一种树状结构的点云数据混合索引方法
2017-05-05张大鹏汪军林
张大鹏 汪军林
一种树状结构的点云数据混合索引方法
张大鹏 汪军林
(河南师范大学新联学院 河南郑州 450000)
为了提高点云数据的索引效率,本文基于KD树和八叉树的索引模型,提出一种新的点云数据的索引的方法,实验证明这种混合索引的方式能够提高点云数据索引的效率。
树状结构;混合索引;点云数据
点云数据索引是点云数据处理中的一个重要的环节,对于大量的三维点云数据信息来说,合理的空间索引结构方式可以高效的实现海量三维点云数据信息的存储和管理。空间索引结构方式的好坏直接影响地理信息系统和空间数据库工作效率,空间索引的结构方式的研究和开发影响了整个空间数据库和地理信息系统领域的进展[1]。目前,数据检索问题的解决除了靠计算机提供商在硬件上生产高速处理器和大容量的存储设备外,还需在算法结构上进行优化,对三维点云数据进行高效的组织和管理,研究和开发新的数据组织和索引结构方式来适应更加复杂的空间操作。
本文提出一种基于KD树和八叉树的混合索引模型,并通过一处矿山点云数据进行实验,证明这种混合索引模型对点云数据的索引效率的改善。
1 KD树空间索引模型
KD书是一种适合管理点云数据的索引方式[2],KD树主要应用于多维点数据和多属性段数据的检索。KD树是一种从二叉类搜索结构推广到多维检索树的结构方式,KD树中的K为数据的维数。与二叉搜索树状结构所不同的是,KD树的每个节点表示K维空间中的一个点,每一层都根据本层次的分辨器和相对应的对象得出分支决策。KD树具体的划分方式是,最顶层节点按照由分辨器所决定的一个维度对数据进行划分,第二层的分辨器所决定的一个维度来划分,由此下去在各个维之间不断的进行划分。直到该节点中的点数少于阈值,划分结束。
KD树每一个节点都是一个K维点的二叉树结构。在KD树中所有的非叶子节点都可以看成许多超平面将数据空间划分为左右或上下两个部分。在这个超平面中所有位于左节点的数据信息都属于左子树,所有位于右节点的数据信息都属于右子树。超平面的构建可以采取下面方式进行构建:每一个节点都与K维中垂直于超平面的一维有着直接关系。假设以Y轴进行划分,所有指定的比Y值小的数值都位于左子树当中,所有指定比Y值大的数值都位于右子树当中。超平面就可以根据此值来确定,法矢是Y轴方向的单位矢量,图1展现了三维数据空间中KD树的剖分结构图,首先红色线段将数据空间划分为两个空间部分,而后绿色线段将分割后的两个空间划分为四个空间部分,最后蓝色线段将这四个空间又分割为八个空间部分,形成最后8个子空间部分。
2 八叉树空间分割
八叉树是四插树在三维空间上的扩展[3],可以用来对三维点云数据进行组织并建立空间索引。每一个八叉树节点都可以代表了一个空间长方体的体积,在具体操作实现的时候,让立方体与坐标轴相互平行。每个八叉树都有8个子节点,如果一个节点没有孩子就意味无需对该节点进行进一步的分割。对三维点云数据进行组织的时候,需要定义一个立方体的停止规则。最小点云个数和递归的最大深度都可以作为分割停止的规则。如果一个叶子节点其中的点云个数小于某阈值或者超过了最大递归深度则停止递归。所有的三维点云数据都存放在叶子节点当中,通过深度和点云数目的限制可以得到一个平衡的八叉树,在这个八叉树中所有的叶子节点都处在同一层次上,且其它的节点都有8个子节点,对于那些空的节点不需要进行分割,所以只对那些包含有三维点云数据的空间创建节点。由于三维点云数据一般都是采集目标物体表面的数据。利用八叉树的数据组织结构方法适合对大量三维点云数据进行存储。图2表示了八叉树的结构方式。
3 混合索引的建立
八叉树的结构是将点云数据所占据的空间的外包六面体按照格网的进行分割,将点云数据通过递归分割的方式进行层层的深入分割,点云数据最终都将归属于叶子节点,中间节点仅仅是作为检索点云数据的通道,采用这种索引方式易于实现,可操作性强。当点云数据量比较大,分布不均勾时,这样分配得到叶子节点的点云的数量会很大,在叶子节点中对点云数据进行检索的效率会大大降低。为了提高点云数据检索的效率,需要对叶子节点的点云数据进行重新组织。将叶子节点中的点云数据采用KD树的方式进行组织,由于KD树已进行点云邻域的空间数据进行组织,所以会大大的提高检索的效率,在进行点云数据的检索时,先确定点云数据所在的叶子格网,然后再对该叶子节点进行KD树的检索,利用这种混合的方法可以避免单一结构带来的弊端。
4 算法实现
基于八叉树与KD树的混合索引进行三维点云数据索引的构建,具体的构建算法如下:
1.根据所输入的三维点云数据集合,计算其最小外包围盒,设定改进八叉树叶子节点的大小和分割的深度deep。
2.通过上一步所得到的参数,对八叉树进行递归分割并存储相关节点的信息。
3.对于分割完成的八叉树的叶子节点,用KD树方法进行二次剖分,节点分别存储索引信息和节点的坐标,并将KD树指针的地址保存在八叉树的叶子节点之中。
4.对三维点云数据进行检索时,首先定位到其所在八叉树的叶子节点当中,然后在进行与该叶子节点唯一确定的KD树当中进行二次检索。需要注意的是,在进行点云邻域搜索时,若该叶子节点点的个数不满足条件数,那么需要在其邻域的8个节点中进行搜索。
利用复合嵌套的组织索引结构,可以平衡各个节点中的点云数据量,在对点云数据进行检索时可以取得较好的查询效率。
5 实验分析
本实验数据是TrimbleGX200激光扫描系统采集的一座矿山。为了更便利区分不同索引方式的效率,选取同一目标物,对点云数据分别抽取25%、50%、75%后得到1178902 、785935、369280个点的数据,抽稀后得到的点云如图3所示。

(a)100%的点云数据 (b)75%的点云数据
(c)50%的点云数据 (d)25%的点云数据
图1 矿山三维扫描点云抽稀结果
分别利用改进的八叉树、KD树以改进八叉树与KD树的混合索引方式对其进行组织。运行环境为XP系统,用于数据处理实验的计算机CPU型号为Pentium (R)Dual-Core E5200 2.5GHz双核。其构建时间统计如表3.2。根据表3.2中的数据绘制图3.17。
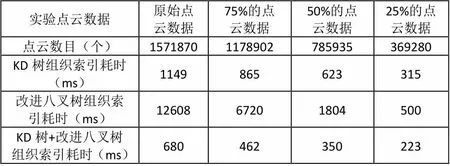
表1 不同索引方式的构建时间
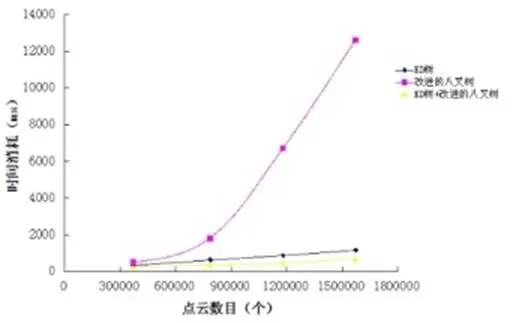
图2 三种组织索引方式的耗时过程线
对同一矿山点云数据,按照25%、50%、75%抽取后的点云数据进行实验比较,通过对KD树、改进八叉树以及改进八叉树与KD混合索引方式的实验验证及分析发现,虽然改进八叉树能够在计算机内存消耗方面得到较大的改善,但是在对点云数据进行检索时,最小分割粒度(叶节点大小)影响了其检索的效率,叶节点越大,其包含的点的数目就越多,由于点数据在叶子当中是以线性的方式进行存储的,所以对点数据的定位和查询时间很长。若分割的粒度太小,那么八叉树的深度就会增加。KD树重建了点云数据之间的邻域关系,所以在查询效率上得到了较大的改善,构建KD树的邻域关系需要消耗大量的时间,所以对所有点云数据都进行KD树的构建,显然是不现实的。利用改进八叉树与KD树的混合索引的结构方式,在不失点云数据整个空间结构的情况下,对叶节点的点进行KD树邻域的构建,可以在处理时间方面取得不错的效果。实验证明混合索引方式的在时间的消耗上花费更少。
6 结语
本文在KD树和八叉树的基础之上,利用混合索引的方式进行点云数据的索引。
1)本文验证了混合索引方式在点云索引过程中的效率,为点云索引提供了一种思路。
2)本文为点云数据索引提供了一个新的思考方向。如何针对不同类型的点云数据使用更加有效的索引方式可以进一步研究。
[1] Levoy M.The digital Michelangelo project.In:3DIM99,1999.2-11.
[2]刘艳丰. 基于kd-tree的点云数据空间管理理论与方法[D].长沙:中南大学,2009.
[3]惠文华,郭新城.3维GIS中的八叉树空间索引研究.测绘通报,2003(1):25~27.
[4]路明月,何永健.三维海量点云数据的组织与索引方法.地球信息科学,2008,10(2):190-194
[5]许鹏.海量三维点云数据的组织与可视化研究[D].南京:南京师范大学,2013.
G322
B
1007-6344(2017)03-0338-01
张大鹏, 1988年7月 , 男,汉,河南 卫辉,硕士研究生,助教,研究方向为三维激光扫描技术。
汪军林,1989年3月,男,汉,河南 项城,硕士研究生,助教,研究方向为精密工程测量
