基于词频-逆文本频率和社区划分的图书推荐算法
2017-04-25曾斯炎周锦黄国华
曾斯炎,周锦,黄国华
(邵阳学院 理学与信息科学系,湖南 邵阳,422000)
基于词频-逆文本频率和社区划分的图书推荐算法
曾斯炎,周锦,黄国华
(邵阳学院 理学与信息科学系,湖南 邵阳,422000)
本文提出一种基于图书内容的图书推荐算法。该算法利用词频-逆文本频率抽象图书特征向量,采用欧式距离度量图书相似性,使用CNM算法对图书相似性网络进行聚类,得到已知类别。当读者用户阅读、购买某本图书时,能够将该类别里的其他图书推荐给读者用户,方便其阅读或购买。
图书推荐; 复杂网络;社区发现;关键词频率;逆文本频率指数;聚类
网上书店给人们购书带来了极大的便利。例如用户只要输入书名或作者等相关信息,就能立刻查到所要购买的书籍。作为用户来说,当选择一本书后,希望再购买一些类似的书籍或从众多书籍中选择一本最适合的购买,但又限于不了解待购书籍的详细信息。在这种情况下,类似于导购员的图书推荐系统,无疑给用户寻找书籍节省了大量时间。对于书店来说,图书推荐系统也能起到促进图书销量的作用。同样,图书自动推荐也能较好的应用在大学图书馆的管理上。
为了提高图书推荐的精准性,研究人员近年来提出许多不同推荐算法[1-13]。这些算法可以分成三类:从用户特征出发的算法,从图书特征出发的算法以及从用户与图书特征相结合出发的算法。协同过滤算法[4,7,8,12,13]属于从用户特征出发的算法。该算法首先构建用户-图书评分矩阵,计算目标用户与其它用户的相似性;筛选出目标用户的k个最近邻用户;根据k个最近邻用户的图书资源访问情况向目标用户推荐图书。当用户-图书评分矩阵稀疏时,协同过滤算法很难计算用户-用户相似性,从而导致推荐效率低下。徐文青等[14]利用用户、图书以及标签信息,融合热门因子,改进了基于内容和协同过滤的图书推荐算法。郑祥云等[10]根据目标用户历史借阅图书与其它图书的内容相似性和用户之间的相似性,提出了一种基于潜在狄利克雷分布模型的图书推荐算法。用户具有多方面的特征,同样图书也具有多方面的特征。特征选择不同,图书推荐的效果差别就很大。李克潮等[9]融合用户和图书方面的特征来探索图书推荐算法,即使用图书的中图分类号、借阅时间、页数等多特征计算图书相似性,使用用户的专业、年级、性别、兴趣等多特征计算用户相似性。李树青等[11]将图书与用户分别当作节点,利用图书-用户借阅关系构建二分网络,提出一种测度图书可推荐质量的迭代算法。关联规则挖掘技术,如Apriori算法,在图书推荐系统上也得到了广泛应用[15,16]。基于关联规则的图书推荐主要有生成频繁项集和提取强关联规则等步骤。就大数据而言,基于关联规则的图书推荐算法计算效率并不高。
以上推荐算法都没有使用图书的内容来计算相似性。图书内容是读者用户判断或归类图书最核心的特征。本文采用信息检索和过滤技术中的词频(term frequency,TF)与逆文本频率(Inverse Document Frequency,IDF)概念描述图书,进而构建图书相似性网络,使用CNM社区划分算法[17]聚类图书,从而实现图书推荐。
1 TF-IDF方法
词频-逆文本频率(TF-IDF)是文本信息检索中非常重要的方法。词频是指某一个特定词语(特征词)在某一文件或网页中出现的频率。逆文本频率是衡量词语重要性的指标,可以视作特征词的权重。Sparck Jones[18]在1972年首次提出了IDF概念,指出可以给每个特征词赋予一个权重,而且在多个文档中出现的特征词权重应小于在少量文档中出现的特征词权重。Salton等[19-21]进而提出了TF-IDF的计算,阐述了TF-IDF的理论基础以及在信息检索方面的应用。假设整个数据库中文件的总数为M,所选用的特征词总数为N,第j个特征词在第i个文件中出现的频率记为tfij,计算如下[19,20]:
tfij=nij/∑kniki=1…M,j=1…N
(1)
其中nij为特征词j在该文件i中出现的次数。式(1)实际上是将特征词频数进行归一化。很显然,在同一个文件中,词频高的特征词比词频低的重要。然而,仅使用TF进行信息检索忽略了另一个问题。有些特征词高频率出现在几乎所有文件中,如一些通用的词语,“应用”,“基础”,对分类不起什么作用。而另一些专业词仅出现在少量相关文件中,则对文件分类有着重要作用。因此,应该给每个特征词赋予一个权重,逆文本频率就相当于这个作用,计算如下:
(2)
其中Mi表示数据库中出现特征词i的文件总数。很显然,词频-逆文本频率反映了两方面:(a)在特定文件中高频率出现的特征词具有较强的分类能力;(b)特征词的分布文件越广,其分类能力越差。由于词频-逆文本频率有效地刻画了文件的特征,因此它在文本搜索、文献分类等相关领域得到了广泛应用。在本文中,利用公式(1)与公式(2)的乘积构造图书的特征向量,即
Vij=tfij·idfi
(3)
2 构造图书相似性网络
网络是一种非线性结构,由节点以及连接节点的之间的边构成。网络,尤其是复杂网络,是探索复杂系统(如生物系统,社区结构等)的有效方法之一。本文以TF-IDF为图书的特征向量,进而构建图书相似性网络。计算图书之间的相似性:
(4)
其中Vi,Vj代表特定图书的节点,i,j∈[1,M] i≠j。若d(xi,xj)<α,则连接两节点;否则不连接两节点。α是相似性度量临界值。
3 CNM算法
CNM算法是Clause等人[17]提出的一种适合大规模网络社区划分方法。CNM算法采用了模块度度量社区之间的紧密程度。模块度是指社区内部节点的边所占总边数比例与外部接入社区中的边所占的比例差值,即
(5)
eii表示社区i中内部边所占的比例,ai表示接入该社区的边所占总边数的比例。模块度的上限值为1。模块度越大,说明该网络社区结构越明显。因此模块度常用于社区划分效果的标准[22]。
CNM算法步骤如下[23]:
1)初始化
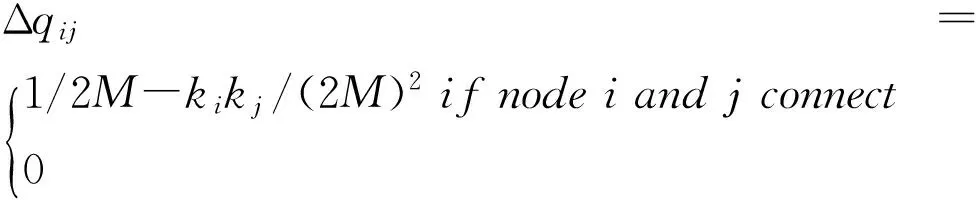
(6)
2)合并
选择最大的分量Δqij,合并相应的社区Ci和Cj,并标记合并后的社区为Cj,同时更新Δqij和向量A。

(7)
更新向量A:
aj=ai+aj,ai=0
(8)
更新模块度值
Q=Q+max{Δqij}
(9)
3)迭代
重复步骤2),直至模块度值不增终止算法,最终得到L个社区。
4 实验结果
本文采集了豆瓣读书网(https://book.douban.com)上《信息简史》、《爱的艺术》、《百年孤独》、《编程珠玑》、《从零开始做运维》、《二手时间》、《克鲁苏神话》、《魔戒》、《杀死一只知更鸟》、《神经网络与机器学习》、《小王子》一共11本图书的信息,书名如表1所示。将“信息”、“编程”、“科学”、“互联网”、“数据”、“程序”、“计算机”、“算法”、“哲理”、“思索”、“奇幻”、“小说”、“经典”、“文学”、“名著”一共15个词作为TF-IDF方法中的特征词。

表1 11本图书的书名
相似度量临界值α=2.5,得到最终的图书划分结果为
只要读者用户选择类别中任何一本图书,可将同类别的其它图书推荐给读者。例如读者阅读《信息简史》时,系统能够将《编程珠玑》、《二手时间》和《神经网络与机器学习》推荐给用户。
5 结论
本文以词频与逆文本频率刻画图书,从而构建图书相似性网络。基于CNM社区划分算法实现图书推荐。相比以前的图书推荐算法,该算法从图书的内容出发,能够排除部分主观因素的影响,并能较好的反映出图书之间存在的客观联系。
[1]周玲元,段隆振.个性化图书推荐系统设计与实现——以南昌航空大学图书馆为例[J].图书馆理论与实践, 2014,(12):106-109.
[2]杨永权.基于协同过滤技术的个性化图书推荐系统研究[J].河南图书馆学刊,2014,(06):119-122.
[3]王连喜.一种面向高校图书馆的个性化图书推荐系统[J].现代情报,2015,(12):41-46.
[4]孙守义,王蔚.一种基于用户聚类的协同过滤个性化图书推荐系统[J].现代情报,2007,(11):139-142.
[5]付凯丽.基于社会化标签的图书推荐系统模型研究[J].情报探索,2016,(10):80-85.
[6]陈宇亮,沈奎林.基于读者评论的图书推荐系统研究[J].图书情报导刊,2016,(09):6-9.
[7]曾庆辉,邱玉辉.一种基于协作过滤的电子图书推荐系统[J].计算机科学,2005,(06):147-150.
[8]安德智,刘光明,章恒.基于协同过滤的图书推荐模型[J].图书情报工作,2011,(01):35-38.
[9]李克潮,梁正友.基于多特征的个性化图书推荐算法[J].计算机工程,2012,(11):34-37.
[10]郑祥云,陈志刚,黄瑞,等.基于主题模型的个性化图书推荐算法[J].计算机应用,2015,(09):2569-2573.
[11]李树青,徐侠,许敏佳.基于读者借阅二分网络的图书可推荐质量测度方法及个性化图书推荐服务[J].中国图书馆学报,2013,(03):83-95.
[12]董坤.基于协同过滤算法的高校图书馆图书推荐系统研究[J].现代图书情报技术,2011,(11):44-47.
[13]景民昌,于迎辉.基于借阅时间评分的协同图书推荐模型与应用[J].图书情报工作,2012,(03):117-120.
[14]徐文青,双林平.融合热门度因子基于标签的个性化图书推荐算法[J].图书情报研究,2015,(03):82-86.
[15]林郎碟,王灿辉.Apriori算法在图书推荐服务中的应用与研究[J].计算机技术与发展,2011,(05):22-24,28.
[16]丁雪.基于数据挖掘的图书智能推荐系统研究[J].情报理论与实践,2010,(05):107-110.
[17]Clauset A,Newman ME,Moore C.Finding community structure in very large networks[J].Physical review E,2004,70(2):066111.
[18]Sparck Jones K.A statistical interpretation of term specificity and its application in retrieval[J].Journal of documentation,1972,28(1):11-21.
[19]Salton G,Yu CT.On the construction of effective vocabularies for information retrieval[J].Acm Sigplan Notices,1973,10(1):48-60.
[20]Salton G,Fox EA,Wu H.Extended Boolean information retrieval[J].Communications of the ACM,1983,26(11):1022-1036.
[21]Salton G,Buckley C.Term-weighting approaches in automatic text retrieval[J].Information processing & management,1988,24(5):513-523.
[22]韩华,王娟,王慧.改进的CNM算法对加权网络社团结构的划分[J].计算机工程与应用,2010,(35):86-89.
[23]张震,李玉峰,王晶,等.基于复杂网络挖掘的用户行为感知机制.中国科学:信息科学,2014,(09):1069-1083.
A book recommendation algorithm based on term frequency-inverse document frequency and community partition
ZENG Siyan,ZHOU Jin,HUANG Guohua
(Department of Science and Information Science,Shaoyang University,Shaoyang 422000,China)
A book recommendation algorithm based on content was proposed.The method used the term frequency-inverse document frequency to represent the books eigenvector,computed similarities between books by the Euclidean distance,clustered books via the CNM algorithm,and finally obtained the classes of books.When users read or bought books,the method could recommend other books in the same category.It is helpful for users to read and buy books.
book recommendation; complex network; community finding;term frequency;inverse document frequency; cluster.
1672-7010(2017)02-0019-05
2017-02-18
国家自然科学基金资助项目(61672356);湖南省自然科学基金(2017JJ2239);湖南省教育厅优秀青年项目(15B216)
黄国华(1978-),湖南祁东人,副教授,博士,从事生物信息学、生物医药大数据、机器学习等研究
TP391.1
A
