基于轨迹结构的移动对象热点区域发现
2017-04-17吕绍仟孟凡荣
吕绍仟,孟凡荣,袁 冠
(中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
(*通信作者电子邮箱shaoqianlv@cumt.edu.cn)
基于轨迹结构的移动对象热点区域发现
吕绍仟*,孟凡荣,袁 冠
(中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
(*通信作者电子邮箱shaoqianlv@cumt.edu.cn)
针对现有热点区域发现算法难以从轨迹数据集中准确识别活动热点的问题,提出了基于轨迹结构的热点区域发现框架(TS_HS)。TS_HS由候选区域发现(CHSD)算法和热点区域过滤(HSF)算法组成。首先,使用基于网格相对密度的CHSD识别空间上的轨迹密集区域作为候选热点区域;然后,利用HSF根据候选区域中轨迹的活动特征和时间变化特征,筛选出移动对象活动频繁的热点区域。在Geolife数据集上进行的实验表明,与基于全局密度的热门区域发现算法(GD_HR)以及移动轨迹时空热点区域发现算法(SDHSRD)相比,TS_HS能更有效地解决多密度热点区域的识别问题。实验结果表明,TS_HS能够根据轨迹的活动特征准确发现移动对象的活动热点区域。
移动对象;轨迹结构;热点区域;轨迹数据;数据挖掘
0 引言
近年来,随着GPS(Global Positioning System)设备、卫星和无线传感网络[1-3]等定位技术的快速发展,以及信号处理[4-6]等相关研究的不断推进,使得全球范围内的各种移动对象都可以得到有效跟踪,由此越来越多的移动对象轨迹数据被收集并存储在数据库中。这些轨迹数据蕴含了大量有价值的信息,迫切需要深入、有效地分析。这些分析结果在诸如导航、基于位置社交服务、位置相关的广告以及智能交通等领域有着广泛的应用。
移动对象的原始轨迹数据通常是由〈Location,t〉形式的采样点组成的序列,其中Location是一个2维或3维的点,表示移动对象在t时刻的位置。这些采样点是定位设备以相对固定频率采集得到。轨迹数据是移动对象的活动在时空维度上的表达,因此分析轨迹可以挖掘出移动对象的行为特征。移动对象活动的热点区域发现是轨迹数据挖掘的一个重要分支,以热点区域为基础可以将对象的活动轨迹转化为活动区域序列,从中挖掘出移动对象活动的关联规则[7]、频繁模式[8]等有价值信息。此外热点区域也能直接被应用,例如作为交通的有效参考信息,通过发布某一时段的热点区域可以指导司机避开这些区域,从而达到缓解交通拥塞的目的。
研究人员针对移动对象活动热点区域的识别展开了广泛而深入的研究,提出了基于密度的方法[9]、基于停留点的方法[10-13]以及基于网格的方法[14-15]。尽管现有算法能够较为有效地发现活动空间上的重要位置,但是还存在以下问题:
1)无法区分多密度的活动热点区域。热点区域是相对的概念,通过全局的密度阈值难以区分具有不同密度的热点区域。例如将城市与周围的村庄相比,城市是相对密度较高的热点区域;而将城市内部的中央商务区(CentralBusinessDistrict,C)和郊区的住宅区相比,CBD是活动热点区域而住宅区不是。现有研究大多采用基于全局密度阈值的聚类算法来检测热点区域,无法解决多密度热点区域的识别问题。
2)忽略了区域热度随时间变化的特性。区域热度衡量了一段时间内移动对象活动的频繁程度,随着时间的推移区域热度会不断变化。以滑雪场为例,在每年的冬季通常会有较多的游客来滑雪,所以可以将其视为冬天的一个热点区域;但以识别一年里的移动对象热点区域为目标时,滑雪场就应该被排除,因为滑雪场在除了冬天外以外的大部分时间很少有人活动。
3)无法准确发现活动密集区域。现有研究大多关注的是发现空间上的轨迹密集区域,但轨迹密集区域并不等同于热点区域,轨迹密集是活动密集的必要不充分条件。以地铁站为例,地铁站每天都有大量行人经过,所以必然是轨迹密集区域。但将其视为一个活动区域并不合理,地铁站是移动对象的必经区域,这里的轨迹通常是速度较快、方向固定的,并不满足活动轨迹的特征。因此需要对于轨迹密集区域中的轨迹作进一步分析,以确定该区域是否为活动热点区域。
在活动区域中,移动对象的运动呈现低速、无规则性,这些活动特点间接地反映在轨迹结构中,轨迹结构的概念由袁冠等[16-17]率先提出。轨迹并不是单纯的采样点序列,轨迹还蕴含了丰富的信息,如速度、形状、转角、加速度等,这些特征为移动对象的活动分析提供了重要意义。通过对轨迹结构的分析可以发现更有意义的活动区域,而不仅仅是轨迹密集区域。
为了解决多密度轨迹数据中的移动对象活动热点区域的发现问题,本文提出了基于轨迹结构的移动对象热点区域发现框架(TrajectoryStructure-basedHotspotsDiscovery,TS_HS),图1为TS_HS的框架。TS_HS由候选热点区域发现(CandidateHotspotsDiscovery,CHSD)算法和热点区域过滤(HotspotsFilter,HSF)算法组成。首先通过CHSD识别空间上的轨迹密集区域,这些区域都是潜在的活动密集区域,称之为候选热点区域。HSF对候选区域进一步过滤,根据轨迹的结构特征计算区域的热度,从候选区域集中筛选出活动热点区域。
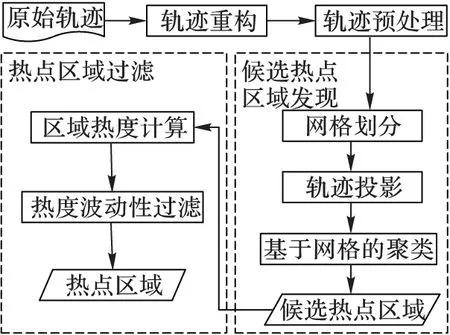
图1 TS_HS框架
1 相关研究
目前在轨迹挖掘领域中有较多热点区域发现相关的工作,根据轨迹数据的时间属性可以分为同步区域和异步区域。同步区域是指从移动对象同步运动的轨迹上发现的热点区域,其主要任务是发现轨迹数据集中某一时刻上的移动对象活动密集区域。Hadjieleftheriou等[18]306-315提出轨迹密度的概念,轨迹密度是单位面积上经过的轨迹数量,并根据轨迹密度从空间中发现当前热点区域。Jensen等[19]提出了二维的密度直方图以及基于离散余弦变换的压缩形式,进一步提高了查询的效率。Verhein等[20]进一步考虑了密度的变化,拓展定义了大交通区域和稳定区域。
异步区域是指从历史轨迹中识别出的热点区域。轨迹数据集的特征是不尽相同的,有些数据集中轨迹在空间上具有高度的重叠性,但是在时间上却有较大的偏差,因此难以找到明显的周期性规律,同步热点区域识别的方法难以应用于此类数据集中。异步区域的发现是目前研究普遍关注的问题。
利用聚类算法可以有效地从历史轨迹中自动识别活动热点区域。Ashbrook等[21]通过K-means聚类算法挖掘轨迹数据中的重要地点,运用K-means算法的难点是需要预先确定簇的数量。为了识别单个用户活动的热点区域,Zhou等[12]4-7提出了基于密度和连接的聚类(Density-and-Join-based Cluster,DJ-Cluster)算法,类似于DBSCAN(Density-Based Spatial Clustering of Applications with Noise),DJ-Cluster算法也是基于邻近点之间的连通性。Palma等[22]提出了基于速度的时空聚类方法,用于识别单条轨迹上的移动对象停留点,并可以有效解决诸如进入建筑导致采样点丢失等问题。
机器学习和统计学的方法也已被应用于热点区域的识别。Khetarpaul等[13]将关系代数和统计学方法相结合,用于评价位置点的热门程度;Liao等[23-24]使用机器学习和概率推理的方法从GPS中识别出移动对象的日常活动。这类方法在检测和评价重点位置、寻找热点区域等方面有较好性能。
停留点(Stops)是热点区域识别领域的一个重要概念,由Alvares等[25]提出。停留点是指移动对象停留时间较长的区域。在停留点检测的基础上,Zheng等[10]791利用层次聚类算法识别空间中的热门区域,然后挖掘出移动对象的频繁活动序列等知识。同样是基于停留点,Cao等[11]使用两层图模型对移动对象和位置之间的关系建模,从而识别出空间上前K个热点区域。这类算法需要耗费较多的时间用于检测停留点,此外阈值选择得是否合理也很大程度上影响了算法的效果。
Giannotti等[14]331-339提出了基于网格的热点区域发现算法。先将移动对象的活动空间分割为较小的子区域,然后每条轨迹投影到子区域上,最后使用基于网格的聚类算法合并相邻的密集子区域来得到最终的热点区域。为了解决文献[14]中存在的大区域问题,刘奎恩等[15]提出了基于趋势以及基于差异度的区域重构算法,能够从热点区域中识别出更加具有代表性的区域。王亮等[27]913将随机采样移动轨迹数据在时间轴上进行投影转换得到对应的时间投影数据集,然后采用自底向上和滑动时间窗口相结合的策略以提取密集时间区间,最后采用网格划分技术识别各个密集时间区间上的热点区域,进而以识别的热点区域为基础进行移动对象的行为模式发现。
2 候选热点区域发现
轨迹密集是活动密集的充分不必要条件,HS_TS的基本思想是利用CHSD算法从轨迹数据中识别出轨迹密集区域作为候选区域,然后根据轨迹活动特征进一步过滤。
2.1 候选热点区域发现算法
CHSD用DBSCAN聚类算法识别空间上轨迹较密集、形状任意的候选热点区域。将DBSCAN算法应用于轨迹数据需要解决两个问题:1)时间复杂度高;2)无法识别多密度簇。
假设轨迹点的数量是np,DBSCAN算法的时间复杂度为O(np2),轨迹数据集中的轨迹点数量以千万计,因此DBSCAN难以直接应用于轨迹数据上。CHSD算法通过网格划分技术解决候选区域识别时间复杂度较高的问题,定义1给出了网格划分的形式化定义。
定义1 网格划分。给定一个d维数据集D={D1,D2,…,Dd},其中属性Di都是有界的,取值区间为[li,hi),i=1,2,…,d,则[l1,h2)×[l1,h2)×…×[ld,hd)就是一个d维数据空间S。可以将S的第i维划分成Ni个不相交的左闭右开区间,从而将整个数据空间划分成∏Ni个不相交的超矩形单元,每个单元称之为一个单元格,记为C。
将移动对象活动的2维空间进行网格划分,每个单元格保存落在其内部的轨迹概要信息,然后以单元格为对象进行聚类。这么处理的一个优点是处理速度快,算法的时间复杂度是轨迹点个数的线性函数,并且有利于算法实现增量处理。
基于密度的聚类算法依赖于一个全局的密度阈值,导致无法有效识别多密度的簇。利用DBSCAN对图2所示的数据集进行聚类,无法同时检测到密集区域A、B、C1、C2和C3。较低的密度阈值只能检测到密集区域A、B、C;较高的密度阈值只能检测到C1、C2、C3。

图2 多密度数据集聚类示意图
本文使用基于网格相对密度的聚类算法[26]解决多密度数据集上候选热点区域识别的问题。定义2~7是基于网格相对密度的聚类算法的相关定义。
定义2 单元格密度。用经过单元格Ci的轨迹数量来表示Ci的单元格密度,记为d(Ci)。
定义3 邻接单元格。当且仅当Ci和Cj有相邻的边界或者相邻点时,Ci和Cj是邻接单元格。记Ci的所有非空邻接单元格集合记为Ngs(Ci)。
定义4 单元格相对密度。Ci的单元格密度与邻接非空单元格的密度均值之比称之为Ci的单元格相对密度,记为rd(Ci)。
定义5 核心单元格。给定相对密度阈值δrd,一个单元格Ci是核心单元格,当且仅当满足不等式(1):
rd(Ci)≥δrd
(1)
rd(Ci)足够大意味着Ci密度远大于周围单元格,这些单元格通常是热点区域的中心。
定义6 直接密度可达。如果非空单元格Ci是非空单元格Cj的邻接单元格,并且满足不等式(2):
1/k≤d(Ci)/d(Cj)≤k
(2)
则称Ci直接密度可达Cj。k是预先设定好的波动系数。直接密度可达是对称的,因此如果Ci直接密度可达Cj,那么Cj也直接密度可达Ci。
定义7 密度可达。如果存在一个单元格序列C1,C2,…,Cn满足C1=C,Cn=C′,并且Ci直接密度可达Ci+1,则称C密度可达C′。
由核心单元格开始,CHSD算法通过不断合并邻接的密度可达单元格,得到最终的候选热点区域集合。
2.2 算法步骤
算法1是CHSD算法的具体步骤。
算法1CHSD(CandidateHotspotsDiscovery)。
输入:网格G,单元格宽度w,核心单元格阈值δrd,浮动系数k。 输出:候选热点区域CH。 /*步骤1:网格的划分与轨迹投影*/
1)
根据w初始化网格G
2)
根据定义2将轨迹投影到网格G/*步骤2:单元格相对密度计算与核心单元格发现*/
3)
初始化核心单元格列表coreCells;
4)
Foreachcellc∈G
5)
rd← CalRelatvieDensity(c);
//定义4
6)
If(rd > δrd)
//定义5
7)
coreCells.add(c); /*步骤3:拓展核心单元格,将与其密度可达的单元格标记上相同的标号*/
8)
labelcount← 1;
9)
Foreachcellcc∈coreCells
10)
If(cc.label=0)
11)
candidateHotspot← Extend(g,cc,label,k);//定义7
12)
CH.add(candidateHotspot);
13)
labelcount←labelcount+1;
14)
returnCH;
步骤1 网格划分与轨迹投影。首先使用参数w初始化网格G,然后将轨迹投影到经过的单元格中。
步骤2 寻找核心单元格。依次计算每个单元格的相对密度,如果单元格的相对密度大于δrd,则将该单元格加入到核心单元格集合coreCells中。
步骤3 拓展核心单元格。迭代处理coreCells中的每个核心单元格,如果单元格的标号不为0,说明该单元格已经被合并到其他候选区域中,跳过处理。否则分配一个新的标号,使用Extend方法将与之密度相连的所有单元格加入同一个候选区域中,并将拓展得到的候选区域加入到结果集中。
设轨迹数量为nt,单元格数量为nc,CHSD通过遍历将轨迹投影到网格中的时间复杂度为O(nt)。以单元格为基本单位进行聚类的时间复杂度为O(nc)。通常nt远大于nc,所以CHSD算法的时间复杂度趋近于O(nt)。
3 热点区域过滤
CHSD算法只考虑了轨迹的数量特征,而没有考虑到轨迹的结构特征。TS_HS框架在第二阶段使用HSF算法对候选热点区域作进一步筛选,以候选区域内移动对象的轨迹运动特征为依据,过滤出活动密集的热点区域。
3.1 区域热度计算
要从轨迹密集的候选区域中进一步筛选出活动密集区域,首要问题是如何量化表示区域活动的热门程度。定义8形式化描述了区域热度的计算问题。
定义8 区域热度。给定区域S、时间段Δt和这段时间内经过区域S的轨迹集合TD,那么区域S在Δt时间段内的区域热度P可以用式(3)表示:
P=F(TD)
(3)
其中F是区域热度计算函数。F函数的定义决定了区域热度能否客观反映对象的活动特征。例如文献[18]中使用轨迹密度作为区域热度,计算方法如式(4)所示:
Pdensity=|TD|/Area(S)
(4)
其中:Area(S)是区域S的面积,|·|表示有限集合的计数操作。如前文所述,轨迹密度不能反映移动对象的活动特点,因此Pdensity难以准确表达区域热度。移动对象的活动体现在轨迹的结构特征中,本文提取轨迹的停留时间、转角次数、对象覆盖率这三个重要特征来概括对象活动的特点。
停留时间 候选区域内移动对象的停留时间越长,发生活动的可能性就越大,区域的热度也就越高。本文以每条轨迹的停留时间avgTime来表示在区域S内移动对象活动的时间特征,记为式(5):
(5)
其中si表示经过S的第i条轨迹在S内停留的时间。
转角次数 热点区域内移动对象普遍存在运动无规则的特征,最明显体现就是转角次数多。本文以每条轨迹的转角次数avgCorner来量化区域内的轨迹转角特征。avgCorner的计算方法如式(6)所示:
(6)
其中ci表示经过S的第i条轨迹在区域S内的转角次数。
对象覆盖率 热点区域的一个重要特征是能够吸引大量不同的对象。本文定义区域S上经过的人数占总人数的比率为区域S的对象覆盖率objRatio,记为式(7)。以对象覆盖率来衡量区域对所有对象的吸引程度,热点区域通常是对象覆盖率较高的公共活动区域。
objRatio=|US|/|UTD|
(7)
UTD表示轨迹数据集TD中的用户集合,US表示区域S内出现的用户集合。objRatio最大值为1.0,表示所有用户都路过了区域S。
通过上述轨迹结构的概括特征,可以有效地度量候选区域内移动对象活动的热度。式(8)给出了基于轨迹结构特征的区域热度(Trajectory Structure based Popularity Measurement, TS_PM)计算方法:
(8)
其中:max(avgTime)和max(avgCorner)表示所有候选区域中,avgTime和avgCorner的最大值。
3.2 基于时间过滤的热点区域
热点区域是移动对象长时间频繁活动的区域,计算整体时间热度来判断热点区域的方式忽略了区域热度随时间变化的特征。本文将整体时间划分成较小的时间段,依次计算每个时间段内的区域热度,最后以频繁活动的时长为依据进行热点区域的过滤。为了形式化定义热点区域,本文首先给出区域历史热度的定义。
定义9 区域历史热度。给定时间段[TS,TE],将其划分成等长的n个时间段T1,T2,…,Ti,…,Tn(1≤i≤n),Pi为区域在Ti时间段内的区域热度,那么区域热度历史PH是时间段[TS,TE]内的热度集合,即PH={Pi|1≤i≤n}。
区域历史热度反映了活动热度变化特性,在区域历史热度的基础上,本文形式化地定义移动对象活动热点区域。
定义10 热点区域。给定区域S的历史热度PH={Pi|1≤i≤n}、区域热度阈值δP和时长阈值δT,如果不等式(9)成立:
(9)
那么区域S就是一个热点区域。其中time(Pi)表示Pi对应的时间段,Sub(PH)是PH的一个子集,满足式(10):
Sub(PH)={Pi|Pi∈PH,Pi≥δP}
(10)
热点区域是满足热度阈值δP的总时长不小于δT的候选区域,这就保证了识别出的热点区域是轨迹密度相对较高、对象活动特征明显,并且活动时间较长的区域。
3.3 算法步骤
算法2是热点区域过滤算法HSF的具体步骤。
算法2HSF(HotspotsFilter)。
输入:网格G,候选区域集合CH,开始时间TS,结束时间TE,时间间隔tv,区域热度阈值δP,时间阈值δT。 输出:热点区域HR。
1)
根据tv将时间区间[TS,TE]划分成等长的时间集合TN
2)
ForeachchinCH
3)
activityTime← 0;
4)
ForeachtninTN
5)
P← CalPopularity(G,tn,ch);
//式(8)
6)
IfP≥δP
7)
activityTime←activityTime+tv;
//定义10
8)
IfactivityTime≥δT
9)
HR.add(ch)
10)
ReturnHR
对于每个候选区域,HSF调用CalPopularity方法计算每个时间段内的区域热度。CalPopularity通过查询候选区域内每个单元格中的轨迹结构信息来计算区域热度值,轨迹的结构信息在算法1的轨迹投影阶段已预先计算并保存到了相关的单元格中。变量activityTime记录候选区域的高活动热度时长,当activityTime满足时间阈值δT时,将当前候选区域添加到结果集HR中。
设单元格数量为nc,时间被划分为s段,HSF算法的最坏时间复杂度为O(nc*s),也就是每个单元格都在候选区域中的时候。
4 实验
本实验在真实的Geolife数据集进行,Geolife数据集包含了182个移动对象在5年中的活动轨迹,总计17 621条轨迹,总长度超过129×104km。本文对轨迹主要分布的北京地区(39.8°N~40.05°N,116.30°E~116.50°E)进行热点识别,该区域内轨迹分布密度如图3所示。
4.1 候选热点区域发现
将移动对象活动区域划分为125行100列的网格,划分之后的单元格尺寸为0.002°×0.002°,然后将轨迹投影到网格中。为了验证CHSD算法的效果,本文与文献[14-15]中使用的基于全局密度的热门区域发现(GlobalDensitythresholdbasedHotRegiondiscovery,GD_HR)算法以及文献[27]中的移动轨迹时空热点区域发现(Spatio-tempaoralHotSoptRegionDiscovering,SDHSRD)算法进行对比。他们的研究与本实验所关注的轨迹密集区域具有相似性和可比性,都通过网格划分减少计算量,并且都通过密度阈值来判断网格是否为轨迹密集区域。不同的是GD_HR采用基于全局密度阈值的聚类算法挖掘空间中的密集轨迹区域,SDHSRD则根据全局的密度阈值直接过滤出高密度的网格作为热点区域。通过GD_HR、SDHSRD和CHSD算法检测出的候选区域如图4所示。其中:图4(a)、图4(b)、图4(c)是使用SDHSRD算法发现的候选区域,密度阈值δd的分别取前1.5%、5.0%和8.0%处的密度值;图4(d)和图4(e)为GD_HR算法识别出的轨迹密集区域,密度阈值δd分别为前1.5%和5%处的密度阈值;图4(f)是CHSD算法的实验结果。
图3 北京地区轨迹密度分布

图4 候选热点区域
对比图4(a)、图4(b)和图4(c)所示可知,SDHSRD通过调整密度阈值无法区分不同密度的密集轨迹区域,并且会产生很多密度高面积小的小热点区域。同样采用全局密度阈值的GD_HR算法依旧无法解决多密度识别的问题,结果如图4(d)和图4(e)所示。但是通过合并操作可以克服小区域产生。由于不断的合并会导致热点区域更大,这种大区域难以应用于轨迹模式识别等挖掘任务。CHSD则能够很好地区分开不同密度的区域,并且不存在大区域或者小区域的问题,聚类结果如图4(f)所示。
表1是SDHSRD、GD_HR和CHSD聚类结果的综合比较,RegionNum表示候选区域数量,SmallNum表示小区域(网格数小于5的区域)的数量,AvgSize为候选区域的平均大小,Multi-Density表示是否能区分开多密度候选区域。
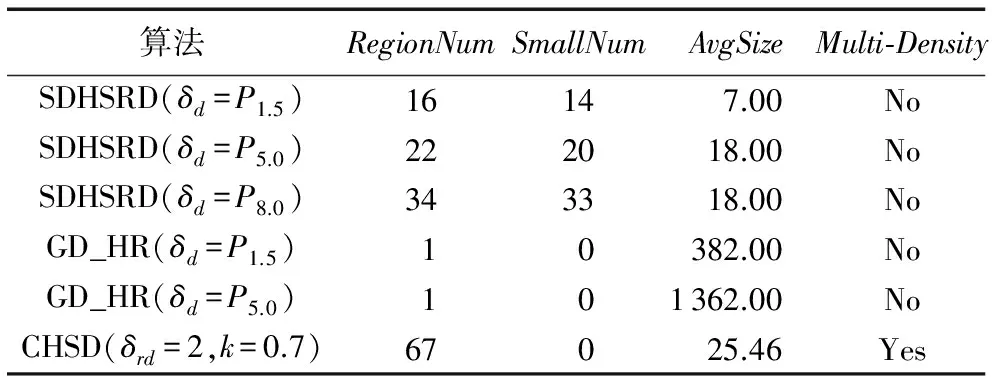
表1 候选区域效果对比
从表1中可以看出,当δd不断减小时,SDHSRD热点区域中的平均区域大小变化不大,但这是由于大区域越来越大、小区域越来越多共同导致的,这两类区域的存在对于后续研究的开展都是极为不利的。小区域的问题在GD_HR中得到了有效解决,只要平均密度不大于δd,GD_HR就不断合并邻接的单元格,密度较高的小区域因此被合并到邻近的大区域中。这也会导致不同密度的簇由于相邻而被合并,因此GD_HR也无法区分多密度的候选区域。CHSD通过计算相对密度避免了不同密度的区域因为邻接而被合并,识别出的候选区域更小、数量更多,这种紧凑的热点区域对需要精确表达轨迹模式的应用至关重要。
4.2 热点区域过滤
4.2.1 区域热度计算方法的验证
以图4(f)所示的候选热点区域为基础,本文通过实验进一步验证基于轨迹结构的区域热度计算方法TS_PM的有效性。图5是编号为#56和#76的两个候选热点区域内的轨迹统计信息。为了便于展示,每个属性都作了归一化处理。
从图5中可以看出,#56区域的轨迹密度(trajDensity)虽然较低,但是通过轨迹的结构特征可以认为该候选区域很可能是一个移动对象的活动区域,无论是移动对象活动的时间、转角次数还是对象覆盖率上都更符合活动区域特点。候选区域#76虽然轨迹密度较高,但是轨迹的活动特征不明显,表明#76可能只是交通路口等必经地。以轨迹结构为基础计算得到的区域热度很好地反映了两个候选区域中移动对象活动的差异。
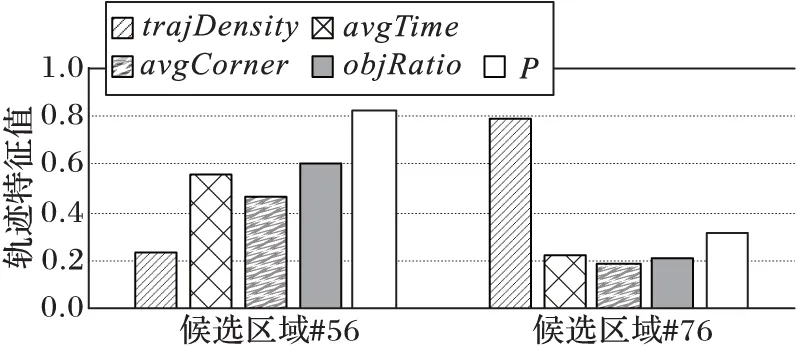
图5 候选区域轨迹结构特征对比
4.2.2 基于时间过滤的有效性验证
图5计算的是候选区域在总体时间内的区域热度,为了进一步验证对候选区域进行时间过滤的必要性,本文选取两个整体区域热度很接近的候选区域#73和#19,其整体区域热度分别为1.09和1.13。以月为时间间隔分别统计这两个候选区域的历史热度,结果如图6所示。
从图6可知,虽然两个热点区域的整体区域热度十分相近,但是历史热度区别明显。候选区域#73在2007年10月到2008年4月以及2010年12月到2011年6月这段时间内有明显的移动对象活动特征,除此之外的其他时间段内都没有频繁的移动对象活动;而候选区域#19的移动对象活动较为平稳,表明这是一个较长时间内的稳定活动区域。
对图4(f)中的候选区域进行筛选,设置区域热度阈值δP=1.0、时间阈值δT=50%,得到图7所示的北京热点区域分布。
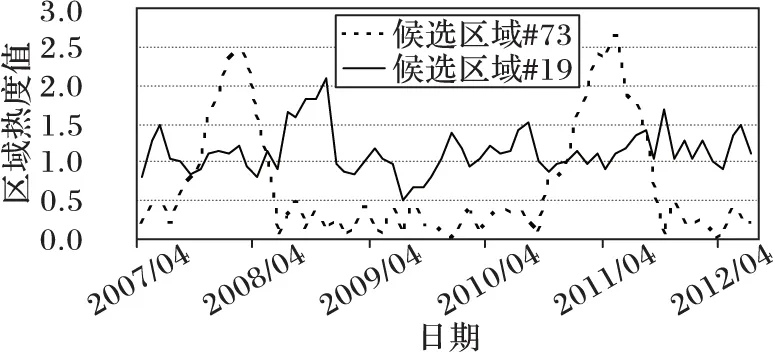
图6 候选区域历史热度对比

图7 北京地区热点区域
5 结语
本文提出了基于轨迹结构的移动对象活动热点区域识别框架——TS_HS。TS_HS框架由CHSD算法和HSF算法两部分组成。CHSD算法首先对空间进行网格划分与轨迹投影,然后利用多密度网格聚类识别活动空间上的轨迹密集区域作为候选热点区域。在热点区域过滤阶段,提出了基于轨迹结构的区域热度计算方法来度量候选区域中移动对象的活跃程度,并根据区域热度的时间变化特性过滤出最终的热点区域。通过在Geolife数据集上进行的实验,从多个角度验证了本文提出的TS_HS框架的有效性。
)
[1]WEIW,QIY.InformationpotentialfieldsnavigationinwirelessAd-Hocsensornetworks[J].Sensors, 2011, 11(5): 4794-4807.
[2]WEIW,XUQ,WANGL,etal.GI/Geom/1queuebasedoncommunicationmodelformeshnetworks[J].InternationalJournalofCommunicationSystems, 2014, 27(11): 3013-3029.
[3]WEIW,YANGXL,SHENPY,etal.Holesdetectioninanisotropicsensornets:topologicalmethods[J].InternationalJournalofDistributedSensorNetworks, 2012, 8(10): 135054.
[4]SONGH,BRANDT-PEARCEM.A2-Ddiscrete-timemodelofphysicalimpairmentsinwavelength-divisionmultiplexingsystems[J].JournalofLightwaveTechnology, 2012, 30(5): 713-726.
[5]SONGH,BRANDT-PEARCEM.Rangeofinfluenceandimpactofphysicalimpairmentsinlong-haulDWDMsystems[J].JournalofLightwaveTechnology, 2013, 31(15): 846-854.
[6]SONGH,BRANDT-PEARCEM.Model-centricnonlinearequalizerforcoherentlong-haulfiber-opticcommunicationsystems[C]//GLOBECOM2013:Proceedingsofthe2013IEEEGlobalCommunicationsConference.Piscataway,NJ:IEEE, 2013: 2394-2399.
[7]JEUNGH,LIUQ,SHENHT,etal.Ahybridpredictionmodelformovingobjects[C]//Proceedingsofthe2008IEEEInternationalConferenceonDataEngineering.Piscataway,NJ:IEEE, 2008: 70-79.
[8]YANGJ,HUM.TrajPattern:miningsequentialpatternsfromimprecisetrajectoriesofmobileobjects[M]//EDBT2006:Proceedingsofthe10thInternationalConferenceonExtendingDatabaseTechnology,LNCS3896.Berlin:Springer, 2006: 664-681.
[9]KAMIN,ENOMOTON,BABAT,etal.AlgorithmfordetectingsignificantlocationsfromrawGPSdata[C]//Proceedingsofthe2010InternationalConferenceonDiscoveryScience.Berlin:Springer, 2010: 221-235.
[10]ZHENGY,ZHANGL,XIEX,etal.MininginterestinglocationsandtravelsequencesfromGPStrajectories[C]//WWW2009:Proceedingsofthe18thInternationalConferenceonWorldWideWeb.NewYork:ACM, 2009: 791-800.
[11]CAOX,CONGG,JENSENCS.MiningsignificantsemanticlocationsfromGPSdata[J].ProceedingsoftheVLDBEndowment, 2010, 3(1): 1009-1020.
[12]ZHOUC,FRANKOWSKID,LUDFORDP,etal.Discoveringpersonallymeaningfulplaces:aninteractiveclusteringapproach[J].ACMTransactionsonInformationSystems, 2007, 25(3): 1-31.
[13]KHETARPAULS,CHAUHANR,GUPTASK,etal.MiningGPSdatatodetermineinterestinglocations[C]//Proceedingsofthe8thInternationalWorkshoponInformationIntegrationontheWeb:inConjunctionwithWWW2011.NewYork:ACM, 2011: 1-6.
[14]GIANNOTTIF,NANNIM,PINELLIF,etal.Trajectorypatternmining[C]//KDD’ 07Proceedingsofthe13thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2007: 330-339.
[15] 刘奎恩,肖俊超,丁治明,等.轨迹数据库中热门区域的发现[J].软件学报,2013,24(8):1816-1835.(LIUKE,XIAOJC,DINGZM,etal.Discoveryofhotregionintrajectorydatabases[J].JournalofSoftware, 2013, 24(8): 1816-1835.)
[16] 袁冠,夏士雄,张磊,等.基于结构相似度的轨迹聚类算法[J].通信学报,2011,32(9):103-110.(YUANG,XIASX,ZHANGL,etal.Trajectoryclusteringalgorithmbasedonstructuralsimilarity[J].JournalonCommunications, 2011, 32(9): 103-110.)
[17] 袁冠.移动对象轨迹数据挖掘方法研究[D].徐州:中国矿业大学,2012:39-59.(YUANG.Researchontheminingmethodsoftrajectorydataformovingobjects[D].Xuzhou:ChinaUniversityofMiningandTechnology, 2012: 39-59.)
[18]HADJIELEFTHERIOUM,KOLLIOSG,GUNOPULOSD,etal.On-linediscoveryofdenseareasinspatio-temporaldatabases[C]//Proceedingsofthe8thInternationalSymposiumonAdvancesinSpatialandTemporalDatabases.Berlin:Springer, 2003: 306-324.
[19]JENSENCS,LIND,OOIBC,etal.Effectivedensityqueriesoncontinuouslymovingobjects[C]//Proceedingsofthe22ndInternationalConferenceonDataEngineering.Piscataway,NJ:IEEE, 2006: 71-71.
[20]VERHEINF,CHAWLAS.Miningspatio-temporalassociationrules,sources,sinks,stationaryregionsandthoroughfaresinobjectmobilitydatabases[C]//Proceedingsofthe2010InternationalConferenceonDatabaseSystemsforAdvancedApplications.Berlin:Springer, 2010: 187-201.
[21]ASHBROOKD,STARNERT.UsingGPStolearnsignificantlocationsandpredictmovementacrossmultipleusers[J].Personal&UbiquitousComputing, 2003, 7(5): 275-286.
[22] PALMA A T, BOGORNY V, KUIJPERS B, et al.A clustering-based approach for discovering interesting places in trajectories [C]// SAC’ 08: Proceedings of the 2008 ACM Symposium on Applied Computing.New York: ACM, 2008: 863-868.
[23] LIAO L, PATTERSON D J, FOX D, et al.Building personal maps from GPS data [J].Annals of the New York Academy of Sciences, 2006, 1093(1): 249-65.
[24] LIAO L, FOX D, KAUTZ H.Extracting places and activities from GPS traces using hierarchical conditional random fields [J].International Journal of Robotics Research, 2007, 26(1): 119-134.
[25] ALVARES L O, BOGORNY V, KUIJPERS B, et al.A model for enriching trajectories with semantic geographical information [C]// GIS’ 07: Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems.New York: ACM, 2007: Article No.22.
[26] CHENG G Q.Clustering algorithm for multi-density based on grid relative density [J].Computer Engineering & Applications, 2009, 45(1): 156-158.
[27] 王亮,胡琨元,库涛,等.随机采样移动轨迹时空热点区域发现及模式挖掘[J].吉林大学学报:工学版,2015,45(3):913-920.(WANG L, HU K Y, KU T, et al.Discovering spatiotemporal hot spot region and mining patterns from moving trajectory random sampling [J].Journal of Jilin University Engineering and Technology Edition, 2015, 45(3): 913-920.)
This work is supported by the Natural Science Foundation of Jiangsu Province (BK20130208).
LYU Shaoqian, born in 1992, M.S.candidate.His research interests include moving trajectory data mining, machine learning.
MENG Fanrong, born in 1962, Ph.D., professor.Her research interests include database, data mining.
YUAN Guan, born in 1982, Ph.D., associate professor.His research interests include trajectory data mining.
Trajectory structure-based moving object hotspots discovery
LYU Shaoqian*, MENG Fanrong, YUAN Guan
(CollegeofComputerScienceandTechnology,ChinaUniversityofMiningandTechnology,XuzhouJiangsu221116,China)
Focused on the issue that the existing algorithms are unable to accurately detect active hotspots from trajectory data, a novel Trajectory Structure-based Hotspots discovery (TS_HS) algorithm was proposed.TS_HS consisted of the following two algorithms: Candidate Hotspots Discovery (CHSD) algorithm and Hotspots Filter (HSF) algorithm.First, trajectory dense regions were detected by the grid based clustering method CHSD as candidate hotspots.Second, the active hotspots region of moving objects were filtered by using HSF algorithm according to moving feature and time-varying characteristic of trajectories.The experiments on the Geolife dataset show that TS_HS is an effective solution for multi-density active hotspot problem, compared with Global Density threshold based Hot Region discovery (GD_HR) and Spatio-temporal Hot Spot Region Discovering (SDHSRD).The simulation results show that the proposed framework can detect active hotspots effectively based on the structure feature and time-varying characteristic of trajectory.
moving object; trajectory structure; hotspot; trajectory data; data mining
2016-08-15;
2016-08-25。 基金项目:江苏省自然科学基金资助项目(BK20130208)。
吕绍仟(1992—),男,江苏南京人,硕士研究生,主要研究方向:轨迹数据挖掘、机器学习; 孟凡荣(1962—),女,辽宁沈阳人,教授,博士,CCF会员,主要研究方向:数据库、数据挖掘; 袁冠(1982—),男,江苏徐州人,副教授,博士,CCF会员,主要研究方向:轨迹数据挖掘。
1001-9081(2017)01-0054-06
10.11772/j.issn.1001-9081.2017.01.0054
TP391.4
A
