基于混合数据挖掘模型预测用户流失*
2017-04-24辽宁大学计算中心沈阳0036辽宁大学信息化中心沈阳0036
董 博,王 雪(.辽宁大学计算中心,沈阳 0036;.辽宁大学信息化中心,沈阳 0036)
基于混合数据挖掘模型预测用户流失*
董 博1,王 雪2
(1.辽宁大学计算中心,沈阳 110036;2.辽宁大学信息化中心,沈阳 110036)
用户流失预测问题广泛应用在银行、金融、电信等多种领域。对用户行为进行有效的预测和分析有助于企业的竞争和了解瞬息万变的市场规律。采用3种混合的数据挖掘模型对用户流失问题进行了研究,以形成一个准确高效的用户流失预测模型。这3种模型应用于数据挖掘的两个阶段:聚类阶段和预测分析阶段。在第1阶段中,对用户的数据进行过滤。第2阶段对用户行为进行预测。第1个模型采用了二分k-means算法进行数据过滤和多层感知人工神经网络(MLP-ANN)相结合进行预测。第2个模型采用层次化聚类与MLP-ANN相结合进行预测。第3个模型使用自组织映射(Self-Organizing Maps)与MLP-ANN进行预测。这3种模型预测分析基于真实数据,用户流失率采用3种模型混合计算的方式得出结果并同真实值进行比较。分析结果表明采用多模型的混合数据挖掘模型的数据准确度优于普通的单一模型。
数据挖掘,用户流失,人工神经网络,多层次感知,自组织地图
0 引言
用户生命周期包含5个主要阶段:获取用户信息,建立,峰值,下降和用户流失[3]。“用户流失”这一术语,经常用于电信领域,主要表示变更服务(由不同的电信运营商提供)的用户[4]。用户流失管理过程是任何成功的公司所必须考虑的问题。用户流失管理过程的目标是,预测那些在发生“用户流失”行为之前有用户流失意向的用户,从而有效地保留老用户[5]。流失预测有助于评估当前公司的情况,从而设置具体的计划或制定有针对性的营销活动。而且,用户流失预测是保证作出一个准确有效决策的重要因素[6]。
许多学者提出了不同的机器学习方法来预测电信业务中的用户流失问题。这些方法大多采用单一分类算法,如文献[2-10]。然而,由于用户流失的数量通常远远小于忠诚用户,这种不平衡的分布规律使得流失预测是一个具有挑战性的问题。正基于此,使得大多数传统的单一机器学习方法不适合对数据进行分类[11]。因此,其他研究人员提出了多种机器学习方法相混合的算法,用于预测用户流失问题。其中比较有代表性的方法,如文献[11-13]中的算法,在用于数据执行分类任务前的预处理。一些作者建议将数据聚类成一个系列的子集,并去除一些小的子集,从而过滤掉一些不具有代表性数据[13-15]。
在本文中,提出了3种混合的数据挖掘模型用于电信行业的用户流失预测。所有这3个模型均由一个聚类算法和一种分类算法构成。首先,聚类算法的主要作用是过滤掉不具代表性的行为。其次,分类算法在机器学习过程中,用已经过滤好的数据建立最终的预测模型。在聚类过程中,采用3种算法分别为:二分k-means算法,自组织映射算法(Self-Organizing Map),层次化聚类算法。分类算法采用多层感知人工神经网络(MLP-ANN)算法。
1 相关研究
1.1 二分k-均值聚类算法
K-均值(k-means)聚类算法,是由Steinhaus于 1956年,LIoyd于1957年,Ball和Hall于1965年,McQueen于1967年分别在其各自不同的科学研究领域所提出的[16]。之所以称为k-均值算法,是因为该算法可以发现k个不同的簇,并且,每个簇的中心计算过程由其所含值的均值构成。簇的生成过程是基于数据点与聚类中心的距离最短为原则。工作流程如下:首先,确定要创建的簇的数量。其次,随机选择这些簇的中心(称为质心),以任意的数据点作为初始聚类中心。再次,确定每个数据点与质心的距离(欧氏距离或曼哈顿距离通常选择测量距离),将每个节点分配给该质心所对应的簇。最后,根据计算每个簇中节点的平均值,更新其所属簇的质心,数据点被分配到最接近的质心。这个过程迭代执行,直到达到最低标准或包含数据点的簇组成保持不变。
1 210例特发性鼻出血患者和406例对照组基因频率分布见表1。在采用对照组资料之前,首先对其可靠性进行检验,采用t值表示:,|t|≤2,P>0.05)说明期望值与观察值间并无显著性差异,对照资料可靠。
k-均值算法会产生收敛于局部最小值的问题[17],为了解决该问题,一些学者提出了二分k-均值(bisecting K-means)算法[18]。算法过程如下:首先将所有点划分到一个簇中,然后一分为二,分割该簇。其次,选择其中之一继续进行划分。对于每一个簇计算总误差,选择误差最小的簇进行划分。直到簇的数量大于等于K。
1.2 层次化聚类算法
层次化聚类算法的过程是建立一个集群的层次结构或一棵树的集群。以自底向上(合并)方法为主要过程,算法过程如下:首先,将每个数据对象作为一个簇,之后对这些簇集依照某种准则(如单链、全链或平均分组)被一步步进行合并。簇集的聚类合并过程会反复进行,直到所有数据对象最终合并形成一个簇或者达到用户所指定的簇数目。
层次聚类算法的主要优点是:能够发现任意形状的簇类型,不存在K均值算法中的初始质心选择的问题,能够产生较高质量的聚类。主要缺点:①时间复杂度较高,对大数据集的处理基本上是计算不可行的;②合并决策是最终的,一旦决定不能撤消,这意味着一组对象一旦合并则下一步处理将在新生成的簇上进行,已做的处理不能被撤销,簇之间也不能交换对象,这可能会导致低质量的聚类结果,有可能造成局部最优变成全局最优[17]。
1.3 自组织映射(Self-Organizing Maps)算法
自组织映射(Self-Organizing Maps)算法[19]是一种聚类算法,也是高维可视化的无监督学习算法,算法通过模拟人脑中对信号处理的特点而发展起来的一种人工神经网络模型。该模型由芬兰赫尔辛基大学教授Teuvo Kohonen于1981年提出后,已经成为应用最广泛的自组织神经网络学习方法。
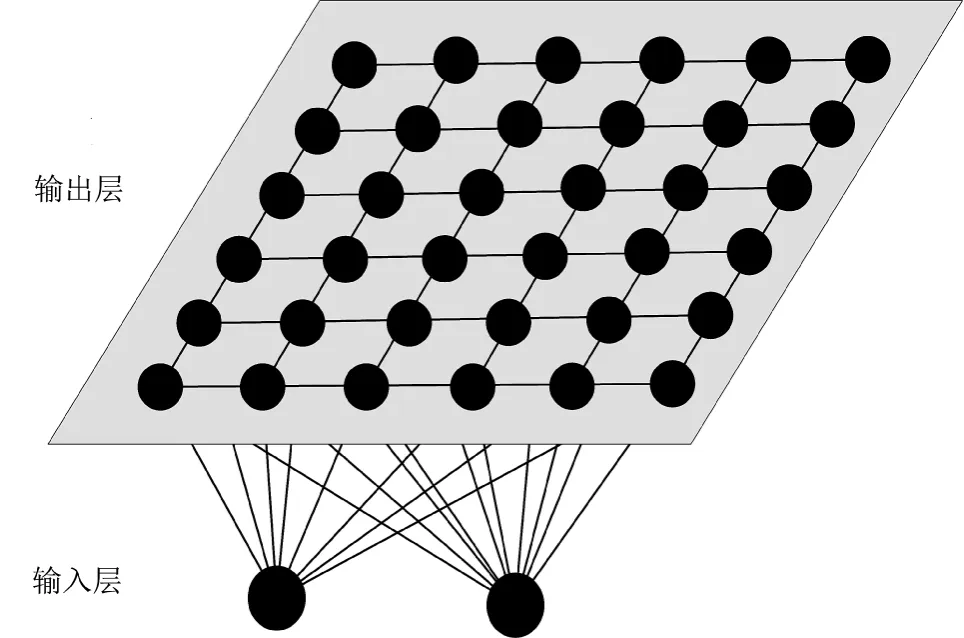
图1SOM网络拓扑结构图
训练SOM网络是基于矢量量化的。输入由向量x1,x2…组成,其中每一个向量使用的输入空间的概念,是指可以在一个输入空间内的可视化的输入向量的输入空间内的向量相同维数。矢量量化思想是将整个空间划分为区域,SOM网络是基于竞争学习。竞争学习的理念是,当一个以输入向量表示的模式被应用于输入单元,其中一个响应单位,由于它的权重向量是到输入矢量X最小的欧氏距离而赢得了竞争。然后,权重向量通过移动它更接近输入矢量X被改变。这个过程再将所有的向量集中对所有模式重复执行。如图1所示,SOM的输入层模拟视网膜感知外界的信号,通过类似于网络拓扑结构的连接方式,将信号传输到输出层模拟的大脑皮层,从而对输入作出正确的响应。
1.4 多层感知神经网络
人工神经网络是由生物神经系统激发的数学模型。模式识别在计算中通过传统的编程方法实现,是一个非常复杂的任务,而人类能够很自然地执行许多类似这样的任务。通过应用神经网络技术的模型可以学习的例子,并创建一个内部复杂的结构和规则来分类不同地输入,如预测用户流失问题。神经网络通过一个学习过程,能够有效地进行模式识别或数据分类。
人工神经网络将一组输入节点映射到一组输出节点。输入/输出的数量是可变的。网络本身是由任意数量节点的任意拓扑结构。因为人工神经网络适应未知的情况同时具有容错性、自主学习和泛化能力,所以人工神经网络已广泛用于解决数据挖掘问题。
在用户流失预测过程中,利用多层感知器神经网络(MLP-ANN)。多层感知器(MLP)是一个多层次的,非线性神经网络。由输入层,一个或多个隐藏层和输出层组成多层次结构。每个隐藏层神经元的激活函数是非线性的,如S状弯曲或类似于S状弯曲。每个神经元的特点是激活功能,并连接到所有下一层神经元中[20]。每条连接表示是它的权重因子或突出权重。一个典型的基于多层感知器的神经网络如图2所示。
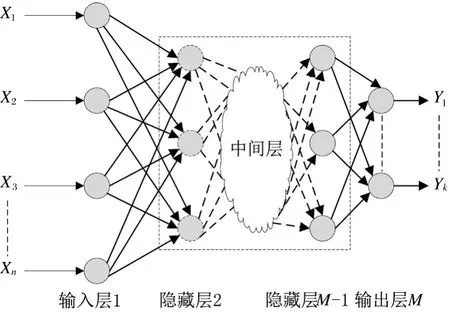
图2 多层感知器神经网络示意图
该结构中共有M层结构,第一层是输入层,第M层为输出层。隐藏层从第二层到第(M-1)层。每一层的神经元同下一层次的神经元网络是完全互联的。这使得从输入层通过隐藏层正向传输到输出层成为可能。输入信号在这里可以通过网络逐步向前移动。第M层输出可以表示为:
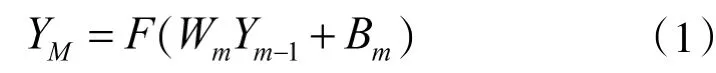
其中,F表示每个神经元的激活函数。YM和Ym-1是第M层和第M-1层的输出,Wm是M层和M-1层之间的权重矩阵,Bm是偏差矩阵[21]。源于输出的错误信号可以智能地在网络中向后倒退。训练的过程是持续的直到错误到达最低期望的水平。输入/输出的数量是可变的。训练MLP-ANN模型,采用著名的反向传播学习算法。
2 用户流失预测模型结构
2.1 模型框架
所提出的用户流失预测模型,主要基于两个过程。第1阶段,聚类算法用于收集用户数据,对大量用户数据加入分组代表不同的行为。最大的两个集群分别代表流失用户和非流失用户的簇进行合并,并作为下一阶段的输入。另一方面,小集群被忽略,因为这组小集群代表异常行为。在研究过程中,采用3种不同的聚类方法二分k-均值算法、层次化聚类方法和SOM方法。第2阶段,采用MLP-ANN算法使用从第一阶段中获得过滤之后的数据,通过学习分类用户行为分为两类:流失用户和非流失用户。下页图3表示了所采用的双层模型的结构。
最后开发了MLP-ANN分类器模型对结果进行评估和评价,评估的结果基于新的不同于机器学习过程中所使用的测试数据。
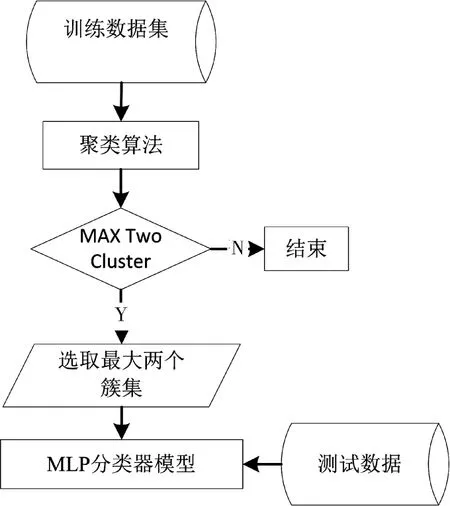
图3 用户流失预测流程图
2.2 数据集
本研究中采用的数据是采用某电信运营商移动电话数据(出于保密需要,未列出具体公司名称)。数据集如0中,包含15个属性、3个月内有消费记录的用户。属性值包括接打电话记录。

表1 实验中所用数据集表
训练数据与测试数据的分布如0所示,选取了3个月有通话记录的数据作训练数据和测试数据。其中选用5 000个数据作为训练数据,917个数据作为测试数据。用户是否流失的判定方法,通过原始记录中第5个月的数据可以得知。训练数据中流失用户总数为275个(占总用户的5.5%)。测试数据中流失用户的数量为55个。(占用户总数的5.9%)

表2 训练数据与测试数据分布表
2.3 评估标准
采用的评估标准使用的扬程曲线(lift curve)与误匹配率,预测模型的准确性。
在用户流失分析中的绩效分析中,扬程曲线是首选的评价和比较模型。给出一个用户流失概率阈值,扬程曲线图绘制出所有该阈值之上的用户的百分比并同在该阈值之上的所有流失用户的百分比相对比。它与ROC信号检测理论曲线和精确召回曲线相关[23]。
算法评估中也经常采用匹配率预测模型,如0所示。准确率AR(Accuracy Rate)的计算方法即:
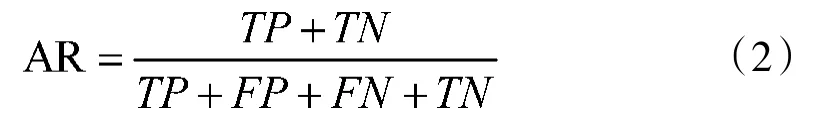
用户流失率CR(Churn Rate)的计算方法即:
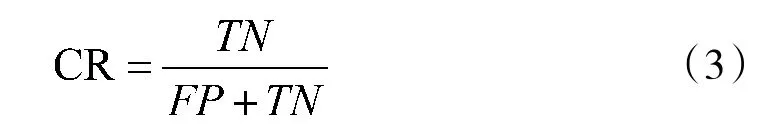
准确度AR计算方法,表示了在两种分类的情况下预测正确的全部比率;客户流失率CR的计算方法,在实际流失客户中预测正确的百分比。如果具有较高的AR和CR值,则表明模型建立的结果较好。
3 实验过程
首先,数据集被分成训练集和测试集两部分。之后选取一个聚类算法,从训练数据中进行对异常类的数据过滤。其次,采用神经网络模型(MLP),对过滤之后数据进行学习建立模型,并使用其他测试数据进行评估。
实验过程中,选取3种不同的聚类算法:二分k-均值算法、层次化方法和SOM方法。k-均值算法和层次化方法选取不同的k值从5到10。SOM方法中,采用的分区大小分别为(2×2),(2×3),(3× 3)和(4×4)。开始学习率设置为0.20,方差距离归一化。
为了建立准确的分类模型,神经网络是使用在第一阶段的聚类方法过滤后的数据进行训练。之后使用测试数据进行测试。MLP的参数调整如0。

表4MLP参数设置表

表3 匹配率预测模型表
采用3种不同的方法进行评估,之后与C4.5算法和不使用任何聚类技术的决策树算法的基本MLP模型进行比较。结果如图4所示。可以看出通过设置的k-均值为6的算法,层次化算法值为7的算法和(3×3)的SOM与MPL相结合的算法都得到了较好的预测结果,其中使用SOM与MPL相结合的算法获得了最好的CR预测结果
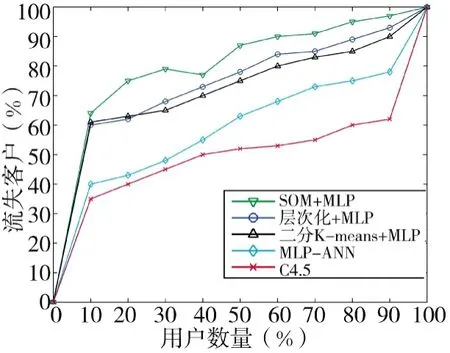
图4 预测用户流失率(CR)扬程曲线对比结果
图5中,对不同算法分别计算出的CR和AR值加以对比分析,从图中可以看出,所有混合方法的CR值和AR值同基本的C4.5和MLP-ANN算法相比都有相应的提升。第一种混合模型即二分k-均值聚类和MLP神经网络的算法在准确率(AR)值优于其他模型。用户流失率CR的均值计算中SOM聚类和MLP相结合的算法效果最好。
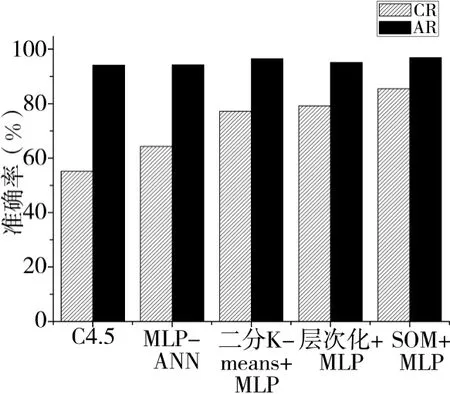
图5 不同算法CR和AR对比图
4 结论
数据挖掘的目标之一是提高对现有数据的理解,并预测未来可能即将发生的行为。本文提出了3种混合模式,以帮助电信公司分析和预测未来的客户行为。通过对3种混合模型的研究分析,便于制定一个准确、高效的客户流失预测模型,以帮助电信公司预测和分析未来的用户行为。这3种模型是分阶段的模型,主要包括聚类阶段和预测阶段两个阶段。3种模型的建立使用真实电信公司的数据进行验证,通过对准确率以及客户流失率值计算和同传统模型相比较,3个混合模型优于传统单一模型。
[1]ZHANG Y,WANG Y,HE C,et al.Modeling and application research on customer churn warning system based in big data era.[J].International Journal of Multimedia&Ubiquitous Engineering,2014,9(9):281-298.
[2]XIA G,JIN W.Model of customer churn prediction on support vector machine[J].Systems Engineering-Theory& Practice,2008,28(1):71-77.
[3]YABAS U,CANKAYA H C,INCE T.Customer churn prediction for telecom services[C]//COMPSAC 2012:Computer Software and Applications Conference,2012 IEEE 36th Annual.IEEE,2012:358-359.
[4]YESHWANTH V,RAJ V V,SARAVANAN M.Evolutionary churn prediction in mobile[C]//Proceedings of the 24th International Florida Artificial Intelligence Research Society Conference,AAAI Press,2011:471-476.
[5]KANG C,PEI-JI S.Customer churn prediction based on SVM-RFE[C]//ISBIM’08:International Seminar on Business andInformationManagement.Wuhan:IEEE,2008: 306-309.
[6]SHARMA A,PANIGRAHI D,KUMAR P.A neural network based approach for predicting customer churn in cellular network services[J].International Journal of Computer Applications in Technology,2013(27):26-31.
[7]RODAN A,FARIS H,ALSAKRAN J,et al.A support vector machine approach for churn prediction in telecom industry [J].In ternational journal on information,2014,17(8): 3961-3970.
[8]ADWAN O,FARIS H,JARADAT K,et al.Predicting customer churn in telecom industry using multilayer preceptron neural networks:Modeling and analysis[J].Life Science Journal,2014,11(3):75-81.
[9]BUREZ J,VAN DEN POEL D.Handling class imbalance in customer churn prediction[J].Expert Systems with Applications,2009,36(3):4626-4636.
[10]FARIS H.Neighborhood cleaning rules and particle swarm optimization for predicting customer churn behavior in telecom industry[J].International Journal of Advanced Science and Technology,2014,68(1):11-22.
[11]TSAI C,LU Y.Customer churn prediction by hybrid neural networks[J].Expert Systems with Applications,2009,36 (10):12547-12553.
[12]OBIEDAT R,ALKASASSBEH M,FARIS H,et al.Customer churn prediction using a hybrid genetic programming approach[J].Scientific Research and Essays,2013,8 (27):1289-1295.
[13]FARIS H,AL-SHBOUL B,GHATASHEH N.A geneticprogramming based framework for churn prediction in telecommunication industry[J].Lecture Notes in Computer Science,2014,8733(1):353-362.
[14]JAIN A K.Data clustering:50 years beyond K-means[J]. 19th International Conferencein Pattern Recognition (ICPR),2010,31(8):651-666.
[15]ZENG Z X.Effective hybrid clustering algorithm based on partition and hierarchy[J].Journal of Computer Applications,2007,27(7):1692-1694.
[16]STEINBACH M,KARYPIS G,KUMAR V,et al.A comparison of document clustering techniques[C]//KDD International Conference on Knowledge Discovery and Data Mining.Boston,2000:525-526.
[17]KOHONEN T.The self-organizing map[J].Neurocomputing,1998,21(1-3):1-6.
[18]WIDROW B,LEHR M.30 years of adaptive neural networks:perceptron,madaline,and backpropagation[J]. Proceedings of the IEEE,1990,78(9):1415-1442.
[19]SIT Y L,AGATONOVIC M,ZWICK T.Neural network based direction of arrival estimation for a MIMO OFDM radar[C]//EuRAD:Proceedings of the 9th European Radar Conference,IEEE,2012:298-301.
[20]NESLIN S,GUPTA S,KAMAKURA W,et al.Defection detection:improving predictive accuracy of customer churn models[R].Tuck School of Business,Dartmouth College,2004.
[21]MOZER M C,WOLNIEWICZ R H,GRIMES D B,et al. Churn Reduction in the Wireless Industry[C]//Advances in Neural Information Processing Systems,2000:935-941.
Anticipation of Customer Churn Based on Hybrid Date Mining Models
DONG Bo1,WANG Xue2
(1.Computing Center,Liaoning University,Shenyang 110036,China;2.Information Technology Center,Liaoning University,Shenyang 110036,China)
Customer churn prediction is widely used in a variety of fields including banking,finance and telecommunications.User behavior contributes effectively to predict and analyzes the law and understand the competitive fast-changing market.In this paper,using three hybrid data mining models,churn conducted a study in order to form an accurate and efficient customer churn prediction model.Two stages of the three models applied to data mining:clustering stage and predictive analysis phase.In the first stage,the customer's data is filtered.The second phase is customer behavior prediction.The first model is applied for the bisecting k-means algorithm for data filtering and Multilayer Perceptron artificial neural network(MLP-ANN)combined forecast.The second model uses hierarchical clustering and MLP-ANN combined forecast.The third model is the use of self-organizing map(Self-Organizing Maps)and MLP-ANN to predict.All three models predict based on real data,customer churn by the method of three hybrid models calculated and compared with the outcome of the true value.The results showed that the use of comparison data accuracy multiple models mixed data mining model is superior to conventional single model.
datamining,customerchurn,artificialneuralnetwork,multilayerperceptron,self-organizing maps
TP<311.13 class="emphasis_bold">311.13 文献标识码:A311.13
A
1002-0640(2017)03-0156-05
2016-02-12
2016-03-16
第54批中国博士后科学基金(2013M540232);教育部博士点基金(2013004212006);教育部基本科研业务费项目重大科技创新基金资助项目(N120817002)
董 博(1981- ),男,硕士,讲师。研究方向:数据挖掘、网络信息安全、无线传感器网络。
