和Spark Streaming完成[14-15]。阿里云Stream Compute是阿里云提供的流式计算框架,在包括吞吐量在内的若干关键性能指标是Apache Storm的6~8倍,数据计算延迟优化到s级乃至ms级,单个作业吞吐量可达到百万条/s,单集群规模在数千台[16],为实现更低延迟的电力设备监测数据的流式计算和可视化展示提供了强有力的计算引擎。
本文基于阿里云流计算以及配套的上下游产品(DataHub[17]、物联网(internet of things,IOT)套件、关系数据库服务(relation database service,RDS)、DataV[18])构建了从数据采集、数据处理到数据可视化展示的一个完整系统,实现了电力设备监测数据的实时收集、时频分析以及动态可视化数据展示。实验测试表明,整体的处理延迟控制在s级别,可以满足电力设备在线监测及实时数据展示的性能要求。
1 流式计算与可视化展示系统架构
不同于传统的离线数据,电力设备监测流式数据产生自源源不断的事件流。由多个数据源持续生成数据,流数据通常也以数据记录的形式发送。但相较于离线数据,流数据具有实时、连续、无界的特征,对于采集、计算、集成的时延要求较高。阿里云流式计算服务部署在分布式集群上,经由DataHub高速通道到达的多源监测数据,进入流计算后,在内存中就可以完成数据分析,具有延迟时间短的特点,可以在s级甚至ms级完成计算,与以Hadoop MapReduce为代表的批量计算有着本质的差别。基于阿里云Stream Compute技术所设计的电力设备监测数据流式计算和可视化展示系统框架如图1所示。

图1 电力设备监测数据流式计算和可视化展示系统框架图Fig.1 Stream computing and visualization of power equipment monitoring data
系统整体架构可以分为3个部分:数据采集和交互、实时数据处理和数据应用。数据采集设备嵌入阿里云IOT套件SDK,目前支持主流的MQTT/CCP协议,可以直接与IOT套件通信。IOT套件用于采集设备终端和云端的双向通信,可以支撑亿级设备长连接,百万条消息并发。使用IOT套件规则引擎,可以配置数据实时同步至DataHub。
DataHub服务可以对各种电力设备监测所产生的大量流式数据进行持续不断的采集、存储和处理。监测数据进入DataHub之后,便直接由流计算引擎订阅,监测数据的实时处理在流计算引擎中完成。流计算产出实时图表、报警信息、实时统计等各种实时的数据处理结果,并可以同步至RDS,用于后期各类实时数据消费,包括可视化的实时数据展示和实时报表等。此外,流式计算的结果和流数据本身也可以再次同步至大数据计算引擎,用于支撑后期的历史数据批量计算和分析。
2 基于流计算的电力设备监测数据实时特征提取
2.1 监测数据时频域特征提取
本文的流计算任务主要基于变压器局部放电特高频波形数据进行实时的时频分析和特征提取,计算的特征包括:脉冲波形时间重心、频率重心、等效时宽、等效频宽、二次等效时宽和二次等效频宽。
2.1.1 时间重心
设信号的1个脉冲波形时域表达式为s(t),将|s(t)|2看作时间密度,则基于标准偏差对时域信号进行标准化处理后,信号的时间重心(平均时间)为
tN=∫T0τ[s(τ)]2∫T0[s(t)]2dtdτ
(1)
时间重心可以反映信号时域分布密度的特征及密度集中的位置。
2.1.2 频率重心
与时域波形相似,设|s(ω)|2表示频率密度,则经过标准化处理后的信号频率重心(平均频率)为
ωN=∫0ω[s(ω)]2∫0[s(σ)]2dσdω
(2)
频率重心可以反映信号频率分布密度的特征及密度集中的位置。
2.1.3 等效时宽
由时间重心进一步定义等效时宽Wt:
Wt=∫T0(τ-tN)2[s(τ)]2∫T0[s(t)]2dtdτ
(3)
等效时宽表示信号持续时间,反映了时间重心周围信号的集中程度。
2.1.4 等效频宽
由频率重心定义等效频宽Wf:
Wf=∫0(ω-ωN)2[s(ω)]2∫0[s(σ)]2dσdω
(4)
等效频宽表示信号频谱范围,反映了频率重心周围信号的集中程度。
2.1.5 2次等效时宽和2次等效频宽
通过引入随机过程高阶统计量,可计算脉冲波形的高维特征量,使波形特征量在数值上差异更大,更加有利于后续信号识别,Wkt和Wkf分别为k次等效时宽和k次等效频宽[19],其计算公式为:
Wkt=∫T0(τ-tN)2k[s(τ)]2k∫T0[s(t)]2kdtdτWt
(5)
Wkf=∫0(ω-ωN)2k[s(ω)]2k∫0[s(σ)]2kdσdωWf
(6)
当k=2时,Wkt和Wkf分别为2次等效时宽和2次等效频宽。
2.2 阿里云流式计算服务
阿里云流计算(Alibaba Cloud Stream Compute)是运行在阿里云平台上的流式大数据分析平台,提供在云上进行流式数据实时分析的功能。使用阿里云StreamSQL,可以有效规避掉底层流式处理逻辑的繁杂重复开发工作,主要应用于流数据分析、实时监控、实时报表和实时数据仓库等领域。Stream Compute的典型应用场景及主要的上下游工具组件如图2所示。
不同于其他开源流计算中间计算框架需要开发者实现大量的流计算细节,Stream Compute集成了诸多全链路功能,方便进行全链路流计算开发。Stream Compute集成的全链路功能包括:(1)流计算引擎。提供标准StreamSQL,支持各类Fail场景的自动恢复;支持故障情况下数据处理的准确性;支持多种内建的字符串处理、时间和统计等类型函数。(2)关键性能指标超越Storm的6~8倍,数据计算延迟优化到s级乃至ms级,单个作业吞吐量可做到百万条/s,单集群规模在数千台。(3)深度整合包括DataHub、日志服务、RDS、分析型数据库、IOTHub等在内的各类数据存储系统,无需额外的数据集成工作。

图2 Stream Compute的典型应用场景及主要的上下游工具组件Fig.2 Typical application scenario and main upstream and downstream tool assembly of Stream Compute
2.3 基于阿里云的实时特征提取的实现
2.3.1 存储设计
通过IOT套件实时采集的监测数据暂存在DataHub中。流计算处理产生的结果将存储在云数据库RDS中。在进行流式处理前,需要首先在阿里云流计算中注册其存储信息,才可与这些数据源进行互通。
需要在Data Hub中创建项目(Project)和主题(Topic)。Project是DataHub数据的基本组织单元,可以包含多个Topic。设计了4个Topic,分别用于暂存原始采样数据和流数据统计特征。其逻辑模型和血缘关系如图3所示。

图3 存储逻辑模型和血缘关系设计Fig.3 Storage logic model and related design
在图3中,a0,a1,a2,…ai, …,an-1代表时域上n个采样点的波形值;A0,A1,A2, …Ai, …,An-1则代表快速傅里叶变换后n个点的频谱赋值。
特征提取过程分多步执行,分别使用流计算任务实现实时计算。计算中间过程数据均使用DataHub的Topic暂存。最终特征计算结果持久化保存至RDS for MySQL数据库。创建表的SQL如图4所示。

图4 创建表的SQL描述Fig.4 SQL of create table
2.3.2 流式数据处理
流式数据处理过程包含4个过程,如下详述。
(1)注册DataHub数据存储。数据源在使用前必须经过流计算中的注册过程,注册相当于在流计算平台中登记相关数据源信息,方便后续的数据源使用。
(2)注册RDS数据存储。当前RDS仅支持MySQL引擎的数据库,其他的数据库引擎暂时不支持。
(3)创建Stream SQL任务。为了完成电力设备监测数据实时特征提取,创建了4个串行的Stream SQL任务,其依赖关系用工作流有向无环图(directed acyclic graph,DAG)描述,如图5所示。

图5 实时流计算任务处理流程Fig.5 Processing flow of real time stream computing
Stream Compute的流计算任务主要使用Stream SQL描述,部分功能使用用户自定义函数(user define function,UDF)定义,并嵌入到Stream SQL中。快速傅氏变换(fast fourier transformation,FFT)计算的Stream SQL描述如图6所示。
Stream SQL流计算任务主要包括3个部分:输入表生成、输出表生成和数据加工过程。Stream Compute并没有存储功能,所以这里的输入和输出均来自DataHub。数据加工中的FFT是UDF,使用Java语言实现。其他流计算过程的代码结构与图6类似,这里不再赘述。最后1个流计算任务(计算2次等效时、频宽)的输出是RDS FOR MYSQL表,与之前的输出均不相同。

图6 FFT计算的Stream SQL描述Fig.6 Stream SQL of FFT computation
(4)上线Stream SQL任务。当完成开发、调试,经过验证Stream SQL正确无误之后,可将该任务上线到生产系统中。
2.4 实时可视化展示
数据展示使用阿里云数据可视化服务(DataV)实现。DavaV提供了多种场景模板和各类报表模板支持。DataV同时支持数据库、应用程序接口、静态文件等各类数据源的可视化展示。由于本文中流计算的输出使用了RDS,所以在DataV中使用RDS FOR MYSQL作为数据源,与可视化组件绑定,生成动态、实时的数据可视化报表。监测数据可视化展示效果如图7所示。
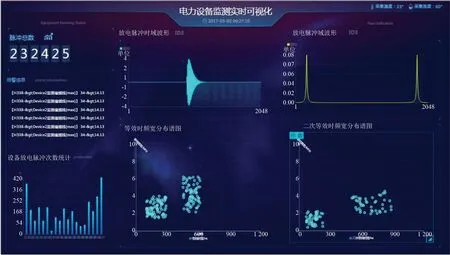
图7 电力设备监测数据实时可视化展示大屏Fig.7 Real time visualization of power equipment monitoring data
3 试验与测试
试验在阿里云的数加平台上完成,使用的服务包括:IOT套件、DataHub、Stream Compute、RDS for MYSQL和DataV。其中,Stream Compute是本次工作的核心功能,申请的硬件配置是10 CU。CU是阿里云流计算中计算单元,1 CU描述了1个流计算作业最小运行能力,即在限定的CPU、内存和输入/输出设备 (I/O)情况下对于事件流处理的能力。1个流计算作业可以指定在1个或者多个 CU上运行。在计算能力上,1 CU的性能处理瓶颈是1 000条数据/s。
本文试验中,使用的是局部放电特高频波形数据,采样率达到10 GHz,每次采样时间取2 μs,每次触发流计算任务,处理的数据规模为80 KB,含2万个采样点。
试验主要关注流计算的关键性能指标包括业务延迟、计算耗时、数据输入、数据输出、CPU占用、内存占用、源表响应时间(response time,RT)和脏数据统计等。局部放电数据等效时、频宽流计算任务的性能指标分析如下详述。
(1)业务延时。业务延时等于流计算处理时刻减去流式数据业务时间戳,集中反映当前流计算全链路的1个时效情况。业务延时用来监控全链路的数据处理进度。如果源头采集数据由于故障没有进入DataHub,业务延时也会随之逐渐增大。局部放电数据等效时、频宽流计算业务延时记录如图8所示。当前该流计算任务的业务延时,包括当前的业务延时以及历史的延时曲线。
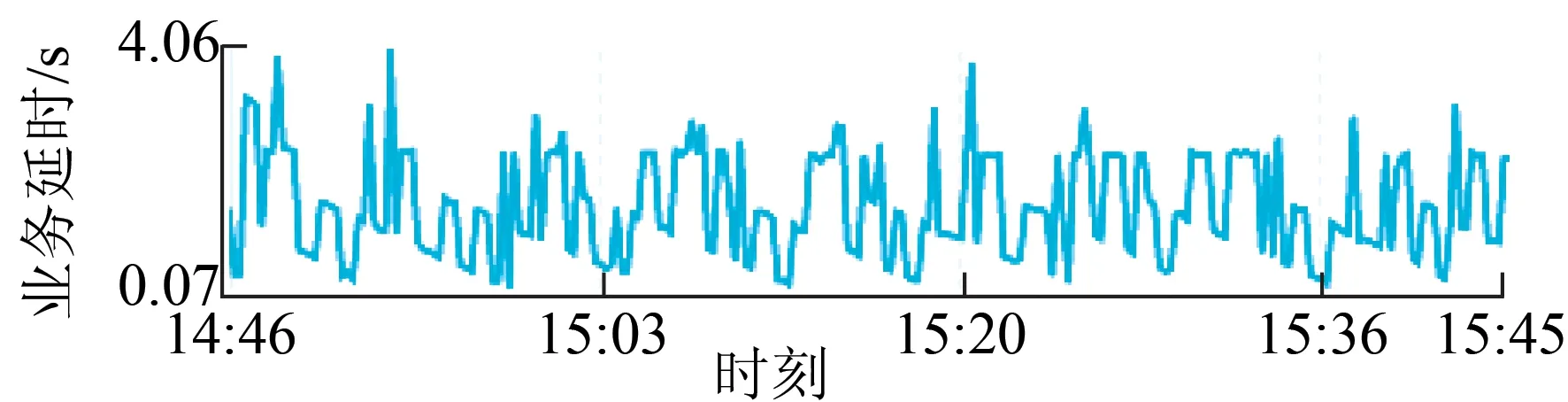
图8 业务延时记录Fig.8 Service delay record
(2)计算耗时。计算耗时等于1批数据从进入流计算过程到最终输出结果所用的时间,集中反映出当前流计算处理自身的时延,是表征流计算处理能力的一项数据指标。一般计算耗时在s级。如果计算耗时大于1 min,可能是由于内部处理逻辑过于复杂,需要调优。局部放电数据等效时、频宽流计算耗时如图9所示。
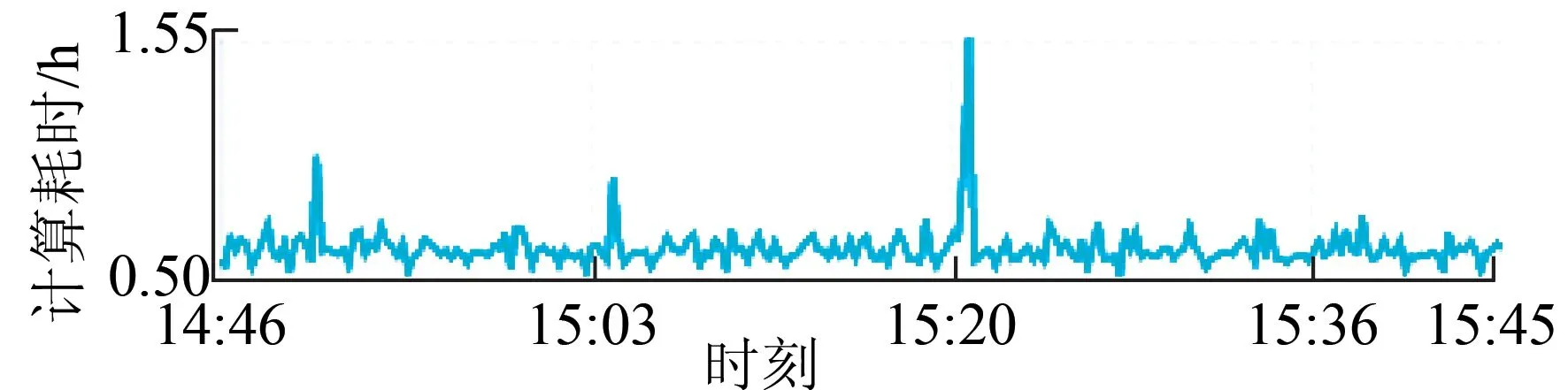
图9 计算耗时记录Fig.9 Computation time record
计算耗时页面会提供当前该流计算任务的计算耗时,包括当前的计算耗时以及历史的耗时曲线。
(3)数据输入。对流计算任务所有的流式数据输入进行统计,给出数据源输入每s记录数(record per second,RPS),如图10所示。
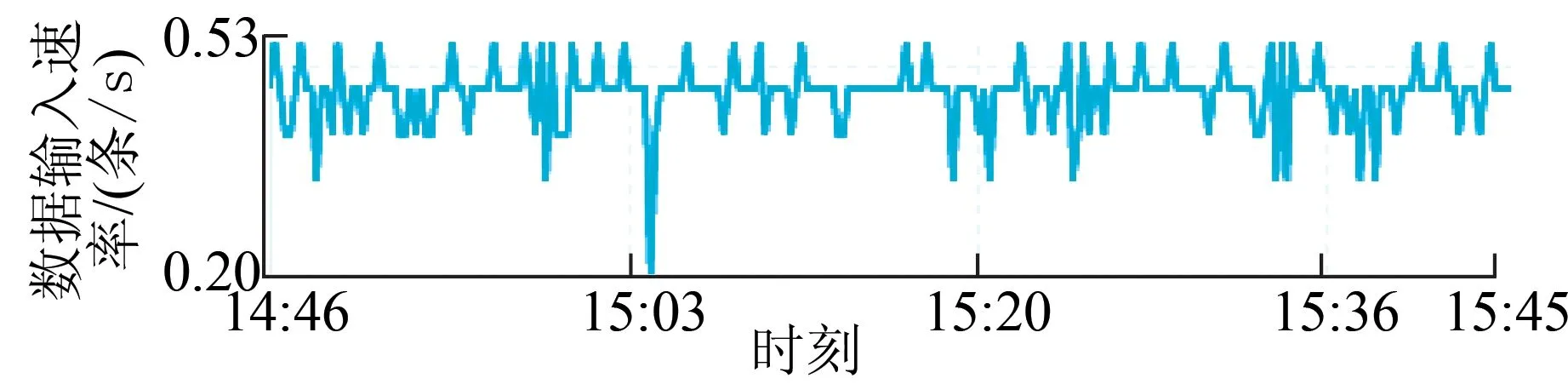
图10 流式数据输入RPSFig.10 RPS of stream data input
(4)数据输出。对该流计算任务所有的数据输出进行统计,给出数据源输出的RPS,如图11所示。
(5)CPU占用。CPU占用反映的是流计算任务对于CPU资源消耗情况,包括CPU使用率和使用核数。本试验中CPU使用核数为1。CPU使用率如图12所示。
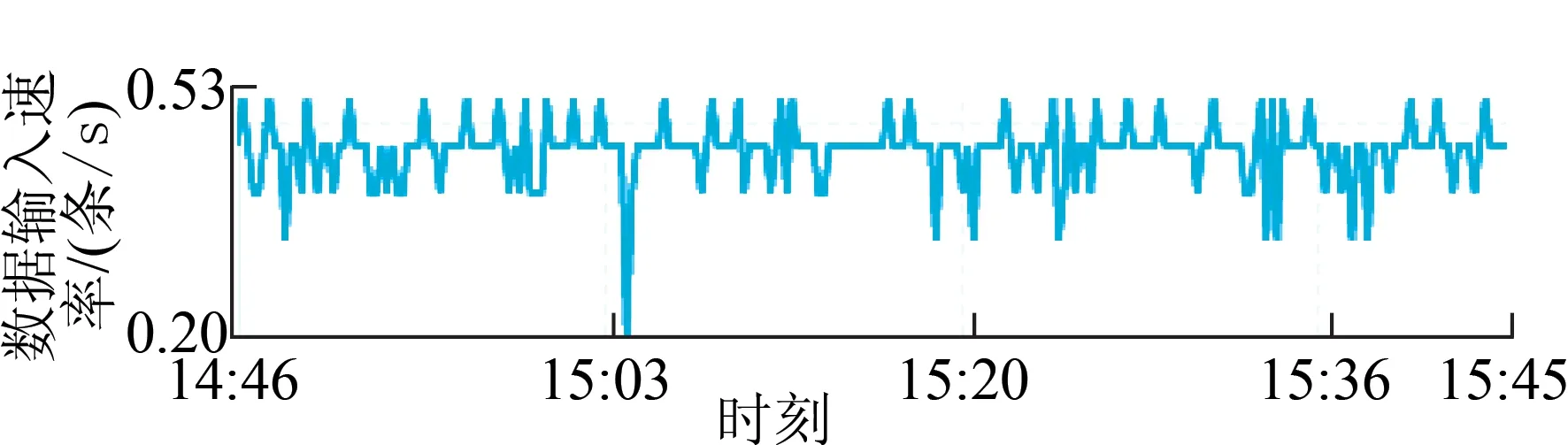
图11 流式数据输出RPSFig.11 RPS of stream data output

图12 CPU占用情况Fig.12 CPU occupancy
(6)内存使用率。内存使用率反映的是流计算任务对内存资源消耗情况,如图13所示。

图13 内存使用率Fig.13 Memory usage
(7)源表RT。源表RT反映的是流计算读取1次源数据的平均RT时间,如图14所示。
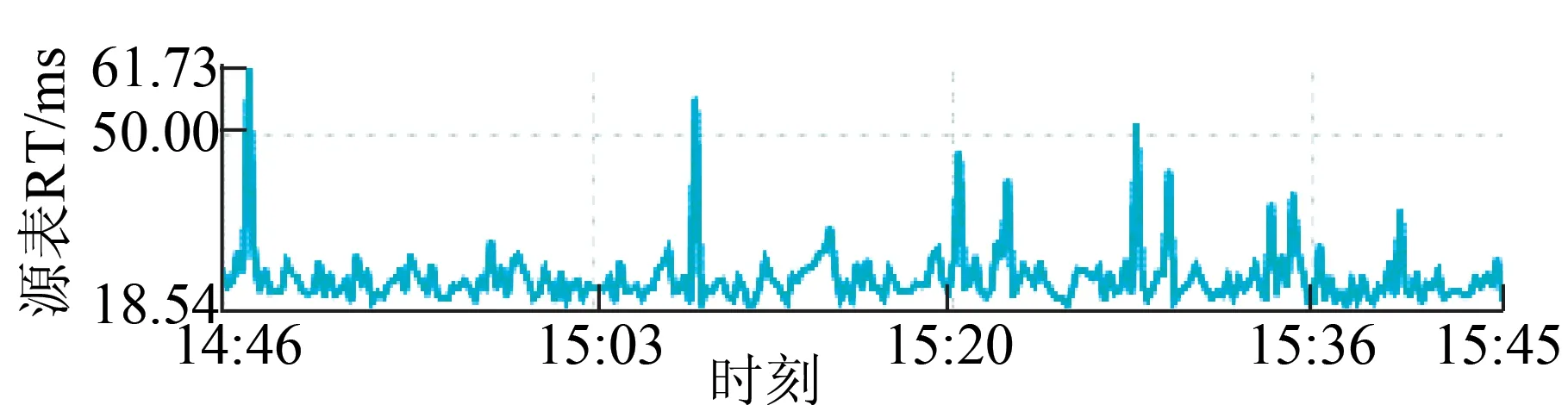
图14 源表响应时间Fig.14 Response time of source table
4 结 论
基于阿里云数据平台,以Stream Compute为核心,综合应用IOT套件、DataHub、RDS和DataV实现了电力设备监测数据的实时采集、数据加工、时频分析和数据可视化展示。通过云监控,实时监视流计算任务的各项性能参数,整体计算延时达到s级,可以满足电力设备在线监测、计算和数据展示的性能需求。
[1] Tom W. Hadoop权威指南:中文版[M]. 周敏奇,王晓玲,金澈清, 译. 北京: 清华大学出版社, 2010:51-55.
[2] DEAN J, GHEMAWAT S.MapReduce: simplified data processing on large clusters[C]//6th Conference on Symposium on Opearting Systems Design & Implementation. Berkeley:USENIX Association, 2004:137-150.
[3] AGNEESWARAN V S. Big data analytics beyond hadoop : real-time applications with storm, spark, and more hadoop alte[M]. New Jersey:Pearson Education, 2014:55-70.
[4] 孙大为, 张广艳, 郑纬民. 大数据流式计算:关键技术及系统实例[J].软件学报, 2014, 25(4):839-862. SUN Dawei, ZHANG Guangyan, ZHENG Weimin. Big data stream computing: Technologies and instances[J]. Journal of Software, 2014, 25(4):839-862.
[5] 林子雨, 林琛, 冯少荣,等. MESHJOIN*:实时数据仓库环境下的数据流更新算法[J]. 计算机科学与探索, 2010, 04(10):927-939. LIN Ziyu, LIN Chen, FENG Shaorong, et al. MESHJOIN*: An algorithm supporting streaming updates in a real-time data warehouse[J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(10):927-939.
[6] SILVA B N, KHAN M, HAN K. Big data analytics embedded smart city architecture for performance enhancement through real-time data processing and decision-making[J/OL].Wireless Communications and Mobile Computing,2017, [2017-01-18].https://doi.org/10.1155/2017/9429676.
[7] 乔通, 赵卓峰, 丁维龙. 面向套牌甄别的流式计算系统[J]. 计算机应用, 2017, 37(1):153-158. QIAO Tong, ZHAO Zhuofeng, DING Weilong. Stream computing system for monitoring copy plate vehicles[J]. Journal of Computer Applications, 2017, 37(1):153-158.
[8] 王德文, 杨力平. 智能电网大数据流式处理方法与状态监测异常检测[J]. 电力系统自动化, 2016, 40(14):122-128. WANG Dewen, YANG Liping. Stream processing method and condition monitoring anomaly detection for big data in smart grid[J]. Automation of Electric Power Systems, 2016, 40(14): 122-128.
[9] 刘子英, 唐宏建, 肖嘉耀,等. 基于流式计算的Web实时故障诊断分析与设计[J]. 华东交通大学学报, 2014(1):119-123. LIU Ziying, TANG Hongjian, XIAO Jiayao, et al. Analysis and design of web real-time fault diagnosis based on stream computing[J]. Journal of East China Jiaotong University, 2014(1):119-123.
[10] 高欢. 基于流式计算的网络舆情分析模型研究[J]. 情报学报, 2016, 35(7):723-729. GAO Huan. Research on model of network public opinion analysis based on stream computing[J]. Journal of the China Society for Scientific and Technical Information, 2016, 35(7):723-729.
[11] 张丽岩, 马健. 流式计算在交通信息实时处理中的应用框架初探[J]. 物流科技, 2014, 37(9):8-9. ZHANG Liyan, MA Jian. A preliminary application framework study of stream computing in traffic information real-time processing[J]. Logistics Sci-Tech, 2014, 37(9):8-9.
[12] 周建宁, 徐晓东, 蔡岗. 流式计算在交通管理中应用研究[J]. 中国公共安全:学术版, 2016(1):70-75. ZHOU Jianning, XU Xiaodong, CAI Gang. Study on the application of steam computing in traffic management[J]. China Public Security, Academy Edition, 2016(1):70-75.
[13] SHRUTHI K, SIDDHARTH P. Easy, real-time big data analysis using storm [EB/OL]. [2012-12-04]. http://www.drdobbs.com/cloud/easy-real-time-big-data-analysis-using-s/240143874?pgno=1.
[14] 张少敏, 孙婕, 王保义. 基于Storm的智能电网广域测量系统数据实时加密[J]. 电力系统自动化, 2016, 40(21):123-127. ZHANG Shaomin, SUN Jie, WANG Baoyi. Storm based real-time data encryption in wide area measurement system of smart grid[J]. Automation of Electric Power Systems, 2016, 40(21):123-127.
[15] 王铭坤, 袁少光, 朱永利,等. 基于Storm的海量数据实时聚类[J]. 计算机应用, 2014, 34(11):3078-3081. WANG Mingkun, YUAN Shaoguang, ZHU Yongli, et al. Real-time clustering for massive data using storm[J]. Journal of Computer Applications, 2014, 34(11):3078-3081.
[16] 阿里云. 流计算产品特点[EB/OL]. [2017-02-28]. https://help.aliyun.com/document_detail/49930.html ?spm=5176.doc49929.6.550.DVbqvj.
[17] 阿里云. 阿里云DataHub[EB/OL]. [2016-11-21]. https://data.aliyun.com/product/datahub?spm=a2c0j.117599.588239.11.abJECp.
[18] 阿里云. DataV数据可视化[EB/OL]. [2016-09-15]. https://data.aliyun.com/visual/datav?spm=a2c0j.117599.416540.109.abJECp.
[19] 鲍永胜. 局部放电脉冲波形特征提取及分类技术[J]. 中国电机工程学报, 2013, 33(28):168-175. BAO Yongsheng. Partial discharge pulse waveform feature extraction and classification techniques[J]. Proceedings of the CSEE, 2013, 33(28):168-175.
(编辑 郭文瑞)
Stream Computing and Dynamic Visualization for Electric Power Equipment Monitoring Data
LI Li, ZHU Yongli, SONG Yaqi
(School of Control and Computer Engineering, North China Electric Power University, Baoding 071003, Hebei Province, China)
Real-time analysis and visualization of power equipment monitoring data are the important contents of smart grid construction. The traditional data processing model represented by Hadoop cannot meet the requirements of business delay. This paper presents a method of stream computing and dynamic visualization for power equipment monitoring data based on Alibaba Cloud Stream Compute, and uses Stream Compute upstream and downstream service to build an application system for time-frequency analysis and visualization of power equipment monitoring data. The experimental tests show that the overall processing delay of the system is controlled at the second level, which can meet the performance requirements of on-line monitoring and real-time data display.
on-line monitoring; big data; stream computing; data visualization; Alibaba cloud
国家自然科学基金项目(51677072); 中央高校基本科研业务费专项资金资助项目(2016MS116,2016MS117)
TM 93
A
1000-7229(2017)05-0091-07
10.3969/j.issn.1000-7229.2017.05.012
2016-10-15
李莉(1980),女,博士研究生,讲师,本文通信作者,主要从事输变电设备状态检测大数据分析与信号处理等方面的研究工作;
朱永利(1963),男,教授,博士生导师,主要从事大数据技术在输变电设备状态监测数据分析中的应用与智能信息处理等方面的研究工作;
宋亚奇(1979),男,博士,讲师,主要从事电力大数据与云计算等方面的研究工作。
Project supported by National Natural Science Foundation of China(51677072)
