基于同义词词林的平滑BLEU研究
2017-04-17于俊婷何宏业刘伍颖易绵竹
于俊婷, 何宏业, 刘伍颖, 易绵竹
(1.洛阳外国语学院 语言工程系 河南 洛阳 471003; 2.广东外语外贸大学 语言工程与计算实验室 广东 广州 510420)
基于同义词词林的平滑BLEU研究
于俊婷1, 何宏业1, 刘伍颖2, 易绵竹1
(1.洛阳外国语学院 语言工程系 河南 洛阳 471003; 2.广东外语外贸大学 语言工程与计算实验室 广东 广州 510420)
基于同义词词林提出一种语义空间变换算法,并将其应用于平滑BLEU中,提出一种改进的基于同义词词林的BLEUS评测方法,该方法针对候选译文中短译文或英文缩写可能导致一元语法零匹配的情况,对传统BLEUS的n元语法均进行了平滑处理,并且以参考译文的一元语法为标准,对候选译文进行语义空间变换.在俄汉双语句子数据集上对谷歌、百度、必应、有道在线翻译系统的俄汉翻译输出译文进行评测,改进方法与传统BLEUS的评测结果一致;基于同义词词林的BLEUS提升传统BLEUS的评测性能,使得百度的NBLEUS值提高了3.99%,谷歌提高了7.66%,必应提高了11.15%,有道提高了4.65%.与此同时,验证了基于同一类型评测方法的纵向比较方法的有效性.
同义词词林; BLEUS; BLEUS-syn; 评测
0 引言
机器翻译系统评测通常指对给定翻译系统生成的译文质量进行量化评测.国家语言文字工作委员会发布的《语言文字规范》中规定[1]:机器翻译系统的语言文字评测主要有人工评测和自动评测两类.其中人工评测主要是由语言专家主观地对系统输出译文的忠实度和流利度进行打分,主观性强,受外界因素影响比较大,代价高昂.研究者更倾向于使用自动评测对系统译文进行量化评测.
自动评测方法一般可以分为3类:基于语言学检测点的方法[2]、基于字符串相似度的方法[3]、基于机器学习的方法.基于字符串相似度的方法成为目前单一指标评测中应用最为广泛的评测方法,其中应用最为成熟、广泛的是2002年Papineni等人提出的BLEU;随后针对BLEU无法应用于句子级评测、不考虑召回率等问题,研究者们进行了大量的改进研究:最为著名的且应用较为广泛的是文献[4]提出的平滑BLEU(BLEUS)以及ROUGE-N系列[5]评测方法,还有基于词对齐的METEOR[6]评测方法.
面向汉语可供选择的语义资源有很多,同义词词林作为一部汉语语义类词典,具有明确的同义词集合,更适合同义词匹配的应用.语言表达具有多样性,信息处理的难度增加,将同义词词林应用于自动评测方法,可以改善其性能.本文提出一种基于同义词词林[7]的语义空间变换算法,并将其应用于平滑BLEU方法,在BLEUS平滑技术[8]中除了精确词形匹配,还加入基于同义词词林的同义词匹配,可以弥补系统只有一个参考译文的缺陷,增加候选译文和参考译文相似度,以此提高BLEUS评测性能.
1 基于同义词词林的BLEUS评测指标
1.1 平滑BLEU介绍
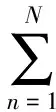
2004年,Lin等[4]首次提出平滑BLEU(BLEUS),即当n>1时,对匹配的n元语法个数和总的n元语法个数分别加1,以保证候选译文不足n个词时依然可以得到正的BLEUS值.
但是当汉语译文经过分词之后对候选译文和参考译文进行词语级n元语法匹配时,由于中文分词器分词粒度、译文表达的缺省等原因,有可能会出现整个译文较短被分成一个词语或者源语言句子被翻译成英文缩略语的情况;再者为保持n元语法准确率的一致性,对所有的n元语法均采用加1平滑处理.
1.2 基于同义词词林的语义空间变换算法
机器翻译实际上就是对“同一语义”的不同编码[9],其核心内容是相同的,只是形式不同.由于语言表达的多样化,信息处理的难度逐渐增加,不同系统对于相同内容的翻译会呈现出不同的表现方式,语义分析和同义词替换对于机器翻译评测有着很重要的作用.同义词词林具有明确的同义词集合,能够很好地提高候选译文和参考译文的匹配程度,而且不会影响译文的可读性.故本文提出一种基于同义词词林的语义空间变换(semantic space transformation, SST)算法,对BLEUS进行改进优化.
1.2.1 同义词词林简介
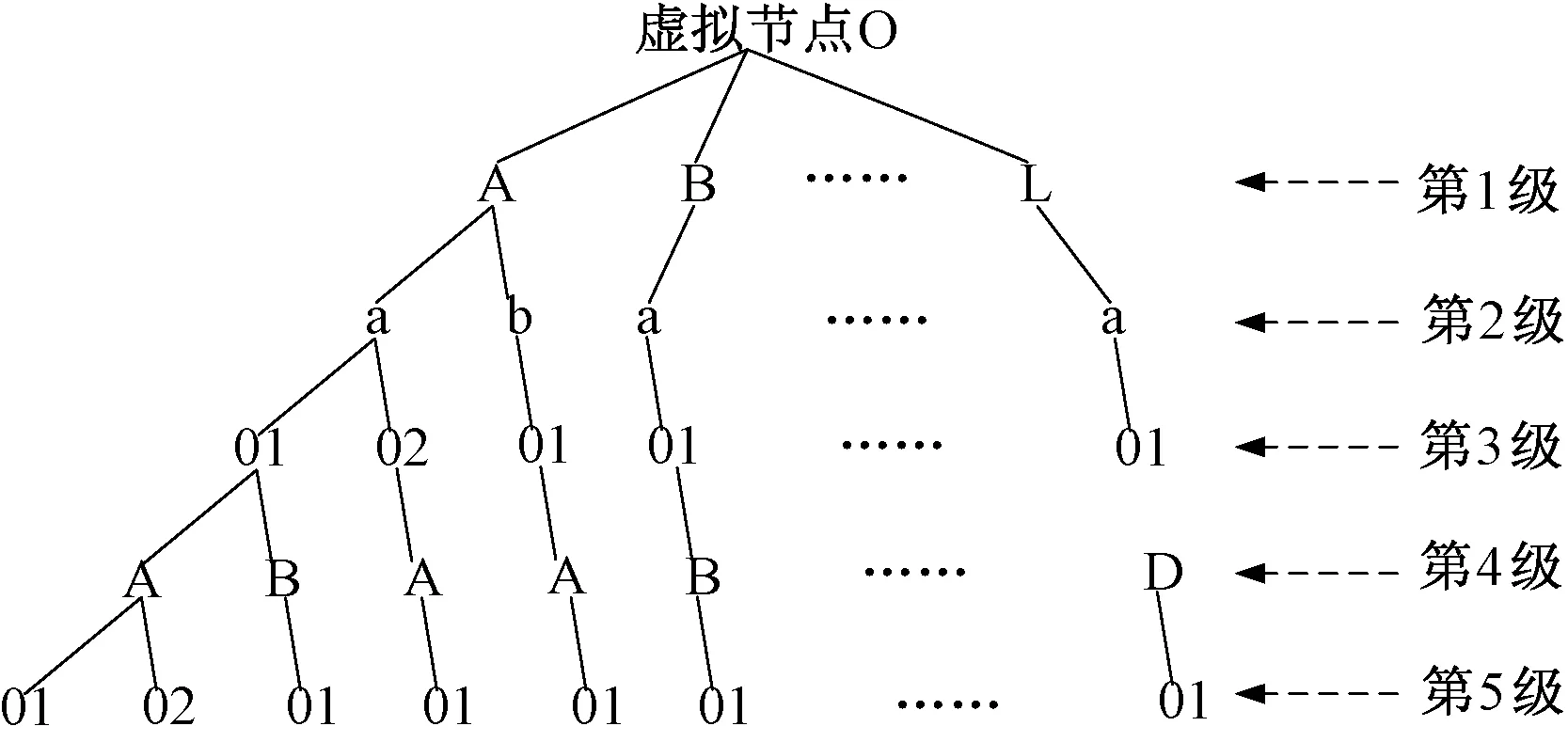
图1 同义词词林树状层次体系图Fig.1 Cilin tree hierarchy
同义词词林是由梅家驹等学者编纂的一部对汉语词汇按语义全面分类的义类词典,最终词表包含77 343条词语[10],其语义分类图如图1所示.其中包括:词语的同义词、相关词和独立词[11].义项是描写词义的最小单位,所有义项构成一个大的树状层次体系,并采用一个虚拟节点O将所有树连接起来,只有叶节点是相同或相似或独立的词的集合.
1.2.2 同义词词林编码体系改进
为了便于计算,本文采用6级编码体系,对每一级采用二位十进制数编码,其中英文字母按照顺序编码,比如“A”或者“a”用01代替,“B”或者“b”用02代替,依次顺延;最后两位我们称为“标记位”,为新的编码体系中的第6级,“=”用01代替,“#”用02代替,“@”用03代替.新的编码体系采用十二位十进制数编码,从根节点开始向右一直追溯到叶节点,如表1所示,则“Da15B02#”的新编码为“040115020202”.

表1 改进的《同义词词林》二位数编码体系表
1.2.3 基于同义词词林的语义空间变换算法
语义空间变换(SST)算法主要是基于参考译文的一元语法进行的,对候选译文和参考译文进行匹配构成映射时,首先进行精确词形匹配,然后进行基于同义词词林的同义词匹配,二者顺序无重叠地进行.语义空间变换算法主要包含两个main函数:isSynonym和sst,其伪代码如图2所示.

图2 SST算法伪代码
当输入词语content1和content2时,isSynonym函数启动:1) 假如两个词语均不在同义词词林中,但是词形相同,则返回index=1;2) 利用getCodesByContent函数从“同义词词林.xls”文件中分别提取content1和content2的十二位编码集合code1和code2,因为同义词词林中每个词语可能有多个义项,故每个词语的编码集合可能对应有多个编码,假如两编码集合中有相同的编码,则返回index=1.index=1表示这两个词语content1和content2词形相同或者是同义词,可以互相匹配.
当sst函数启动时,以参考译文中的一元语法为标准,对候选译文实施语义空间变换:1) 将分词后的参考译文ref取一元语法后存入动态数组al1,进行去重后存入数组arr[],分词后的候选译文candi取一元语法后存入动态数组al2;2) 数组arr[]中的元素content与动态数组al2中的一元组content2进行isSynonym函数求值为1时,利用arr[]数组中的该元素content替换al2中对应的一元组content2,并将进行语义空间变换后的候选译文重新存入新的动态数组并转化为字符串型动态数组seg22以备后续使用;3) 其中CHIsegment函数为分词函数,将译文进行分词,ngram函数将分词后的译文取其一元语法.
语义空间变换算法,以参考译文一元语法为标准,基于同义词词林对候选译文中的一元语法进行同义词替换,在不破坏机器翻译系统输出候选译文可读性的前提下,增加了译文之间的相似度,提高了自动评测方法的整体性能.
1.3 基于同义词词林的BLEUS
汉语语言文化丰富多样,同一意义可以有不同的表达形式,尤其是在自动评测机器翻译系统译文质量时,基于同义词词林的语义空间变换算法的引入,能有效提高自动评测指标的匹配性能.本节提出一种基于同义词词林的BLEUS自动评测指标.
给定一个参考译文r和一个候选译文c,基于参考译文中的一元语法进行语义空间变换,假设候选译文和参考译文相匹配的一元语法数目为m1.1) 精确词形匹配:以参考译文为标准,在进行候选译文中的一元语法Wc与参考译文中的一元语法Wr匹配过程中,如果词形完全相同,则可以匹配成功,m1加1;2) 同义词匹配:如果词形不同,则进行同义词匹配,如果Wc和Wr是同义词,则m1加1,同时将Wc替换为Wr;比如“部队”和“军队”基于同义词词林是同义词可以互相匹配;3) 精确词形匹配和同义词匹配按照顺序且无重叠地进行.基于一元语法的两种匹配模式,将一元语法替换后的候选译文与原始的参考译文进行2~4元语法匹配并求得对应的准确率值,如此便增加了n元语法的匹配概率,从而改善了n元语法的准确率.对各阶n元语法的准确率进行平滑,求得最终的NBLEU值,由此基于同义词词林的BLEUS算法即可实现.
基于同义词词林的BLEUS算法对传统的BLEU进行了平滑处理,使得句子级评测成为可能;而且对一元语法也进行了平滑处理,很好地应对了输出译文较短甚至为一个词语以及英文缩写词语的出现而导致一元语法零匹配的情况,使得句子级评测分数更加稳定可靠;同时以参考译文为标准引入了基于同义词词林的语义空间变换算法,减少了因为汉语语义表达的多样性造成的匹配率降低的情况,提高了候选译文和参考译文的匹配效率.
2 评测指标性能分析
2.1 实验语料及环境
实验中,双语句子数据集采用基于俄汉双语新闻的句子对齐语料库[12],其中包含52 892个俄汉双语对齐句对,采用分层采样的方式将这些俄汉句对分为训练集和测试集以备后续实验使用.其中测试集包括1 057个句对,这些句子按照俄语句子长度进行升序排序,并且已经被去重处理,形式上各不相同.基于网络上主流的俄汉在线翻译系统谷歌、百度、必应、有道对俄语句子进行俄汉翻译,得到4个在线翻译系统的汉语机器译文.其中语料库中人工对齐的汉语句子作为人工参考译文.
实验均在具有8.00GB的内存和CPU为Intel(R) Core(TM) i7-6700HQ的计算机上运行.
2.2 实验结果
首先利用测试集对传统BLEUS进行实验,其中按照俄语句子长度对平行语料进行了升序排序.通过对谷歌、百度、必应、有道4个在线系统的输出候选译文与人工参考译文采用传统BLEUS指标进行评测,得到NBLEUS值,由于BLEU进行了平滑技术的处理,其句子级评测分数有效,且整个实验测试集上4个系统的NBLEUS平均值如图3所示.然后利用同一组测试语料,同样的方法采用基于同义词词林的BLEUS对4个在线翻译系统输出译文的质量进行评测,得到4个系统的NBLEUS平均值(NBLEUS-syn)如图3所示.
由图3中可以看到,横坐标代表BLEU的几种平滑方法,纵坐标为每种平滑方法在测试集上的平均NBLEUS值.1) 4个在线翻译系统的整体变化趋势是相似的,排序是一致的,百度系统的俄汉在线翻译性能最优,谷歌系统性能比百度略差,优于有道系统的性能,必应系统的俄汉在线翻译性能最差.2) 基于同义词词林的语义空间变换的引入,使得baseline的BLEUS性能得以改善,对于同一个系统而言,基于同义词词林的BLEUS性能比传统BLEUS有所提升,百度系统的NBLEUS-syn比NBLEUS提升了3.99%,谷歌系统提升了7.66%,必应系统性能提升了11.15%,有道系统提升了4.65%.3) 应用语义空间变换算法之后,谷歌系统和必应系统的性能提升幅度较大,百度和有道系统的性能改善幅度较小,主要原因在于谷歌系统和必应系统的输出候选译文在语言表达及习惯用语方面与人工参考译文的表达差异较大,当采用以参考译文为标准的语义空间变换算法后,谷歌系统和必应系统的译文用词与参考译文相同,故性能提升较多;而百度系统和有道系统的译文语言表达方面与参考译文差异较小,故性能提升较小.4) 对于基于同一种评测指标NBLEUS的不同平滑算法采用纵向比较的方式进行实验,即通过NBLEUS均值衡量,更加方便明确,有利于评测指标性能参数的调整与优化,大大节约能源与时间,提高时效性.由此分析,语义空间变换算法可以明显改善传统BLEUS的性能,提升NBLEUS值,既能很好地避免短译文和英文缩略语导致出现零准确率的问题,又不会影响候选译文的可读性.
在对传统BLEUS和基于同义词词林的BLEUS进行性能比较时,上文采用NBLEUS均值来进行衡量,对基于同一类型的评测方法进行纵向比较;但是最传统的方法是采用人工的方法计算自动评分与人工流利度和忠实度分数的相关系数,系数越高,说明评测指标性能越好.本文采用皮尔森相关系数rxy来计算自动评测指标与人工评测得分的相关性,从而验证纵向比较的可行性.对于包含变量自动打分x和人工打分y的测试集上的数据点{(xi,yi)},自动打分x和人工打分y之间的皮尔森相关系数为[13]:
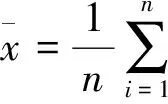
4个俄汉在线翻译系统采用传统BLEUS和基于同义词词林的BLEUS评测方法的自动评分与人工的忠实度(ade)和流利度(flu)分数的的相关系数如图4所示.
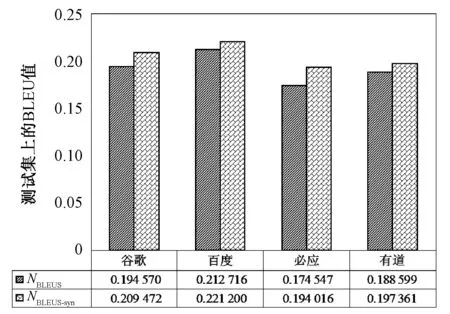
图3 4个在线系统的俄汉翻译BLEUS评测结果Fig.3 BLEUS evaluation results of 4 systems
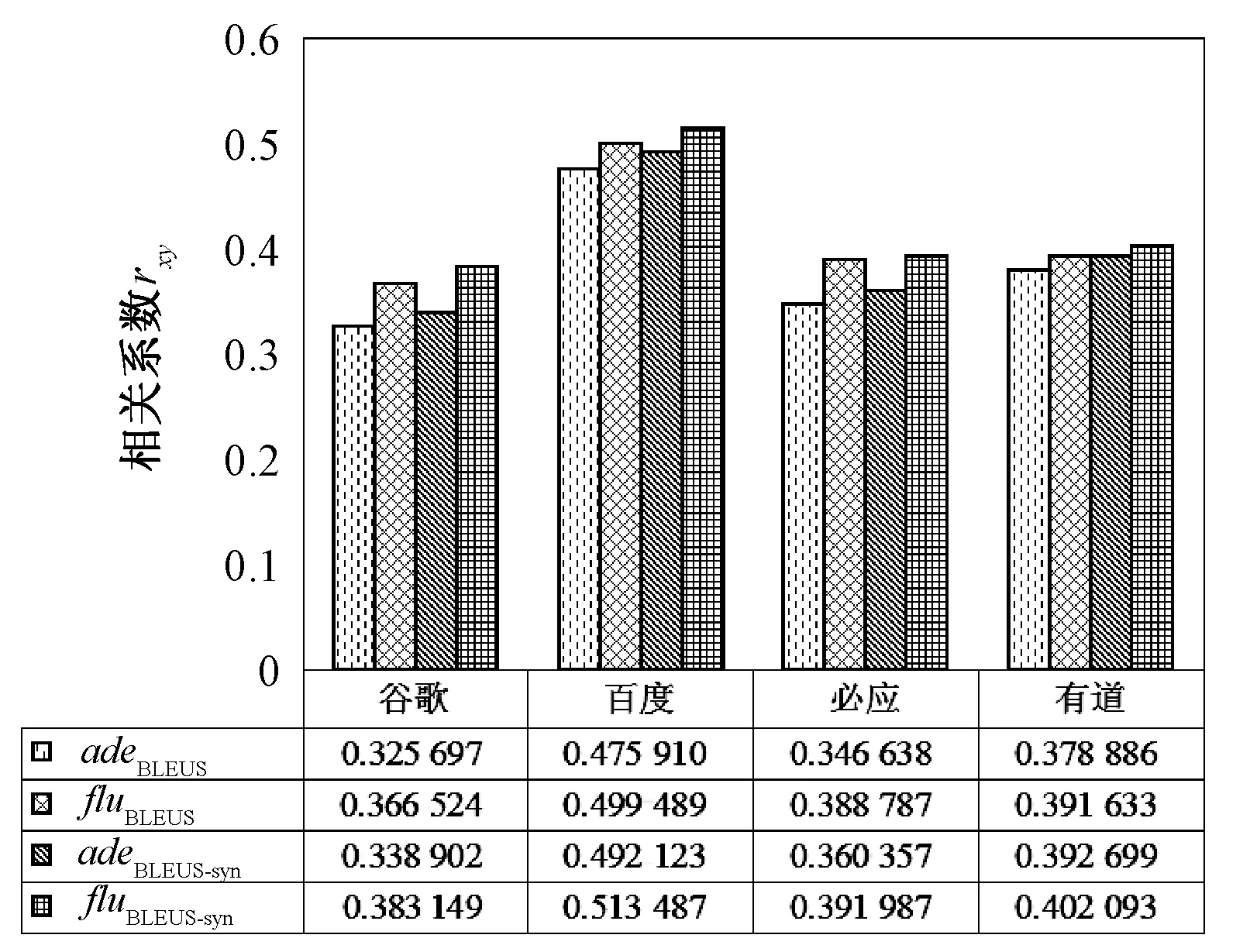
图4 系统采用不同评测方法的忠实度(ade)和流利度(flu)的相关系数
由图4可以分析得到,对于传统BLEUS评测方法,加入基于同义词词林的语义空间变换之后,忠实度和流利度的相关系数均有所提高,表明使用精确词形匹配和同义词匹配顺序、无重叠匹配比只使用精确词形匹配,在提高译文忠实度的同时,没有影响译文的流利度,而且译文依然可读.上文纵向比较的实验结果与人工评价的结果一致,因此,基于同一类型的不同参数设置的评测方法通过纵向比较评判性能的方法和人工评价结果是一致的,说明纵向比较是有效的,能够方便明确地对基于同一类型的不同评测方法性能进行比较,有利于评测指标性能参数的调整与优化,大大节约能源与时间,提高时效性.
同样,此方法可以应用到离线的开源统计机器翻译系统中进行研究,在语料规模不受限的情况下,可以很大程度地提升机器翻译系统的性能.基于同义词词林的BLEUS评测方法能够大幅度提升传统BLEUS的评测性能,在评测目标语言为汉语的机器翻译系统方面可以发挥很好的作用.
3 结束语
本文主要基于同义词词林提出了一种改进的平滑BLEU评测方法,针对候选译文中短译文或英文缩写可能导致一元语法零匹配的情况,对传统BLEUS的n元语法均进行了平滑处理,并且对一元语法匹配时引入同义词匹配,而后对替换后的词语求2~4元语法的准确率.该评测方法与传统BLEUS评测结果一致,且能够大幅度提升传统BLEUS的评测性能,在评测目标语言为汉语的机器翻译系统方面可以发挥很好的作用.目前只是进行了浅层次的语义空间变换,后期工作中还会对同类词、引入知网以及基于同义词词林的ROUGE、METEOR等其他评测指标的改进进行更加细致的研究.
[1] 中华人民共和国教育部国家语言文字工作委员会.机器翻译系统评测规范:GF-2006[S].2006.
[2] YU S.Automatic evaluation of output quality for machine translation systems[J].Machine translation,1993,8(1):117-126.
[3] PAPINEN K,ROUKOS S,WARD T,et al.BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics.Philadelphia,2002:311-318.
[4] LIN C Y,OCH F J.Orange: method for evaluating automatic evaluation metrics for machine translation [C]// Proceedings of the International Committee on Computational Linguistics 2004.Barcelona,2004.
[5] LIN C Y.Rouge: package for automatic evaluation of summaries [C]// Proceedings of Workshop on Text Summarization Branches out, Post-conference Workshop of Association for Computational Linguistics 2004.Barcelona,2004.
[6] BANERJEE S,LAVIE A.Meteor: an automatic metric for MT evaluation with improved correlation with human judgments [C]// ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for MT and/or Summarization.Michigan,2005.
[7] 梅家驹,竺一鸣,高蕴琦,等.同义词词林[M].2版.上海:上海辞书出版社,1996.
[8] CHEN B,CHERRY C.A systematic comparison of smoothing techniques for sentence-level BLEU [C]// Proceedings of the 9th Workshop on Statistical Machine Translation on Association for Computational Linguistics 2014.Baltimore,2014:362-367.
[9] 张钹.自然语言处理的计算模型[J].中文信息学报,2007,21(3):3-7.
[10]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报(信息科学版),2010,28(6):602-608.
[11]徐建民,刘清江.基于同义词关系的局部查询扩展[J].郑州大学学报(理学版),2010,42(1):45-48.
[12]DU W,LIU W,YU J,et al.Russian-Chinese sentence-level aligned news corpus [C]// Proceedings of the 18th Annual Conference of the European Association for Machine Translation.Antalya,2015:213.
[13]姚建民,周明,赵铁军,等.基于句子相似度的机器翻译评价方法及其有效性分析[J].计算机研究与发展,2004,41(7):1258-1265.
(责任编辑:王海科)
Research on Smoothed BLEU Based on Thesaurus of Cilin
YU Junting1, HE Hongye1, LIU Wuying2, YI Mianzhu1
(1.DepartmentofLanguageEngineering,LuoyangUniversityofForeignLanguages,Luoyang471003,China; 2.LaboratoryofLanguageEngineeringandComputing,GuangdongUniversityofForeignStudies,Guangzhou510420,China)
A new algorithm based on thesaurus of Cilin was put forward with the name statistical space transformation (SST). And then it was applied into traditional smoothed BLEU(BLEUS).And an improved smoothed BLEU was got based on thesaurus of Cilin. As many cases of short translations or English abbreviations in candidate translations might cause unigram without matches, this new evaluation metric smoothed the traditional BLEUSn-gram and made the candidate translation unigram “synonymy match” based on thesaurus of Cilin,and took the reference translations unigrams as standard.Exact match and synonymy match were applied in unigram matching. Experiments were performed in Russian and Chinese bilingual sentence data set,and it evaluated the output translations of online translation system such as Google, Baidu, Bing and Youdao. The evaluation results of Cilin-based BLEUS and traditional BLEUS were proved to be consistent. Cilin-based BLEUS could greatly enhance the traditional BLEUS evaluation performance.NBLEUSvalue of the Baidu improveed 3.99 percent, Google improved 7.66 percent, Bing improved 11.15 percent, and Youdao improved 4.65 percent.Experiments were performed on the longitudinal comparisons to evaluate the metrics with different parameter settings based on the same measurement. And the results were consistent with the results of the human evaluation.
thesaurus of Cilin; BLEUS; BLEUS-syn; evaluation
2016-11-10
国家语言文字工作委员会重点项目(ZDI135-26);广东省高校特色创新项目(2015KTSCX035).
于俊婷(1984—),女,河北衡水人,博士,主要从事机器翻译评测研究,E-mail:314201559@qq.com;通讯作者:刘伍颖(1980—),男,江西九江人,副研究员,主要从事计算语言学和自然语言处理研究,E-mail:wyliu@gdufs.edu.cn.
TP391.1
A
1671-6841(2017)02-0054-06
10.13705/j.issn.1671-6841.2016307
