基于路径聚类分析的代码缺陷定位研究
2017-04-13黄小红
黄小红
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于路径聚类分析的代码缺陷定位研究
黄小红
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于路径分析的代码缺陷定位所使用的方法通常分为两类:基于路径轨迹相似性分析的方法和基于路径元素信息统计的方法。通过理论分析以及实际环境中的应用,发现两类方法有以下不足:冗余路径的存在降低了整体定位效率;源代码一般包含了大量对定位没有意义的谓词和语句,对这些无意义元素的统计不仅耗时耗力,而且会影响定位效率和精度。因此,提出基于路径聚类分析的模糊聚类算法Pbtc。实验结果表明,该方法在一定程度上能够提高代码缺陷定位的效率和精度。
路径特征;聚类算法;路径差异;代码缺陷定位
0 引言
近年来软件开发工作取得了较大进展,人们在软件工程学中对软件的开发以及维护投入了大量成本[1],因此需要研究一些新方法来降低软件调试成本。代码缺陷定位和缺陷修复是程序调试过程中的两个主要阶段,相对于缺陷修复,代码缺陷定位更为重要,只有准确定位到缺陷位置才能顺利将其修复。因此,如何开发出快速高效的代码缺陷定位技术,该研究对于软件行业的发展具有重要意义。
基于聚类分析的动态代码缺陷定位(Clustering Based Dynamic Fault Localization,简称CFL)是动态代码缺陷定位的重要方法。DFL的原理是通过跟踪分析测试用例的执行路径信息,找到与失败路径最为相似的成功路径,然后通过二者差异分析,快速定位到可疑程序位置。
基于路径的研究已有大量成果,但仍有不足之处:①冗余路径的存在对代码缺陷定位几乎无价值;②对源代码中大量无贡献意义的谓词和语句的统计耗时耗力。因此本文提出新的路径聚类算法,该算法通过去除冗余路径,得到执行失败路径与成功路径代表,然后对两条代表路径作差异分析计算,最后针对差异分析生成缺陷可疑度排名报告。通过实验分析以及与经典实验的对比可以证实,本文方法能够提高代码缺陷定位的效率和精确度。
1 相关工作
基于路径分析的方法是当前软件代码缺陷定位方法中的一类重要方法[2-5]。基于路径轨迹相似性的方法主要通过找到与执行失败用例路径最接近的执行成功路径,然后通过计算统计差异信息进行代码缺陷定位。该方法的典型研究成果是Renieris等[6]提出的“最近邻模型”。
基于路径元素特征信息统计的方法通过统计两种路径(执行失败路径和与失败路径最接近的成功路径)对应的程序元素信息,定位到缺陷相关语句或直接定位到缺陷准确存在的语句。Tarantula、CBI、SOBE方法都是比较有代表性的基于元素特征统计的方法。三者在一定程度上都能达到代码缺陷定位的目的,但不能被所有程序通用,有一定局限性。
近年来通过对基于聚类分析的方法的探究,学者们已经取得了许多研究成果。Renieris[2]提出了“近邻模型”策略;Yates[7]提出了“谓词最少化”策略;Bertolino[8]提出了“控制流分析”策略;Agrawal[9]提出统计执行失败与执行成功路径程序切片的策略;Wong[10]在Agrawal基础上提出改进的执行路径切片以及内嵌数据依赖分析的策略。本文在路径筛选时引进了聚类分析技术,把现有的聚类分析技术运用到路径筛选中,并且对原有技术加以改进,以适应路径分析的特殊性。
2 基本概念
以下为本文展示的一个示例程序,该程序是求3个数的最大值,S8是缺陷所在位置。借助该程序,将从以下角度阐述本文的研究动机:如果从人的角度出发,定位到基本分支块即可找到问题所在,从而省去对大量谓词、语句的无意义统计,是否可以更高效;把路径执行的次数和顺序信息加入定位考虑范围内,是否可以更加快速精确。
/* S8是错误的.正确的应该是:a>max; */
#include
#include
#define N 3
S1int main(){
S2int i,a;
S3int max;
S4scanf("%d”,&a);
S5max=a;
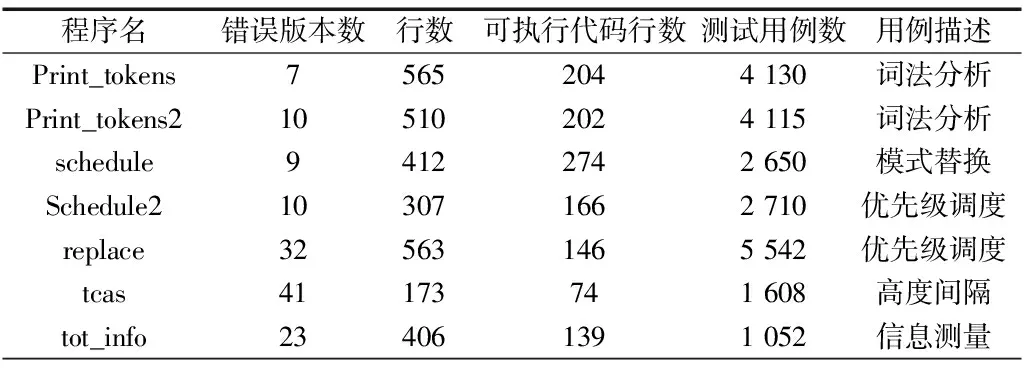
S6for(i=0;i S7scanf("%d",&a); S8if(a<=max) S9max=a;} S10printf("max=%d",max); S11return 0;} 本文涉及以下几个概念: 定义1:路径覆盖向量(PV),即程序在对应测试用例下动态执行时所有运行步骤对语句的覆盖情况。程序每一步执行覆盖到的语句组成一个集合,记为路径覆盖向量。不仅考虑语句覆盖信息,而且还考虑语句的执行顺序以及执行次数。以测试用例(5,4,3)为例,其路径覆盖向量为:{1,2,3,4,5,6,7,8,9,6,7,8,9,6,10,11}。 定义2:路径分支执行序列(PBS)。测试用例动态执行时各路径分支语句执行状态的集合。 设Bi是程序P中的第i个分支,一个测试用例执行结束后,该条路径对应的分支执行序列由Bi的执行顺序和执行次数所唯一表示。如示例程序的执行情况所示,语句6和语句8为执行路径的分支语句;以测试用例(5,4,3)为例,其路径分支执行序列表示为:{6,8,6,8,6}。 定义3:路径分支轨迹特征(BC)。路径分支轨迹特征由路径分支执行序列中路径分支动态运行之后各路径分支取真和取假的个数决定。 如示例程序的执行情况所示,以测试用例(5,4,3)为例,其路径分支分别为S6和S8,其中S6共执行3次,取值分别为“真真假”,则BCS6=2/3;S8共执行2次,取值分别为“真真”,则BCS8=1。 定义4:路径执行轨迹矩阵(PM)。PM用m*(n+1)阶矩阵表示。矩阵元素PMij(1≤i≤m,1<≤j≤n)表示程序P在执行第i个测试用例时,第j个分支的路径分支轨迹特征值BCi。m为本次路径执行所用的测试用例总数,n为本次路径执行轨迹包含的分支总数。 路径分支轨迹特征向量BV构成矩阵PM的行,路径的分支构成矩阵的列。第n+1列表示该条测试用例的执行结果,若执行成功,则PMi(n+1)=1;若执行失败,则PMi(n+1)=0。如示例程序的执行情况所示,若干测试用例执行后,该程序路径执行轨迹矩阵如下: 本文解决的主要问题是如何通过聚类分析实现代码缺陷定位,本节首先给出路径分支轨迹模糊聚类的算法,然后根据聚类结果得到的最优成功代表集和最优失败代表集给出路径差异对比分析的方法,最后介绍了差异统计代码缺陷定位的实现方法。 3.1 路径聚类算法 路径分支轨迹模糊聚类算法是在模糊C均值算法基础上对传统等划分缺陷进行改进,在欧式距离度量中使用了调节因子,提出一种基于分支路径特征改进的矩阵方法代替传统距离度量矩阵。 成功执行路径聚类时样本集为PMs,失败执行路径聚类时样本集为PMf,本节以成功执行路径聚类PMs为例进行详细说明,对PMf作聚类分析时原理相同。将待聚类矩阵PMs= {PMs1,PMs2,…,PMsn}作为一个给定的聚类样本集,本文将用U(PMs)表示它的分块矩阵,按照特定规则把PMs划分为c个聚类子集Fi(F1,F2,…,Fc),c表示聚类数目,每个分块矩阵c×n的大小可以表示为P=[μij]c*n ,i=1,2...c,j=1,2...n,μij∈[0,1]。用V= {v1,v2,…,vc} 表示c个子集的聚类中心,μFi(PMsj)表示PMsj对Fi的隶属度。 聚类算法的优化目标函数为: (1) 其中‖PMsj-vi‖表示PMsj和vi的欧式距离,变量m用于控制矩阵的模糊程度。在实际应用场景中,m值的最佳取值范围为(1.5,2.5)[11-12]。本文经实验验证,在路径聚类中取1.8。 步骤1:初始化矩阵PMs=[μij]c*n,PMs∈Fi,设误差值为θ,得到以下公式: (2) 步骤2:计算模糊聚类中心: (3) 步骤3:算法迭代操作。该聚类算法停止迭代的条件是:Jm<θ。如果Jm<θ,则认为函数已收敛,可以得到需求的聚类子集,否则继续执行步骤2。 步骤4:分别得到成功路径和失败路径代表集作差异分析。 步骤5:得到缺陷可疑度排名。 3.2 可疑度分析 由于Abreu等[13]提出的Jaccard方法是受聚类分析方法启发而来,而本文正是基于路径分支轨迹聚类分析的基础进行代码缺陷定位研究,因此选择Jaccard可疑度计算公式作为可疑度分析比较有研究意义。该公式如下: (4) 其中,nef(si)为语句si被覆盖且执行失败的测试用例个数,nep(si)为语句si被覆盖且执行成功的测试用例个数,nf为所有执行失败的测试用例总数。 4.1 实验对象 为了直观地与其它代码缺陷定位方法的优劣作对比,本文使用国内外比较有权威的Siemens程序组件进行实验分析,试验程序的基本信息如表1所示。 表1 试验程序基本信息 4.2 实验步骤 本文在Ubuntu环境下使用GCC4.7.0编译器对所选取的各个西门子组件版本进行编译处理,然后使用gcov组件记录各条语句执行情况,最后在VS 2010平台下编写算法进行实验。 实验具体流程如下:①使用gcc对西门子组件的各个版本作编译处理;②使用gcov组件记录各条语句执行情况,对测试用例的执行轨迹进行收集存储;③执行Pbtc、Tarantula、Ochiai、Jaccard和Wong五种经典的可疑度算法,使用收集的用例执行信息分别对程序作可疑度排名;④计算5种算法下该程序版本缺陷所在基本分支块的排名,以及为了找到缺陷所在位置需要检查的代码数占总代码数的百分比;⑤根据得到的数据,比较上述5种可疑度排序算法的性能。 4.3 实验结果及分析 通过Siemens程序集中Printtokens2程序的具体运行给出实验结果分析。数据取自Printtokens2中的版本4,共运行了4 115个有效测试用例,实验结果如表2所示。已知版本4的缺陷存在于S355。 表2 缺陷位置排序 执行Pbtc算法后得到基本块可疑度的排序结果。表2还给出了执行Tarantula、Ochiai、Jaccard和Wong算法后得出的基本分支块可疑度排序结果。 从5种缺陷定位算法的实验结果可以看出,本实验方法可以准确定位出缺陷所在位置S355。Tarantula方法和Wong方法将该位置排到第2位;Ochiai和Jaccard方法均将缺陷位置排到第5位。本文在对Siemens其它6个程序集的定位试验中发现,本文方法对程序中90%以上的缺陷定位效果都比较明显,在给出的缺陷位置序列中,90%以上缺陷被排列到前3位的平均概率为88%,而其它4种对应的概率分别为65%、73%、81%和80%。因此,本实验方法在对缺陷的定位中是有效且准确的。 基于聚类分析的代码缺陷定位方法已日趋成熟。本文通过对各种定位方法的研究,提出一种基于聚类分析的路径聚类算法Pbtc。Pbtc算法从人的角度出发,以分支基本块为粒度划分待定位程序,通过程序动态执行过程中路径分支的执行次数和执行顺序进行统计计算,并利用算法Pbtc去除冗余路径,筛选出重要信息,最后通过差异分析对比得到缺陷可疑度排名报告。该方法一定程度上提高了软件代码缺陷定位的精度,并且大大提高了定位效率和资源利用率。 但是本文实验仍有不足,西门子程序集具有代表意义,但是版本过少,实验中植入的缺陷比较简单,而在实际应用中可能较为复杂。因此,后续将在实际应用中考验本文方法的可行性,并通过不断改进,使代码缺陷定位方法更加智能、精确。 [1] JAMES ARTHUR JONES.Empirical evaluation of the tarantula automatic fault-localization technique[C].Proceeding of the 20th IEEE/ACM International Conference on Automated Software Engineering,2005:273-282. [2] BEN LIBIT,MAYUR NAIK,ALICE X.Scalable statistical bug isolation[C].Proceedings of the 2005 ACM SIGPLAN Conference on Programming Language Design and Implementation,2005:15-26. [3] ZHANG LI,CAI MING,CHAI HUI.Improvement of relevant predicate evaluation bias method for sober-based fault localization[J].Journal of Fudan University (Natural Science),2009,48(6):815-822. [4] LIANG GUO,ABHIK ROYCHOUDHURY,TAO WANG.Accurately choosing execution runs for software fault localization[C].Compiler Construction.International Conference, 2006:80-95. [5] STEVEV P REISS,MANOS RENIERIS.Encoding program executions[J].IEEE Computer Society,2001:221-230. [6] STEVEV P REISS,MANOS RENIERIS.Fault localization with nearest neighbor queries [C].18th IEEE International Conference on Automated Software Engineering,2003:30-39. [7] D YATES,N MALEVRIS VENUE.Reducing the effects of infeasible paths in branch testing[J].ACM SIGSOFT Software Engineering Notes,1989,14(8):48-54. [8] A BERTOLINO,M MARRE.Automatic generation of path covers based on the control flow analysis of computer programs[J].IEEE Transactions on Software Engineering, 1994,20(12):885-899. [9] H AGRAWAL,J R HORGAN,S LONDON,et al.Fault localization using execution slices and data-flow test[C].In the Proceedings of the 6th International Symposium on Software Reliability Engineering,1995:143-151. [10] W E WONG,Y QI.Effective program debugging based on execution slices and inter-block data dependency[J].The Journal of System and Software,2006:891-903. [11] JIAN YU,QIANSHENG CHENG,HOUKUAN HUANG.Analysis of the weighting exponent in the FCM[J].IEEE Transactions on System,Man and Cybernetics,2004,34(1):634-639. [12] 肖满生,阳娣兰,张居武,等.基于模糊相关度的模糊C均值聚类加权指数研究[J].计算机应用,2010,30(12):3388-3390. [13] BIRGIT HOFER,ALEXANDRE PEREZ,RUI ABREU,et al.An evaluation of similarity coefficients for software fault localization[J].Pacific Rim International Symposium on Dependab Computing,2006. (责任编辑:黄 健) Fault Localization Method Based on Path Clustering Similar path analysis method and statistical method based on the element information are two basic methods for program fault localization.Through theoretical and environmental analyzing of the above two methods, we found the they have the following problems: the existence of the redundant path will reduce the efficiency of the overall localization;statistical method based on the element information consider the suspicious degree rank of predicate or statements, but the program generally includes plenty of predicate and statement which have no contribution to fault localization,this method ignore the meaningless elements time-consuming statistics.To solve the above problems, path clustering is added to the algorithm,so a fault localization algorithm Pbtc is provided. In this paper,we build experiment based on theoretical research.By comparing with three other classic fault localization methods,the effectiveness of the proposed method is verified in improving the accuracy of the fault localization. Path Characteristics;Clustering Algorithm;Path Difference;Fault Localization 黄小红(1989-),女,河南平顶山人,上海理工大学光电信息与计算机工程学院硕士研究生,研究方向为软件工程、缺陷定位。 10.11907/rjdk.161813 TP301 A 1672-7800(2017)003-0003-043 基于聚类分析的计算方法
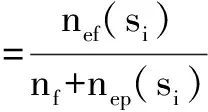
4 实验

5 结语
