一种改进的个性化协同推荐算法研究
2017-04-13陈南平
陈南平
(湖北大学 计算机与信息工程学院,湖北 武汉 430062)
一种改进的个性化协同推荐算法研究
陈南平
(湖北大学 计算机与信息工程学院,湖北 武汉 430062)
在协同推荐算法实际应用基础上,提出了一种改进措施,将多层次相似性度量应用到推荐系统kNN算法中,即借助层次关系矩阵,将内容之间的一些固有属性信息融合到相似度计算中。该改进措施在实际推荐系统应用中取得了较好的效果。
协同推荐;相似度;多层次度量;冷启动
0 引言
推荐算法是目前个性化推荐系统的研究热点,在电子商务领域有着广泛应用,其核心思想是利用数据挖掘与人工智能技术来改进传统的协同过滤算法[1-2]。系统算法通常是某类推荐模型的实现,它负责获取数据,以及预测给定的用户组会对哪些选项感兴趣。推荐算法通常分为4大类:协同过滤推荐算法、基于内容的推荐算法、混合推荐算法和流行度推荐算法。
基于协同过滤推荐的系统从用户角度进行相应推荐,由系统自动完成。它一般采用最近邻技术(KNN),利用用户的历史喜好信息计算用户间的距离,然后根据目标用户的最近邻居对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度对目标用户进行推荐。即用户获得的推荐是系统从购买模式或浏览行为等隐式获得,不需要用户寻找推荐信息。Zhang等[3]提出了推荐系统中应用的SVM分类器,其缺陷是在数据稀疏时分类精度受到很大影响。Grarm等[4]将KNN与SVM的性能进行了对比,结论表明其推荐精度与数据质量高度相关。针对这些问题,本文提出一种改进措施,将多层次相似性度量应用到推荐系统kNN算法中,在实际推荐系统中取得了较好的效果。
1 多层次相似性度量算法分析
协同过滤是基于这样的假设:为一用户找到感兴趣内容的方法是首先找到与此用户有相似兴趣的用户,然后将感兴趣的内容推荐给此用户。日常生活中,人们往往会利用好友的推荐来进行选择。协同过滤把这一思想运用到电子商务推荐系统中,基于其他用户对某一内容的评价向目标用户推荐。
1.1 推荐系统建模
记推荐系统中有m个用户的集合T={t1,t2,…,tm}和n个内容的集合D={d1,d2,…,dn}。用户评估数据集合可用m×n阶矩阵Rm×n表示。某一用户ti对内容dj(di∈D,tj∈T)的评测值为ri、j,这个评测值体现了用户ti对内容dj的兴趣和偏好。某个用户感兴趣的内容集用向量dj=(r1j,r2j,...,rnj)表示,其中r1j表示第1个用户t1对内容d1感兴趣的权重,值越大表示用户对该内容越感兴趣。如果用户t1选取第j项内容,取r1j为1;如果用户t1未选择第j项内容,选取为0。所以,计算dj各分量的值为:
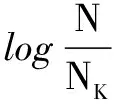
(1)
其中TF-IDF(tk,dj)是第k个用户对第j个内容选择次数,Nk是所有内容中包括第k个用户的数量。最终第k个用户对第j项内容感兴趣的程度由下式获得:
(2)
1.2 内容信息集合与内容属性相似度
记内容di的r个属性信息为Ci=(ci1,ci2,…,cir) ,Cij是指第i个内容的第j个属性。同一内容可以拥有多个属性。记内容类别信息S=(sj1,sj2,...sjr’),Sji是指第j个类别包含第i个内容。同一类别一般包含多个相关内容。C矩阵和S矩阵之间的关系由一个层次关系矩阵PK=(pK1,pK2,…,pKR)联系起来。层次关系矩阵P定义为:如果Cir属于sjr,那么就记pij=1,否则pij=0。根据以上定义,内容Da与Db的属性相似度公式:
(3)
1.3 用户评估相似度
度量用户间的相似性主要有两种方法[5]:余弦相似性和相关相似性。余弦相似性实现起来较简单,也能较好地度量项目间的相似性,而且计算速度较快。本文采用余弦相似性度量内容间的评分相似性。但是在单独使用单一层次的评估作为评判用户相似度的基础数据时,会遇到“相似不相同”的问题。使用用户评估作相似度计算时,可能会因为这两个用户没有共同的评估项目而认为他们不相似,但实际上这两个用户的评估内容属于相同的类别。本文采用多层次相似性度量来解决这个问题,即借助层次关系矩阵PK,将内容之间的一些固有属性信息融合到相似度的计算中。这种改进措施保证了计算的准确性,并得到各项目的最近邻居集。
构造两个层次:①用户的所有属性构成的类别;②所有属性属于的类别。这两个层次之间的关系由S矩阵联系。根据S矩阵定义的关系修正用户对内容评价的相似度。对用户未选择的内容评估公式如下:
(4)
然后使用修正的余弦相似度公式计算用户之间的相似度,并根据用户相似度阈值进行筛选,得到目标用户的最近邻居集T。
1.4 预测推荐结果集
将相似度最高的若干内容作为目标内容di的邻居集合M= { m1,m2,…,mn},且集合M 中的内容按照与di的相似度从高到低排列。
得到用户的最近邻居集后,可以根据邻居对项目的喜好记录计算推荐结果。对于目标用户未评分的项目,重新预测其评分,计算公式如下:
(5)
2 算法设计
将上述改进的算法用于实际推荐系统。实现协同过滤分为3个步骤:①抽象用户喜好特征;②发现相似用户;③计算目标推荐。算法流程需要设计3个基本数据结构:用户信息矩阵T、内容信息矩阵D和用户对内容评价矩阵R。用户信息矩阵用于新用户注册时,增加其基本注册信息; 内容信息矩阵D用于新增一个内容到推荐系统,补充其相关属性信息; 当一个用户对某个内容进行评价后,他对该内容的评价信息将增加到矩阵R中。
(1)抽象用户喜好特征。抽象用户喜好特征需要从用户的特征性行为中发现其规律信息,并以此为依据进行推荐。系统可设计多种方式探测用户的喜好信息,常用的有投票、评分、点击流、转发、保存书签、购买及页面停留时间等。实际推荐引擎设计中可以综合考虑几种方式,以获得用户喜好程度的准确信息。
要在一个推荐系统中得到用户喜好信息需要综合考虑多种不用的用户行为,可采用以下两种不同的方式组合各种不同的用户行为:①将不同的用户行为分组,然后根据不同的用户行为按分组类别计算不同用户对物品的感兴趣程度;②对不同行为产生的用户喜好按照预先设定的权值进行加权处理,然后求出用户对物品的总体喜好特征。本算法采用第②种方式。
得到用户的行为数据后,再对数据进行除噪和归一化预处理,最终得到一张二维表,即用户评价矩阵,如表1所示。其中一维是用户列表,另一维是内容列表,值是用户对商品的评价。

表1 用户评价矩阵
(2)发现相似用户。得到某个用户的评价特征矩阵后,可根据用户的喜好计算相似用户,然后向相似用户进行推荐。本算法应用多层次相似性度量的改进措施,采用公式(4)计算与其相似的邻居用户。
首先建立内容与用户关联映射表,用来保存对若干内容发生过行为的用户。映射表系数矩阵N[i][j]=|N[i]∪N[j]|。如果用户i和用户j同时属于表中Nk个物品对应的用户列表,则N[i][j]=Nk。然后扫描映射表中每项内容对应的用户列表,将用户列表中有重叠内容的系数项加1,最后得到所有用户之间的系数矩阵N,其值为0或1。
建立一个m*n的 用户相似度矩阵R,R的初始取值计算方式为:对于内容a,将r[a][b]和r[b][a]加1,对于内容b,将r[a][c]和r[c][a]加1,直至扫描完所有内容。
内容的属性信息由C矩阵表示,多个属性属于不同层次,本算法将所有内容设定为两个层次,两个层次之间的关系由内容类别信息S矩阵联系。同一个类别包含多个相关内容。C矩阵和S矩阵之间的关系由层次关系矩阵PK=(pK1,pK2,…,pKR)联系。如果Cir属于sjr,那么就记pij=1,否则pij=0。矩阵之间关联的计算公式为C·P∈S。扫描所有内容,按照公式(4)进行计算,可得到最终的R矩阵,即为最终的用户相似度矩阵。
(3)计算目标推荐。得到用户相似度矩阵后,再计算与该用户相似的K个邻居用户感兴趣的内容并进行推荐。 对于用户di没有发生行为的内容j,他对j的感兴趣程度计算过程为:①利用用户di的评估相似度矩阵找到与其最相似的K个邻居用户;②采用K个邻居用户和D(j)的交集得到K个用户中对j感兴趣的若干用户集合v(D(j)为对物品j有兴趣的用户集合); ③将用户di与集合v中的每个v[j]的相似度乘积进行累加求和即为用户di对内容的感兴趣程度。算法中用户di对物品j的喜好程度用如下公式度量:
(6)
其中,D(di,K) 包含与用户di喜好最接近的K个用户,D(j)表示对物品j有过行为的用户集合,rdi,v表示用户di和用户v的喜好相似度,rvj表示用户v对物品j的喜好。
3 仿真实验结果及分析
3.1 实验环境
以MovieLens 站点( http://movielens.umn.edu) 的实验数据集为例,数据集为500个用户对1 200个影片的6万条投票记录。每个影片都有所属的类别,将类别作为影片的属性。实验中取其中两个类别进行模拟,以获得影片两个层次的属性相似度。表2中α表示第1个层次相似度的权值,1-α表示第2个层次相似度权值。两层相似度计算都采用余弦函数法。表2为k=10时的一组实验结果。表3为k=20时的一组实验结果。RMSE表示平均绝对偏差,实验中用它度量对比结果。
(7)
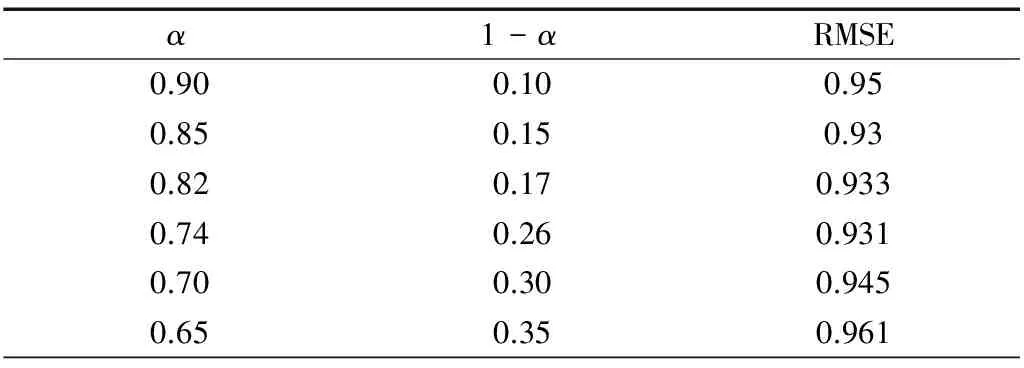
表2 实验结果 (k=10)
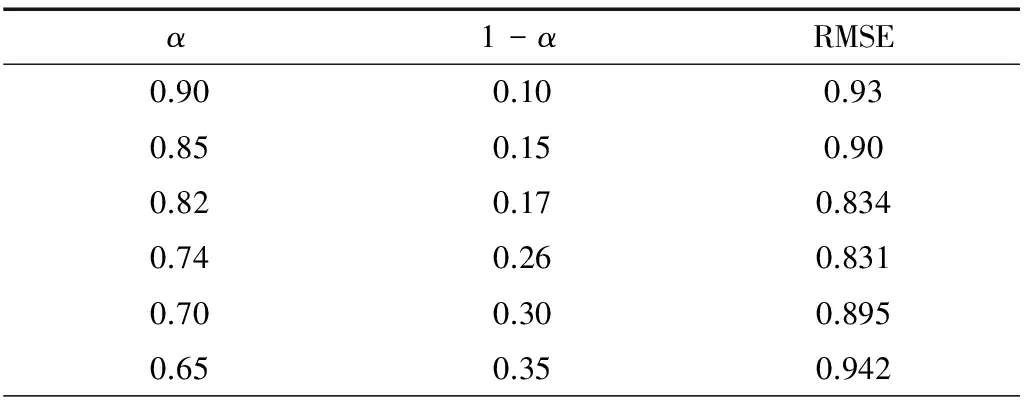
表3 实验结果 (k=20)
3.2 结果分析
从上述表格可以看出,多层次相似度计算的结果优于传统的单层相似度计算,但并不总优于传统计算方法。当α接近于1时,结果比传统的要差。α=1时即为传统的单层相似度。α参数决定了系统对相似内容的评估转化能力和认知能力。
4 结语
本文在协同推荐算法实际应用中提出一种改进措施,将多层次相似性度量应用到推荐系统kNN算法中,实践证明效果较好。系统实际应用中要考虑的因素会更多,关于层次的选择和划分以及系统实验效果还有待继续研究探讨。例如在应用此方法时会算出用户对类别的评估矩阵,这个矩阵可以拓展得到用户的兴趣模型,内容的冷启动问题也可得到解决。
[1]UNGARLH,FOSTERDP.Clusteringmethodsforcollaborativefilter-ring[C].ProcofWorkshoponRecommendationSystems.California:AAAIPress,1998:11-15.
[2]BREESEJS,HECKERMAND,KADIEC.Empiricalanalysisofpre-dctivealgorithmsforcollaborativefiltering[C].Procof14thConfe-renceonUncertaintyinArtificialIntelligence.1998 :43-52.
[3]ZHANGTONG,IYENGARVS.Recommendersystemsusinglinearclassfliers[J].JournalofMachineLearningResearch,2002(2):313-334.
[4]GRARM,FORTUNAB,MLADENID,etal.KNNversusSVMinthecollaborativefilteringframework[C].ProcofDataScienceandClassification,2006:251-260.
[5]COGGINSJM,JAINAK.Aspatialfilteringapproachtotextureanalysis[J].EuropeanComputer-IndustryResearchCenter(ECRC)PatternRecognitionLetters,1985(3):195-203.
(责任编辑:杜能钢)
陈南平(1975-),女,湖北武汉人,硕士,湖北大学计算机与信息工程学院讲师,研究方向为人工智能、网络应用。
10.11907/rjdk.161444
TP312
A
1672-7800(2017)003-0045-03
