本体与条件随机场结合的涉农商品名称抽取与类别标注
2017-04-17黄念娥王儒敬
黄念娥,黄 河,王儒敬
(1.中国科学院 合肥智能机械研究所,合肥 230031; 2.中国科学技术大学 合肥物质研究院,合肥 230027)
(*通信作者电子邮箱hhuang@iim.ac.cn)
本体与条件随机场结合的涉农商品名称抽取与类别标注
黄念娥1,2,黄 河1*,王儒敬1
(1.中国科学院 合肥智能机械研究所,合肥 230031; 2.中国科学技术大学 合肥物质研究院,合肥 230027)
(*通信作者电子邮箱hhuang@iim.ac.cn)
传统的基于条件随机场(CRF)的信息抽取方法在进行涉农商品名称抽取与类别标注时,需要大量的训练语料,标注工作量大,且抽取精度不高。为解决该问题,提出了一种基于农业本体与CRF相结合的涉农商品名称抽取与类别标注方法,将涉农商品名称的自动抽取与分类看作序列标注的任务。首先是原始数据的分词处理和词、词性、地理属性、本体概念特征选择;然后,采用改进的拟牛顿算法训练CRF模型参数,用维特比算法实现解码,共完成4组对比实验,识别出7种类别,并将CRF和隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)通过实验进行比较;最后,将CRF应用于农产品供求趋势分析。结合合适的特征模板,本体概念的加入使CRF开放测试的总体准确率提高10.20%,召回率提高59.78%,F值提高37.17%,证明了本体与CRF结合方法在涉农商品名称和类别抽取中的可行性和有效性,可以促进农产品供求对接。
条件随机场;农业本体;涉农商品名称;供求趋势;序列标注
0 引言
随着互联网的快速发展,目前已有超过30 000家的涉农电商平台[1],如阿里巴巴农业频道、中国惠农网、顺丰优选等,这些网站每天会发布大量种植业、林木花卉、农机、农具等各类涉农商品信息。通过对这些供求信息的分析,有助于预测农产品市场趋势、及时发现买难卖难、促进供求自动对接。然而,对这些涉农供求信息分析之前首先需要对涉农商品名称与类别进行抽取。如“厂家直销 两行玉米播种机 免剥皮玉米脱粒机”这条供求信息中,需要抽取出“玉米播种机”和“玉米脱粒机”这两个涉农商品名称,同时类别标注为农业机械类。这样,就可以对一段时间内、不同地域的农业机械类的供求情况进行趋势分析。
涉农商品名称自动抽取与类别标注主要涉及农业领域术语自动抽取,包括基于规则与基于统计两种方法。基于规则方法依赖于语言和领域规则模板的建立[2],需要人工编制大量规则和有经验的领域专家,系统可移植性差。基于统计的方法分为经典的统计方法和统计机器学习方法。经典的统计方法主要基于词频、互信息以及信息熵等。Guan等[3]利用关联规则、C-value和词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)混合算法提取中国戏曲领域的专业术语。该方法克服了基于规则的缺点,但低频术语通常不能被有效提取。统计机器学习方法中,最具代表性的为条件随机场(Conditional Random Field, CRF)[4-7],利用序列标注的思想,融合上下文多特征提取领域术语。由于其条件独立性,只需考虑当前已经出现的观测状态特性,对于整个序列内部的信息和外部观测信息均可有效利用,避免了标记偏置问题,被广泛应用。孟洪宇[8]通过CRF融合字符本身、词性、词边界等多特征提取中医术语,F值达到75.56%。Zhan等[9]利用两层CRF提取简单和复杂的术语,并通过领域相关性和一致性提取最终领域术语,F值为82.01%。
传统CRF需要大规模的训练语料[10-12]。针对涉农商品名称抽取与类别标注,由于涉农商品名称繁多,人工标注工作量大。如“玉米收割机”进行了标注,但当遇到“小麦收割机”时,如果样本没有标注,依然不能正确抽取,影响了抽取的精确率。而事实上,如果将“玉米”“小麦”的父类概念“粮油作物”作为CRF的一项特征,可实现由“玉米收割机”抽取出新词“小麦收割机”。因此为实现对属于同一概念的大量新词(指未在样本中标注的词)进行有效抽取,文中将农业本体与CRF相结合,引入词所对应的本体概念作为CRF的特征,赋予涉农商品名称以语义知识,同时结合词、词性、地理位置特征进行CRF训练,最终实现涉农商品名称的抽取与类别标注。通过学习样本,CRF模型表现出一定的“推理”能力,如将概念为粮油作物和收获机械的相邻实例词作为一个涉农商品名称抽取,类别识别为农业机械类,概念为生鲜水果和农作物种子种苗的相邻实例词抽取为种植业类的涉农商品名称等;并将CRF与隐马尔可夫模型(Hidden Markov Model, HMM)、最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM)进行比较,同时用于农产品供求趋势的分析。表明农业本体与CRF相结合进行涉农商品名称抽取与类别标注方法的有效性。
1 农业本体与CRF
1.1 农业本体
本体是关于概念体系的明确的、形式化的规范说明[13],农业本体是专业性的本体,表示的知识都是针对农业学科领域,提供了关于该领域中概念的词表以及概念之间的关系[14-15]。
概念层次是本体的骨架,主要反映概念之间的父类子类关系。文中使用阿里巴巴农业(https://www.1688.com/)概念层次体系,结构如图1所示,该分类体系有4个层次,包括218个叶子节点,目前已有超过170万个农业供求信息映射到该分类体系中,因此基本可以涵盖各种农产品供求类型,具有很强的覆盖性。利用本体中的父子类概念知识表示词所对应的概念,赋予词以语义。生鲜水果作为苹果、草莓的父类概念,可用生鲜水果描述苹果、草莓;种植业作为生鲜水果、农作物种子种苗的父类概念,使用种植业来描述生鲜水果、农作物种子种苗,也可使用种植业来描述苹果、草莓、蔬菜种子种苗等,进一步增强知识泛化能力。
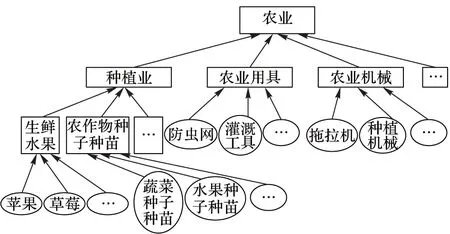
图1 农业本体概念层次树
1.2 条件随机场
CRF是用来标注和划分序列结构数据的概率化的无向图模型[4],具有表达元素长距离依赖性和交叠性特征的能力,在模型中可包含众多领域知识[16]。
1.2.1 CRF模型
对于给定的输出标记序列y=(y1,y2,…,yn)和输入观察序列x=(x1,x2,…,xn),CRF通过定义条件概念p(y|x,λ)来描述模型。图2表示CRF链式结构。
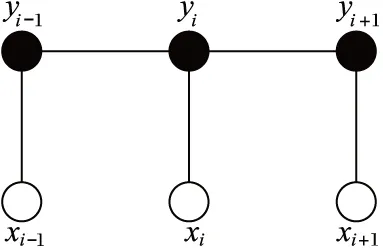
图2 CRF链式结构
CRF定义的条件概率公式为:
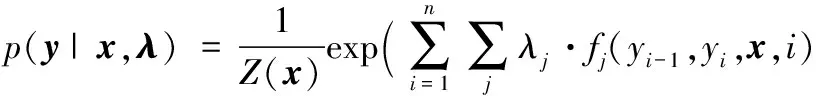
(1)
其中:x为观察序列;y为标记序列;λ=(λ1,λ2,…,λn)为权重向量;λj为特征函数的权重;fj(yi-1,yi,x,i)为对应整个观察序列x,标记位于i和i-1的特征函数;分母Z(x)为归一化因子(保证所有可能的状态序列概率之和为1),公式如下:
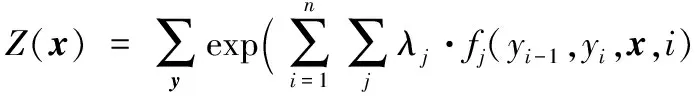
(2)
1.2.2 参数训练
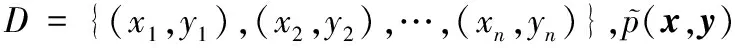

对λj求导:

分别表示经验分布和模型分布中特征的期望值;令式(4)等于0,求λ。
由于改进的拟牛顿算法(LimitedBroyden-Fletcher-Goldfarb-Shanno,L-BFGS)只保存并利用近几次迭代(迭代次数由使用者控制)的曲率信息来构造海森矩阵的近似矩阵,每次迭代的开销小,执行速度快,能保证近似矩阵的正定,算法的鲁棒性强[19]。本文选取L-BFGS算法估计似然参数λ。
1.2.3 解码问题
对于x来说,CRF要做的就是搜索概率最大的y*,即求解式(5):

(5)
该式可通过维特比动态规划算法[4]进行计算,对状态序列作出最优估计。
模型的具体实现中,使用了Taku开发的CRF++-0.58工具包[20],该工具包支持自定义特征集,可输出所有候选的边际概率值,含训练参数时的L-BFGS算法以及解码时的维特比算法,可被应用到各种各样的自然语言处理任务中。实验在64位Windows7下,装有Java、C++编译环境进行,其他配置为IntelPentiumP6200,2.13GHz,2.00GBRAM。
2 数据集和特征选择
2.1 数据集
数据集选自构建农业本体时使用的阿里巴巴网,从中抽取标题数据,包括七大类:种植业、园林业、养殖业、化肥、农业用具、农业机械及鲜活水产品加工制品,覆盖了该网站中近90%的农产品信息,每类500条。
在转换原始语料格式,构造标准的数据集时,利用基于开源HanLp自然语言处理包[21]的CRF分词。分词得到词和词性,并去除停用词,如“阿里巴巴”“淘宝”“顺丰”“包邮”等。如“大量供应优质红小麦”CRF分词后为“大量/m, 供应/vn, 优质/b, 红小麦/nz”,首先利用Java程序经过“,”分隔,得到每个词的词和词性组合,再经由“/”分隔,即可转换为符合CRF++-0.58工具包的输入格式。因涉农商品名称很多由三个及以上词组成,选取5词位标注法,以词为单位进行序列标注,标注符号集为(B,M,E,S,O),为实现类别标注,添加符号集(Z,L,YZ,H,Y,J,X)作为序列标注符号的后缀,各个符号含义如表1所示。如涉农商品名称为“玉米小麦播种机”农业机械类中,标注为玉米(B-J)小麦(M-J)播种机(E-J)。
2.2 特征选择
CRF标注算法中,特征选择以及特征函数的定义至关重要,直接关系到模型的性能。CRF模型的特征一般分为三类[22]:原子特征、复合特征以及全局变量特征,针对不同语料,选取的特征不同。选取词Word、词性(Part-Of-Speech,POS)、地理属性和农业本体概念作为特征。构建特征模板时,使用了对应的原子特征和复合特征,上下文特征窗口为5。
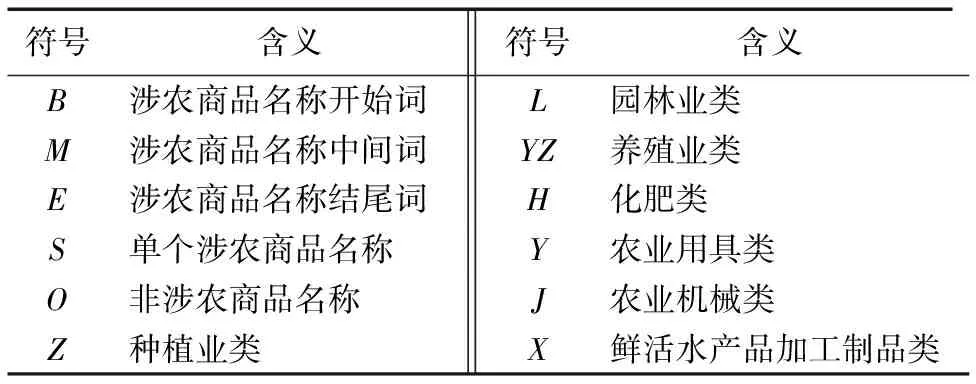
表1 序列标注符号含义
2.2.1 词
由于涉农商品名称具有领域性,有些词只在本领域流通,故词本身包含了最有效的信息,可作为特征。如“拖拉机”“玉米渣”“叶面肥”可作为农业领域的商品名称。
2.2.2 词性
词性特征指当前字符的词性,是涉农商品名称的一个重要特征,一般而言涉农商品名称为名词,复合名词,还包括部分动词。如“麦麸/n”“狼/n青犬/nz”“麦秆/n捡拾/v打捆机/n”可作为涉农商品名称。
2.2.3 地理属性
涉农商品名称中有些涉及到地理属性,如“山东开沟机”“河南特产玉米”“黑龙江大豆”。对于这类数据,应将其地理属性抽取出来,分词后词性标注为“ns”的表示地名,因此可很方便地将地理属性作为特征加入到CRF中。
2.2.4 农业本体概念
选取词在农业本体中所对应的概念作为CRF的一项特征,将词进行泛化,利用概念知识表示实例词,使词具有语义。共使用2种本体概念,一种是实例词在农业本体概念层次树中对应的叶子节点概念,特征表示为F0;另一种是实例词在本体中对应的上层概念,在此指去除叶子节点和根节点后所对应的概念,特征用F1表示。文中使用的农业本体概念如表2所示。如“菠萝莓”对应的叶子节点概念为“草莓”,对应的上层概念为“生鲜水果”和“种植业”。
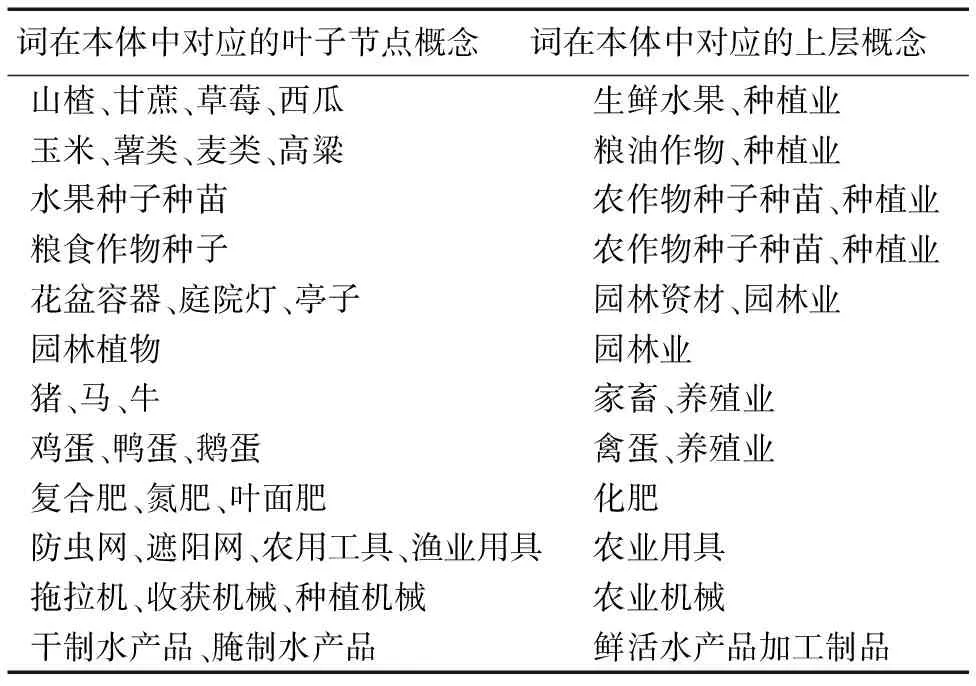
表2 词所对应的本体概念关系
词所对应的农业本体概念通过维护领域词典实现。而中国搜农网供求搜索栏目(http://www.sounong.net/)共搜集全国1万多个农业网站,拥有超过3万条农产品信息,实现了农产品到类别的映射,将该知识与阿里巴巴分类体系建立联系,实现涉农商品名称到概念的映射,降低人工维护领域词典的代价,提高自动化程度。图3表示词所对应的本体概念标注实现流程。
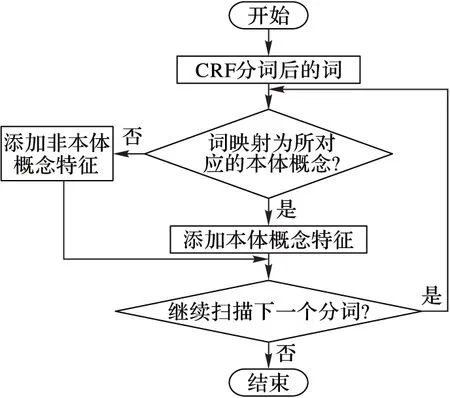
图3 词所对应的本体概念标注流程
3 实验及结果分析
3.1 实验评价指标
涉农商品名称抽取与类别标注的结果评价使用3个指标:准确率P、召回率R和F-值[23],公式表示如下:

(6)

(7)
(8)
3.2 基于CRF涉农商品名称抽取与类别标注
选取数据集中70%为训练数据,30%为测试数据,实现开放测试。实验分为4组,每组包括7大类,即种植业、园林业、养殖业、化肥、农业用具、农业机械和鲜活水产品加工制品。第1组选取词Word、词性POS、地理属性作为特征;第2组在前组的基础上,加入词在农业本体概念层次树中对应的叶子节点概念特征F0;第3组基于第一组实验的特征,直接加入词在农业本体中对应的上层概念特征F1;第4组在第3组实验特征基础上,添加特征F0。实验总体流程如图4所示。
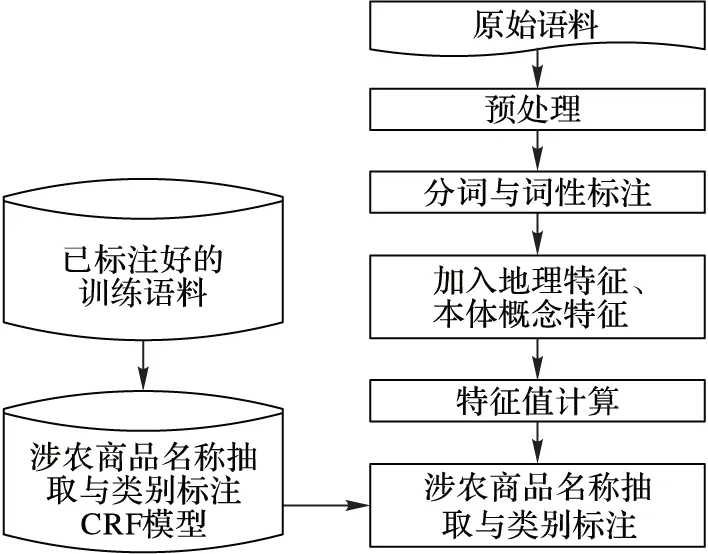
图4 实验总体流程
实验结果如表3所示,在第1组特征基础上,加入本体中对应的叶子节点特征F0,总的准确率P和召回率R上升;加入本体中上层概念特征F1,总体召回率大幅度地上升;同时使用F0和F1特征,准确率P高的同时也保证了召回率R高,总体F值达到92.32%,其中类别标记为化肥类的F值最高96.00%,园林业类的F值最低87.50%,表明基于本体与CRF相结合进行涉农商品名称的抽取与类别标注的方法是有效的。

表3 基于CRF实验结果 %
第1组实验错误主要有:名词组合“广西/ns产地亚/nz热带/n”“天山/ns牌/n”“上海/ns强力/n”“荷兰/ns 十五/nz”等提取为术语;“花卉/n”“磷肥/n”“滴灌管/n”“鲍鱼汁/nz”等未被正确识别;“玉米/nf./nz小麦/n”“现货/n鸵鸟蛋/nf”“爆款/nz低价/n香蕉/nf”“高产量/nz玉米/nf收割机/n”等作为一个整体抽取出来;养殖业、农业机械类的涉农商品名称如“比利时野兔”“山东开沟机”等错误抽取为种植业类。在大量新的涉农商品名称未被有效抽取与分类的前提下,保证准确率高,但召回率低,总体F值为68.30%。
第2组实验中,加入词在农业本体概念层次树中对应的叶子节点概念特征F0,减少了错误分类的概率,可将第1组实验中错误分类的部分名称正确抽取分类;同时削弱词Word、词性POS特征的权重,降低了将非涉农商品名称的名词组合错误识别为涉农商品名称的比率,但泛化能力较弱,对于新的涉农商品名称抽取与分类能力很差,准确率和召回率得到提升,总体F值为72.71%。
第3组直接使用农业本体中的上层概念特征F1,赋予词以概念知识,大大增强泛化程度,抽取出“菠萝”“浇花喷壶”“芝麻香油机”“鱿鱼干”等新词。通过学习样本,CRF模型表现出一定的“推理”能力,如将概念为生鲜水果的单独实例词抽取为种植业类的涉农商品名称,概念为粮油作物和种植机械的相邻实例词抽取为农业机械类的涉农商品名称等。最终召回率大幅度提升,总体F值达到90.64%。
第4组综合第2,3组实验的特征,使用更详细的特征和特征模板,准确率和召回率有所提升,总体F值为92.32%。其中园林业、养殖业类的F值与其他5类相比较低,主要是由于分词错误影响较大以及地理属性未被有效抽取,如将“樟子松木”分词为“樟子/n松木/n”,“河北小猪”抽取出“小猪”。表4列出了抽取的部分涉农商品名称以及标注的类别。
3.3 CRF与HMM、MEMM算法的比较
利用相同的数据集,选取上述第1组实验中词、词性、地理属性作为特征,分别利用CRF和HMM、MEMM完成开放测试,其中后两种算法采用机器学习语言工具包(MAchine Learning for LanguagE Toolkit, MALLET)[24]实现,MALLET是用于文本分类、主题建模和序列标注等的Java工具包,实验结果如表5。

表4 抽取的部分涉农商品名称及类别标注
表5 CRF与HMM、MEMM(词+词性+地理特征)的比较 %
Tab.5 Comparative results of CRF, HMM and MEMM based on word, part of speech and geographical attributes %
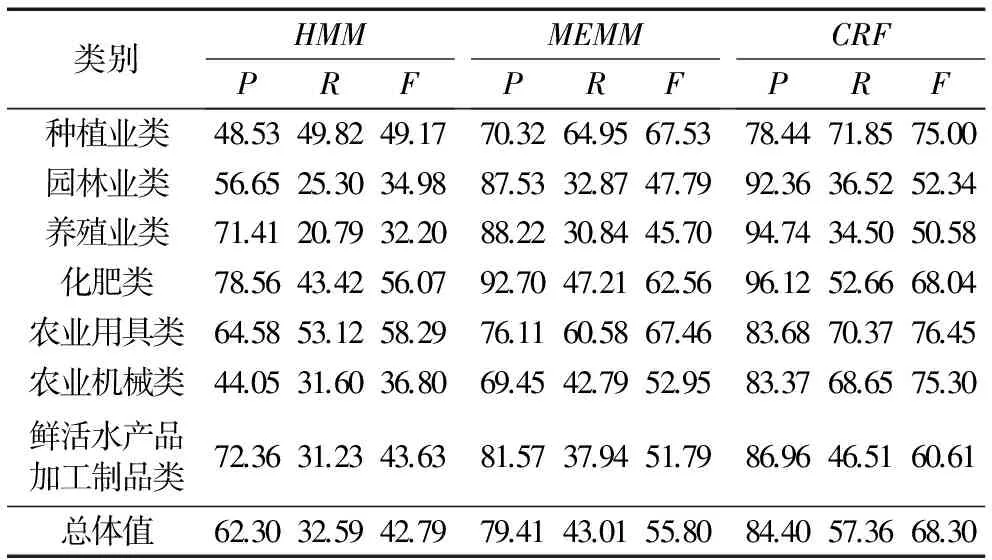
类别HMMPRFMEMMPRFCRFPRF种植业类48.5349.8249.1770.3264.9567.5378.4471.8575.00园林业类56.6525.3034.9887.5332.8747.7992.3636.5252.34养殖业类71.4120.7932.2088.2230.8445.7094.7434.5050.58化肥类78.5643.4256.0792.7047.2162.5696.1252.6668.04农业用具类64.5853.1258.2976.1160.5867.4683.6870.3776.45农业机械类44.0531.6036.8069.4542.7952.9583.3768.6575.30鲜活水产品加工制品类72.3631.2343.6381.5737.9451.7986.9646.5160.61总体值62.3032.5942.7979.4143.0155.8084.4057.3668.30
实验显示,CRF的性能优于HMM、MEMM。主要由于HMM为产生式模型,具有严格的输出独立性假设,不能充分利用上下文多特征信息,对于由3个及以上的词组成的涉农商品名称抽取效率差,如将“玉米小麦收割机”抽取为两个涉农商品名称“玉米”“小麦收割机”,容易出现类别识别错误;MEMM克服了HMM的缺点,但使用每一个状态的指数模型来计算给定前一个状态下当前状态的条件概率,容易陷入局部最优,存在标注偏置的问题;而CRF在所有特征上进行全局归一化,能得到全局最优解,避免了MEMM缺点。因此文中选取CRF抽取涉农商品名称与类别标注是有效的。
3.4 基于本体与CRF的农产品供求趋势分析
涉农商品名称及类别标注的有效抽取,不仅有助于促进农业供求交易的智能对接,而且可用于农业供求趋势分析,了解市场动态。利用中国搜农网供求搜索栏目抓取的网站数据作为原始数据,通过第4组实验的方法,抽取涉农商品名称及分类,图5(a)~5(d)表示2016年5月3日到6月6日连续5周内的供应求购趋势。由图5可知,四川省种植业类的商品求购量高于湖北省,两省在第5周都有大幅度的上升;河北省农业机械类的农产品周供应量较为平稳,而山东省在第5周时上升幅度大,达到591;山东省养殖业类的供应量远高于江苏省,而园林业的供应量则低于江苏省,反映出各地区农产品供应的差异性。根据这些供应求购趋势信息,买卖双方可依据地理位置,来选择适合的产品,更好地促成实时交易,如山东省的客户想购买玉米剥壳机,通过供应趋势图,则可就近选择较好的相关产品,给购买者提供方便。
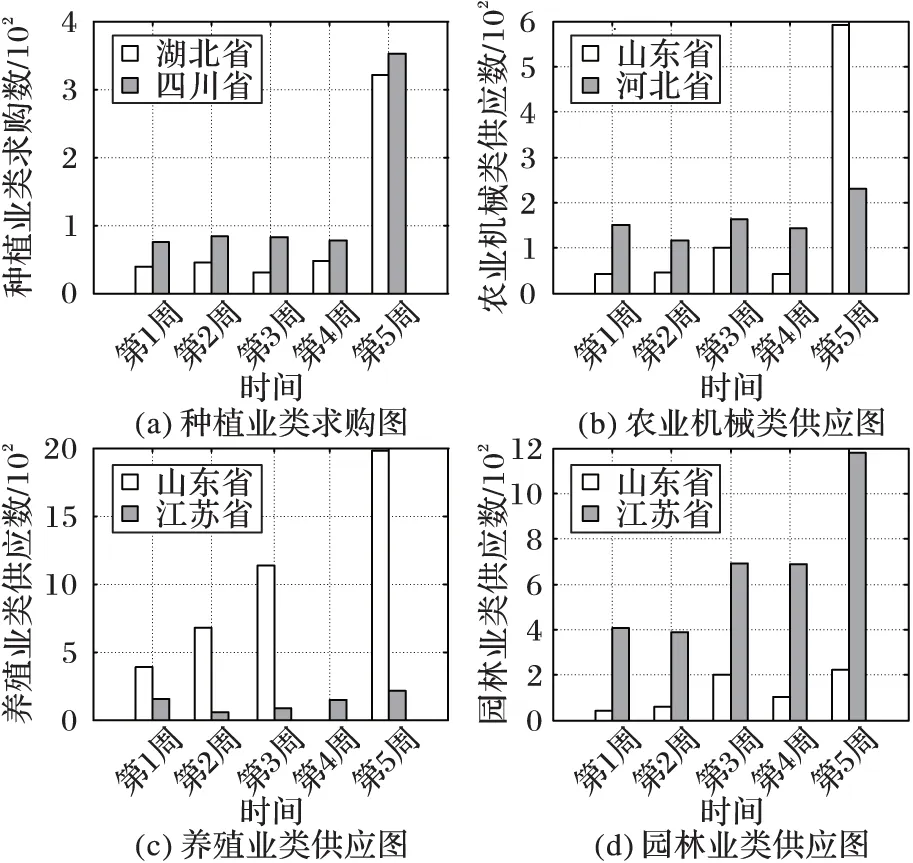
图5 各类供应求购趋势
4 结语
本文基于农业本体与条件随机场CRF相结合抽取涉农商品名称实现类别标记,在词、词性和地理属性特征基础上,自动添加词所对应的农业本体概念特征,对实例名称进行不同程度的泛化,赋予词以语义和概念知识。通过实验,在一定范围内,泛化程度越高,CRF模型表现出的“推理”能力越强,可有效地抽取测试语料中首次出现的涉农商品名称并分类,在准确率高的前提下,也保证了召回率,大量减少训练语料,降低人工工作量,与HMM、MEMM比较,体现出CRF的性能更优,并将此方法用于农产品供求趋势分析,可了解市场动态。原始语料以及分词工具的选取直接关系到CRF模型的性能,在今后的研究工作中,一方面将进行分词方法改进,选取不同的训练语料,进行CRF涉农商品名称抽取研究,进一步提升准确率和召回率,另一方面尝试从降低算法的复杂度入手,提高效率。
References)
[1] 于连军.基于互联网+的农业电子商务发展模式的研究[J].农业网络信息,2015(11):19-21.(YU L J.Research on the development model of agricultural E-commerce based on Internet+ [J].Agriculture Network Information, 2015(11): 19-21.)
[2] LI L S, DAND Y Z, ZHANG J, et al.Domain term extraction based on conditional random fields combined with active learning strategy [J].Journal of Information & Computational Science, 2012, 9(7): 1931-1940.
[3] GUAN A Q, WANG Y B, YANG L F.Automatic term extraction for Chinese opera domain ontology [C]// Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery.Piscataway, NJ: IEEE, 2015: 1372-1376.
[4] 宗成庆.统计自然语言处理[M].2版.北京:清华大学出版社,2013:110-128.(ZONG C Q.Statistical Natural Language Processing [M].2nd ed.Beijing: Tsinghua University Press, 2013: 110-128.)
[5] WALLACH H M.Conditional random fields: an introduction, technical report MS-CIS-04-21 [R].Philadelphia, PA: University of Pennsylvania, 2004: 262-272.
[6] FU W J, LI L.A method and application of automatic term extraction using conditional random fields [C]// Proceedings of the 2009 International Conference on Natural Language Processing and Knowledge Engineering.Piscataway, NJ: IEEE, 2009: 1-5.
[7] ZHANG C Z, WANG H L, LIU Y, et al.Automatic keyword extraction from documents using conditional random fields [J].Journal of Computational Information System, 2008, 4(3): 1169-1180.
[8] 孟洪宇.基于条件随机场的《伤寒论》中医术语自动识别[D].北京:北京中医药大学,2014:41-48.(MENG H Y.Automatic identification of TCM terminology in Shanghan Lun based on conditional random field [D].Beijing: Beijing University of Chinese Medicine, 2014:41-48.)
[9] ZHAN Q, WANG C H.A Hybrid strategy for Chinese domain-specific terminology extraction [C]// Proceedings of the 11th International Conference on Semantics, Knowledge and Grids.Piscataway, NJ: IEEE, 2015: 217-221.
[10] 王春雨.基于CRF的农业命名实体识别研究[D].保定:河北农业大学,2014:19-23.(WANG C Y.Study on recognition of Chinese agricultural named entity with CRF [D].Baoding: Agricultural University of Hebei, 2014: 19-23.)
[11] CAO Y S, WANG J, LI L.Word-level information extraction from science and technology announcements corpus based on CRF [C]// Proceedings of the 2nd IEEE International Conference on Cloud Computing and Intelligence Systems.Piscataway, NJ: IEEE, 2012: 1529-1533.
[12] IZUMI M, MIURA T, SHIOYA I.Estimating the date of blog authors by CRF [C]// Proceedings of the 2007 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing.Piscataway, NJ: IEEE, 2007: 249-252.
[13] GRUBER T R.A translation approach to portable ontology specifications [J].Knowledge Acquisition, 1993, 5(2): 199-220.
[14] 李传席.基于本体的自适应Web信息抽取方法研究[D].合肥:中国科学技术大学,2012:15-17.(LI C X.Adaptive Web information extraction method research based on ontology [D].Hefei: University of Science and Technology of China, 2012: 15-17.)
[15] LIU X G, DUAN X H, ZHANG H Y.Application of ontology in classification of agricultural information [C]// Proceedings of the 2012 IEEE Symposium on Robotics and Applications.Piscataway, NJ: IEEE, 2012: 451-454.
[16] 周晶,吴军华,陈佳,等.基于条件随机域CRF模型的文本信息抽取[J].计算机工程与设计,2008,29(23):6094-6097.(ZHOU J, WU J H, CHEN J, et al.Using conditional random fields model for text information extraction [J].Computer Engineering and Design, 2008, 29(23):6094-6097.)
[17] LAFFERTY J, MCCALLUM A, PEREIRA F.Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings of the 18th International Conference on Machine Learning.San Francisco, CA: Morgan Kaufmann, 2001: 282-289.
[18] Sunfox66.条件随机场详解[EB/OL].(2015-10-25)[2016-01-17].http://wenku.baidu.com/view/bbd57f82fc4ffe473268ab59.html.(Sunfox66.Conditional random field introduction [EB/OL].(2015-10-25)[2016-01-17].http://wenku.baidu.com/view/bbd57f82fc4ffe473268ab59.html.)
[19] LIU D, NOCEDAL J.On the limited memory BFGS method for large scale optimization [J].Mathematical Programming, 1989, 45(45): 503-528.
[20] TAKU K.CRF++ toolkit [EB/OL].(2014-10-15)[2016-01-15].http://download.csdn.net/detail/linson3344/8039087.
[21] HANKCS.Han language processing [EB/OL].(2015-03-27)[2016-01-28].http://www.hankcs.com/nlp/hanlp.html.
[22] 施水才,王锴,韩艳铧,等.基于条件随机场的领域术语识别研究[J].计算机工程与应用,2013,49(10):147-149.(SHI S C, WANG K, HAN Y H, et al.Terminology recognition based on conditional random fields [J].Computer Engineering and Applications, 2013, 49(10): 147-149.)
[23] 贾美英,杨炳儒,郑德权,等.采用CRF技术的军事情报术语自动抽取研究[J].计算机工程与应用,2009,45(32):126-129.(JIA M Y, YANG B R, ZHENG D Q, et al.Research on automatic military intelligence term extraction using CRF model [J].Computer Engineering and Applications, 2009, 45(32): 126-129.)
[24] MCCALLUM A K.MALLET: a machine learning for language toolkit [EB/OL].(2002-02-28)[2016-02-25].http://mallet.cs.umass.edu.
This work is partially supported by the National Science and Technology Support Program (2013BAD15B03), Chinese Academy of Sciences Key Deployment Project (Y622A21291), the Scientific and Technological Project of Anhui Province (1401032010).
HUANG Nian’e, born in 1991, M.S.candidate.Her research interests include information extraction, vertical search engine.
HUANG He, born in 1980, Ph.D., associate professor.His research interests include agriculture big data, agricultural intelligent system.
WANG Rujing, born in 1964, Ph.D., professor.His research interests include knowledge representation and visualization, knowledge acquisition.
Agriculture-related product name extraction and category labeling based on ontology and conditional random field
HUANG Nian’e1,2, HUANG He1*, WANG Rujing1
(1.InstituteofIntelligentMachines,ChineseAcademyofSciences,HefeiAnhui230031,China;2.HefeiInstituteofPhysicalScience,UniversityofScienceandTechnologyofChina,HefeiAnhui230027,China)
Traditional information extraction method based on Conditional Random Field (CRF) requires large-scale labeled corpus, it is expensive to label corpus manually and the extraction precision is low in processing agriculture-related product name extraction and category labeling.In order to solve this problem, a method of agriculture-related product name extraction and category labeling based on agricultural ontology and CRF was proposed, automatic extraction and classification of agriculture-related product names was regarded as sequence labeling.Firstly, original data was processed, word, part of speech, geographical attributes and ontology concept features were selected.Then, parameters of the CRF model were trained by the improved quasi-Newton algorithm and decoding was implemented by Viterbi algorithm.A total of four groups of comparative experiments were completed and seven categories were identified.CRF, Hidden Markov Model (HMM) and Maximum Entropy Markov Model (MEMM) were compared through experiments.Finally, the supply and demand trend analysis of agriculture produce was accomplished.The experimental results show that the overall precision, recall andF-score of the open test were increased by 10.20%, 59.78% and 37.17% respectively by adding ontology concepts with appropriate CRF features; it also proves the feasibility, effectiveness and practical significance of the method in promoting automatic supply and demand docking of agricultural products.
Conditional Random Field (CRF); agricultural ontology; agriculture-related product name; supply and demand trend;sequence labeling
2016-08-02;
2016-09-19。
国家科技支撑计划项目(2013BAD15B03);中国科学院重点部署项目(Y622A21291);安徽省科技攻关项目(1401032010)。
黄念娥(1991—),女,安徽安庆人,硕士研究生,主要研究方向:信息抽取、垂直搜索引擎; 黄河(1980—),男,安徽合肥人,副研究员,博士,主要研究方向:农业大数据、农业智能系统; 王儒敬(1964—),男,安徽亳州人,研究员,博士,主要研究方向:知识表示与可视化、知识获取。
1001-9081(2017)01-0233-06
10.11772/j.issn.1001-9081.2017.01.0233
TP391.1; TP18
A
