基于K-means聚类算法的数据分析模型应用研究
2017-04-13沈泓,刘顺
沈 泓,刘 顺
(1.国网江苏省电力公司常州供电公司 电力调度控制中心,江苏 常州 213001;2.江苏瑞中数据股份有限公司,江苏 南京 210012)
基于K-means聚类算法的数据分析模型应用研究
沈 泓1,刘 顺2
(1.国网江苏省电力公司常州供电公司 电力调度控制中心,江苏 常州 213001;2.江苏瑞中数据股份有限公司,江苏 南京 210012)
阐述了如何使用数据分析模型进行数据收集分析和处理,以及如何通过K-means聚类算法及线性回归模型建立合理预估模型。电能在从发电厂传输到用户的过程中,在输电、变电、配电以及营销管理的各环节中会产生电能损耗,如果线路损耗较高,则会对电网运行的安全性与经济性造成直接影响,同时也会加快线路老化或损坏速度。合理分析预估模型,可以找出差异性较大的台区着重进行管理与监测,并于用户操作区的Web端进行展示,进而有效预测出哪些台区可能存在偷窃电行为或其它影响正常供电的不合理行为,为供电工作提供有效辅助。
回归模型;K-means聚类算法;分析模型;预估;显著性
0 引言
电网数据作为一种对供电公司规划设计、生产运行、经营管理水平的综合反映与直观展示,是供电公司日常管理工作中关注的重要内容。合理分析处理与利用海量的电网数据,能够带来可观的经济与社会效益。以分析预测线损为例,台区线损管理通过比较理论线损与实际线损的差值,对不合理线损进行分析和预测,可提供较为科学有效的降损措施,有利于提升电力部门的管理水平与经济效益,加强电网建设与改造的科学性。传统的台区线损管理中尚存在一些问题:①采取一刀切方式,人为设置合理线损率范围,而缺乏理论依据和数据支撑,离精益化管理目标相差甚远;②台区理论线损的计算主要基于潮流的计算方法,但是由于低压台区下分支线路复杂、元件多样、设备台账数据不全,理论线损计算难度很大;③供电公司管辖范围内台区数量巨大,彼此之间差别较大,无法采用统一模式进行管理。因此,如何进一步提高台区线损管理的精益化水平,给出每个台区可参照的合理线损范围,并科学合理地对台区线损进行监视,及时发现异常台区,分析原因并及时解决问题,成为电力营销工作迫切需要解决的问题。
鉴于此,本文以预测台区线损率为例,依据供电公司辖区内各台区的基础数据,并应用基于K-means算法的数据分析模型,研究一种可以对电网关键数据进行预测分析的技术,以期为电网管理优化提供参考。
1 整体设计
基于K-means算法的数据预估模型的建立包含K-means聚类与线性回归两部分。首先通过K-means聚类算法,依据与台区线损率相关的基本特征属性将台区分为K类,然后给每一类数据分别建立各自的线性回归模型,最后将不同分类的台区特征数据引入对应的线性回归模型,得出合理的数据预测值,并将此值定义为合理预测。合理预测与实际值之差即为预测误差。具体步骤如下:①通过K-means聚类方法按照台区特征对供电公司的海量台区数据进行分类,将供电公司辖区内的台区分为特征不同的类群;②将每一类典型台区的基础数据与预测值相关联,通过线性回归的方式建立数学预测模型;③将需要预测的数据输入模型,得到输出,从而得出每一类台区的合理预测值。整个模型建立的流程如图1所示。
数据分析过程的主要活动由识别信息需求、收集数据、分析处理数据、数据分析模型的建立组成。
2 关键技术
2.1 K-means聚类算法
K-means算法是一种基于样本间相似性度量的间接聚类方法,属于非监督学习方法。此算法以k为参数,将n个对象分为k个簇,使簇内具有较高相似度,而且簇间的相似度较低。K-means算法是一种较典型的逐点修改迭代的动态聚类算法,其要点是以误差平方和为准则函数[1-2]。该算法的优点是可以处理大量数据集,具有很好的可伸缩性,且简单快速,故合理数据预估模型的分类采用了K均值聚类算法。

图1 模型建立流程
K-means算法的基本步骤如下:①从数据集中随机取k个元素,作为k个簇各自的中心;②分别计算剩下元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇;③根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;④将数据集中全部元素按照新的中心重新聚类;⑤重复第4步,直到聚类结果不再变化;⑥输出结果。
2.2 线性回归建模方法
线性回归建模的思路是根据K-means聚类结果数据,将不同分类的台区数据分别作为线性回归的输入,以线损率作为输出,建立线性回归模型,并对结果作相应分析,得出两种分类对应的回归方程[3]。
线性回归建模的原理如下:在线性关系相关性条件下,两个或两个以上自变量对一个因变量,为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。多元线性样本回归方程为:
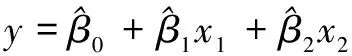
(1)
其中β0,β1,β2,…,βk是k+1个未知参数,β0称为回归常数,β1,β2,…,βk称为回归系数,y称为被解释变量。x1,x2,…,xk是k个可以精确控制的一般变量,称为解释变量。
多元线性回归方程中回归系数的估计同样可以采用最小二乘法,计算残差平方和:

(2)
根据微积分中求极小值的原理,可知残差平方和SSE存在极小值。欲使SSE达到最小,SSE对β0,β1,β2,…,βk的偏导数必须为零。
将SSE对β0,β1,β2,…,βk求偏导数,并令其等于零,加以整理后可得到k+1个方程式如下:

(3)
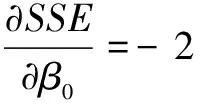
(4)

3 应用案例
3.1 原始样本数据收集分析及处理
首先应该进行识别信息需求的工作。识别信息需求是确保数据分析过程有效性的首要条件,可为收集、分析数据提供清晰的目标。有目的的收集数据,是确保数据分析过程有效性的基础。组织需要对收集数据的内容、渠道、方法进行策划。策划时应考虑:①将识别的需求转化为具体要求,如评价供方时,需要收集的数据可能包括其过程能力、测量系统不确定度等相关数据;②明确由谁在何时何处、通过何种渠道和方法收集数据;③记录表应便于使用;④采取有效措施,防止数据丢失和虚假数据对系统的干扰。
本次建模收集的数据包括台区基础信息表、线路线损率分月报表、台区线损率分月报表、生产经营报表(按月分)、窃电用户统计报表。建模数据收集涉及的部门包括发展策划部、电力营销部、运维检修部。数据范围包括供电公司辖区内各线路下的台区,分别为:220KV线路、110KV线路、35KV线路、10KV线路、10KV以下线路以及1KV以下线路等台区。经过ETL数据工具的处理以及对数据报表的整合,最终收集到的报表数据如图2所示。包含的字段有:台区名称、台区居民户数、台区非居民户数、居民容量、非居民容量、居民户均容量、非居民户均容量、居民容量占比、非居民容量占比、台区总容量、台区窃电量、功率因数平均水平、最大负荷、最大负载率以及以台区统计线损率。
下面进行分析处理数据的工作,将收集的数据通过加工、整理和分析,使其转化为信息,通常采用的方法有:①传统的7种工具,即排列图、因果图[4]、分层法、调查表、散步图、直方图、控制图;②新的7种工具,即关联图、系统图、矩阵图[5]、KJ法、计划评审技术、PDPC法矩阵数据图。
按照K-means算法的基本步骤代入分析所得的初始数据。具体如下:
输入:k,data[n]。
(1)选择k个初始中心点,例如c[0]=data[0],…,c[k-1]=data[k-1]。
(2)对于data[0],…,data[n],分别与c[0],…,c[k-1]比较,假定与c[i]差值最少,则标记为i。
(3)对于所有标记为i的点,重新计算c[i]等于所有标记为i的data[j]之和,除以标记为i的个数。
(4)重复(2)、(3),直到所有c[i]值的变化小于给定阈值。
图3为将k值设为3时,K-means聚类算法的详细示意图,图中(+)符号表示每次聚类选取的中心。

图2 样本数据

图3 K-means聚类示意图(k=3)
3.2 利用K-means聚类算法对台区分类
以供电公司辖区下的台区数据作为样本数据(共630个),作为K-means算法的输入。聚类样本特征输入量包括:台区名称、居民户数、非居民户数、居民容量、非居民容量、居民容量、居民户均容量、居民容量占比、非居民容量占比、台区总容量、台区窃电量、功率因数平均水平、台区最大负荷、最大负载率、实际线损率。在K-means聚类算法中,初始聚类数设定2~12为合理范围,通过尝试设定不同的初始聚类数,计算不同聚类数时的轮廓系数值(轮廓系数值越接近1,表明聚类数越合理)。不同K值聚类的轮廓系数如表1所示。
通过不同K值轮廓系数的对比,可以看出聚类数为2时,轮廓系数值为0.5,在所有的轮廓系数中最接近1,表明聚类数为2时,K-means聚类质量最好,输入13对应的聚类结果如下:
最小聚类大小为:95(15.1%)
最大聚类大小为:535(84.9%)
大小比率(最大聚类比最小聚类):5.63
K-means聚类算法中各变量对于聚类的重要性不同,如图4所示。可以看出,居民容量占比、非居民容量占比、非居民容量、非居民户均容量在聚类中对聚类结果影响比较明显。

表1 K-means轮廓系数
聚类数为2时,各变量在聚类-1与聚类-2中的均值如表2所示,各变量按照在聚类算法中体现出的重要性从上到下依次排序。可以看出,居民容量占比与非居民容量占比对聚类的影响最大,是台区分类过程中的主要依据。其它变量在聚类中对聚类结果有影响,但不是主要影响因素。

图4 K-means聚类中变量重要性
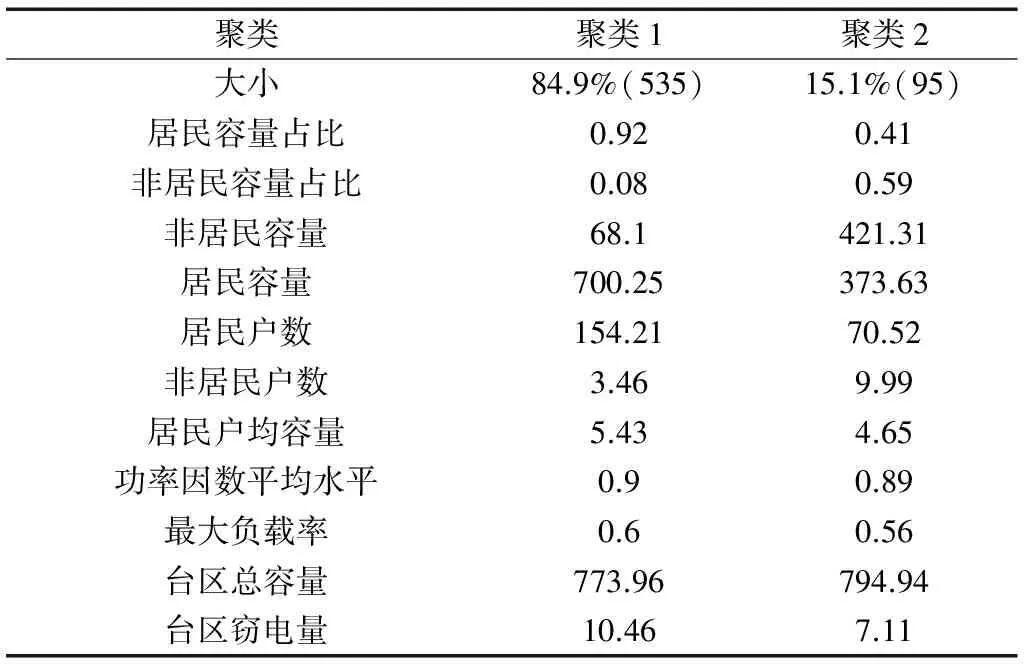
表2 聚类数为2时聚类模型各变量均值
从表2中可以看出,聚类1中居民容量占比为0.92,可以认为此类为居民用户类;聚类2中非居民容量占比为0.59,可以认为此类为非居民用户类。故通过K-means聚类算法将台区分为居民用户类台区、非居民用户类台区。
3.3 通过线性回归模型建立合理线损数据分析预测模型
将上述K-means聚类得出的两类数据作为线性回归模型的输入(见表3),包括:聚类-1、聚类-2。建模特征参数包括:台区居民户数、台区非居民户数、居民容量、非居民容量、居民户均容量、非居民户均容量、居民容量占比、非居民容量占比、台区总容量、台区窃电量、功率因数[6]平均水平、最大负荷、最大负载率[7]。输出参数为:台区线损率。
现对上述K-means聚类得出的聚类-1与聚类-2分别建立线性回归模型,并对模型进行分析。依据调整后的R平方值、F检验系数、T检验系数、sig值检验系数等对模型进行评估,从而判断出合理线损预测模型的拟合程度。
T检验是对单个变量进行显著性检验,检验该变量独自对被解释变量的影响。
F检验是检验回归模型的显著意义,即所有解释变量联合起来对被解释变量的影响。对方程联合显著性检验的F检验,实际上也是对可决系数的显著性检验。
R的平方值系数实际反映样本数据与预测数据间的相关程度。越接近1,回归平面拟合程度越高;反之,越接近0,拟合程度越低。
sig值的含义是显著性。一般将该sig值与0.05相比较,如果大于0.05,说明差异不显著,从而认为两组数据之间的平均值相等;如果小于0.05,说明差异显著,认为两组数据之间的平均值不相等。
3.3.1 聚类-1线性回归模型分析
调整后的R平方值为0.824,拟合优度较高,不被解释的变量较少,即表示输入变量中82.4%的自变量对因变量线损值有影响。依据此系数可知,样本数据与预测数据间的相关程度与模型模拟程度较高,模型具有可用性。
回归方程显著性检验(sig值)的概率为0,小于显著性水平0.05,则认为系数不同时为0,被解释变量与解释变量全体的线性关系是显著的,说明生成的模型具有明显的统计学意义。
如图5所示,给出了回归方程的系数值,即常量为1.930,居民容量为0.010,居民户均容量为1.068,台区窃电电量为0.013,居民户数为0.012,最大负载率为0.920。
所以线性回归方程为[8]:
线损率=1.930+0.01*居民容量+1.068*居民户均容量+0.012*居民户数+0.013*台区窃电量+0.92*最大负载率
将台区样本数据代入线性回归方程可得出台区线损率预测值,并将台区预测线损率与台区实际线损率通过折线图作比较,如图6所示。可知大部分台区的实际线损率与预测线损率较为接近,但存在少数台区的线损率实际值远大于预测值的情况。出现这一现象的可能原因如下:①台区的实际线损率在日常统计工作中有较大误差,导致预测结果不合理;②该部分台区的线损率有异常,可能存在用户偷窃电行为,需加强管理与核实。

图5 聚类-1的线性回归模型系数

图6 聚类-1台区实际线损率和预测线损率误差值
3.3.2 聚类-2线性回归模型分析
调整后的R2值为0.612,拟合优度较高,不被解释的变量较少,即表示输入变量中61.2%的自变量对因变量线损值有影响。依据此系数可知,样本数据与预测数据间的相关程度较高,模型模拟程度较高,模型具有可用性。 回归方程显著性检验的概率为0,小于显著性水平0.05,则认为系数不同时为0,被解释变量与解释变量全体的线性关系是显著的,表明生成的模型具有明显的统计学意义。
如图7所示,给出了回归方程的系数值,即常量为5.681,非居民户均容量为0.045,台区总容量0.005,最大负载率为2.952,台区窃电电量为0.015,所以线性回归方程为:
线损率=5.681+0.045*非居民户均容量+0.005*台区总容量+2.952*最大负载率+0.015*台区窃电总量
同样,将聚类-2中的台区样本数据代入线性回归方程可得出台区预测线损率,并将台区预测线损率与台区实际线损率通过折线图作比较,如图8所示。可知大部分台区的实际线损率与预测线损率较为接近,存在少数台区的线损率实际值远大于或远小于线损预测值的情况。出现这一现象的可能原因如下:①台区的实际线损率在日常统计工作中有较大误差,导致预测结果不合理;②该部分台区的线损率有异常,可能存在用户偷窃电行为,需加强管理与核实。

图7 聚类-2的线性回归模型系数
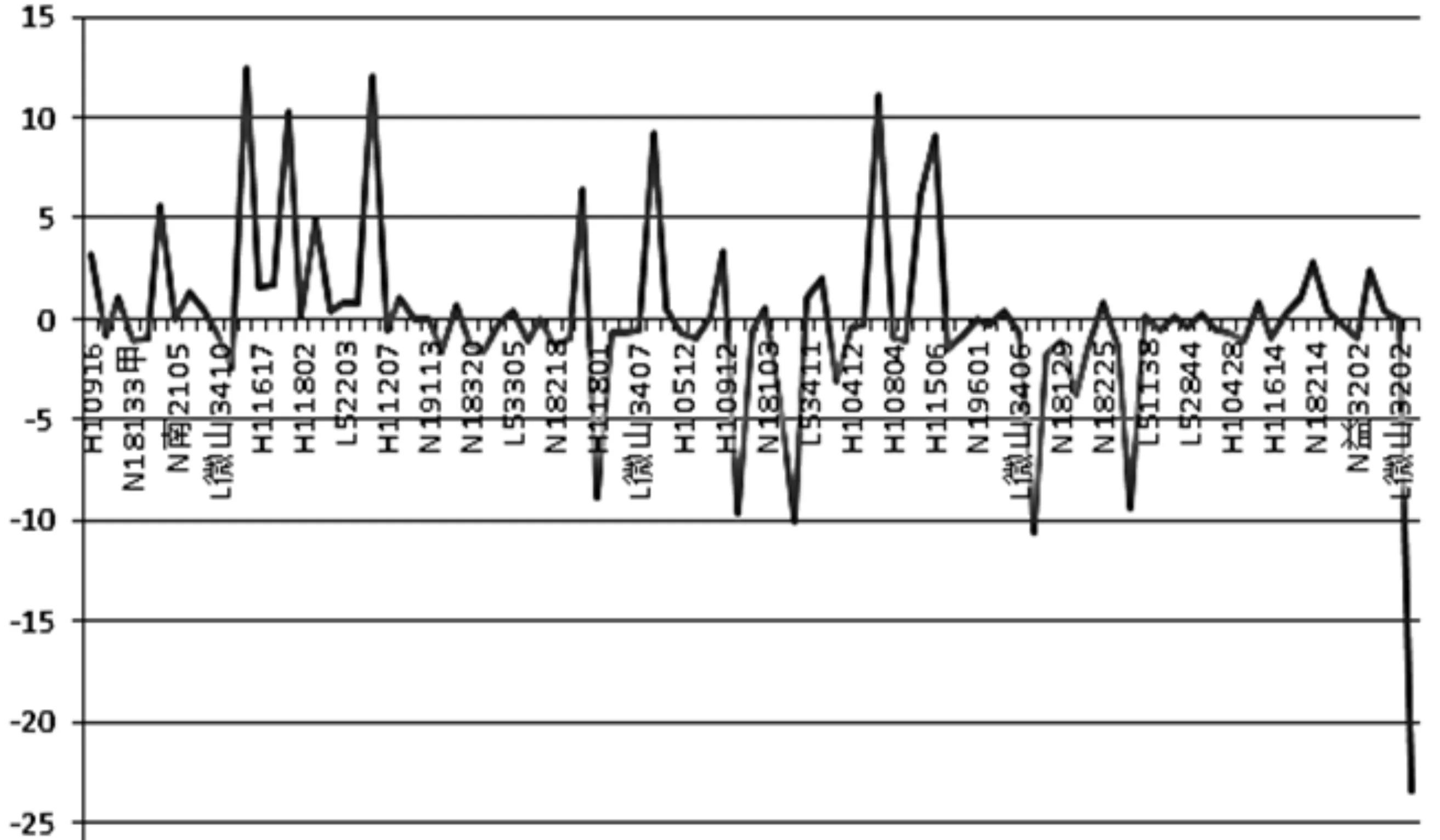
图8 聚类-2台区实际线损率与预测线损率误差值
4 结语
在企业的供电管理中,应加大对线损数据的分析预测,这是降低电网线损率的有益举措,同时也是提高企业供电管理水平的有效手段。使用合理的数据分析模型有以下3方面优势:①可以找出线损管理工作的不足与降损方向。针对线损较高或居高不下的情况,可以找出电网结构的薄弱环节,以及管理方面存在的问题,确定改善电网结构工作的重点,加强管理,降低线损;②可及时查找出线损升降原因,特别是上升原因,准确掌握每条线路在不同用电季节、各种用电负荷情况下所引起的线损变化规律及特点,以确定降损的主攻方向,以便有针对性地采取降损措施,使电网的线损率降到合理范围,提高企业的经济效益和社会效益;③可以找出电网运行存在的问题,确定最佳运行方案。
在实际应用中,需要不断加强该数据分析模型技术应用于电网数据的管理,提高计量远程采集管理水平。通过此技术预测各电网指标的运行状态及偏差值,并及时作出指导建议,为供电工作提供有效的辅助。
[1] 周爱武,于亚飞.K-Means聚类算法的研究[J].计算机技术与发展,2011,21(2):62-65.
[2] 冯能山,林志华,等.一种K-means聚类的改进算法与实现[J].软件导刊,2012,11(3):66-70.
[3] 李芳.DE算法在多元线性回归模型参数估计中的应用[J].软件导刊,2012,11(6):46-48.
[4] 萧萍.基于因果图的测试用例设计及应用[J].软件导刊,2016,15(4):44-46.
[5] 周天祥.通俗易懂的QCC——矩阵图法[J].中国质量,2003(12):59.
[6] 顾军,王清灵,等.基于SVG的电网功率因数控制系统[J].电力自动化设备,2011(2):40-43,47.
[7] 于群,曹娜,等.负载率对电力系统自组织临界状态的影响分析[J].电力系统自动化,2012(1):24-27,37.
[8] 周红艳.配电网理论线损率的分析与预测[D].芜湖:安徽工程大学,2015.
(责任编辑:黄 健)
沈泓(1970-),女,江苏常州人,国网江苏省电力公司常州供电公司电力调度控制中心高级工程师,研究方向为电网调度自动化技术;刘顺(1990-),男,江苏南京人,江苏瑞中数据股份有限公司工程师,研究方向为智能分析技术在电网领域的挖掘。
10.11907/rjdk.162534
TP319
A
1672-7800(2017)003-0103-05
