基于内存优化配置的MapReduce性能调优*
2017-04-25罗永刚陈兴蜀杨露
罗永刚 陈兴蜀 杨露
(四川大学 网络空间安全研究院, 四川 成都 610065)
基于内存优化配置的MapReduce性能调优*
罗永刚 陈兴蜀 杨露
(四川大学 网络空间安全研究院, 四川 成都 610065)
MapReduce作业性能与内存配置存在极大的相关性,针对准确预测作业内存困难问题,根据Java虚拟机(JVM)的分代内存管理特点,提出了一种分代内存预测方法.首先使用回归模型对年轻代与垃圾回收平均时间的关系进行建模,将寻找合理年轻代内存大小的问题转换为一个受约束的非线性优化问题,并设计搜索算法来求解该优化问题.文中还建立MapReduce作业的Map任务和Reduce任务性能与内存的关系模型,求解最佳性能的内存需求,从而获得Map任务和Reduce任务的年长代内存大小;使用聚类算法预测JVM晋升对象阈值,优化JVM配置,减少了JVM的垃圾回收暂停时间.实验结果表明,文中提出的方法能准确预测作业的内存需求,显著提升作业运行性能.
大数据;MapReduce;垃圾回收;内存分配;性能优化
Apache Hadoop(包含Hadoop分布式文件系统(HDFS)和MapReduce两个核心组件,文中只考虑MapReduce,因此在没有特殊说明情况下Hadoop和MapReduce等价使用)是谷歌公司提出的MapReduce编程模式的开源版本[1],得到了学术界、工业界的大力支持.随着MapReduce应用规模的不断扩大,优化MapReduce作业的性能显得极其重要.
已有大量关于MapReduce性能与配置参数的关系研究.文献[2]在Hadoop性能模型[3]的基础上,使用递归随机搜索算法找到优化的配置参数,但性能模型非常复杂,所获得的内存配置存在不合理之处,且对Hadoop应用的编程规范有严格的要求.文献[4]使用统计方法分析了Hadoop应用特征、Hadoop配置和Hadoop性能的关系,但需要在大量不同配置参数下运行测试程序,当选择的配置参数太多时,配置参数的组合非常庞大.文献[5]借鉴了文献[2,4]的核心思想,但同样存在与文献[4]相同的缺陷.文献[6]提出了基于多项式代理的MapReduce作业性能调优模型,采用拟牛顿优化算法寻找最优的配置参数点.文献[7]提出了一种MapReduce配置参数优化框架MR_COF,与文献[2]类似,MR_COF先使用基于代价的性能模型计算配置参数对应的作业时间,再使用遗传算法搜索最佳的配置参数点.文献[8]提出了一种在线的配置参数优化框架MRONLINE,使用拉丁超立方体抽样方法进行采样,采用智能爬山搜索算法搜索最优配置点.上述性能优化方法的基础是求解函数t=F(p,d,r,c),其中t为作业的性能(执行时间),p为MapReduce程序,d为输入数据,r为集群资源(即Map槽和Reduce槽的数量),c为MapReduce相关的配置参数集.参数集c中大量参数与内存资源相关,如io.sort.mb等,因此内存资源对Hadoop应用的运行性能产生非常重要的影响.文献[2,6-8]均需要通过复杂的性能模型来计算特定参数下作业的运行时间,再使用优化算法搜索最佳的配置.使用优化算法搜索参数空间需要用户指定每个参数的搜索范围,增加用户的使用难度.根据文献[9-10]可知,大量MapReduce作业的处理数据均为GB级别,当前的Hadoop集群内存资源足够容纳待处理的数据.文献[2-3]使用的性能模型没有针对此种内存资源充分的情况,导致其性能模型非常复杂.
Hadoop应用程序运行在Java虚拟机(JVM)之上,JVM的配置对Hadoop应用的性能和稳定性有着直接的影响.文献[11]通过样本作业的内存使用量来预测数据规模增加后内存的使用量,但缺乏对内存需求合理性的定性和定量分析.文献[12]通过机器学习方法对JVM配置进行调优,但没有给出内存大小的预测功能.文献[13]提出了用于分析JVM垃圾回收性能的工具Shrek,文献[14]提出了一种通用的JVM垃圾回收日志的分析系统,但都没有对内存大小进行定量分析,没有考虑MapReduce作业的特殊情况,很难应用到MapReduce环境中.
JVM使用分代内存管理机制[15],将管理的内存空间分为年轻代和年长代.在默认配置下,年长代内存大小是年轻代内存大小的2倍,当为Hadoop任务分配较大的内存资源时,也为年轻代分配了较大的内存,实验数据表明,过大的年轻代内存并不能提升MapReduce作业的运行性能.JVM的垃圾回收性能与MapReduce作业有关,目前针对JVM垃圾回收的优化工作鲜有报道.
为解决这些问题,根据年轻代和年长代内存作用的不同,文中提出了分代内存优化配置方法,使用回归模型对年轻代垃圾回收平均暂停时间进行建模,将寻找合理的年轻代内存大小问题转换为非线性优化问题,并设计相应的求解算法;分析了Map任务和Reduce任务的性能与内存配置的关系,并建立了内存模型,通过内存模型求解年长代的内存需求;设计了JVM对象晋升阈值预测算法来优化JVM的内存配置.
1 分代内存大小预测方法
1.1 基本概念
1.1.1 JVM内存管理
JVM的内存由垃圾回收器管理,将内存分为年轻代和年长代.年轻代分配给临时对象(通常很小),年长代分配给长久有效的对象(通常很大).当不能为新对象分配内存时,JVM触发垃圾回收操作.年轻代的垃圾回收为Minor GC,年长代的垃圾回收为Major GC.JVM内存结构如图1所示.

图1 JVM内存结构
在JVM创建新对象时,JVM将大于大对象阈值的新对象分配到年长代,将小于大对象阈值的新对象分配在Eden区域.在设置晋升对象阈值时,大对象阈值等于设置的晋升对象阈值;未设置晋升对象阈值时,大对象阈值与垃圾回收器有关.选择串行垃圾回收器时,大对象阈值为Eden区域的内存大小;选择并行垃圾回收器时,大对象阈值为Eden区域内存大小的一半.
在执行Minor GC操作时,年轻代中的幸存对象被拷贝到To区域,如图1中的①和②.当To区域没有足够空闲空间时,Eden或From区域中的对象直接被拷贝到年长代,如图1中的③和④.当From区域中的对象经历多次Minor GC后仍为有效对象,则该对象将晋升到年长代.
1.1.2 MapReduce作业的执行流程
MapReduce作业是对特定输入数据集进行处理,并产生特定输出数据的程序运行实例,每个作业由Map阶段和Reduce阶段组成,Map阶段和Reduce阶段分别由一个或多个Map任务和Reduce任务构成.
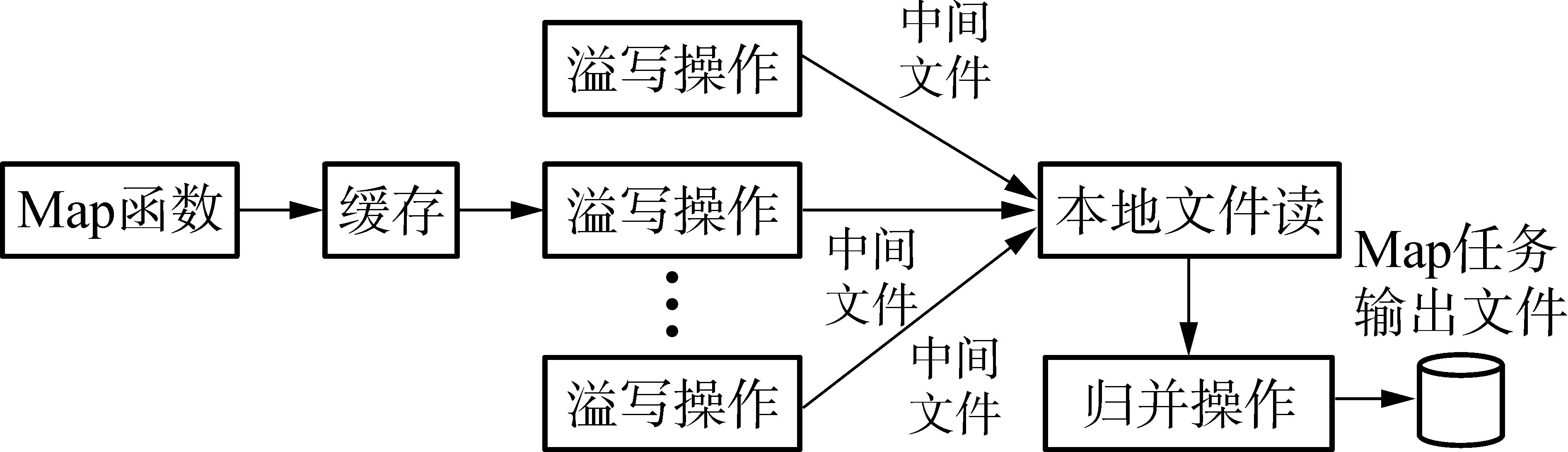
Map任务从HDFS上读取输入数据分片(大小通常为64、128或256 MB),并将其切分为多条包含键、值对的记录,用户设计的Map函数逐条处理这些记录,并将输出的记录交由MapReduce框架缓存.
Reduce任务从远端拷贝数据(Reduce任务的Shuffle阶段),数据拷贝完成后根据记录的键进行排序(排序阶段),然后将数据交给用户的Reduce函数处理,并将最终的处理结果写入HDFS.
Map任务和Reduce任务运行在单独的JVM上.
1.2 分代内存预测
Java虚拟机使用分代内存管理机制,将管理的内存分为3个区域,即年轻代、年长代和恒久代.不同的内存区域容纳不同类型的对象.特定MapReduce作业使用恒久代的量通常为确定值.因此,文中主要研究年轻代和年长代的内存大小与作业的关系.由此可以得到Map或Reduce的JVM的总内存:
Mh=My+Mo
(1)
式中,Mh、My、Mo分别为JVM堆大小、年轻代内存大小和年长代内存大小.其中年轻代可以进一步划分为Eden、From和To区域.在理想情况下,大对象分配到年长代,小对象分配到Eden区域.需要的内存空间小于PretenureSizeThreshold设定值的对象为小对象,否则为大对象.
1.2.1 年轻代内存大小预测
年轻代分配的对象绝大部分为临时的小对象,即这些对象通常只有kB级别,且每次执行垃圾回收操作时几乎能完全回收这些对象占用的空间.
根据JVM内存管理原理,年轻代各区域内存大小的关系如下:

(2)
即
My=(1+2/a)Me
(3)
式中:Mf和Mt分别为From和To区域的内存大小;参数a可以通过JVM命令行设置,默认值为8.求出Me值即可获得My值.
对某个Map任务或Reduce任务,设Eden区域的大小为e,分配在年轻代对象的总大小为s,年轻代垃圾回收的总暂停时间为tt,gc,则有tt,gc=g(e,s).对于相同的Map任务和Reduce任务,s保持不变.寻找合理的Eden区域内存大小转换为求解如下的优化问题:
minf(e)=e
(4)
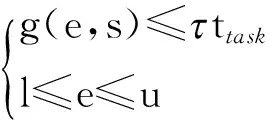
式中:g(·)为非线性函数;l为ψ(e)训练数据集中Eden区域内存的最小值;u取值为ψ(e)训练数据集中Eden区域内存的最大值与设定的最大阈值中的最小值;ttask可通过查询作业的历史记录获得.
输入:g(e,s)、l、u、步长STEP和tlimit(tlimit=ttask).
输出:预测的Eden区域内存大小
(1)随机选择x1,使l≤x1≤u,将x1设置为起始搜索点.
(2)计算t1=g(x1,s),如果t1
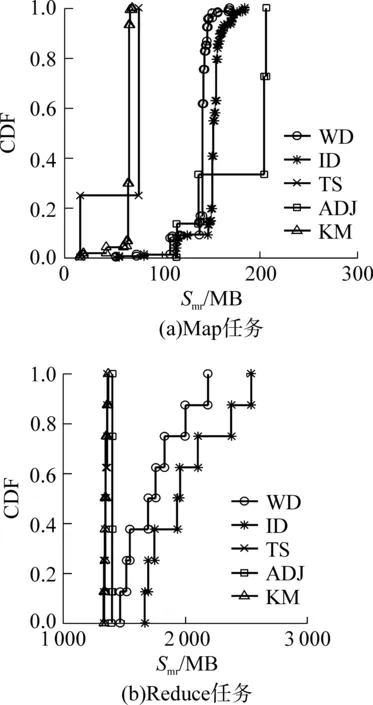
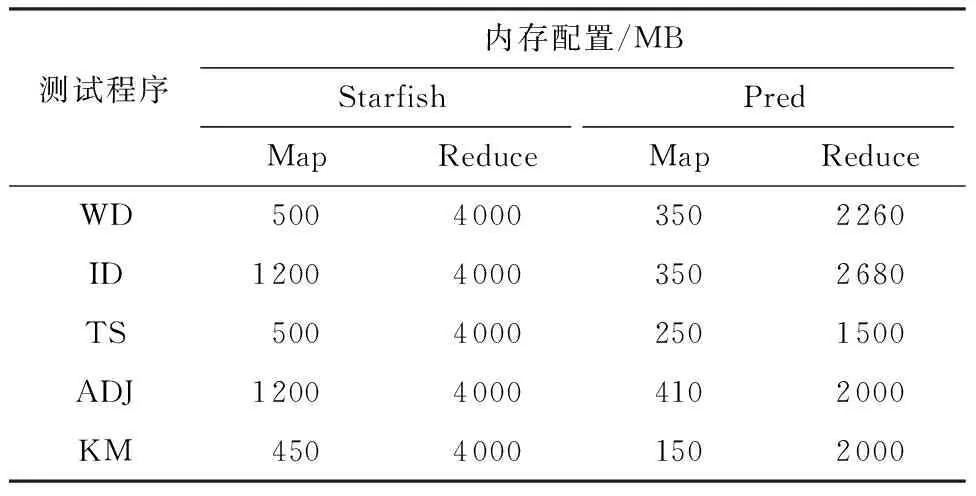
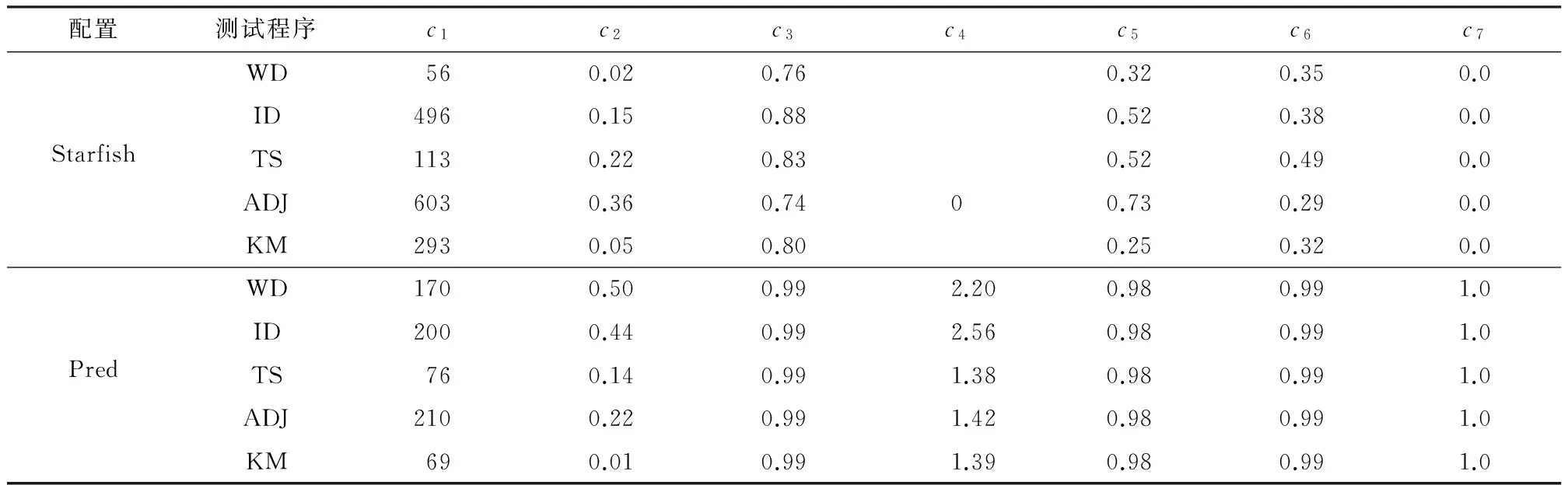
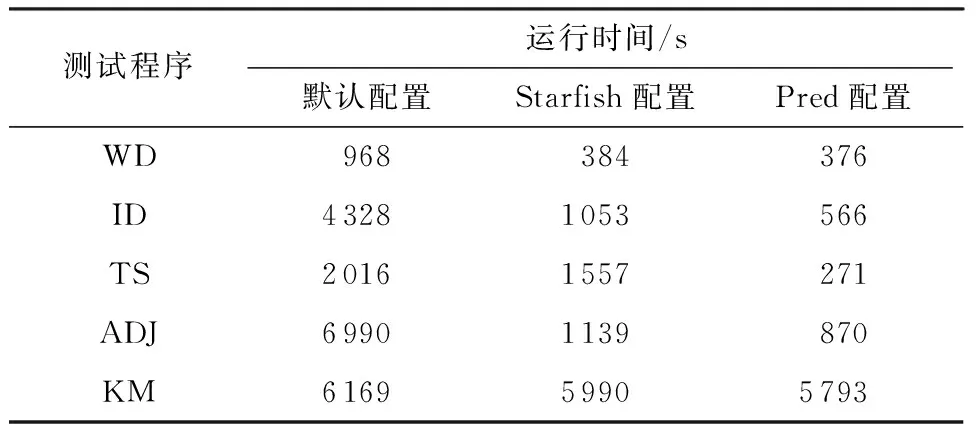
(3)x2=x1+step,计算t2=g(x2,s),如果t2 (4)x2=x1+step,计算t2=g(x2,s),如果t2>tlimit,则依次检查x3,x4,…,直到xi使得ti≤tlimit,返回xi;如果t2≤tlimit,则返回x2. 1.2.2 年长代内存大小预测 设在年长代中创建的缓冲区大小为So,MapReduce框架创建的缓冲区大小为Smr,用户Map函数或Reduce函数创建的缓冲区大小为Su,则有So=Smr+Su.Su通常远小于Smr,因此文中不考虑. (1)预测Map任务的Smr MapReduce框架为Map任务创建的缓冲区主要有记录索引缓存和记录缓存,其大小分别用 Sidx和 Srd表示,则有 Smr=Sidx+Srd (5) 设Sidxi和Srdi分别为同一个作业的第i个Map任务的Sidx和 Srd,Pidx为作业的索引记录缓冲区所占百分比,则有 (6) 进而计算Smr的值: Smr=max(「Sidx/Pidx⎤,「Srd/(1-Pidx)⎤)/β (7) 式中,β为触发数据溢写操作的阈值. (2)预测Reduce任务的Smr 设SRj为第j个Reduce任务的内存需求,SR为作业的Reduce任务的内存预测,则有 SR=maxSRj, j[1,m] (8) 当Reduce任务的Smr≥SR时,可保证该作业的所有Reduce任务没有发生数据溢写操作. (9) ψ可以通过回归建模获得.当已知年轻代对象的总大小s和Eden区域的大小e时,可计算出需要执行的MinorGC的次数Ngc,即 Ngc=「s/e⎤ (10) 则MinorGC的总暂停时间估计值g(e,s)为 (11) 将式(9)、(10)代入式(11),得 g(e,s)=「s/e⎤ψ(e) (12) s可以通过对MinorGC日志信息进行统计分析获得,即 (13) 式中,Oi为第i次Minor GC期间分配到年轻代的对象大小,n为Minor GC发生的次数. 3.1 Map任务的性能分析与优化 Map任务的数据流和工作流如图2所示. 图2 Map任务的工作流程 定义Map函数读取输入数据的时间为tin,处理时间为tm,缓存时间忽略不计.设第i次溢写的操作时间为tsp,i,且tsp,i=tsort,i+tws,i,tsort,i为第i次溢写时的排序时间,tws,i为将记录写入本地文件的时间;读取第i次溢写的中间文件的时间为trs,i,归并时间为tms,i,将Map最终的输出数据写入本地文件的时间为twm,则Map阶段的时间为 发生溢写操作的主要原因是Map输出缓存过小,若保存Map函数输出记录索引的缓存或保存Map输出记录的缓存使用量达到设定阈值,则触发溢写操作(Spill操作).如果Map输出缓存足够大,则Map任务只会在处理完所有输入数据后执行一次溢写操作,此时Map阶段的时间为 (15) 令Nrd,i表示第i个Map任务输出的记录数,则有 Sidx,i=16Nrd,i (16) 其中,Sidx,i和Srd,i在Map任务运行期间一直被占用,故通常会占用年长代空间.MapReduce框架在初始化Map任务时根据配置参数分配3个缓冲区,令M0、M1、M2分别为通过配置参数设置的io.sort.mb大小、索引缓冲区大小和记录缓冲区大小,则有 (17) 当M1>Sidx,iPsp、M2>Srd,iPsp时,Map任务的性能达到最优,即Map运行时间为式(15). 3.2Reduce任务的性能分析与优化 Reduce任务的数据流和工作流如图3所示,主要的工作流程包括:从Map端拷贝数据;从缓存拷贝数据;将缓存数据溢写到本地文件系统的中间文件;当中间文件数量超过阈值后执行归并操作,形成单个更大的中间文件;对缓存数据和本地文件中的数据执行归并排序;执行用户自定义的Reduce函数;将Reduce输出结果写入HDFS.在Hadoop1.2.1的默认配置下,归并排序会将缓存和中间文件中的数据执行归并排序,将排序后的数据写入本地文件系统,形成单个中间文件. 图3 Reduce任务的工作流程 定义特定Reduce任务通过网络拷贝数据的时间为tcp,缓存时间忽略不计,Reduce任务所有输入数据执行内存归并排序的时间为tsort,第i次溢写操作的时间为tsp,i,Reduce函数运行时间为tred,将结果写入HDFS的时间为twdfs,Reduce任务的总运行时间为tR,则有 (18) (19) 通过上述分析知道,Reduce的最优化性能必须满足式(19),不需要关心每一个子操作的具体时间,大大简化了Reduce任务的性能模型. 令Mr,i为第i个Reduce任务的JVM年长代内存大小,Sred,i为第i个Reduce任务拷贝的数据大小,Psf为拷贝可用的缓冲占Mr,i的比例,Psp为发生溢写的阈值,不发生溢写操作时需要 Mr,iPsfPsp>Sred,i (20) 即 Mr,i>Sred,i/(PsfPsp) (21) 在Sred,i一定的情况下,取Psf和Psp接近于1可以最小化Mr,i,因此取Psf=Psp=0.99. 令执行用户Reduce任务阶段的数据缓存大小占Mr,i的比例为Pred,则有 Mr,i>Sred,i/Pred (22) 为了最小化Reduce任务的运行时间,式(21)、(22)必须同时成立. Hadoop1.2.1的Reduce内存管理将每个Reduce任务缓存数据的最大值限制为2GB,为获得式(19)的最小运行时间,修改了Reduce任务的内存管理代码,将限制设置为263-1. 晋升对象阈值的设置对Map和Reduce任务的JVM垃圾回收性能有重要的影响.阈值设置得过小会导致年长代分配大量的小对象,引起不必要的MajorGC;若设置得过大则导致本应分配到年长代的对象被分配到年轻代,引起不必要的对象拷贝. 设置Map任务JVM晋升对象阈值的目的是使得Sidx和Srd记录索引缓存和记录缓存分配在年长代;设置Reduce任务JVM晋升对象阈值的目的是使得缓存Shuffle的对象分配在年长代.通过分析每次MinorGC发生之前的Eden空闲空间,可以估计晋升对象阈值的大小. 晋升对象阈值估计算法(算法2)描述如下. 输入:MinorGC时Eden的空闲空间向量a 输出:对象晋升阈值的估计值 (1)计算初始聚类中心c,c[1]=maxa,c[2]=mina. (2)使用k-均值聚类算法对a进行聚类. (3)计算各聚类的摘要统计信息,包括最小值、均值、中位数、最大值等. (4)选择Eden均值较大簇的Eden最小值作为晋升对象阈值的估计值. 4.1 实验环境 Hadoop测试集群有8个从节点,每个从节点分配5GB内存,排他性使用一个E5-2609@2.4GHz的物理核.每个从节点分配2个Map任务槽和1个Reduce任务槽,Hadoop以Apache1.2.1为基础,修改了Reduce任务内存管理和日志保存机制.文中选择PUMA测试套件[17]的Wordcount(WD)、Invertedindex(ID)、TeraSort(TS)、Adjlist(ADJ)、Kmeans(KM) 5个测试程序.Wordcount、Invertedindex测试程序的输入数据为多个文件组成的大小为10GB的Wikipedia数据集(单个文件大小为几百兆到1GB左右).Adjlist测试程序的输入数据集为从图数据集[18]中随机选出的10GB数据.TeraSort测试程序的输入数据是使用MapReduce的程序自动生成(10GB左右).Kmeans测试程序使用PUMA推荐的电影评论数据(大小为11GB).HDFS数据块和Map任务的Split大小均为64MB,HDFS的副本数设置为1,慢启动设置为1.由于Map任务和Reduce任务运行的节点只有一个CPU核,因此Map任务和Reduce任务均选择使用串行垃圾回收器.JVM使用64位Linux系统下JDK1.7.0update45. 4.2 任务年轻代内存分析 使用局部加权线性回归模型拟合Eden与MinorGC平均暂停时间的关系.使用R[19]统计工具库的Loess[20-21]对WD、ID、TS、ADJ、KM的Map任务和Reduce任务的MinorGC进行回归建模.回归模型的预测精度如表1所示.使用内存搜索算法1(u设置为100MB)预测年轻代内存大小,结果如表2所示,预测精度如表3所示.表3中年轻代预测值为100MB表明:算法1搜索范围达到上界100MB,此时预测的大于0.01. 表1 回归模型的预测精度 表2 算法1预测的年轻代内存大小 表3 Minor GC代价预测精度 为了测试算法1的运行效率,分别使用WD、ID、TS、ADJ和KM的数据测试算法1,重复运行10次,平均运行时间分别为22.0、11.0、3.8、2.0与2.9 ms. 从表2可知,Map任务的年轻代内存分配普遍较大(除KM外).进一步分析Map任务运行历史数据和Minor GC暂停时间历史数据后发现:①Map任务的运行时间较短,通常为20 s左右,因此Minor GC暂停时间只能小于等于200 ms;②随着Map任务JVM的Eden区域内存的增大,单次Minor GC操作的时间也相应增加. 从表3可知,除了WD和ADJ的Reduce任务的Minor GC暂停时间的百分比大于1%外,其他任务的Minor GC暂停时间百分比均小于或等于1%. WD的Map任务和Reduce任务运行时间随年轻代内存大小的变化如图4所示,其中任务运行时间为同一个作业的Map任务和Reduce任务的平均运行时间.从图4可知,年轻代内存在100~200 MB范围内能获得较好的运行时间与年轻代内存大小的折衷.ID、TS、ADJ与KM的任务运行时间也呈现与WD任务运行时间相似的特征.由此可以对算法1中的u值做进一步限制,将u限制为100 MB. 图4 Wordcount的Map和Reduce任务运行时间与年轻代内存大小的关系 Fig.4 Relationship between running time of tasks and new gene-ration memory size for Wordcount’s map and reduce tasks 4.3 任务年长代内存分析 每个MapReduce作业包含大量的Map任务和Reduce任务,所有的Map任务和所有的Reduce任务分别共享相同的内存配置,因此合理的内存配置应该保证所有Map任务和Reduce任务的运行性能最优.5种MapReduce程序的Map和Reduce任务的Smr分布如图5所示,其中CDF为累积分布函数.从图中可知,5种MapReduce作业的Smr分布集中,因此即使采用最大内存需求也不会造成过多的内存资源浪费. Pred(即文中提出的优化配置方法)和Starfish推荐的内存配置如表4所示.从表4可知,Pred推荐的内存配置均比Starfish的小.为评价Smr分配的合理性,文中分别统计了默认配置、Starfish和Pred配置条件下发生溢写的任务数,结果如表5所示,其中MSC、MNSC、RSC和RNSC分别为发生溢写的Map任务数、未发生溢写的Map任务数、发生溢写的Reduce任务数和未发生溢写的Reduce任务数.未发生溢写是任务获得最佳运行性能的基本条件.从表4和表5可知,Pred能在使用比Starfish更少的内存配置下获得最佳的任务执行流程,即未发生溢写操作. 图5 5种MapReduce程序的Map和Reduce任务的Smr分布 Fig.5Smrdistribution of Map and Reduce tasks of the five MapReduce applications 表4 Starfish和Pred推荐的内存配置 Table 4 Memory configurations recommended by Starfish and Pred 测试程序内存配置/MBStarfishPredMapReduceMapReduceWD50040003502260ID120040003502680TS50040002501500ADJ120040004102000KM45040001502000 Starfish与Pred的MapReduce相关重要参数的优化配置如表6所示,参数c1、c2、c3、c4、c5、c6、c7分别表示io.sort.mb、io.sort.record.percent、io.sort.spill.percent、mapred.job.reduce.total.mem.bytes、mapred.job.shuffle.merge.percent、mapred.job.shufle.input.buffer. percent和mapred.job.reduce.input.buffer.percent. 与Starfish相比,Pred不仅优化了MapReduce层的配置参数,还根据年轻代与年长代的内存大小对JVM的内存参数进行配置,对JVM的参数配置包括设置JVM的堆大小、年轻代内存大小及对象晋升阈值.与文献[2,6-8]相比,Pred对参数c4进行了设置,以实现更加灵活的JVM内存配置. 表5 3种配置下溢写操作统计结果 表6 Starfish与Pred 的MapReduce参数配置 4.4 晋升对象阈值分析 对象晋升会增加Minor GC的暂停时间,最终增加Map和Reduce任务的运行时间.分析Map任务和Reduce任务的对象晋升时序可以分析对象晋升对Map和Reduce任务的影响.在默认配置下,收集WD的一个Map和Reduce任务的GC日志数据,得到该Map和Reduce任务的晋升时序图[22],如图6所示.Map任务在开始阶段发生了对象晋升,晋升对象大小的理论值应大于100 MB×0.05×0.8=4 MB,根据Hadoop 1.2.1的实现,该4 MB空间进一步划分为1 MB和3 MB两个缓冲区,与图6(a)实验数据契合.Reduce任务的Shuffle阶段会不断分配缓冲来保存拷贝的数据,因此在Shuffle阶段发生大量的对象晋升操作,如图6(b)所示.由此可见,对于Map任务,对象晋升发生次数少,对Minor GC性能的影响有限,但Reduce任务受对象晋升的影响很大.使用算法2获得的晋升对象阈值来优化配置运行相同的作业,发现Reduce任务在优化配置下的Minor GC总暂停时间只有在默认设置下的1/8.使用算法2分析WD、ID、TS、ADJ和KM的Minor GC日志,获得的对象晋升阈值分别为4、4、2、18和5 MB. 图6 对象晋升时序图 4.5 作业性能分析 MapReduce配置参数调优以Starfish最为全面,效果最佳.与基于经验的配置参数优化相比,Starfish能获得更好的性能提升[2].在Starfish 0.3.0的基础之上增加了Adjlist、Invertedindex与Kmeans测试程序的支持,在相同的集群资源下分别比较5种测试程序在默认配置、Starfish和Pred优化配置下的运行时间,结果如表7所示.除了Kmens外,Starfish和Pred给出的配置参数建议显著提升了作业性能,且Pred的作业性能在5种测试程序下均优于Starfish.排除Kmean测试程序,与默认配置相比,Starfish在测试集群上对其他4种作业的平均加速比为3.5,最大加速比为6.1;同理,Pred对其他4种作业的平均加速比为6.4,最大加速比为8.0.实验结果表明,Starfish与Pred对Kmeans的性能调优效果不明显,究其原因,Kmeans是一种计算密集型应用,其性能瓶颈在于CPU资源. 表7 5种MapReduce程序在不同配置下的运行时间对比 Table 7 Comparison of running time among five MapReduce applications with different configurations 测试程序运行时间/s默认配置Starfish配置Pred配置WD968384376ID43281053566TS20161557271ADJ69901139870KM616959905793 Starfish目前只支持Hadoop 0.20,要求MapReduce必须使用新的API编写.Pred只需要作业的历史记录文件和任务的JVM输出的垃圾回收日志,MapReduce的各个版本均支持通过简单配置获得这些数据,因此从原理上讲,Pred比Starfish更易于使用. 文献[9-10]表明,在Facebook、雅虎和淘宝的Hadoop生产集群中,大部分MapReduce作业的输入数据只是GB级别,当前的Hadoop集群内存资源足够将这些数据全部放在内存中处理.对于这种数据规模的MapReduce作业,Pred能提供很好的性能优化效果. 文中提出了一种分代内存大小预测方法和JVM优化配置方法;根据JVM的分代内存管理特点,分别使用不同的方法来预测JVM不同分代的内存区域大小(采用回归模型预测特定年轻代大小下垃圾回收的平均暂停时间,即通过计算分配在年轻代中对象的总大小获得Minor GC发生次数的估计,Minor GC平均暂停时间乘以Minor GC发生次数即为特定年轻代大小下的Minor GC总暂停时间;通过Map和Reduce阶段的性能模型与内存模型的关系来预测年长代内存大小);最后设计一种搜索算法来求解最佳的年轻代内存大小.文中提出的年轻代预测方法充分考虑了Map和Reduce任务的最佳工作流和数据流,因此也是一种MapReduce作业的配置参数优化方法.测试结果表明,与默认配置相比,除了计算密集型的测试程序Kmeans外,文中方法对其他4种测试程序的内存优化配置性能平均提升了6倍,性能提升最大为8倍.与Starfish相比,文中提出的方法在提升性能的前提下,更易于应用到生产集群中. [1] DEAN J,GHEMAWAT S.MapReduce:simplified data pro-cessing on large clusters [J].Communications of the ACM,2008,51(1):107-113. [2] HERODOTOU H,LIM H,LUO G,et al.Starfish:a self-tuning system for big data analytics [C]∥Proceedings of the 5th Biennial Conference on Innovative Data Systems Research.Pacific Grove:ACM,2011:261-272. [3] HERODOTOU H.Hadoop performance models [EB/OL]. (2011-06-06) [2015-10-09].http:∥arxiv.org/pdf/1106.0940v1.pdf.[4] YANG H,LUAN Z,LI W,et al.MapReduce workload mo-deling with statistical approach [J].Journal of Grid Computing,2012,10(2):279-310. [5] 周世龙,陈兴蜀,罗永刚.基于灰盒模型的Hadoop Map-Reduce job参数性能分析与预测 [J].四川大学学报(工程科学版),2014,46(S1):146-154. ZHOU Shi-long,CHEN Xing-shu,LUO Yong-gang.Hadoop MapReduce job performance analysis and prediction based on grey-box model [J].Journal of Sichuan University(Engineering Science Edition),2014,46(Suppl1):146-154. [6] JOHNSTON T,ALSULMI M,CICOTTI P,et al.Perfor-mance tuning of MapReduce jobs using surrogate-based modeling [J].Procedia Computer Science,2015,51:49-59.[7] LIU C,ZENG D,YAO H,et al.MR-COF:a genetic Map-Reduce configuration optimization framework[M]∥Algorithms and Architectures for Parallel Processing.Zhang-jiajie:Springer,2015:344-357.[8] LI M,ZENG L,MENG S,et al.MRONLINE:MapReduce online performance tuning [C]∥Proceedings of the 23rd International Symposium on High-Performance Parallel and Distributed Computing.Vancouver:ACM,2014:165-176.[9] REN Z,WAN J,SHI W,et al.Workload analysis,implications,and optimization on a production hadoop cluster:a case study on taobao [J].IEEE Transactions on Services Computing,2014,7(2):307-321. [10] CHEN Y,GANAPATHI A,GRIFFITH R,et al.The case for evaluating MapReduce performance using workload suites [C]∥Proceedings of IEEE the 20th International Symposium on Modeling,Analysis & Simulation of Computer and Telecommunication Systems.Singapore:EEE,2011:390-399. [11] XU L,LIU J,WEI J.FMEM:a fine-grained memory estimator for MapReduce jobs [C]∥Proceedings of the 10th International Conference on Autonomic Computing.San Jose:USENIX in Cooperation with ACM SIGARCH,2013:65-68.[12] SINGER J,KOVOOR G,BROWN G,et al.Garbage co-llection auto-tuning for Java MapReduce on multi-cores [J]. ACM SIGPLAN Notices,2011,46(11):109-118. [13] KEJARIWAL A.A tool for practical garbage collection analysis in the cloud [C]∥Proceedings of 2013 IEEE International Conference on Cloud Engineering.California:IEEE,2013:46-53. [14] ANGELOPOULOS V,PARSONS T,MURPHY J,et al. GcLite:an expert tool for analyzing garbage collection behavior [C]∥Proceedings of IEEE the 36th Annual Computer Software and Applications Conference Workshops.Turkey:IEEE,2012:493-502.[15] Sun Microsystems.Memory management in the Java Hot-Spot virtual machine [EB/OL].(2006-04-01)[2015-10-09].http:∥www. oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf.[16] RAO S S.Engineering optimization:theory and practice[M].4th ed.Hoboken:John Wiley & Sons,2009. [17] AHMAD Faraz,LEE Seyong,THOTTETHODI Mithuna,et al. PUMA:Purdue MapReduce benchmarks suite[EB/OL]. (2012-10-30)[2015-10-13].https:∥pdfs.semanticscholar.org/70bd/563d00fcb402eb7d9f251bea-544ecb-08f213.pdf.[18] AHMAD Faraz.PUMA bencharks and dataset downloads[EB/OL].(2011-05-17)[2015-10-13].ftp:∥ftp.ecn.purdue.edu/puma/adjlist_30GB.tar.bz2. [19] R Core Team.R:a language and environment for statistical computing [EB/OL].(2015-03-09)[2015-10-09].https:∥www.r-project.org. [20] KABACOFF R.R语言实战 [M].高涛,肖楠,陈钢,译.北京:人民邮电出版社,2013. [21] CLEVELAND W S,DEVLIN S J.Locally weighted regression:an approach to regression analysis by local fitting [J].Journal of the American Statistical Association,1988,83(403):596-610. [22] 罗永刚,陈兴蜀,王煜骢.基于垃圾回收的MapReduce作业内存调优 [J].四川大学学报(工程科学版),2015,47(6):104-112. LUO Yong-gang,CHEN Xing-shu,WANG Yu-cong.GC-based MapReduce job memory tuning [J].Journal of Sichuan University(Engineering Science Edition),2015,47(6):104-112. MapReduce Job Performance Tuning by Optimizing Memory Configurations LUOYong-gangCHENXing-shuYANGLu (Cybersecurity Research Institute, Sichuan University, Chengdu 610065, Sichuan, China) MapReduce job performance depends heavily on memory configurations. In order to overcome the difficulty in predicting the memory requirement of MapReduce jobs, on the basis of the fact that Java Virtual Machine (JVM) divides the heap space managed by JVM Garbage Collector into young and old generations, a generational memory prediction method is proposed. In the method, first, a regression model to resolve average garbage collection time for a given young generation size is constructed. Then, the problem of looking for the rational size of young generation is converted into a constrained nonlinear optimization problem, and a fixed-size search algorithm is designed to solve the optimization problem. Moreover, memory models of the Map and Reduce tasks of MapReduce jobs are constructed to solve the memory requirement of optimal performance, thus obtaining reasonable old generation memory size of the Map and Reduce tasks. Finally, ak-means clustering algorithm is used to predict the value of parameter PretenureSizeThreshold, and JVM configurations are tuned to reduce garbage collection pause time. Experimental results show that the proposed method can accurately predict the memory requirements of the Map and Reduce tasks of MapReduce jobs, and it can significantly improve job performance. big data; MapReduce; garbage collection; memory allocation; performance tuning 1000-565X(2017)01- 0102- 10 2015- 11- 25 国家科技支撑计划项目(2012BAH18B05);国家自然科学基金资助项目(61272447) Foundation items: Supported by the National Science and Technology Support Planning Program of China(2012BAH18B05) and the National Natural Science Foundation of China(61272447) 罗永刚(1980-),男,博士生,主要从事大数据和网络安全研究.E-mail:iamlyg98@163.com TP 393.09 10.3969/j.issn.1000-565X.2017.01.0152 g(e,s)求解

3 作业性能分析与优化
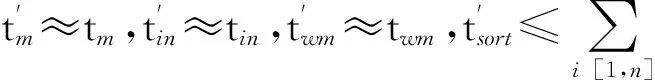


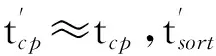
3 JVM配置优化
4 实验与结果分析



5 结论
