基于多特征和Ranking SVM的微博新闻自动摘要研究
2017-04-17李孟爽昝红英贾会贞
李孟爽, 昝红英, 贾会贞
(郑州大学 信息工程学院 河南 郑州 450001)
基于多特征和Ranking SVM的微博新闻自动摘要研究
李孟爽, 昝红英, 贾会贞
(郑州大学 信息工程学院 河南 郑州 450001)
提出了面向微博应用的新闻文本自动摘要研究方法.利用互信息对新闻文本中词语和句子之间的语义特征进行计算,根据其关联度对句子进行主题划分,赋予主题句较高的权重,同时从文本中抽取多种组合特征,利用Ranking SVM对句子进行排序,从而得到自动摘要.在NLP&CC2015面向微博中文新闻自动摘要评测数据集上进行对比实验,取得了良好效果,证明该方法的有效性.
互信息; 语义特征; 主题句; Ranking SVM; 新闻文本自动摘要
0 引言
文献[1]显示,截至2015年7月,中国网民微博用户规模达2.04亿,手机微博用户规模达1.62亿.当社会媒体用户需通过这个平台转发自己喜欢的新闻时,微博允许用户发布的文本长度一般不能超过140字,用户发布该新闻的简要内容,然后附上整条新闻的URL链接.这样在方便发布者的同时也节省他人时间.因此,针对微博新闻文本的自动摘要研究具有深远的意义.本文提出了基于多特征和Ranking SVM的自动摘要方法,具体过程为:
1) 对原始文本进行预处理,除去不会作为摘要句的疑问句和否定句.
2) 抽取文本的词频、句子位置、与标题相似度、指示性词语及句子长度等统计特征.
3) 利用互信息抽取文本的语义特征,对其进行主题划分,赋予主题句较高的权重.
4) 综合文本的统计特征和语义特征,利用训练数据训练Ranking SVM模型,然后用得到的模型对句子进行排序.
5) 选出得分最高的句子加入摘要句,如果所选句子与摘要句相似则移除,直至摘要句长度140字停止.
1 相关工作
自动摘要是指自动地从原始文章中提取一个简短的能够全面反映原文内容的摘要.自动摘要分两种类型:一种是基于抽取的摘要,即从原始文章中抽取一些具有代表性的句子作为摘要句;另一种是基于篇章理解的摘要,即先理解原始文章内容,再通过自然语言生成来产生摘要.
1.1 基于抽取的摘要
基于抽取的自动摘要是根据句子的各种特征计算句子的总权重,然后根据句子的总权重给句子排序,选取排序靠前的句子作为摘要句.文献[2]提出一种基于高频词给句子打分得到摘要句.文献[3]提出把句子位置和线索词等特征应用到自动摘要研究中.文献[4]综合使用句子长度、句子位置、句子与文章标题的相似度等以提高摘要句子的准确性.文献[5]提出基于词频、句子位置、句子长度及句子与标题相似性等特征的4种不同的加权方法,解决了基于微博新闻文本的自动摘要问题.文献[6]提出一种基于图的迭代强化方法,在一个框架下同时处理两个任务,表达句子与词之间的各种二元关系.文献[7]提出了一种新的基于超图的协同抽取方法,以句子作为超边,以词作为结点构建超图,在一个统一的超图模型下同时利用句子与词之间的高阶信息来生成摘要和关键词.文献[8-9]提出面向微博的自动摘要方法Hybrid TF-IDF和词语加强(phrase reinforement, PR)方法.上述一系列方法都在一定程度上提高了摘要句抽取的召回率.
1.2 基于篇章理解的摘要
基于篇章理解的自动摘要方法是基于对自然语言的理解发展起来的,它需要利用语言学和领域知识对句子进行结构分析和语义的判断、推理,最后根据句子语义生成自动摘要.文献[10]研发出基于知识理解的SCSIOR系统.文献[11]在文本物理结构的基础上,利用汉语复句研究理论、RST理论和各种汉语语言特征的融合方法获取摘要句.文献[12]系统地描述了不同层面上文本单元之间的相互关系,并且提出了文档的修辞结构框架.基于篇章理解生成的摘要质量好、简洁全面以及可读性好,解决了基于抽取的摘要质量差的问题.
本文总结上述方法及微博新闻文本特点,提出了互信息主题划分、多种统计特征和Ranking SVM模型相结合的策略来获取微博新闻文本的自动摘要.
2 自动摘要
本文把自动摘要任务分成两个阶段,即基于文本的特征提取和文本摘要句提取.针对微博新闻文本给出各个特征的提取方法,摘要句提取部分则是采用有监督的Ranking SVM模型,来对上一过程得到的各种特征进行排序,得到排序靠前的句子作为摘要句.
2.1 特征提取
在对新闻文本提取特征之前,首先判断每一句话是否为否定句和疑问句,这两类句子一般不会作为摘要句出现,所以先去除这类句子,以减少后面的处理工作.
2.1.1 词频 词频作为最能反映文本信息的统计特征,可以通过多种计算方式得到,用公式(1)来计算文本中每个单词的频率,句子作为词语的集合形式,出现在其中的所有词语的频率之和反映了该句子的重要性,用公式(2)来计算每个句子的词频权重.

(1)
其中:n代表新闻文本词语的总个数;mi代表词语在文本中出现的次数;分母表示所有的词语在文本中出现的总次数.

(2)
其中:seni表示新闻文本中第i个句子,w代表句子中的一个词语,tf(w)的值可由公式(1)计算得到.
2.1.2 句子位置 句子位置是反映新闻文本的一个重要特征.每篇新闻文本都可以看作是句子的线性组合,往往第一个句子涵盖整篇文本的重要信息,因此,用Posi=(1+n-pi)/n来计算句子的位置特征.其中:pi代表新闻文本中第i个句子的位置;n代表新闻文本中总的句子数目.
2.1.3 与标题相似度 标题一般情况下是文本信息的浓缩体现,能很好地反映文本的主题,因此与标题具有很高相似度的句子较容易被选为摘要句,本文采用余弦相似度来衡量每个句子与标题的相似度.具体的计算公式为

其中:Simi表示第i个句子与标题的相似度;s和t是句子和标题的向量表示;n表示向量的维数;sj和tj分别表示向量的第j维的值.
2.1.4 指示性词语 文章中常有一些特殊的短语、字串,即指示性短语,它们对文章主题有明显的提示作用,例如“这篇文章的意义是”、“本文的目的是”、“我们认为”等.基于提示性短语句子si权重的加权规则为
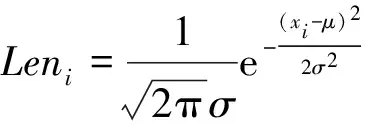
2.1.6 主题句 一篇新闻通常可能包含一个以上的主题,每个主题句包含的相应信息较多,因此选取摘要句时应赋予主题句较高的权重.本文利用互信息对文本中词语、句子之间的关联程度进行计算,根据其关联程度将其划分为包含不同主题的较小单元,并根据句子权重计算公式进行主题句提取,是主题句赋值为1,否则为0[13].
2.2 摘要句提取
在摘要提取这部分,本文采用Ranking SVM 对句子进行排序,根据排序结果选出摘要句.Ranking SVM模型是由文献[14]提出的一种排序算法.文献[15]将该模型用于文档检索任务.文献[16-17]提出了基于pairwise的数据标注方法,并且给出了免费工具SVMRank.
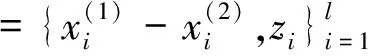
Herbrich等人将上述的排序学习问题看做基于实例对的分类学习问题.首先设定一个线性函数f.f(x;w)=
(3)
将公式(3)转换为二值分类问题,则可以表示为:

对于给定的训练数据S,本文以此构造一个新的包含l个向量的训练数据集合S′,将S′中的数据作为分类数据构造SVM模型,对任意一组向量X(1)和X(2)赋以分类类别,其中z =+1 代表正样例,z=-1 代表负样例.
根据上述特征组,利用训练数据训练RankingSVM模型,然后用该模型对测试文本做预测,具体过程见表1的算法1.
3 实验
3.1 实验数据
实验所用数据是由第四届自然语言处理与中文计算会议(NLP&CC2015)提供,NLP&CC2015评测数据来自新闻文本,包含训练数据140篇,测试数据250篇,并且每篇新闻文本都提供两个人工摘要分别记为a和b.
3.2 实验评估指标
采用ROUGE工具(1.5.5版)[19],通过计算待评价摘要与人工摘要在 n-gram 上的重叠度来衡量模型生成摘要的质量.其中基于1-gram 的 ROUGE 分数(ROUGE-1)被公认为和人工摘要的结果最接近.此外,由于摘要长度限定在140字以内,因此我们在实验时使用了“-l”命令.
3.3 实验结果及分析
采用两种基线方法,分别是参与NLP&CC2015取得不错结果的CIST-SUMM团队和获得最佳结果的NLP@WUST团队.CIST-SUMM团队同时采用基于规则和基于机器学习的句子排序方法,所用特征包括句子覆盖率、和标题相似度、句子位置、关键词、命名实体和通过LDA获得的新特征.NLP@WUST团队则是使用词频、句子位置、句子长度、和标题的相似度4个特征的线性组合.具体结果如表2所示.
由表2可知,本文所选取的特征在新闻文本自动摘要中很具有代表性,并取得了不错的结果.CIST-SUMM团队的结果是参加评测团队中结果相对较好的,与CIST-SUMM团队相比,本文首先利用互信息对文本进行关联度计算,即通过计算文本中词与词、句子与句子、段落与段落之间的互信息值量化文本段落之间的关联度,从而确定文本的主题句,进一步提高了摘要句提取效果、采用基于多特征的、监督的Ranking SVM排序算法很好地融合文本多个统计特征和语义特征,证明了本文所用的排序方法在新闻文本自动摘要领域的有效性.

表1 算法设计

表2 NLP&CC2015整体结果的ROUGE值对比
4 结论
本文通过对新闻文本自动摘要的研究与实验,分析了研究中的问题,并提出了可行的研究方法、解决路线及技术框架.借助自然语言处理的开源工具进行数据预处理和各个特征提取.基于Ranking SVM模型的文本自动摘要,从最初的新闻文本中选取多语义特征,对文本中每一个句子进行排序,最终选取得分最高的句子作为文本摘要句.
[1] 中国互联网信息中心. 第36次中国互联网络发展状况统计报告[R].北京:中国互联网信息中心,2015.
[2] LUHNHP.The automatic creation of literature abstraets[J].IBM journal of research and development,1958,2(2):159-165.
[3] EDMUNDSON H P. New methods in automatic extracting [J]. Journal of the ACM (JACM),1969,16(2):264-285.
[4] LIN C Y,HOVY E. Identifying topics by position [C]// Proceedings of the 5th Applied Natural Language Processing Conference.New Jersey, 1997:283-290.
[5] LIU M F, WANG L M, NIE L Q. Weibo-oriented chinese news summarization via multi-feature combination[C]//The Conference on Natural Language Processing and Chinese Computing.Nanchang,2015:581-589.
[6] WAN X, YANG J, XIAO J. Towards an iterative reinforcement approach for simultaneous document summarization and keyword extraction[C]//Annual Meeting-Association for Computational Linguistics. Prague, 2007:552-559.
[7] 莫鹏,胡珀,黄湘冀,等.基于超图的文本摘要与关键词协同抽取研究[J].中文信息学报,2015,29(6):135-140.
[8] SHARIFI B, INOUYE D, KALITA J.Summarization of twitter microblogs [J].The computer journal,2014,57(3):378-402.
[9] SHARIFI B, HUTTION M, KALITA J. Experiments in microblog summarization[C]//Proceedings of the 2nd International Conference on Social Computing. Minneapolis,2010:49-56.
[10]SJACOBS P, FRAU L.Scisor:extracting information from online news[J].Communications of the ACM,1990,33(11):88-97.
[11]BAE J H J, LEE J H. Another investigation of automatic textsummarization :a reader-oriented approach[C]//Proceedings of the Austrilian and New Zealand Intelligent Information System.Brisbane,1994:472-476.
[12]张美娜,亓超,迟呈英,等. 基于汉语篇章结构的自动摘要方法研究[J]. 情报杂志,2007,26(8):34-36.
[13]兰希. 基于篇章修辞结构的多文档自动文摘系统的设计与实现[D].厦门:厦门大学,2014.
[14]刘星含,霍华. 基于互信息的文本自动摘要[J]. 合肥工业大学学报(自然科学版),2014,37(10):1198-1203.
[15]HERBRICH R, GRAEPEL T, OBERMAYER K. Large margin rank boundaries for ordinal regression[C]//Advances in Neural Information Processing Systems 12.Colorado:Denver,1999: 115-132.
[16]CAO Y, XU J, LIU T Y, et al. Adapting ranking SVM to document retrieval[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington, 2006: 186-193.
[17]JOACHIMS T. Optimizing search engines using clickthrough data[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Alberta:Edmonton, 2002: 133-142.
[18]DILL S, EIRON N, GIBSON D, et al. Semtag and seeker: bootstrapping the semantic web via automated semantic annotation[C]//Proceedings of the 12th International Conference on World Wide Web.Philadelphia, 2003: 178-186.
[19]LIN C Y, HOVY E. Automatic evaluation of summaries using n-gram co-occurrence statistics[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Edmonton, 2003: 71-78.
(责任编辑:方惠敏)
Micro-blog-oriented Chinese News Summarization Based on Multi-feature and Ranking SVM Algorithm
LI Mengshuang, ZAN Hongying, JIA Huizhen
(SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450001,China)
A Micro-Blog-oriented Chinese news automatic summarization algorithm was proposed.Mutual information was used to compute semantic feature among words and sentences in the Chinese news text.Then different topics were divided according to the correlation among the sentences,and a higher weight was gaven to topic sentences. Various combined features were extracted from the text,and sentences were ranked by Ranking SVM algorithm.The result of this algorithm demonstrated the effectiveness of the method.
mutual information; semantic feature; topic sentences; Ranking SVM; Chinese news automatic summarization
2016-09-19
国家自然科学基金项目(61402419);国家社会科学基金项目(14BYY096);国家高技术研究发展863计划项目(2012AA011101);国家重点基础研究发展计划 973 课题(2014CB340504).
李孟爽(1993—),女,河南周口人,硕士研究生,主要从事自然语言处理研究,E-mail:limengguan@foxmail.com;通讯作者:昝红英(1966—),女,河南焦作人,教授,主要从事自然语言处理研究,E-mail:iehyzan@zzu.edu.cn.
TP391
A
1671-6841(2017)02-0043-05
10.13705/j.issn.1671-6841.2016239
