海量图书检索信息的快速查询系统优化设计研究
2017-04-10高玉平
高玉平

摘 要: 以往依据关键词的检索方法,在对海量图书检索信息进行查询过程中,无法满足海量信息的大批量检索需求,存在查询效率低和误差高的缺陷。因此,设计基于分布式架构的海量图书检索信息的快速查询系统,系统中的各组件通过并行数据库和分布式存储实现交互。该系统的功能模块包括用户管理模块、数据抽取模块、索引创建模块、文本查询模块及索引检索模块。分析了系统各功能模块的设计和实现过程,这些功能模块共同对外提供图书信息的快速查询服务。实验结果表明,所设计系统可实现海量图书检索信息的快速、精确查询,并且具有较高的索引创建和索引检索性能。
关键词: 海量图书信息; 信息检索; 快速查询系统; 分布式架构
中图分类号: TN911?34; TP39 文献标识码: A 文章编号: 1004?373X(2017)06?0005?05
Abstract: The previous keywords retrieval method can not meet the retrieval requirements massive information in the query process of information retrieval for mass books, and has defects of low query efficiency and high error. Therefore, a fast query system for massive bookinformation retrievalthe is designed. Each assembly in the system realizes their interaction by means of parallel database and distributed storage. Function modules of the system are user management module, data extraction module, index creation module, text query module and index retrieval module. The process of each function module′s design and implementation of the system is analysed. These function modules provide a fast query service of book information. The experimental results indicate that the system can realize fast and accurate query of retrieval information of massive books, and has high index creation and index retrieval performance.
Keywords: massive book information; information retrieve; fast query system; distributed framework
0 引 言
随着信息技术和互联网技术的快速发展,当前的信息总量不断增加。图书是重要的信息存储方式,图书信息的数量和规模也呈现膨胀式增长趋势。从海量图书信息中快速获取用户所需的数据,成为相关人员着手解决的关键问题[1?3]。而以往的依据关键词的检索方法,对海量图书检索信息进行查询过程中,无法满足海量信息的大批量检索需求,存在查询效率低和误差高的缺陷[4?5]。文献[6]通过分词方法完成海量图书检索信息的查询,该方法按照相应的规范和方法对文本进行自主分词,再对检索结果进行词汇匹配分析,完成图书检索信息的快速查询,但是该方法无法对中文进行有效分词,存在查询准确率低的缺陷。文献[7]分析了依据局域网以及纯文本种类的图书信息查询系统,该种系统需要对各接口进行二次开发,存在工作量高的缺陷,导致图书信息查询效率大大降低。文献[8]提成了依据关键词全文检索的图书信息查询方法,但是关键词通常无法准确反映用户的查询意图,该方法会向用户显示大量的信息,存在查准率低的问题。文献[9]设计了依据Web的图书信息查询系统,采用Web技术从海量图书检索信息中查询用户所需信息。但是海量的图书信息会降低用户查询兴趣度,并且从海量信息中采集满足用户的有价值信息,需要耗费大量的时间。文献[10]依据关键词的检索方法,对海量图书检索信息进行查询过程中,无法满足海量信息的大批量检索需求,存在查询效率低和误差高的缺陷。
针对上述问题,设计了基于分布式架构的海量图书检索信息的快速查询系统。实验结果表明,所设计系统可实现海量图书检索信息的快速、精确查询,并且具有较高的索引创建和索引检索性能,取得了令人满意的效果。
1 海量图书检索信息的快速查詢系统优化设计
1.1 系统的架构设计
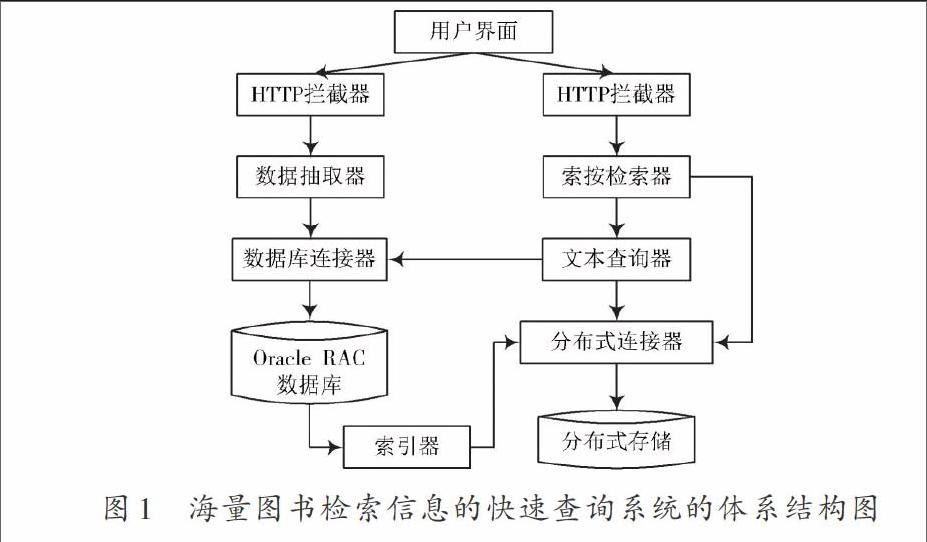
基于分布式架构的海量图书检索信息的快速查询系统的结构图如图1所示。从图1可以看出该系统包括用户界面、HTTP拦截器、数据库连接器、数据抽取器、索引器、索引检索器、文本查询器及索引分布式连接器等组件。这些组件间实现交互的连接件为并行数据库 Oracle和分布式存储。
用户界面组件通过JSP技术完成界面的展示,通过Struts2技术分析用户提成的图书信息查询申请,采用JDBC技术访问Oracle数据库,实现数据库数据的读写操作,塑造依据B/S体系结构的Web应用程序。
数据库连接器、数据抽取服务、HTTP拦截器、索引更新服务组件,用于实现海量图书信息数据抽取以及文本索引维护。数据库连接器、文本查询服务、HTTP拦截器以及索引检索服务组件实现关键词查询,主要有海量图书信息全文查询和文本信息查询两部分。其中,数据库连接器实现JDBC同Oracle数据库间的连接。数据抽取器实现对数据库的CRUD处理,分布式连接器实现应用程序同分布式存储间的连接,进而采用相关服务,完成索引的管理和信息查询。HTTP拦截器实现用户申请和响应申请。索引检索器可控制分布式存储中的检索服务,实现海量图书信息索引的检索。文本查询器完成通过rowid及其他查询条件查询数据库的操作任务。分布式存储是依据全文索引的分布式存储系统,其在Lucene服务引擎中集成了大量接口,确保用户调用相关操作命令,完成图书信息的查询操作。分布式存储可将图书信息的全文索引分割成不同的分段、分片以及分片副本,并分别保存在分布式存储集群中不同数据节点并可对不同的分片进行操作和协助,确保不同数据节点间通信的均衡化。一个索引由不同的分片构成,各分片可看成微小的搜索引擎。
对索引进行查询是分布式处理过程,也就是分布式存储应查询索引中的不同分片中的数据复制,并将查询结果汇总至单一结果集中。同种硬件条件下,该种查询方式可支撑海量的信息负载查询,实现海量图书检索信息的快速查询。系统中的数据库存储Oracle RAC组件,完成数据的并行存储。
1.2 系统功能模块的设计与实现
设计的海量图书检索信息快速查询系统通过HTTP服务方式对外提供服务。该系统的功能模块包括用户管理模块、数据抽取模块、索引创建模块、索引重构模块、文本查詢模块及索引检索模块。这些模块共同对外提供图书信息的快速查询服务。
系统中的用户管理模块对用户信息进行管理,依据不同的用户种类,修改用户权限信息和登录信息等;数据抽取模块采集数据库中的文本备份数据,将数据集反馈给索引创建模块完成数据的操作。索引创建模块读取采集的文本数据集,通过分布式存储创建索引引擎,塑造文本索引,同时将索引写入文件系统中;索引检索模块实现用户的图书信息检索,可检索相应分区中的索引数据集,并且将获取的索引数据集当成文本查询模块的查询条件;文本查询模块采集数据库中文本数据,将满足rowid的匹配数据集合,通过多线程手段打包返回。
1.2.1 数据抽取模块的设计与实现
设计的数据抽取模块采用Quartz 定时器技术,在每天的0:00运行数据抽取模块的定时任务,并将抽取出的文本信息结果集当成索引创建模块的输入信息。设置创建索引的终止时间为定时任务的开始时间,采集数据库中低于该时间的全部分区数据,依据分区名创建索引。如果创建索引失败,则结束本次创建索引任务,等待下次创建索引任务开始。
Quartz定时器能够同J2EE 和J2SE应用程序融合,运行十个、百个、甚至万个Jobs的日程序表。通过Java库发布文件(.jar文件)开发Quartz,该文件中存在全部的Quartz功能,这些功能的关键接口(API)为Scheduler接口,该种接口可实现任务在日程中的融合和终止。Quartz定时器内的任务可为Java代码,定时器通过调用作业,确保作业处于工作时间。定时器可创造可循环的调度表。定时任务通过Quartz定时器,在固定的时间内运行数据抽取模块,采集数据库中不同分区数据,并将采集到的数据读入内存,向文本索引创建过程提供依据。图2时序图描述了定时任务采用数据抽取模块完成文本信息采集的流程。
1.2.2 索引创建模块设计与实现
采用类IndexTaskManager完成索引创建模块,该类采用Quartz定时任务器申请运行,通过数据抽取模块、数据库连接请求执行以及分布式存储索引库连接器交互,实现索引创建模块的运行。图3给出了索引创建模块的运行流程图。
1.2.3 索引检索模块的设计与实现
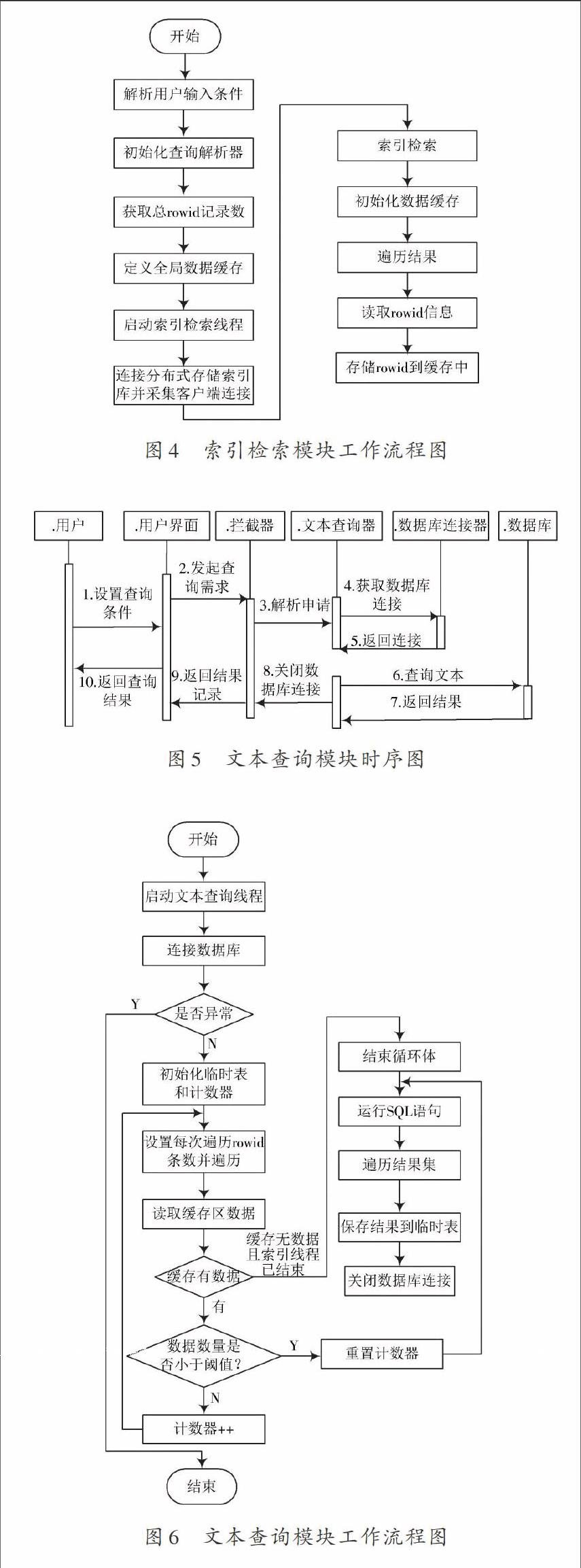
塑造全文索引过程中,各分区名以及索引名间相互对应。依据不同的发送日期划分不同的数据分区。因此,当用户查询条件中不存在起始和终止时间,则检索索引索引文件;否则按照用户申请的时间,检索相应的索引分区名,极大增强了图书信息的检索效率。索引检索模块的结果为rowid的集合,是文本查询模块进行分析的依据。索引检索模块的运行流程图如图4所示。
1.2.4 文本查询模块的设计
通过文本查询器运行文本查询模块,其采用数据连接器同Oracle 数据库相连,检索数据库分区表,同时将检索结果反馈给用户。文本查询模块的时序图如图5所示。文本查询模块采用文本查询线程,运行数据库查询任务。该线程采集全局共享缓存区中的 rowid信息,同时依据用户查询条件,构成SQL 语句,对数据库进行查询,最终向数据库临时表中存储查询结果,为用户界面进行导出数据提供服务。文本查询模块通过SQL查询数据库,因为 Oracle数据库要求SQL的最高长度为4 500个字符,因此,设置rowid每次查询700个,利用In方式查询。文本查询模块的运行流程图如图6所示。
2 实验分析
通过实验对本文设计的基于分布式架构的海量图书检索信息的快速查询系统的性能进行测试。实验通过表1和表2 的多条件检索和单关键词查询条件检索测试用例,检测本文系统的测试结果的有效性。
通过表1和表2可以看出,本文系统可准确查询出多条件检索和单关键词查询条件检索结果,是有效的图书检索信息查询系统。
实验对基于关键词的信息查询系统和本文系统的性能进行检测时,主要对两种系统的索引创建以及检索性能进行测试。检测数据是单台Oracle数据库服务器中的3.5亿条图书信息记录,分布式存储以及检索服务器模拟3个服务器,同时模拟6个分片以及单个备份节点当成检测环境,对本文系统的查询性能进行检测。
分析两种系统的CPU占用率、内存占率、I/O的使用率等指标,对本文系统的索引创建性能进行检测。两种进行图书检索信息查询过程中的索引创建压力测试结果如图7和图8所示。
具体性能值如表3,表4所示。
分析图7、图8以及表3和表4可得,相对比基于关键词的图书信息查询系统,本文系统创建索引的效率和性能较高,并且会增加文件存储空间;本文系统的I/O读写更为频繁,吞吐量更高。说明本文系统能够完成海量图书检索信息的快速、准确查询。
表5和表6分别是基于关键词的图书信息查询系统以及本文系统的索引检索性能测试结果,包括样本数量、吞吐量以及平均值三个参数。其中,样本数量表示发送到服务器的全部用户申请数量;吞吐量值是系统服务器单位时间操作的用户查询申请数;平均值是系统进行图书信息查询过程中的总运行时间同申请数的比值。
对比表5和表6可以看出,本文系统的样本数量、吞吐量以及平均值均优于基于关键词的信息查询系统,本文系统具有较高的索引检索性能。
通过上述实验可得相对于基于关键词的信息查询系统,本文系统的索引创建性能和检索性能都较高,可以满足用户的查询需求。
3 结 论
以往的依据关键词的检索方法,在对海量图书检索信息进行查询过程中,无法满足海量信息的大批量检索需求,存在查询效率低和误差高的缺陷。因此,本文设计基于分布式架构的海量图书检索信息的快速查询系统,该系统中的各组件通过并行数据库和分布式存储实现交互。该系统的功能模块有用户管理模块、数据抽取模块、索引创建模块、索引重构模块、文本查询模块及索引检索模块。分析了系统各功能模块的设计和实现过程,这些功能模块共同对外提供图书信息的快速查询服务。实验结果表明,所设计系统可实现海量图书检索信息的快速、精确查询,并且具有较高的索引创建和索引检索性能。
参考文献
[1] 罗芳,李春花,周可,等.基于多属性的海量Web数据关联存储及检索系统[J].计算机工程与科学,2014,36(3):404?410.
[2] 刘鹏.基于Hadoop的结构化电子病历存储检索系统研究与改进[J].中国数字医学,2015,10(1):40?42.
[3] 孙霞,禹龙,田生伟,等.基于一致性Hash的分布式海量分子检索模型[J].计算机应用,2015,35(4):956?959.
[4] 李维乾,李莉,张晓滨,等.Hadoop平台下突发水污染应急预案并行化处置[J].西安工程大学学报,2015,29(6):733?739.
[5] 曹锋.基于细微特征区分的海量图像检索模型仿真[J].计算机仿真,2015,32(9):368?371.
[6] 董岳珂.发现系统引发的关于信息素养教育的思考[J].图书馆论坛,2014,34(4):58?63.
[7] 宋一兵.基于本体的文献情报信息检索方法研究[J].青岛理工大学学报,2015,36(4):82?86.
[8] 张广庆,葛唯益,贺成龙.基于Simhash的海量相似文档快速搜索优化方法[J].指挥信息系统与技术,2015,6(2):61?65.
[9] 万艳丽,雷行云,王岩,等.基于层次化深度学习的海量医学影像组织与检索研究[J].医学信息学杂志,2015,36(5):46?51.
[10] 黄杰,曹锦梅,努尔艾拉·阿布力孜,等.维吾尔语在图书馆数据库查询系统中的应用[J].电脑与信息技术,2014,22(5):53?55.
