基于SVM的医学图像模式识别分类算法的研究
2017-04-15左亚灵
左亚灵

三、训练及结果分析
本课题中选用的医学图像数据为乳腺X线图像,全部示例图像均来自MIAS图像库,该图像库中包含322张乳腺X线图像,并分为三大类:正常、良性和恶性(异常),其中正常的208例,良性63例,恶性51例,后两类都划分为不正常。本课题中只分为“正常”和“异常”两类,良性和恶性都归为“异常”类中。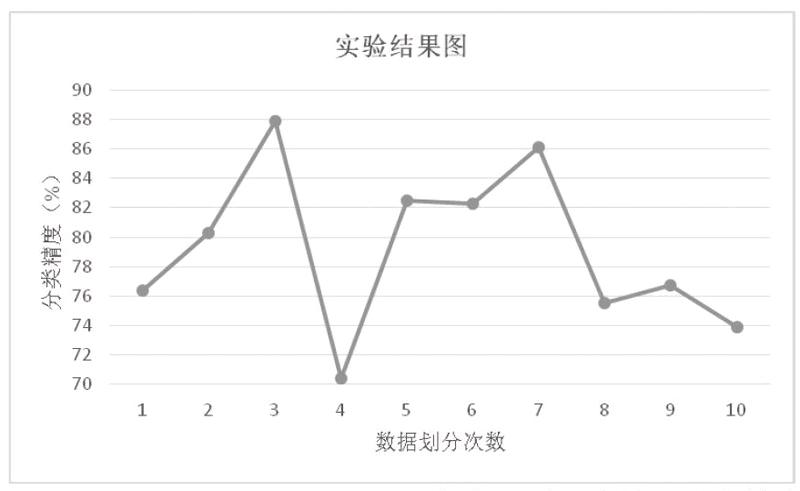
本文采用10重交叉驗证的方法,将数据库中的全体图像随机分为十份,其中一份用作测试集,另外九份用作训练集,依次轮换,直到每份样本都做了一次测试集,即进行了十次训练和预测。实验结果如右图所示,最终平均分类精度为79.2%。本实验中的支持向量机虽然证明了其可行性,但从结果来看,不仅准确度不够高,实验过程中最高精确度与最低精度相差也比较大,表明分类器的稳定性还不够,猜测可能与随机分类中图片分类分组也有一定关系,在进一步研究中可对其分组分类进行记录,来研究其中的关系。
四、结束语
基于本文中的实验方法,还可以在此基础上从以下方面进行改进,以提高精确度。
(1)本课题是在考虑SVM适用于小样本训练的前提下进行的,但如果用于大量样本的实验训练,则空间复杂度和时间复杂度也会大大增加。
(2)现已有多种基于提高识别率的优化算法,但如果要进一步优化分类算法,还应考虑提高训练速度。
此外,以上两点的结合以及最终问题就是增量学习和在线学习。无论什么样的算法,都不能直接保证其在任何时间地点都能进行百分之百准确的运算,但是如果用于应用中不断学习的在线学习,则可以使准确率无限接近于百分之一百,这是比现有算法都要更加实用的小样本分类算法。
参考文献:
[1]田 捷,包尚联,周明全.医学影像处理与分析[M].北京:电子工业出版社,2003.
[2]Ma J,Theiler J,Perkins S.Accurate online support vector regression[J].Neural Computation,2003(11).
[3]汪 辉.增量型支持向量机回归训练算法及在控制中的应用[D].杭州:浙江大学,2006.
