基于语境情感消岐的评论倾向性分析
2017-04-17蔡肖红刘培玉王智昊
蔡肖红, 刘培玉, 王智昊
(1.山东师范大学 信息科学与工程学院 山东 济南 250014; 2.山东省分布式计算机软件新技术重点实验室 山东 济南 250014)
基于语境情感消岐的评论倾向性分析
蔡肖红1,2, 刘培玉1,2, 王智昊1,2
(1.山东师范大学 信息科学与工程学院 山东 济南 250014; 2.山东省分布式计算机软件新技术重点实验室 山东 济南 250014)
研究评论倾向性分析中情感词的动态极性变化问题.用Apriori算法在语境基础上挖掘情感歧义词语搭配,构建出(情感对象,情感词,情感倾向性)三元组形式的情感歧义词搭配词典,利用条件随机场模型(CRFs)序列标注方法从评论文本中抽取出情感要素,在构建的情感歧义词搭配词典基础上对评论文本进行了细粒度情感倾向性分析.在手机和电脑两个领域的评论语料集上进行多组实验,与传统方法的对比实验表明了方法的可行性,较为明显地提高了情感倾向性分析的准确率.
情感歧义词; CRFs; 语境; 细粒度; 情感要素
0 引言
情感分析主要的研究对象是互联网上的海量文本信息,主要任务包括网络文本的情感极性判断、评价对象抽取和意见摘要[1]等.目前研究更倾向于细粒度级别的情感分析,如词语或短语级的评价关系的识别和分析.细粒度的情感分析也称为基于特征的情感分析,旨在从评论文本中抽取情感要素,为一些实际应用提供必要的细节信息[2].在评价对象和评价词抽取及情感倾向性分析方面已有不少学者进行相关研究.文献[3]利用关联规则挖掘的方法依据词频信息抽取名词和名词短语作为产品属性,并抽取产品属性临近的形容词作为观点,扩展低频属性词,再通过剪枝处理移除噪声,得到最终属性集合,该方法由于规则限定导致召回率低.文献[4]首次将基于条件随机场的判别式学习模型运用于评论文本的细粒度情感分析,避免了特征之间的条件独立性假设问题.王素格等利用依存句法分析结果分别建立了名词、动词及形容词的组块规则,设计评价对象与评价词的搭配算法[5].徐冰等人将浅层句法信息和启发式位置信息引入到条件随机场模型中,在不增加领域情感词典的情况下,有效地提高了系统的准确率[6].戴敏等人引入句法分析来丰富句法特征,使用基于条件随机场模型的监督学习方法实现对英文的评价对象抽取[7].
此外,研究者们也尝试了利用领域本体来解决细粒度的情感分析问题.姚天昉等人利用领域本体抽取汽车评论中的实体和特征,利用极性词词典识别用户评论意见并判断它们的褒贬性以及强度[8].郭冲等人针对细粒度的意见要素抽取和情感判定问题,定义了一种情感本体树结构,并通过评价搭配抽取算法、评价搭配倾向预测算法和特征聚合算法自动构建领域情感本体树[2].刘丽珍等基于产品特征之间的语义关系,设计词性模式匹配方法提取特征词和情感词的固定搭配,并采用评论句的极性标签结合否定词典,逆向推测搭配组合的情感极性,构建领域情感本体,进一步设计本体节点匹配规则进行情感分析[9].
1 情感歧义词搭配词典的构建
1.1 情感歧义词定义
情感倾向性分析中主要基于情感词的极性与否定转折等情感影响因子计算情感得分,本文从情感角度出发,挖掘情感歧义词在不同语境中的动态情感倾向性.根据语境信息可将情感词划分为两种:第一种是上下文无关型,具有明显的褒贬倾向,如喜欢、讨厌等;第二种是上下文相关型,如高、大、长、快等.第一种情感词依据基础情感词典可得到确定的情感极性,然而第二种则需要结合情感词所搭配的上下文语境信息,根据不同词语的搭配动态地选择情感极性,本文定义此类具有动态情感极性的情感词为情感歧义词.情感歧义词具有动态情感极性(dynamic polarity),即在不同上下文语境中修饰不同产品属性或搭配某些词语时表现出不同的情感极性,例如:
comment1:这款新手机的配置很高,音质是亮点,就是价格太高了.
comment2:风扇有声音,屏幕有亮点…
对比两条评论可看出,comment1中有评论短语“配置、高”和“价格、高”,情感词“高”在修饰产品属性“配置”时是正向的情感,而在修饰产品属性“价格”时是负向的情感;comment2中有评论短语“风扇、声音”,“声音”作为情感词,和评价对象“风扇”搭配时表现出负向的情感倾向;comment2中评论短语“屏幕、亮点”,“亮点”作为情感词,和评价对象“屏幕”搭配时表现出负向的情感倾向,而在comment1中评论短语(音质,亮点)中“亮点”作为情感词,和评价对象“音质”搭配时表现出正向的情感倾向.情感歧义词的动态情感极性确定依赖于上下文语境信息,根据所搭配的词语不同,表现出不同的情感倾向性.
1.2 搭配词典的构建
本文采用Apriori算法挖掘文本中的情感歧义词语搭配集,词语的集合看成是两个item,词语搭配的集合看成是transaction,找出两个item中的元素在transaction上的并发关系.设I={i1,i2,…,im}是一个项目集合代表文本输入,T={t1,t2,…,tn)是一个数据库事务(transaction),其中每个事务ti是一个项目集合.从不同语境的词语搭配方面选取情感歧义种子词,如“亮点、低、声音、大、小、快、慢、效率、水平、看法、脾气、道德、问题、高…”,依据情感歧义词大多是多义词在不同语境表现动态情感极性的,借助HowNet和哈尔滨工业大学的同义词词林对情感歧义词进行扩展,扩充多义词和种子词典的同义词.给出搭配集和频繁集[10],其中X,Y是item中两个元素,最小支持度为α,最小置信度为β.本文针对评论短文本特点,对语料集分词后,以构建的情感歧义词种子词典为中心词,取前后6个词与种子词构成一个item,采用关联规则挖掘方法,在transaction中先发现满足α的搭配集,然后在搭配集中识别满足β的频繁集,α和β的值设定太小,剪枝不明显,设置太大,导致搭配集噪音过大,本文实验针对(αi,βi)取结果最好的一对参数α=0.01%,β=0.01%.
通过点互信息PMI(pointwise mutual information)来进一步挖掘词语间搭配关系强度.用公式(1)计算词语word1与word2的搭配关系强度,其中,P(word1)与P(word2)表示词语word1与word2的出现概率,PMI(word1,word2)表示词语word1与word2共同出现的概率,P(word)用公式(2)计算词语word的tfidf值替换.PMI的值越大表示词语word1与word2间的搭配关系越强.设定一个阈值δ,过滤掉词语互信息满足PMI(word1,word2)≤δ的弱关联搭配对.
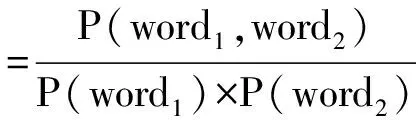
(1)
(2)
公式(2)中,W(t,d)为词语t在句子d中的权重,tf(t,d)表示词语t在句子d中出现频率,N为训练语料句子总数,ni表示训练语料出现词语t的句子数度,α取0.01,分母为归一化因子.经过PMI过滤后构成情感歧义词候选搭配集,利用情感词典标注搭配集中评价词语的情感极性,进而构建成情感歧义词搭配词典,词条存储形式:<情感对象,情感词,情感倾向性>.在情感倾向性分析时,情感歧义词动态极性值的确定需同时满足词语配对,解决同一情感词修饰不同情感属性时不同情感倾向的问题.
2 细粒度情感分析
2.1 条件随机场模型(CRFs)
CRFs由 Lafferty 等人[11]在 2001 年的ICML会议(international conference on machine learning) 上提出,之后广泛用于自然语言处理领域,特别是在分词、词性标注、命名实体识别等任务中表现出优良性能.CRFs是一种序列标注模型,在序列标注任务中,X={x1,x2,…,xn}为观察序列,如中文分词中对应字序列及其他一些特征.Y={y1,y2,…,yn}为标记序列,在中文分词中对应位置角色标记序列.在命名实体识别任务中,X可以是一段文本,而Y则是相对应的类别标记序列.条件随机场使用一种概率图模型,具有表达长距离依赖性和交叠性特征的能力,能够较好地解决分类偏置等问题,而且所有特征可以进行全局归一化,能够求得全局的最优解.评论语句可看成以字或词为基本单位的序列,对情感词和情感对象的抽取过程可看成一个序列标注的过程,基于CRFs能同步抽取情感词和情感对象.
2.2 情感要素抽取
需要标注的情感要素包括情感对象,情感词、情感修饰词中否定修饰词和程度级别修饰词在词性标注后,基于相应的否定词典和程度级别词典可判定得出.本文所选用的条件随机场模型工具是综合性能最好的CRF++.
2.2.1 抽取的特征
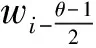
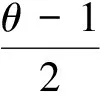
3) 情感歧义词典特征DIC:将本文构建的情感歧义搭配词典作为一项特征,可反应句中词与词之间的句法依赖关系,依赖特征包括词语间和词性直接的相互依赖.
2.2.2 构建标注集
为了实现对细粒度情感要素的有效识别,将标注集设置的相对简单来防止特征稀疏,我们将标注集设定为4种标记.给定输入序列W={wi},输出标注序列Y={yt},yt∈{FO,SO,ADV,P}.标注集如表1所示.

表1 标注集示例
2.3 倾向性分析
通过CRFs序列标注出情感要素后,对抽取出的情感要素表达的观点进行细粒度的分析,传统方法基于基础情感词典,基础情感词典有知网的Hownet、台湾大学的NTUSD、大连理工大学信息检索研究室的中文情感词汇本体库.本文添加了网络词汇词典、否定副词词典、程度副词词典和情感歧义词搭配词典进行特征级别的情感分析.网络词汇词典包括给力、稀饭等正向情感词以及和杯具、坑爹等负向情感词;否定副词词典包含对情感表达逆转的否定词47个;程度副词依据情感词的情感强烈强度由低到高分为Ⅰ类、Ⅱ类、Ⅲ类、Ⅳ类、Ⅴ类、Ⅵ类共6个等级,词典规模236个.
情感倾向计算算法的基本思想:利用情感词和影响情感的情感修饰词计算情感对象的情感.算法步骤如下:
1) 根据否定词ni的情感值Negi和程度副词di的情感值Modi,计算情感修饰词的情感影响因子Qadvi,公式如下:
式中,存在否定词时Negi取值-1,反之默认为1;Modi的值根据程度副词的情感强度等级依次取值为{-0.5,0.5,0.8,1.2,1.6,2.0}.
2) 结合情感词的极性Pi,计算情感要素组成的属性观点对的情感极性值Score(fti),
其中:F={ft1,ft2,…,fti,…,ftn};fti为评论语料中的产品属性;n为产品属性总数.
3) 计算产品属性的正向情感强度Sentiment(fti)+和负向情感强度Sentiment(fti)-,
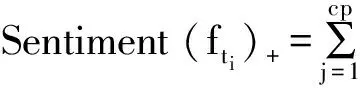
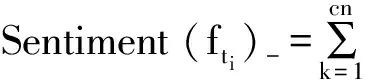
其中:cp和cn分别为产品属性fti组成的观点对情感倾向为正向和负向的语句数;wj与wk分别为正向和负向情感极性值的权重,主要依赖于产品属性观点对所在原评论的点赞数和用户等级;Score(ftj)+和Score(ftk)-分别为产品属性fti组成观点对的正向和负向情感极性值.至此得到各个产品属性对应的正负向情感强度值,情感倾向计算算法结束.
3 实验与分析
3.1 数据集预处理
在构建的细粒度情感分析系统中进行实验,采用数据采集模块编写的爬虫程序从京东商城上采集2016年的手机和电脑两个领域的评论数据,共采集手机评论60 681条,电脑评论41 561条,提取标签组成特征观点对存储.实验前针对本文研究内容对原始数据集进行预处理,处理过程包括原始语料集去重,过滤官方用户回复评论,用户的回复评论,只保留用户原始评论数据,过滤晒单等文本无关评论,过滤广告类虚假评论.中文分词采用NLPIR汉语分词系统,因分词准确率直接影响后续情感要素抽取和情感分析的准确性,本文将标签提取的属性词和评价词、领域相关特征词和未登录网络情感词加入用户词典,如性价比、蓝牙、坑爹、杯具、USB、蓝屏等共82个,提高分词准确率.采用评价标准是准确率、召回率以及F1值,分别记作Precision、Recall、F1.
3.2 不同上下文窗口长度下实验结果
词语之间的上下文关系影响CRFs模型对情感要素的识别,本文设置不同上下文窗口长度进行实验,结果如表2所示.当上下文窗口长度为7时,识别效果最佳,也即词语的上下文语境信息在词语前后3个词范围内,区别于长篇文本的语境范围,评论文本自身带有用户典型的口语化表达习惯,情感表达简单直接.本文后续实验均选用窗口长度为7的特征模板,避免窗口长度过大造成特征冗余和窗口长度过小造成上下文依赖不足.
3.3 训练语料规模的影响
本实验准备了5组手机领域的数据,依次增加训练集的大小,其余参数保持不变,训练集大小分别为200、500、1 000、2 000、4 000,实验结果如图1所示.由实验结果可知,数据集越大,训练语料中包含的情感要素模式也就越多,口语化表达也越多,情感要素的抽取效果越好.随着数据集增大一定程度后,准确率和召回率的增长速度减缓.

表2 上下文窗口长度实验结果
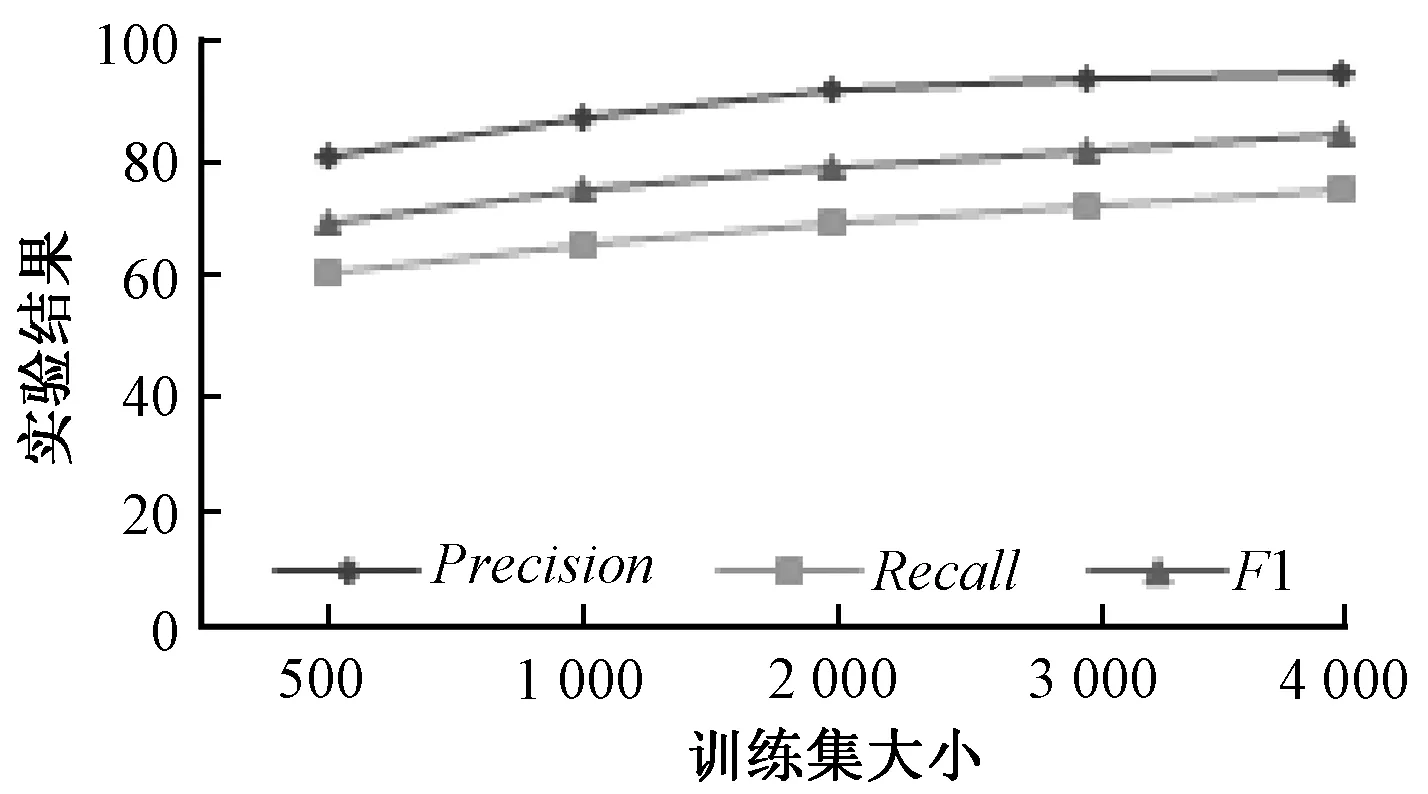
图1 训练集大小实验结果图Fig.1 Influence of training corpus size
3.4 情感要素抽取实验结果
情感要素抽取结果如表3所示,本实验分别在手机和电脑两个领域各4 000条训练集上进行实验.由实验结果可知,在手机和电脑两个领域的情感要素抽取准确率都比较高,召回率偏低,主要是因为评论语料中包含很多不规范的口语化表达,情感词语表达比较随意,相对正规表达的情感要素来说抽取困难;对比手机和电脑两个领域的实验结果可看出,手机领域的抽取结果优于电脑领域的抽取结果,这主要是因为电脑产品部件多,操作系统硬件软件等包含更多配件缩写变形的口语表达.

表3 情感要素抽取实验结果
3.5 传统方法对比
由表4实验结果看出,本文方法在添加情感歧义词搭配词典后,实验结果在准确率和召回率上都有一定提高,原因在于通过搭配词典能够根据上下文词语搭配,确定情感歧义词的动态情感极性;召回率仍然较低,主要原因是评论文本中一部分隐式评价对象的情感流失,还有一部分不包含情感词但包含表达情感倾向的句子,需要进行语义理解分析情感.

表4 与传统方法对比实验
4 结论
情感词动态极性的确定对文本倾向性分析具有很大意义,本文基于上下文词语搭配的语境信息角度,构建不同类型情感歧义词的搭配词典,在CRFs上监督训练标注情感要素,通过否定词和程度副词的依赖搭配计算情感影响因子,基于情感词典计算各产品属性对应的正负向情感强度值,完成特征级别的细粒度情感分析.通过实验结果分析可得本文方法是可行的,具有一定的研究意义.下一步将研究各不同领域产品评论专有领域词典和隐式评价对象抽取问题,提高细粒度情感分析的准确率.
[1] 赵妍妍,秦兵,刘挺. 文本情感分析[J].软件学报,2010,21(8):1834-1848.
[2] 郭冲,王振宇.面向细粒度意见挖掘的情感本体树及自动构建[J].中文信息学报,2013,27(5):75-83.
[3] HU M,LIU B.Mining and summarizing customer reviews [C] // Tenth Acm Sigkdd International Conference on Knowledge Discovery & Data Mining.New York,2004:168-177.
[4] QI L,CHEN L.A linear-chain CRF-based learning approach for web opinion mining[C].Proceedings of the 11th international conference on Web information systems engineering.Hong Kong,2010:128-141.
[5] 王素格,吴苏红.基于依存关系的旅游景点评论的特征-观点对抽取[J].中文信息学报,2012,26(3):116-121.
[6] 徐冰,赵铁军,王山雨,等.基于浅层句法特征的评价对象抽取研究[J].自动化学报,2011,37(10):1241-1247.
[7] 戴敏,王荣洋,李寿山,等.基于句法特征的评价对象抽取方法研究[J].中文信息学报,2014,28(4):92-97.
[8] 姚天昉,聂青阳,李建超,等.一个用于汉语汽车评论的意见挖掘系统[C]//中国中文信息学会二十五周年学术会议.北京,2006:260-281.
[9] 刘丽珍,赵新蕾,王函石.基于产品特征的领域情感本体构建[J].北京理工大学学报,2015,35(5):538-544.
[10]宋艳雪,张绍武,林鸿飞.基于语境歧义词的句子情感倾向性分析[J].中文信息学报,2012,26(3):38-43.
[11]LAFFERTY J,MCCALLUM A,PEREIRA F.Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]//Proceedings of the 18th International Conference on Machine Learning (ICML 2001).San Francisco,2001:282-289.
(责任编辑:王海科)
Sentiment Analysis of Comments Based on Contextual Emotional Disambiguation
CAI Xiaohong1,2, LIU Peiyu1,2, WANG Zhihao1,2
(1.SchoolofInformationScienceandEngineering,ShandongNormalUniversity,Ji′nan250014,China; 2.ShandongProvincialKeyLaboratoryforDistributedComputerSoftwareNovelTechnology,Ji′nan250014,China)
The problem of dynamic polarity change in sentiment analysis was studied. Apriori algorithm was used to expand the sentiment ambiguous words based on context, and constructed the sentiment ambiguous lexicon of triples (namely sentiment object, sentiment word, sentiment polarity). CRFs was used to extracted sentiment elements from comments. Finally, the completed fine-grained sentiment analysis based on the sentiment ambiguous lexicon was conducted. Multiple sets of experiments were performed on two domains of mobile phones and computers. Compared with the traditional method, the experimental results showed the feasibility of the proposed method and the improved accuracy of sentiment analysis.
sentiment ambiguous words; CRFs; context; fine-grained; sentiment elements
2016-10-28
国家自然科学基金项目(61373148);山东省科技发展计划项目(2014GGX101004).
蔡肖红(1989—),女,山东泰安人,硕士研究生,主要从事文本情感分析研究,E-mail:xhcai_nlp@126.com;通讯作者:刘培玉(1960—),男,山东潍坊人,教授,主要从事网络信息安全、自然语言处理研究,E-mail:lpynlp@163.com.
TP391.1
A
1671-6841(2017)02-0048-06
10.13705/j.issn.1671-6841.2016305
