引用图片激活扩散的信息加密方法
2017-04-20付熙徐龚希章
付熙徐,龚希章
(上海海洋大学 现代信息与教育技术中心,上海 201306)
(*通信作者电子邮箱xxfu@shou.edu.cn)
引用图片激活扩散的信息加密方法
付熙徐,龚希章*
(上海海洋大学 现代信息与教育技术中心,上海 201306)
(*通信作者电子邮箱xxfu@shou.edu.cn)
对于加密编码算法而言,复杂性、非线性和正确性是重要的特性。而人类对知识的处理正好具备这些特性,激活扩散理论则描述了人类对知识的处理方法。受到激活扩散理论的启发,提出一种全新的基于引用图片的信息编码方法。该方法中,每个字符都用一个RGB分量的相对位置和偏移量表示,编码数据则通过激活扩散的方法生成。同一个字符可以用不同的编码表示,而相同的编码也可以表示不同的字符。通过引入激活扩散模型,该方法创建了巨大的搜索空间,从而保证了解码的复杂性;另一方面,该方法也减少了密文和明文间的相关性。
激活扩散;密码编码学;动态编码;参照编码
0 引言
创建安全的编码系统一直是密码编码学的重要话题之一。安全编码的本质就是使合法用户能够容易地获得明文,而不让非法入侵者轻易地破解密文。要达到这个目的通常需要在两方面作出努力:一方面是增加密文破解的复杂度,另一方面是减少明文和密文之间的关联性。目前计算机硬件发展迅速,很多复杂的加密算法都可以在可接受的时间内被破译出来。而明文与密文的相关性通常也能通过对大量明文/密文对的分析被发现。幸运的是我们能从人的认知系统得到一些启发,得到一些好的解决方案。
我们所处的自然环境是一个极其复杂的系统,复杂到即使是最先进的机器也无法将其表示和存储,更遑论枚举每一个元素,但人类却能自如地认识和使用这个系统。人们建立了大量系统试图模拟人的认知[1]。激活扩散理论的产生正是为了解释人在自然系统中的推理过程[2-5]。该模型中知识和场景通常很复杂,没有合理的背景知识,推理者不可能得到正确的答案。因此,以背景知识作为密码,用激活扩散模型进行加密,再通过重复执行激活扩散的过程来解密是一种合适的密码编码方法。
本文的研究是建立一个激活扩散模型用于编码数据,模型中使用位图文件作为密钥,通过激活扩散对字符进行加密,解密时需要用到加密时的位图文件。
1 相关工作和研究动机
1.1 加密方法
目前研究者已经提出了大量的加密算法,并对这些算法进行了形式化分析。在文献[6]中攻击被分为仅有密文攻击、已知明文攻击和选择明文攻击,而防止这些攻击最有效的方法之一就是增加破解的复杂度。
基于此原则,研究者提出了两类算法:一类是基于逻辑计算的算法,如典型MD5算法[7]。MD5算法通过逻辑计算使得密文理论上要极长时间才能被破解,然而随着计算机性能的提升,该算法已可以在数小时内被破解[8]。另一类算法是基于替换的算法[9],这类算法的最大问题就是可以通过明文与密文的关系猜出明文[10]。
演化编码是一种新的编码方法,该类方法试图用不同的方法编码各个字符,这是一种好的趋势,然而目前的方法主要还是已有算法的组合[11]。另一种值得借鉴的是隐写方法,该类方法通常使用大的媒体文件隐藏少量的秘密信息[12-14]。
1.2 激活扩散理论
激活扩散理论首先由心理学和语义处理领域的科学家提出[2],而激活扩散模型目前已在复杂语义处理领域如推荐系统中得到应用[5]。该理论适合对复杂系统建模,最近就有相关工作用激活扩散模型对复杂的故事进行建模和推理[4]。激活扩散编码的原理如图1所示。

图1 通过激活扩散编码数据
如图1所示,输入数据被送到表示不同函数的节点中进行编码。这些函数对输入进行拆分、计算、替换或重排列等操作后将输出送入下一个节点,直至计算完成输出密文。由于固定的输入和背景知识(密钥)会获取固定的输出,因此可以被看作是对称加密的过程。
1.3 本文研究动机
一张图片通常有数十到上百万个像素,每个像素都可以表示为RGB三个分量,对于24位的位图图像,每一个分量值都可以用于对应一个字符。即使知道了位图的形状要枚举所有可能的位图在计算上都是不可行的,因此图片是适合作为密钥的。而一种简易的方式就是用字符的ASCII值在图片中的位置和分量表示字符,通过激活扩散算法搜索。
2 算法与评价
2.1 用索引位置和偏移表示字符
位图可以用像素表示,而每个像素的颜色都可以用3个分量RGB来表示。对于一幅24位位图来说,每个分量都是8位,和字符的ASCII码位数相同。图2表示了小写字母a在图片Lenna中的分布。

图2 小写字母“a”在图像中的分布
如图2所示,图(b)中的点表示该点所在位置的像素有某个分量值与小写字母a的ASCII码相同,不同颜色的点对应匹配的分量。显然,同一个字符可以在一幅图像中找到多个对应的分量。
很显然,一个字符可以用三元组〈X,Y,C〉表示,其中X和Y是像素的坐标,C是匹配的分量。由于图像可能较大,因此X和Y的值也可能较大,对于较长的文件,密文可能很长。因此,可以采用相对位置代替绝对位置,令Xi为表示第i个字符的像素的X轴位置,Yi为该像素Y轴位置,Xi-1和Yi-1分别为上一个字符的对应像素位置。则第i个字符的相对位置(ΔXi,ΔYi)如下所示:
ΔXi=Xi-Xi-1
(1)
ΔYi=Yi-Yi-1
(2)
为进一步减少搜索的范围并防止图像中没有与字符匹配的分量的极端情况,本文引入了偏移量的概念。如式(3)所示,只要分量与字符ASCII值小于偏移量Dev即可,而偏移量在激活扩散的过程中可以逐渐增大。
|P(x,y).C-ASCII(S)|≤Dev
(3)
引入偏移量后,字符可用四元组〈ΔX, ΔY,C,D〉表示,其中D是偏移量,如式(4)所示。
D=P(x,y).C-ASCII(S)
(4)
对文本信息编码后的密文表示如图3所示。

图3 编码后的密文表示
如图3所示,头部注明起始搜索位置和表示一个字符需要的长度,文件体中保存每个字符的加密表示,包括相对位置ΔX,ΔY、分量C和偏移D。为了提高密文的安全性,头部也可以不和密文放在一起。
2.2 用激活扩散模型编码数据
可用如图4所示的激活扩散模型对字符进行编码。

图4 用于编码的激活扩散模型
如图4所示,模型由4个节点组成:
1)输入节点获取输入的文本,将字符拆分出来,并将字符和它的起始搜索位置发给定位节点,如果输入已经结束,该节点还将结束符发给编码节点。
2)寻址节点负责搜索与字符匹配的分量位置,并将分量的位置、名称和偏移量输出给编码节点。在搜索的过程中,如未找到匹配分量,寻址节点还向偏移节点发送偏移增大请求以提高允许的偏移量。字符找到对应位置时,该节点还向输入节点索要下一个字符。
3)偏移节点的作用较为简单,只需接收寻址节点的请求并发送改变后的偏移量给寻址节点即可。
4)编码节点负责将获得的信息编码成密文的最终形式,在接到输入节点的结束指令后等待当前编码完成后结束编码输出密文。
这个过程对应的加密算法如下:
输入 字符串S,位图B,起始搜索位置p(x,y);
输出 密文编码E。
步骤1 将起始位置和一个字符的密文长度写入E作为头部。
步骤2 对于每一个S中的字符c进行以下步骤编码:
步骤2.1 重置相对位移Δx,Δy、搜索范围变量i,j和允许偏移量dev为0。
步骤2.2 搜索像素p周围坐标在 ([x-i,x+i],[y-i,y+i])之间的点的RGB分量,如果找到像素的某一个分量符合颜色值与字符c的ASCII码之差的绝对值小于等于允许偏移量dev,则记录下像素的位置Δx、Δy,分量名称(R,G或B)以及颜色值与字符c的ASCII码之差d,将其输出到E,并以该像素位置为新的起始搜索位置(x,y)编码下一个字符。如果未找到符合要求的字符则扩大搜索范围(i=i+1)和增大允许偏移量(dev=dev+1)继续搜索直至搜索到符合要求的分量为止。
解密的算法较加密更为简单,只需根据密文找到对应的分量和偏移量即可计算出字符。算法如下:
输入 密文E,密钥位图B;
输出 明文字符串S。
步骤1 读入密文头部,获取起始搜索位置p(x,y)。
步骤2 根据头部信息用如下步骤逐个处理加密元组直至密文尾部:
步骤2.1 提取元组中相对位置Δx、Δy,分量c和偏移d;
步骤2.2 获取像素位置(x+Δx,y+Δy),取得c对应分量的颜色值color;
步骤2.3 获取字符ASCII码:asc=color+d;
步骤2.4 通过ASCII码得到字符并加入明文S;
步骤2.5 以当前像素位置(x+Δx,y+Δy)作为下个字符搜索起始位置。
2.3 评价与标准
评价加密算法有很多种标准,但所有标准都分为两个部分:一部分是正常的加密解密需要正确高效地完成,另一部分是没有密钥的攻击者不能轻易地获取全部或部分明文。若明文和密文间无任何相关关系则可以称该加密算法是绝对安全的。衡量明文和密文关系的最著名标准就是香农提出的信息熵[8]。
令T表示明文,R表示明文在密文中的表示(在本文中为对应的四元组),Pi表示第i个字符出现的概率,Pj表示第j个表示出现的概率,Pij表示第i个字符对应第j个表示出现的概率。若式(5)成立则表示明文与密文无关。
(5)
由于事实上式(5)不可能为0,本文用明文自信息和明文与密文互信息之差评价明文和密文之间的不相关性,如式(6)所示。
(6)
D值越大证明密文和明文的相关性越小。易证明文和自身之间以及明文和一对一替换密文之间的D值都为0。
另一个评价标准就是破解的复杂性,根据前文的描述,显然通过枚举的方法是无法猜测出用于加密的图片的。
3 实验和结果分析
3.1 实验设计
在本文的实验中:一篇包含有约66 000字符的英文文本被用作明文;两张不同的图像被用作知识环境,其中一张是常用图像库中的Lenna(512×512),另一张是随机生成的600×600的图片。第一个字符的初始搜索位置均为(100,100)。文本的字符分布如表1所示。
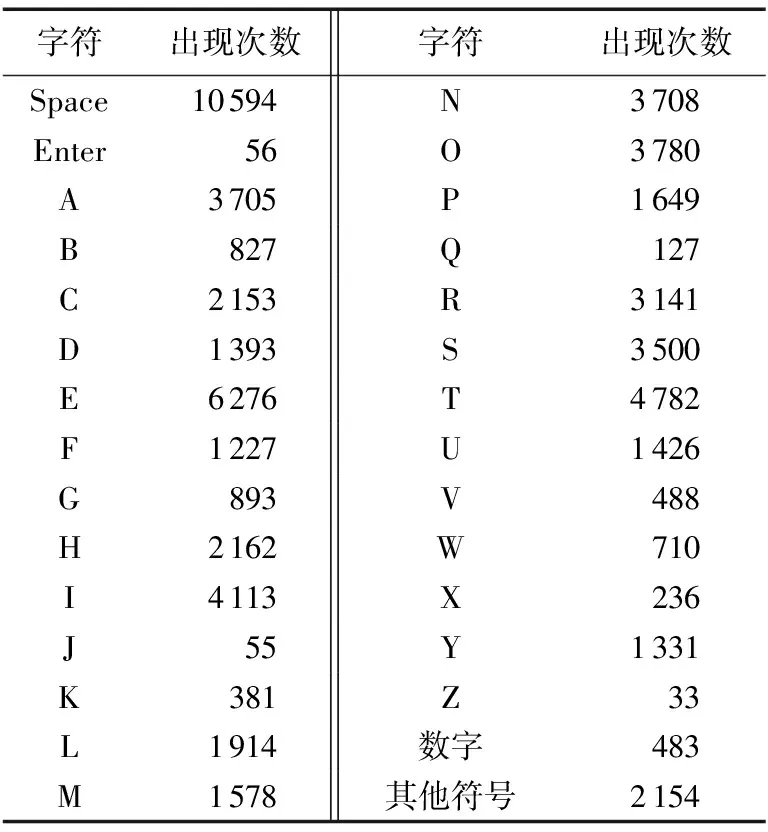
表1 实验文本的字符分布情况
经计算,文本中字符的平均熵为3.068。
3.2 实验结果
对应不同字符的表示数目情况如表2所示。表2中:RFlenna是用图片“Lenna”作为知识背景时各字符对应的密文表示数目;RFrandom是用随机生成的图片作为知识背景时各字符对应的密文表示数目。从该表中可以看出,一个字符可以对应多种加密表示。另一方面,两个实验中平均每个表示对应的字符数也分别为3.107和6.954。根据表2可以得知字符和其编码之间没有对应关系,明文和密文间的联系也很弱。
为了更好地说明明文与密文间的无关性,可以用前文中介绍的基于信息熵的方法进行评估。在两个实验中,密文与明文的互信息分别为1.948和1.274,根据式(6)计算出信息熵下降值D分别为1.12和1.794,明显好于直接替换的情况。
编码一个字符的实际复杂性S可以用式(7)表示:
S≤(|X|×2+1)×(|Y|×2+1)×3
(7)
统计搜索空间内完成匹配的字符数量的结果如表3所示,可以看出,尽管图像中有海量的候选值,但绝大多数字符还是在搜索了不到50个分量时就完成了编码。
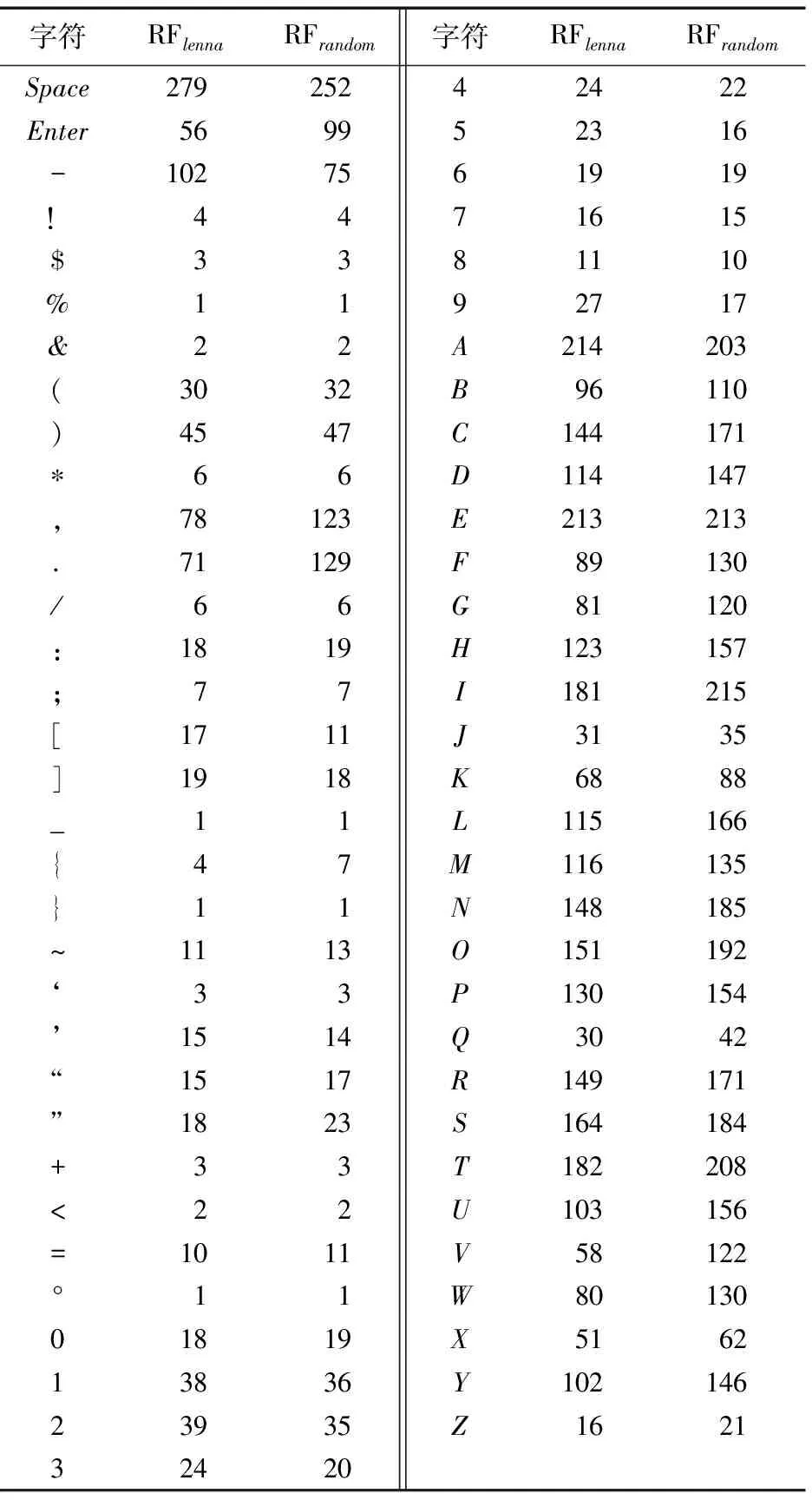
表2 各字符对应的表示数目

表3 编码搜索空间情况
4 结语
受到激活扩散理论的启发,本文提出了一种新的加密编码方法。该方法使用图片作为密钥,通过相对位置索引编码字符。本文分析表明该算法是正确的、非线性的,可以快速解密,明文和密文的关联度低,而且无法通过枚举的方式攻击。最后实验结果也显示该加密算法事实上是高效的。
)
[1]LENATDB.CYC:alarge-scaleinvestmentinknowledgeinfrastructure[J].CommunicationsoftheACM, 1995, 38(11): 33-38.
[2]ANDERSONAR,PIROLLIPL.Spreadofactivation[J].JournalofExperimentalPsychology:Learning,Memory,andCognition, 1984, 10(4): 791-798.
[3]COLLINSAM,LOFTUSEF.Aspreading-activationtheoryofsemanticprocessing[J].PsychologicalReview, 1975, 82(6): 407-428.
[4]FUX,WEIH.Problemsolvingbysoakingtheconceptnetwork[J].ComputerScienceandInformationSystems, 2011, 8(3): 761-778.
[5]YOLANDAB.Exploringsynergiesbetweencontent-basedfilteringandspreadingactivationtechniquesinknowledge-basedrecommendersystems[J].InformationSciences, 2011, 181(21): 4823-4846.
[6]DIFFIEW,HELLMANM.Newdirectionsincryptography[J].IEEETransactionsonInformationTheory, 1976, 22(6): 644-654.
[7]THOMPSONE.MD5collisionsandtheimpactoncomputerforensics[J].DigitalInvestigation, 2005, 2(1): 36-40.
[8]LIANGJ,LAIXJ.ImprovedcollisionattackonhashfunctionMD5 [J].JournalofComputerScienceandTechnology, 2007, 22(1): 79-87.
[9]KAVUTS.Resultsonrotation-symmetricS-boxes[J].InformationSciences, 2012, 201: 93-113.
[10]BORISSOVYL,LEEMH.Boundsonkeyappearanceequivocationforsubstitutionciphers[J].IEEETransactionsonInformationTheory, 2007, 53(6): 2294-2296.
[11]WANGC,ZHANGHG,LIUL.EvolutionarycryptographytheorybasedgeneratingmethodforasecureKoblitzellipticcurveanditsimprovementbyahiddenMarkovmodels[J].ScienceChinaInformationSciences, 2012, 55(4): 911-920.
[12]KUOW.Securemodulusdatahidingscheme[J].KSIITransactionsonInternetandInformationSystems, 2013, 7(3): 600-612.
[13]QINC,CHANGCC,HSUTJ.Effectivefragilewatermarkingforimageauthenticationwithhigh-qualityrecoverycapability[J].KSIITransactionsonInternetandInformationSystems, 2013, 7(11): 2941-2956.
[14]FENGB,WANGZ,WANGD,etal.Anovel,reversible,ChinesetextinformationhidingschemebasedonlookaliketraditionalandsimplifiedChinesecharacters[J].KSIITransactionsonInternetandInformationSystems, 2014, 8(1): 269-281.
[15]SHANNONCE.Communicationtheoryofsecrecysystems[J].BellSystemTechnicalJournal, 1949, 28(4): 656-715.
FU Xixu, born in 1981, Ph.D., engineer.His research interests include artificial intelligence, knowledge system, cognitive computing, data mining.
GONG Xizhang, born in 1963, M.S., senior engineer.His research interests include information management and system.
Spreading activation method to encrypt data with images as references
FU Xixu, GONG Xizhang*
(InstituteofInformationandEducationTechnology,ShanghaiOceanUniversity,Shanghai201306,China)
Complexity, non-linearity and correctness are important features in cryptography.Human beings’s knowledge processing just has these features.Spreading activation theory describes how human beings deal with complex and non-linear knowledge correctly.Inspired by the spreading activation theory, a new method for encoding data with references to a bitmap was advanced.In this method, a symbol was represented with a deviation range and a relative position of a contour.Encrypted data was generated by using a spreading activation process.The same symbol can be represented in different code, and the same code can represent different symbols too.This method can ensure the complexity of deciphering by implementing the spreading activation model to create a mass potential searching space.On the other hand, it can also reduce the relativity between the cipher text and the plaintext.
spreading activation; cryptography; dynamic encryption; referential encryption
2016- 08- 22;
2016- 09- 07。
付熙徐(1981—),男,江西抚州人,工程师,博士,CCF会员,主要研究方向:人工智能、知识系统、认知计算、数据挖掘;龚希章(1963—),男,上海人,高级工程师,硕士,主要研究方向:信息管理与信息系统。
1001- 9081(2017)02- 0408- 04
10.11772/j.issn.1001- 9081.2017.02.0408
TP309.7
A
