知识驱动的游戏攻略自动标注算法
2017-04-17陈环环陈小红高大启王昊奋
陈环环,陈小红,阮 彤,高大启,王昊奋
(1.华东理工大学 计算机科学与工程系,上海 200237; 2.盛趣信息技术(上海)有限公司,上海 201203)
(*通信作者电子邮箱1558589300@qq.com)
知识驱动的游戏攻略自动标注算法
陈环环1*,陈小红2,阮 彤1,高大启1,王昊奋1
(1.华东理工大学 计算机科学与工程系,上海 200237; 2.盛趣信息技术(上海)有限公司,上海 201203)
(*通信作者电子邮箱1558589300@qq.com)
为了帮助用户快速检索感兴趣的游戏攻略,提出了知识驱动的游戏攻略自动标注算法。首先,对每款游戏的多个资讯网站进行融合,自动构建游戏领域知识库;然后,再通过游戏领域词汇发现算法和决策树分类模型,抽取游戏攻略中的游戏术语;由于游戏术语在攻略中大多以简称的形式存在,故最后将攻略中游戏术语和知识库进行链接得到该术语所对应的全称即语义标签对攻略进行标注。在多款游戏上的实验结果表明,所提出的游戏攻略标注方法的准确率高达90%。同时,游戏领域词汇发现算法与其他术语抽取方法n-gram语言模型相比取得了更好的效果。
游戏攻略;知识库;游戏术语;语义标签;决策树
0 引言
当前游戏产品愈发同质化,游戏能否成功占有市场,游戏玩家的用户体验成为最关键的一步[1]。如今,游戏产品可供选择的数量众多,用户偏好日趋多元化。只有将好的用户体验利用在游戏设计上,才能赢得用户玩家的心声。目前,主要从游戏角色的设计、游戏视觉效果及游戏的操作等方面提升用户的体验[2]。据统计,大量的热门游戏的资讯网站中都包含丰富的游戏攻略,这是玩家的主要检索对象,可帮助用户特别是新手玩家快速地入门和升级,是提升用户体验的重要组成部分。游戏攻略标注问题近年来研究较少。因此,本文通过对游戏攻略进行标注帮助用户快速检索所需的游戏攻略从而提高用户的游戏体验。
由于每款游戏有多个资讯网站,且有很少资讯网站提供搜索功能,玩家检索自己感兴趣的攻略时需辗转于多个资讯网站之间,花费大量的时间和精力,因此,对游戏攻略进行标注可以提高攻略检索的效率。同时,玩家通过语义标签,可以更快更全面地了解攻略内容,且语义标签的生成有助于游戏攻略的分类和语义搜索系统的构建。
本文中的游戏攻略的标注任务如下:给出一条基于文本的游戏攻略,识别出其中包含的游戏术语,并将这些术语作为该攻略的标签。然而,攻略中的游戏术语大多以简称的形式存在,且游戏攻略内容比较口语化,这是对攻略进行标注的难点。在本文中,游戏术语为游戏领域内的专有词汇且包含其简称。例如,游戏“最终幻想14(FF14)”中的一个攻略标题为“FF14剑术师及骑士入门技能分析和输出手法”包含游戏术语“剑术师”和“骑士”,因此“剑术师”和“骑士”是该攻略的标签。首先,针对同一款游戏不同资讯网站的异构现象,本文提出通过融合多个网站来构建知识库的思想,知识库具有完善的层次结构并存储了丰富的游戏领域知识。其次,为了准确地抽取游戏攻略中的游戏术语,本文提出一个新的方法:游戏领域词汇发现算法。由于大多游戏术语以简称的形式存在于游戏攻略中,因此,本文使用匹配算法将攻略中的游戏术语和知识库进行链接,从而得到游戏术语的全称即语义标签。
本文的主要工作如下:
1)对于大多数热门游戏,提出一套通用的方法构建知识库。对于知识库构建过程中所产生的冲突给予有效的解决方法。
2)针对游戏攻略的结构特点及游戏术语特征,在原有“新词发现算法”[3]基础上进行优化得到“游戏领域词汇发现算法”,并结合决策树分类模型抽取游戏术语。
3)本文提出一种适合游戏领域的匹配算法,将游戏攻略中的术语与所构建知识库进行连接,从而生成语义标签。
1 相关工作
本文研究的关键技术为:构建游戏领域知识库、抽取游戏攻略中游戏术语。近年来,知识库的构建和中文术语的抽取得到了广泛的研究。下面将简要介绍。
构建高质量的知识库是本文游戏攻略标注的关键步骤,知识库的完善与否直接影响游戏攻略标注的准确率。DBpedia[4]、Freebase[5]、YAGO(Yet Another Great Ontology)[6]都是通用知识库,包含了丰富的数据,但是缺乏游戏领域知识。DBpedia是从维基百科中自动抽取结构化信息,被广泛用于语义万维网和商业环境。Freebase中的所有内容由用户添加,所有条目都采用结构化数据的格式。YAGO主要信息来源于维基百科,具有足够高的准确度和覆盖度。本文所建的知识库和上述几个知识库相似,都是通过融合互联网资源得到。
中文术语的抽取是中文信息处理的一项重要任务,在领域本体构建方面有着重要应用。现有的术语抽取方法主要有以下三类:
1)基于规则的方法。通过人工总结的规则模板抽取术语,如术语的上下文、词法模式、词形等。文献[7]利用术语的共同特征前缀信息,抽取前缀是名词的文本片段为术语。类似的,还有一些其他的抽取规则,如首部修饰定律、五层术语抽取模型[8]等。该方法的优点在于实现简单、准确率较高,缺点在于规则由人员编写,耗时耗力。
2)基于统计的方法。利用术语内部各组成成分之间较高的关联程度以及术语的领域特征信息来抽取术语。目前该方法在抽取术语时,用到的主要参数有:互信息(Mutual Information, MI)[9]、Term Frequency-Inverse Document Frequency(TF-IDF)[10]、词频[11]、似然比(Likelihood Ratio, LR)[12]等。陈士超等[13]在不更改互信息公式的前提下,通过设置双阈值的方法进行候选术语的选取与过滤。该方法的优点是通用性较强,缺点是针对稀疏数据效果较差。
3)统计和规则相结合的方法。此方法综合基于规则和统计的优缺点而提出。樊梦佳等[14]提出了采用左右信息熵扩展、边界信息出现概率和TF-IDF相融合的统计方法,同时引入词性搭配规则进一步约束术语的构成,从而抽取术语。Bonin等[15]先根据规则抽取候选集合,然后使用C-value和T检验的方法计算,最后得到真正术语。目前,统计和规则相结合的方法在术语抽取方面还未达到理想水平。
本文抽取的是游戏攻略所包含的游戏术语,由于游戏攻略语言表达较口语化且游戏术语组成结构也无规律可循,使用以上抽取方法效果不佳。本文提出的游戏术语抽取方法综合词组的词频和上下文信息得到候选词,在统计方法的基础上进行了扩展。
2 游戏攻略标注算法的整体流程
2.1 游戏攻略标注算法的思想
本文的目标是找到一种适用于大多数热门游戏的游戏攻略标注方法。整体流程如图1所示,通过对三个数据源的数据进行解析融合后得到如图2所示的知识库结构。从每款游戏的多个资讯网站中解析攻略文本数据构成语料库,每条攻略包含标题和内容两部分。通过游戏领域词汇发现算法得到候选词,该算法包含两个成词标准“内部凝固程度”和“自由运用程度”。在进行链接时,判断标题中是否包含候选词。若包含,则选取最长候选词使用匹配算法和知识库进行链接。在链接的过程中,若攻略标题中游戏术语以全称的形式存在,则和知识库完全匹配。若以简称的形式存在,则通过相似度计算和知识库匹配。通过匹配算法得到游戏术语全称进而对攻略进行标注。
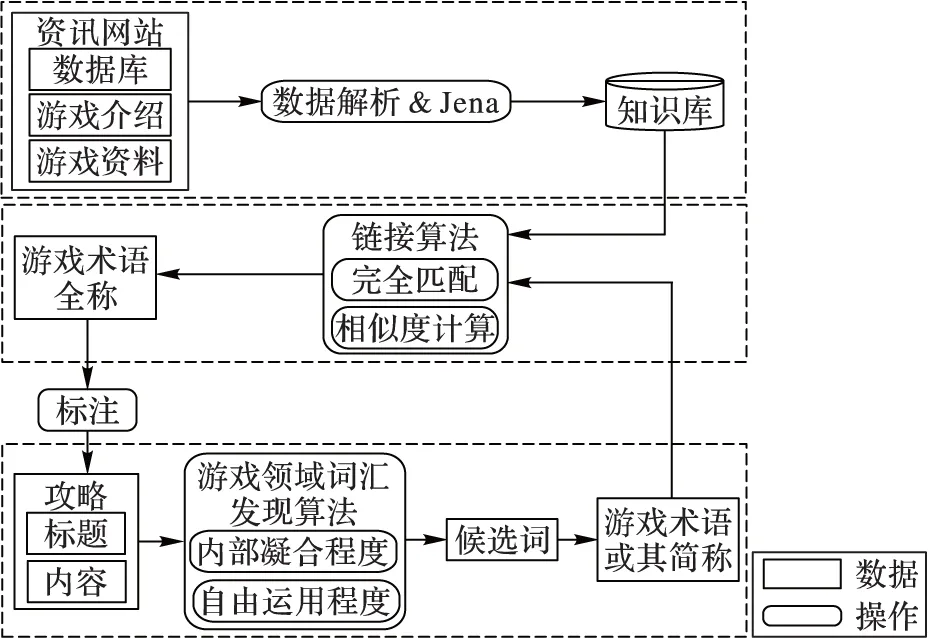
图1 算法整体流程
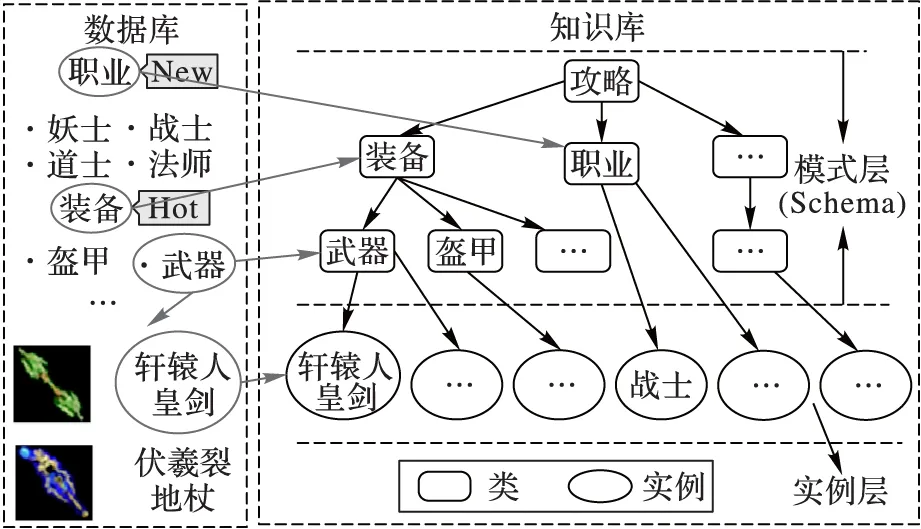
图2 知识库结构
2.2 问题定义
本文主要研究对象为游戏,通过观察发现,热门游戏均满足以下条件。
1)每款游戏至少有两个资讯网站,资讯网站至少包含数据库(Database)、游戏资料、游戏介绍中的一项,且它们都包含完善的分类体系及丰富的游戏领域知识。这是构建知识库(Knowledge Base)的主要数据来源。
2)游戏攻略(Strategy)每天都在不断更新,每条攻略数据都由两部分构成:攻略标题(title)和攻略内容(content),且94%左右的标题都会包含一个或者多个游戏术语。游戏攻略构成语料库。标题中的游戏术语是语义标签的来源。
3)在知识库中,游戏术语均是以全称的形式存在。
针对满足以上条件的热门游戏,本文的主要任务可以描述为:对于给定的语料库(Corpus),抽取出每条攻略所包含的游戏术语集合M={mention | mention in title},在知识库中找到其对应的游戏术语全称集合E={entity | entity in Knowledge Base}。本文输入为大量的游戏攻略数据,输出为游戏攻略及其标签{(strategy,tags) | strategy in corpus and tags in Knowledge Base}。具有以上条件的游戏均可使用本文所提出的方法进行游戏攻略标注,具体算法在下面的章节中会详细介绍。
3 游戏攻略标注算法设计
3.1 构建游戏领域知识库
本文提出一套通用的方法来构建游戏知识库。知识库的主要来源为游戏资讯网站中的数据库或游戏介绍或游戏资料,这些数据可能存在于同一款游戏的多个资讯网站中。它们具有完善的分类体系和丰富的游戏领域知识,可通过解析网页的超文本标记语言(Hyper Text Markup Language,HTML)结构获得,进而构成了知识库的模式层和实例层。以“传奇世界(http://woool.games.sdo.com/knowledge/index)”为例,图2给出了这款游戏的部分知识库结构。“传奇世界”数据库中有“职业”和“装备”,“装备”下包含“盔甲”“武器”等,在页面上点击“武器”会出现具体的武器页面如“轩辕人皇剑”且其下面没有更细的划分,因此“轩辕人皇剑”是“武器”的实例构成实例层,且“武器”和“盔甲”是“装备”子类和“装备”一起构成模式层。同理,“职业”也是如此。由于每款游戏有多个资讯网站且资讯网站之间存在差异性,因此需要进行数据融合,同时需要解决融合过程中可能产生的冲突。
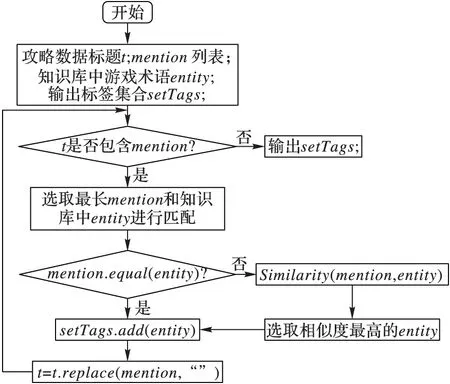
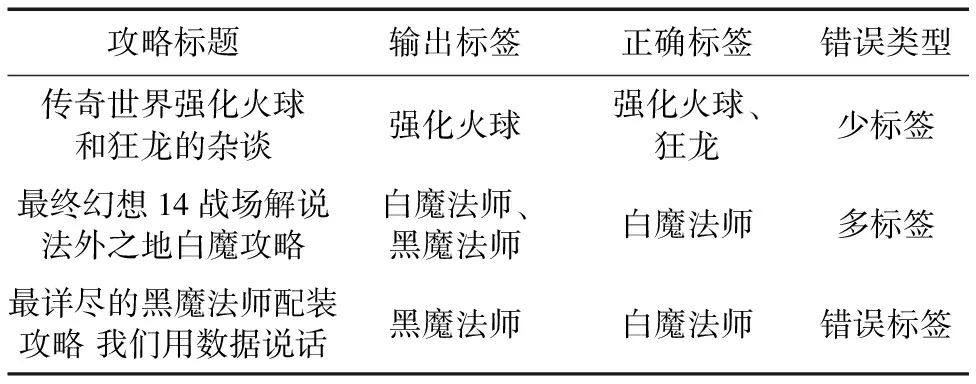
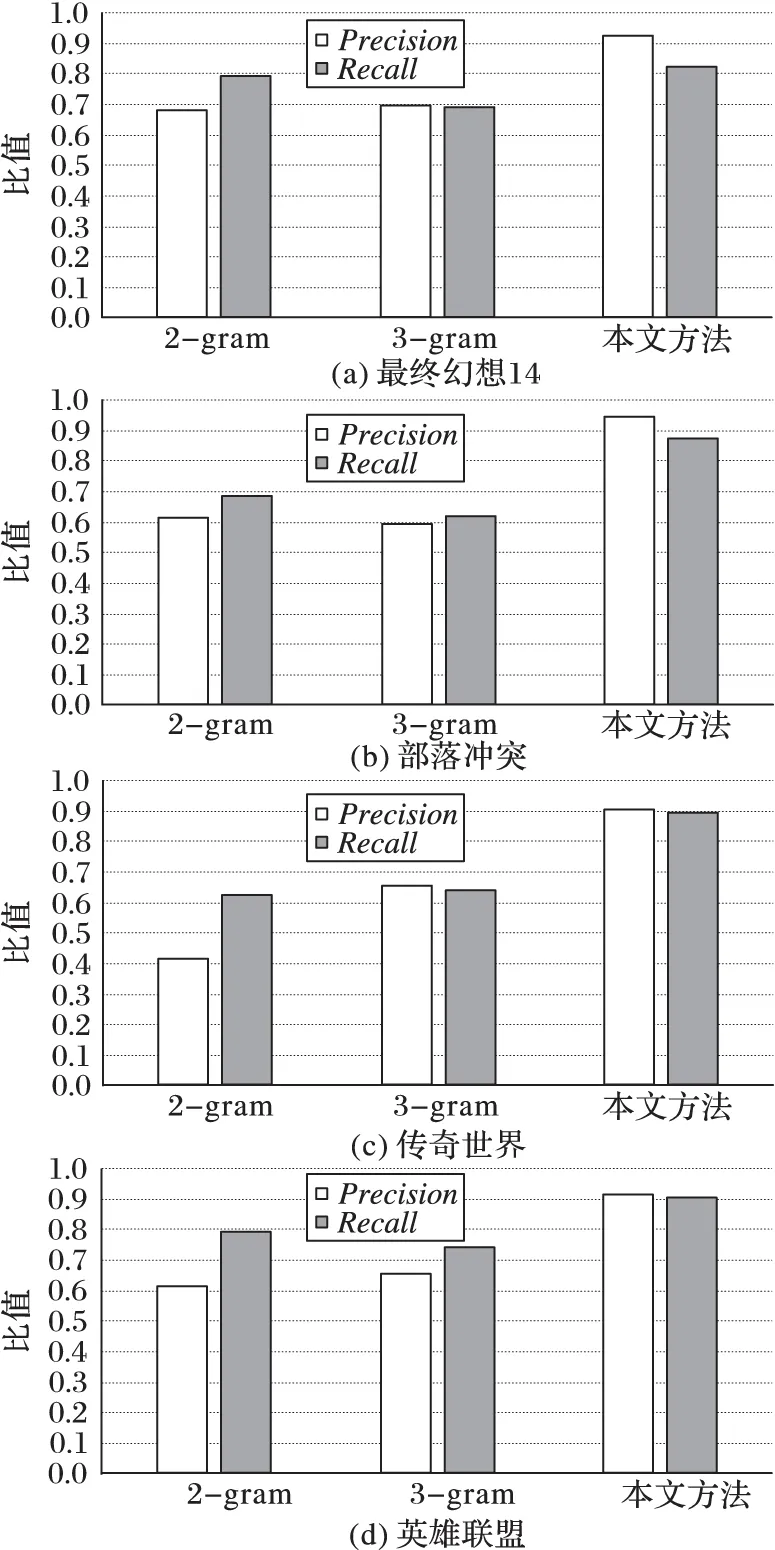
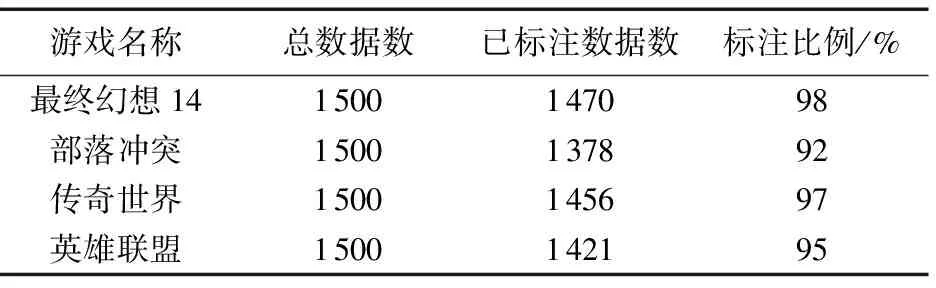
首先,对模式层进行融合。模式层所产生的冲突主要表现为:同一个子类在不同的资讯网站中所属父类不同。可以描述为:设有三个类A、B、C,类C在不同的网站中分别属于不同的父类A和B。首先根据简单的投票机制计算类C属于类A的网站数num(A)及属于类B的网站数num(B)。若num(A)>num(B),则将类C划分到类A下。若num(A) Ri=fi/(f1∪f2∪…∪fi) (1) 其中,fi为类i的实例数,通过这个公式可得RA和RB。若RA>RB,将类C划分到类A下;若RA 然后,对实例层进行融合。在实例层会产生两类冲突:一类是同一个实例在不同的网站分属不同的类;另一类是同一类在不同的网站所包含的实例不同。对于第一种情况使用解决模式层冲突的方法,这里不再重复。对于第二种冲突,需要对此类中的实例进行字符串相似度计算,这里使用简单的最长公共字串的计算方法,公式如下: (2) 其中:lcs(longest common substring)是最长公共子串;length(lcs)指的是两个实例最长公共子串的长度;length(fi)指网站i中实例f的长度;length(fj)指网站j中实例f的长度。通过实验,sim(fi,fj)取值有三种情况: 1)sim(fi,fj)=0,实例fi作为实例fj的补充加入知识库中。 2)0.5 3)sim(fi,fj)=1,实例fi和实例fj完全相同,则进行去重融合。 例如,“最终幻想14”这款游戏有两个资讯网站“178(http://ff14.178.com/)”和“多玩(http://ff14.duowan.com/index.html)”。“178”网站副本类中有实例“塔姆·塔拉墓园”,“多玩”网站副本类中有实例“地下灵殿塔姆·塔拉墓园”,计算相似度得到sim∈(0.5,1),故将“地下灵殿塔姆·塔拉墓园”加入知识库中。 本文通过以上方法,可对热门游戏构建知识库。详细介绍了知识库数据的来源以及在融合过程中产生的冲突,并对融合中产生的冲突提出了统一的解决方法。构建的知识库使游戏领域知识更加结构化且使玩家对游戏有更全面的认识,有利于对游戏进行组织和管理。但是,游戏知识库构建的完善与否直接影响其质量,且构建知识库是本文标注质量的关键技术之一。本文将通过攻略数据的标注效果对所构建的游戏领域知识库质量进行评测。 3.2 游戏攻略中游戏术语的抽取 游戏攻略所包含的游戏术语大多属于未登录词即新词,无法使用传统的分词方法进行抽取。因为,传统的分词方法要想达到分词的准确性必须依赖词库的完整性,然而目前词库无法穷举出所有的未登录词。基于游戏术语的特点,本文提出一种新的游戏术语抽取方法:游戏领域词汇发现算法。 游戏领域词汇发现算法在新词发现算法[3]的基础之上优化得到。新词发现算法判断一个文本片段是否成词的标准为:“内部凝固程度”和“自由运用程度”。由于语料库的不同,对成词标准的计算进行了优化以适应游戏领域。“内部凝固程度”的计算公式为: (3) (4) 其中,λ1λ2λ3表示一个词是由λ1、λ2、λ3三部分组成,在使用的时候可能不止这三部分其计算原理是一样的。P(λ)为λ出现的概率,length为长度,num为词频,Text是整个语料库。例如,“蝙蝠侠”“自由运用程度”就是P(蝙蝠侠)与P(蝙蝠)·P(侠)的比值和P(蝙蝠侠)与P(蝙)·P(蝠侠)的比值中的较小值。 “自由运用程度”也是成词的重要标准之一。一个文本片段可以成词的话,肯定有非常丰富的左邻字和右邻字。例如“我最近眼睛痛,可能是用眼睛过度,应该保证眼睛适当的休息,因为眼睛是我们心灵的窗户”。这句话中“眼睛”一次共出现四次,它的左邻字集合为{近,用,证,为},右邻字集合为{痛,过,适,是}。这里,使用信息熵进行衡量。通过对游戏攻略的观察,发现每个攻略数据所包含的内容较短且由多个段落组成,故属于短文本。在计算信息熵时,会经常出现一个词的左邻字是开头或者是标点符号,右邻字是结尾或者标点符号。针对这种情况本文的处理是视其左邻字或右邻字为一个未出现的新词,并统计出现这种左邻字或右邻字的词频。通过以上的改进得到信息熵的计算方法为:设一个词W的左邻字集合为{X1,X2,…,Xn},则W的左邻字信息熵为: n+m=num(W) (6) 由式(5)和式(6)可得: 其中:P(X)=num(XW)/num(W),num(Otherl)为左邻字是开头或者标点符号的次数。同理,设W的右它们邻字集合为{Y1,Y2,…,Yn},可得到W的右邻字信息熵的计算公式为: 其中:P(Y)=num(YW)/num(W),num(Otherr)为右邻字是结尾或者标点符号的次数。综合左邻字信息熵和右邻字信息熵,可得信息熵的计算公式为: H=min{H(X),H(Y)} (9) 针对游戏攻略数据的特点,在实际的抽取过程中还进行了如下改进: 1)候选词长度d的调整。该算法必须设定候选词长度,候选词长度的选取直接影响链接的准确率和效率:若过小,则会丢失很多游戏术语;若过大,则会掺杂很多无用的词汇。针对不同的游戏,所设置的候选长度也会不同。具体调节策略为:候选词长度为知识库中游戏术语的长度最大值。如此,所抽取的候选词不会产生遗漏现象,也不会掺杂过多无关词汇,从而提高抽取的质量。 2)将语料库中出现的英文和数字进行预先处理存储在候选词集合中,然后进行正常的抽取。之所以事先抽取英文词语,是因为攻略数据绝大部分是中文,即使出现英文也是一个完整的英文单词。如果在正常抽取过程中抽取英文单词,则会将英文词的子串加入到候选集合中。对于热门游戏来说,游戏术语不会出现有数字的情况。预先处理数字可以提高抽取的效率和质量。 该算法的伪代码为: 输入:setStrategies, Set of game strategy 输出:setPhrases, Set of phrase that meet conditions 1) foreachstrategy∈setStrategiesdo 2) PhraseMap←length<=d(phrase;num) 3) ifleftPhraseexiststhen 4) LeftPhraseMap←leftPhrase 5) ifleftPhraseispunctuationorbeginningthen 6) PBMap← (LeftPhrase, 1) 7) rightPhrasesame asleftPhrase 8) if!leftPhrase‖!rightPhrasethenAsanewword 9) PhraseSet← 1 10) setPhrase←Phrase(C,H,num) 11) endfor 该算法的输入为游戏攻略数据,输出为满足条件的词组集合,第2)行是抽取长度不大于d的词组的词频。该算法得到包括游戏术语在内的词组及该词组的凝合度、信息熵和词频。得到的词组包含大量的无用词汇,比如得到的词组中包含黑魔法师,但也包含魔法、法师等无用词汇。对此,本文使用二分类模型进行过滤。以每个词的凝合度、信息熵、词频作为特征训练二分类模型:一类是需要的候选词,另一类是不需要的。首先,从词组列表中随机选取2 000条数据进行人工标注,分别选取支持向量机(Support Vector Machine, SVM)、贝叶斯和决策树[16]作为分类模型,使用十折交叉验证测试每个分类模型的准确率。整个分类的过程使用机器学习工具Weka实现。最后,得到决策树分类模型的准确率最高,为97.4%。因此,选取决策树作为分类模型过滤出所需的候选词汇即mention列表。 3.3 实体链接 本文的实体链接任务为:将攻略标题中出现的游戏术语和知识库中的游戏术语进行链接,从而得到每条攻略数据的标签。通过对多款热门游戏观察可知,攻略标题包含游戏术语有以下几种情况。 1)攻略标题只包含一个游戏术语。例如,标题为“传奇世界传承珠完全使用的攻略”的攻略,它包含一个游戏术语“传承珠”。该攻略的标签类型为单标签。 2)攻略标题中包含多个游戏术语。例如,标题为“传奇世界武士的终极装备搭配”的攻略,它包含两个游戏术语“武士”和“装备”。该攻略的标签类型为多标签。 3)攻略标题中游戏术语是知识库中游戏术语的简称。例如,标题为“爆发吧黑魔法 黑魔副本输出手法经验谈”的攻略,它包含的游戏术语“黑魔”是知识库中“黑魔法师”的简称。 基于上述情况的考虑,本文提出了适合游戏攻略的链接算法,实现了游戏攻略中术语和知识库的一一映射,进而达到标注的目的。具体链接算法的流程如图3所示。 在图3中,mention列表是由游戏领域词汇发现算法和决策树分类模型得到的候选词集合。若标题中包含mention,必须选取长度最长的mention和知识库链接。例如,知识库中包含“白魔法师”“黑魔法师”,攻略标题包含“黑魔法师”,候选词有“法师”“黑魔法师”。若不选取最长的候选词则链接时会引入错误标签“白魔法师”。mention和知识库不完全匹配时的相似度计算公式为式(2)。 4.1 实验数据 本文语料库为游戏攻略数据。选取4款热门游戏进行测试,分别为“部落冲突”“传奇世界”“英雄联盟”和“最终幻想14”。从这4款游戏的多个资讯网站中爬取游戏攻略数据,并进行去重后,每款游戏各选取1 500条进行实验。为了验证测试结果,本文采用文本标注实验时经常使用的评价标准:准确率(Precision)和召回率(Recall)。若定义Num(right)为正确标注的数据个数,Num(wrong)表示错误标注的数据个数,Num(null)表示没有标注的数据个数,则准确率和召回率的定义分别如下: (10) (11) 图3 实体链接算法流程 4.2 实验结果与分析 在抽取攻略数据中的游戏术语时,除了使用本文提出的方法抽取游戏术语外,还和n-gram语言模型进行对比。n-gram语言模型是一种基于统计的文本模型,在抽取术语领域中得到广泛的研究。这种方法主要通过对语料库的机器学习来获得字与字相邻出现的统计信息而进行分词,它的一个明显优点是可以切分出未登录词,也是一种新词发现方法。它的切分词的思想和本文提出的游戏领域词汇发现算法类似,成词标准都与上下文信息有关。最后,根据标注结果的准确率和召回率对本文方法和n-gram模型进行比较。 在游戏攻略标注的过程中,标注错误的情况如表1所示。 表1 标注错误的类型 对于未标注的攻略,发现大多为玩家心情类。例如,标题为“去年和你一起跑复活节的那个人,今年在哪里”的攻略,标题中并未包含游戏术语,因此本文对这类标题无法标注。对于这类文本的标注还有待研究。使用本文方法和n-gram模型(n取2或3)对4款游戏进行标注,得到的准确率和召回率如图4所示。 通过图4可以看出,在这4款游戏中,本文所提出的方法得到的准确率和召回率均大于n-gram方法。在这4款游戏中,使用本文方法得到的准确率平均为92.0%,平均召回率为87.1%;使用2-gram得到的平均准确率为57.8%,平均召回率为72.0%;使用3-gram得到的平均准确率为64.7%,平均召回率为67.0%。得出本文方法相比2-gram,平均准确率提高了34.2个百分点,平均召回率提高了15.1个百分点;本文方法相比3-gram,平均准确率提高了27.3个百分点,平均召回率提高了20.1个百分点。从数据分析可知,在抽取攻略中游戏术语时,本文所提出的方法相比n-gram语言模型更好。使用n-gram语言模型时,n的值一般取2或3。n过大,需要训练更庞大的语料,并且数据稀疏严重;同时,伴随着n的增大,采用该模型所带来的计算量和计算复杂度将远远超过现有的计算机水平。有的游戏术语较长,当n取2或3,会将游戏术语分割成多个更细粒度的词汇,链接时会引入有歧义的标签。 图4 不同游戏在不同词汇抽取方法下的比较 通过统计这4款游戏的标注情况,具体如表2,可知每款游戏标注的攻略占总攻略数据的平均95%左右。对没有标注的数据,统计发现4%左右的攻略标题中不包含游戏术语,从而可以验证使用本文所提出的方法构建游戏领域知识库覆盖面广,质量高。 表2 不同游戏的游戏攻略标注情况 本文针对游戏攻略检索需花费大量时间问题,对游戏攻略进行标注。每个游戏攻略的标签为其所包含的游戏术语所对应的全称。本文的主要优点为:针对游戏攻略中游戏术语的特点提出一种新的抽取游戏术语的抽取方法:游戏领域词汇发现算法和决策树分类模型。和n-gram语言模型进行对比,结果显示本文方法在游戏术语抽取问题上的有效性,解决了在领域词汇术语抽取工作上一直存在的抽取质量问题。数据集上的实验结果表明,本文提出的方法达到较高的准确率和召回率。接下来计划将攻略标签用于攻略分类及攻略搜索系统的构建,并将本文方法应用于其他领域进行领域词汇抽取,如计算机领域、医疗领域等。 References) [1] 马莹莹.对网络游戏产业同质化现象的分析[J].科技和产业,2012,12(8):13-15.(MA Y Y.Analysis the online game industry homogenization phenomenon [J].Science Technology and Industry, 2012, 12(8): 13-15.) [2] 王研,赵旭江.游戏设计中的用户体验影响探析注——以“英雄联盟”为例[J].设计,2014(2):118-119.(WANG Y, ZHAO X J.The study on the influence of user experience in game design——an instance of “league of legends” [J].Design, 2014(2): 118-119.) [3] 顾森.基于大规模语料的新词发现算法[J].程序员,2012(7):54-57.(GU S.New word discovery algorithm based on large scale corpus [J].Programmer, 2012(7): 54-57.) [4] LEHMANN J, ISELE R, JAKOB M, et al.DBpedia—a large-scale, multilingual knowledge base extracted from Wikipedia [J].Semantic Web, 2015, 6(2): 167-195. [5] BOLLACKER K, EVANS C, PARITOSH P, et al.Freebase: a collaboratively created graph database for structuring human knowledge [C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.New York: ACM, 2008: 1247-1250. [6] RUAN T, LI Y, WANG H, et al.From queriability to informativity, assessing “quality in use” of DBpedia and YAGO [C]// Proceedings of the 2016 International Semantic Web Conference.Berlin: Springer, 2016: 52-68. [7] JUSTESON J S, KATZ S M.Technical terminology: some linguistic properties and an algorithm for identification in text [J].Natural Language Engineering, 1995, 1(1): 9-27. [8] VILARES J, ALONSO M A, VILARES M.Extraction of complex index terms in non-English IR: a shallow parsing based approach [J].Information Processing & Management, 2008, 44(4): 1517-1537. [9] BLEI D M.Probabilistic topic models [J].Communications of the ACM, 2012, 55(4): 77-84. [10] BOLSHAKOVA E, LOUKACHEVITCH N, NOKEL M.Topic models can improve domain term extraction [C]// Proceedings of the 2013 European Conference on Information Retrieval.Berlin: Springer, 2013: 684-687. [11] 周浪,张亮,冯冲,等.基于词频分布变化统计的术语抽取方法[J].计算机科学,2009,36(5):177-180.(ZHOU L, ZHANG L, FENG C, et al.Terminology extraction based on statistical word frequency distribution variety [J].Computer Science, 2009, 36(5): 177-180.) [12] GELBUKH A, SIDOROV G, LAVIN-VILLA E, et al.Automatic term extraction using log-likelihood based comparison with general reference corpus [C]// Proceedings of the 2010 International Conference on Application of Natural Language to Information Systems.Berlin: Springer, 2010: 248-255. [13] 陈士超,郁滨.面向术语抽取的双阈值互信息过滤方法[J].计算机应用,2011,31(4):1070-1073.(CHEN S C, YU B.Method of mutual information filtration with dual threshold for term extraction [J].Journal of Computer Applications, 2011, 31(4): 1070-1073.) [14] 樊梦佳,段东圣,杜翠兰,等.统计与规则相融合的领域术语抽取算法[J].计算机应用研究,2016,33(8):2283-2306.(FAN M J, DUAN D S, DU C L, et al.Domain-specific terms extraction algorithm based on combination of statistics and rules [J].Application Research of Computers, 2016, 33(8): 2283-2306.) [15] BONIN F, DELL’ORLETTA F, VENTURI G, et al.A contrastive approach to multi-word term extraction from domain corpora [C]// Proceedings of the 7th International Conference on Language Resources and Evaluation.Malta: [s.n.], 2010: 19-21. [16] ZHANG M, LI K, HU Y.A real-time classification method of power quality disturbances [J].Electric Power Systems Research, 2011, 81(2): 660-666. This work is partially supported by the National Science Foundation of China (61402173), the Software and Integrated Circuit Industry Development Special Funds of Shanghai Economy and Information Technology Commission (140304). CHEN Huanhuan, born in 1990, M.S.candidate.Her research interests include data mining, natural language processing. CHEN Xiaohong, born in 1974.His research interests include big data, user behavior in virtual world. RUAN Tong, born in 1973, Ph.D., professor.Her research interests include natural language processing, information extraction, data quality. GAO Daqi, born in 1957, Ph.D., professor.His research interests include pattern recognition, machine learning. WANG Haofen, born in 1982, Ph.D., lecturer.His research interests include knowledge graph, graph database, data mining. Knowledge driven automatic annotating algorithm for game strategies CHEN Huanhuan1*, CHEN Xiaohong2, RUAN Tong1, GAO Daqi1, WANG Haofen1 (1.DepartmentofComputerScienceandEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China;2.ShengquInformationTechnology(Shanghai)CompanyLimited,Shanghai201203,China) To help users to quickly retrieve the interesting game strategies, a knowledge driven automatic annotating algorithm for game strategies was proposed.In the proposed algorithm, the game domain knowledge base was built automatically by fusing multiple sites that provide information for each game.By using the game domain vocabulary discovering algorithm and decision tree classification model, game terms of the game strategies were extracted.Since most terms existing in the strategies in the form of abbreviation, the game terms were finally linked to knowledge base to generate the full name semantic tags for them.The experimental results on many games show that the precision of the proposed game strategy annotating method is as high as 90%.Moreover, the game domain vocabulary discovering algorithm has a better result compared with then-gram language model. game strategy; knowledge base; game term; semantic tag; decision tree 2016-08-18; 2016-09-06。 国家自然科学基金资助项目(61402173);上海经信委“软件集成电路产业发展专项资金”项目(140304)。 陈环环(1990—),女,山东菏泽人,硕士研究生,主要研究方向:数据挖掘、自然语言处理; 陈小红(1974—),男,浙江永康人,主要研究方向:大数据、虚拟世界的用户行为; 阮彤(1973—),女,江苏扬州人,教授,博士,CCF会员,主要研究方向:自然语言处理、信息抽取、数据质量; 高大启(1957—),男,湖北宜昌人,教授,博士,主要研究方向:模式识别、机器学习; 王昊奋(1982—),男,上海人,讲师,博士,CCF会员,主要研究方向:知识图谱、图数据库、数据挖掘。 1001-9081(2017)01-0278-06 10.11772/j.issn.1001-9081.2017.01.0278 TP391.1 A


4 实验评测
5 结语
