融合链接结构的主题爬虫算法
2017-04-07刘韶涛李洪胜
刘韶涛, 李洪胜
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)

融合链接结构的主题爬虫算法
刘韶涛, 李洪胜
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)
通过分析基于内容的链接选择Best-First算法,引入能够体现链接价值的HITS(hyperlink induced topic search)算法,提出了新的链接选择策略.将两种算法相结合,新的爬虫不仅仅考虑页面内容,同时将链接结构加入进来,使得在下载的过程中能够保证主题相关性和权威性,缓解爬虫在爬行阶段的“近视”现象.结果表明:新的爬行策略比单一的Best-First算法具有更好的性能表现. 关键词: Best-First算法; 链接结构; HITS算法; 爬行策略
随着互联网的迅猛发展,网络上的信息量也呈指数型增长,如何从数量巨大的网络资源中获取自己想要的信息一直是研究的热点.与此同时,针对特定领域而制定的垂直搜索引擎应运而生.该搜索引擎具有领域特性,其特点是专,精,检索范围小,并且精度高,往往能给用户带来更好的体验[1].垂直搜索引擎通过分布在网络上的主题爬虫,下载用户所要获取的网页,与一般搜索引擎所使用的爬虫不同[2],主题爬虫能够根据预先定义的领域主题.只爬取与主题相关的页面,而忽略不相关的链接.目前使用比较广泛的爬行策略算法大都是基于网页内容的,即通过页面内容或者链接的锚文本与主题的相似度决定所要爬取链接的优先级.用户希望所下载的页面不仅仅只是主题相关,还应该是在领域内比较权威的,并能够被其他网页所认可的,优秀的爬虫应该具有持续发现更多相关页面的能力.因此,本文基于内容爬行Best-First算法的基础上,融合一种能体现链接价值的HITS算法,提出一种新的爬行策略.
1 主题爬行策略与问题分析
1.1 主题爬行策略
主题爬虫根据不同的爬行策略决定要下载的链接[3].目前,主题爬虫的爬行策略形式多样,而绝大部分都是基于文本内容的,其主要考虑以下3个要素:网页正文,链接锚文本,以及锚文本上下文.分别计算这3部分与主题关键词的相似度,决定待下载链接的下载权重.
Best-First[4]算法是Cho提出的一种启发式算法,以简洁高效的特点而著称.它的主要思想是设置两个队列,一个为权重URL队列,一个为已访问URL队列.每一个提取出的URL通过链接选择策略,计算出一个得分,将其放入权重队列,然后,每次从中选择得分最高的一个下载.链接得分的计算目前有以下3种方法[5].
1) 同一个页面中的链接具有相同的权重分.
2) 链接权重通过自身锚文本与主题的相似度计算得出,在这种情况下,同一个页面中的链接可能会有不同的下载权重.
3) 结合第1),2)策略,页面P中第i个链接的权重等于页面P自身的相似度得分加上链接自身锚文本的相似度得分,即
(1)
Best-First算法基于如下原理:如果一个页面是主题相关的,那么,这个页面指向相关页面的可能性就比较大.除此之外,链接锚文本被看作是链接所指向页面的一个总结与概括,而锚文本又不总是可以概括所指向的页面内容,因此,采用第3种页面和锚文本相结合的方式效果最好.
1.2 问题分析
由于基于Best-First算法的爬虫在爬行的过程中,所采用的爬行策略是单纯基于文本内容的,即对于候选链接的选择主要考虑页面内容,以及链接的锚文本,这就使得爬虫所爬取的链接虽然是主题相关的,但是不能确定这个页面在所属的领域是不是权威的,即能不能被其他相关页面所认可,缺乏链接价值方面的考虑.
此外,由于网络的结构特性,相同主题的页面往往聚集在一起,形成一个个主题团.爬虫在爬行过程中,由于每次选择得分最高的一个链接下载,导致在爬行的某些阶段,爬虫会出现局部最优的问题[6].经过分析发现,爬虫在碰到一些中心页面时,陷入了以中心页面为中心的主题团,导致产生了“近视”现象[7],难以发现更多的相关页面.
因此,需要引入一个可以通过链接结构体现链接价值的算法改善爬虫的运行.目前,PageRank算法[8]和HITS算法[9]是比较有代表性的两个算法,主要是通过链接之间相互指向关系代表链接的重要性,它们是基于以下两个假设:
1) 如果一个网页被其他网页指向,被指向得越多,说明这个网页越权威(即有价值);
2) 如果一个网页和另外一个网页有链接相连,说明这两个网页的主题是相似的.
HITS算法与PageRank算法最大的不同在于:HITS算法是与主题相关的,即在某一个领域主题内是有价值的,可以很好地体现网络的结构特性.
2 HITS算法与爬行策略改进
2.1 HITS算法

图1 中心页面和权威页面Fig.1 Hub and authority pages
HITS算法是由Kleinberg于1998年首先提出的,应用于IBM研究中心的CLEVER工程组,用来权衡每一个页面的重要性.它定义了两个概念:权威值(Authority)和中心值(Hub).高权威值的权威页面是指有很多入链的页面,这些页面在某一个主题或者领域中有很权威的内容,其他网页都很乐意去指向它;高中心值的中心页面是指有很多出链的页面,这些出链指向那些在某一主题领域拥有很大影响力的网页.通常来说,好的中心页面会指向许多权威页面,好的权威页面会被许多中心页面所指向[10],如图1所示.
HITS算法根据关键词确定一网络子图G(V,E)(V为网络子图的节点集,E为边集),然后,迭代计算每一个网页的权威值和中心值,具体有如下4个流程.
1) 使用领域主题关键词在通用搜索引擎(如google,baidu)进行查询,提取K个链接作为root集.
2) 使用链接分析扩展root集,将链接的出链以及不多于d(d=50)个的入链加入到root集中,扩展后的root集称为base集.
3) base集中的每个页面都有两个属性ai,hi,它们分别代表页面i的权威值和中心值.若G有n个节点,设a,h为n维向量,并初始化a,h,a0=1,h0=1.然后,进行I,O操作.即
I操作为
O操作为
4) 权威值和中心值的计算式分别为
页面的价值可以通过计算出的权威值和中心值很好地体现,并藉此进行规范化.同时,由于HITS算法的主题相关特性,使权威页面和中心页面同时在领域主题内是主题相关的.正是由于这一特性,可以用来指导爬虫的运行.
2.2 改进的爬行策略
传统的主题爬虫选择候选链接主要是基于链接的以下两个属性:
1) 链接所在页面(即父页面)的主题相似度;
2) 链接自身锚文本的主题相似度,这是单纯基于文本内容的考量.
如果从全局性出发,通过链接结构体现链接价值,每个链接还应该有另外两个属性,也就是权威值和中心值.在链接权重得分的计算过程中,不仅需要考虑文本内容,还要加入链接价值的考量.因此,网页P中第i个链接的权重得分应该由以下两部分组成:基于文本内容的的权重得分和基于链接价值的权重得分.
LinkScore(i)=LinkScoreText(P,i)+LinkScoreValue(i).
为了实现在爬行过程中加入链接价值考量这一想法,提出了一种内容与链接结构相融合的主题爬虫.通过将Best-First算法与HITS算法相结合,使得爬虫除了考虑页面文本内容以外,还加入了链接的权威值和中心值.其中,文本内容的考量通过父页面与主题的相似度和链接锚文本与主题相似度体现,链接价值通过HITS算法计算出的权威值和中心值体现,新的链接分计算公式为
LinkScore(Pi)=A×(SimPage_Content(P)+B×SimAnchor_Text(i))+

(2)
为了使新的算法能同时兼顾文本内容和链接价值,对各个部分分别赋予不同的权重,其中参数A+B+C=1,用于控制父页面、锚文本及HITS算法得分的比重,α和β用来控制权威值与中心值的权重,相对于α来说,β值设置的比较小,因为根据HITS算法计算出来的权威值和中心值,会将网页分为以下两种类型:高权威值低中心值的权威页面和低权威值高中心值的中心页面.
如果分别将它们用X,Y代替,那么,通过以上公式的计算,能够保证X>Y,而这正是想要得到的结果.
父页面以及锚文本的得分是来源于父页面、锚文本与主题的相似度[11].首先,将提取出来的文本内容、锚文本进行分词、去停用词处理;然后,映射到向量空间,使用训练好的TF-IDF主题模型计算每个词的权重;最后,通过余弦相似度方法计算与主题的相似度,即

(3)
式(3)中:Text为文本内容;t为主题表示;W1,k;W2,k分别为文本和主题中词条k的权值.
任何一个网页正文都能用一个n维特征向量表示,因此,网页与主题之间的相似度也就转变成了向量间的距离计算.在计算过程中,将文本内容和主题分别表示成向量,并赋予TF-IDF权重,然后,通过式(3)计算相似度.
新算法描述如下:新算法通过维护3个队列进行爬行,分别为权重队列、已下载队列、错误队列,具体的实现由以下5个步骤组成.算法流程图,如图2所示.
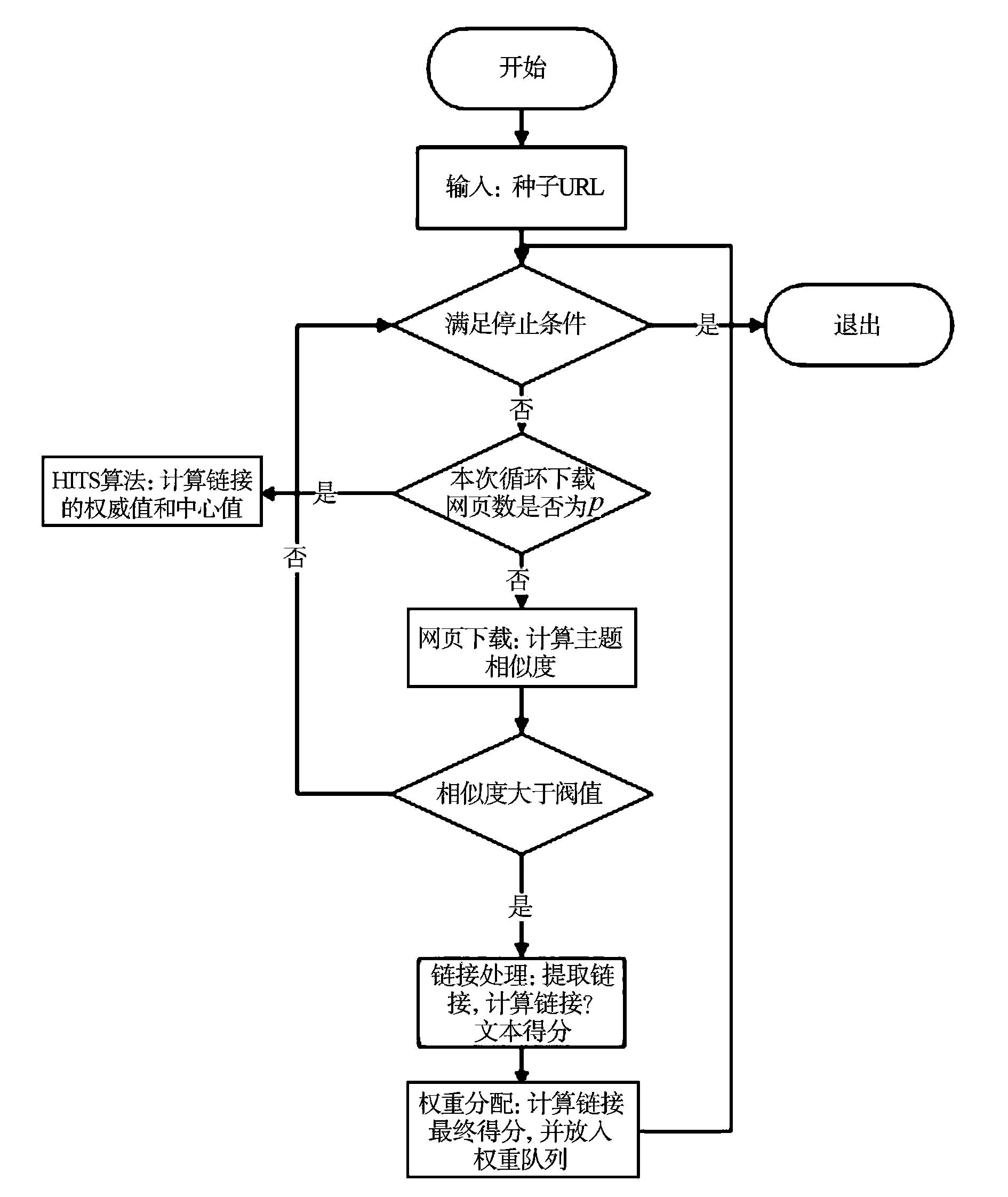
图2 算法流程图Fig.2 Process of algorithm
步骤1 输入.在主题爬虫的开始阶段,爬虫需要接受一组种子链接作为爬虫爬行过程的开始.人工筛选出关于“体育”、“财经”主题的各9个链接作为种子链接,将这9个种子链接赋予权重1,放入权重队列中;此外,这9个链接也将作为HITS算法的初始root集.
步骤2 页面下载.从权值队列中根据式(2)提取得分最高的链接(在爬行初期,由于网页数目较少,因此,使用式(1)计算得分),如果此链接在已下载队列中,则结束当前循环;否则,对这个链接进行下载,并将其放入已下载队列中.然后,针对已下载的这个链接,提取出其中的网页正文,并且对正文进行分词、去停用词、去低频词处理.
采用VSM(vector space model)向量空间模型将其转化为空间向量,权值为TF-IDF权重(TF-IDF模型在爬行之前,通过主题相关的训练集可以得到),并通过式(3),计算此网页与主题的相关度.如果相关度大于预先定义的阈值,那么,此网页为主题相关页面,并将此链接放入HITS算法节点集中,保存当前网页.
步骤3 链接处理.对于页面相关度大于阈值的网页(parent_page),提取其中的链接(child_page),根据链接自身锚文本计算与主题的相关度,得到锚文本的得分.将parent_page→child_page关系加入到HITS算法边集中,然后,将child_page加入到节点集中.
步骤4 权重分配.每当页面下载数为p的时候,进行HITS算法的迭代计算,直到算法收敛(在爬行初期,此步可忽略).然后,根据式(2)计算出每个链接的最终得分,去除得分较低的链接,将其余的链接加入到权重队列中.
步骤5 扩展. 重复步骤2~4,直到算法满足停止的条件,即下载的页面数达到最大值,或者权重队列为空.
3 实验部分
3.1 实验准备
为检验新算法的性能,设置3个实验,分别基于Best-First算法、Best-NFirst算法及所设计的新算法.Best-NFirst算法是Best-First算法的改进算法,其每次选择得分最高的N个链接下载,意为改善Best-First算法的局部最优现象.Best-First算法和Best-NFirst算法的爬虫使用网页内容与链接锚文本得分决定权重队列中链接下载的优先级.
实验采用Python语言实现,文本分词时,使用了Python编程领域中较为常用的jieba分词系统,jieba分词支持3种分词模式:精准模式、全模式和搜索引擎模式,文中采用搜索引擎模式进行分词.硬件环境为:Intel 酷睿i3-2310 2.5 GHz主频的CPU,4 GB内存和500 GB硬盘.
为检验爬虫的性能,设置爬虫爬取5 000个网页时自动停止.在爬行开始之前,通过“搜狗实验室”提供的新闻分类语料库对TF-IDF模型进行训练,“搜狗实验室”提供的分类包含“教育”、“体育”、“娱乐”等10多个不同主题的训练文本.实验选择对“体育”、“财经”主题的网页进行搜集,因此在爬行的过程中,通过训练好的相应的TF-IDF主题模型计算网页正文内容的相关度,如果相关度得分大于阈值,那么,认为此网页为主题相关页面,阈值通过人工挑选的200个主题相关页面的相似度得分确定,初始种子链接如表1所示.
在性能评价方面,通过算法的查准率、查全率以及算法的运行时间综合考量.查全率为爬取的主题相关页面与所有相关页面的比值,查准率又称为精确率,为所爬取得相关页面与所有页面的比值.

表1 种子URL
3.2 实验结果
“体育”主题、“财经”主题精确率对比图,如图3,4所示.图3,4中:r为算法收获率;n为下载网页数目.由图3,4可知:随着n的增加,r变化;基于Best-First算法的爬虫由于只是考虑了文本内容信息,使得爬虫过早的陷入了局部最优的陷阱,导致在爬行的过程中收获率下降得很快,难以发现更多的相关页面,而Best-NFirst算法的爬虫并没有表现出预期的结果.可能是由于每次下载得分最高的N个链接,导致也将许多不相关页面加入了进来,影响了实验的结果.
融合了HITS算法的新爬虫由于加入了链接结构使得爬虫具有了全局特性,HITS算法是主题相关的,爬虫在爬行过程中可以不断的发现更多的相关页面,取得了不错的效果.

图3 “体育”主题精确率对比图 图4 “财经”主题精确率对比图Fig.3 Comparing of precision Fig.4 Comparing of precision rate with sports theme rate with finance theme
在查全率方面,由于爬虫的爬行是一个动态的过程,要想统计整个互联网中所有的主题相关页面几乎是不可能完成的任务,因此,挑选了一部分与主题相关网页检测爬虫的查全率.经过测试,Best-First算法的查全率为67%,Best-NFirst算法的查全率仅为69%,而融合了HITS算法的爬虫的查全率为75%.这是由于HITS算法本身就是主题相关的,因此,对于相关网页的判断会更加准确.算法运行时间的对比,如表2所示.表2中:t为运行时间.
由表2可知:在运行时间上,虽然新算法在收获率上有较好的表现,可是由于融合了HITS算法,导致爬虫的运行效率远远落后其他两种算法,特别是随着爬虫的运行,HITS算法的迭代会占用更多的时间,这也是以后需要改进的方向.

表2 算法运行时间对比
4 结束语
基于内容的主题爬虫由于缺乏全局特性,使爬虫在爬行过程中难以持续发现更多相关页面问题,提出了一种新的爬虫策略,引入链接全局特性的HITS算法,新的算法在爬虫的收获率上有较好的表现.下一步将对新算法的时间复杂度做出优化,使爬虫具有更好的实用性.
[1] 闵钰麟,黄永峰.用户定制主题聚焦爬虫的设计与实现[J].计算机工程与设计,2015,36(1):17-21.
[2] TAYLAN D,POYRAZ M,AKYOKUS S,etal.Intelligent focused crawler:learning which links to crawl[C]∥International Symposium on Innovations in Intelligent Systems and Applications.Madrid:IEEE Press,2011:504-508.
[3] MENCZER F,PANT G,SRINIVASAN P,etal.Evaluating topic-driven web crawlers[C]∥Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Queensland:ACM,2001:241-249.
[4] RAWAT S,PATIL D R.Efficient focused crawling based on best first search[C]∥IEEE 3rd International of Advance Computing Conference.Ghaziabad:IEEE Press,2013:908-911.
[5] BATSAKIS S,PETRAKIS E G M,MILIOS E.Improving the performance of focused web crawlers[J].Data and Knowledge Engineering,2009,68(10):1001-1013.
[6] FILIPOWSKI K.Comparison of scheduling algorithms for domain specific web crawler[C]∥IEEE Conference Publications of Network Intelligence Conference.Nara:IEEE Press,2014:69-74.
[7] 罗林波,陈绮,吴清秀.基于 Shark-Search 和 Hits 算法的主题爬虫研究[J].计算机技术与发展,2010,20(11):76-79.
[8] PAGE L,BRIN S,MOTWANI R,etal.The pagerank citation ranking: Bring order to the web[R].Washington D C:Computer Science,1998:66-73.
[9] ZHENG Ling,BO Yang,ZHANG Ning.An improved link selection algorithm for vertical search engine[C]∥1st International Conference on Information Science and Engineering.Nanjing:IEEE Press,2009:778-781.
[10] 林子皓.主题爬虫的设计与实现[J].计算机技术与发展,2014,24(8):99-102.
[11] DU Yajun,PEN Qiangqiang,GAO Zhaoqiong.A topic-specific crawling strategy based on semantics similarity[J].Data and Knowledge Engineering,2013,88(18):75-93.
(责任编辑: 陈志贤 英文审校: 吴逢铁)
Topic Crawler Algorithm With Link Structure
LIU Shaotao, LI Hongsheng
(College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China)
By analyzing the content-based link selection Best-First algorithm, and introduce the HITS (hyperlink induced topic search) algorithm which can reflect the link value, a new kind of link selection strategy is proposed: Combination of two algorithms, new crawler not only consider the page content, but also the link structure, and can ensure topic relevance and authority in the process of downloading; at the same time, ease the “short-sighted” phenomenon in crawling stage. Experimental result shows the new crawling strategy has better performance than that of the single Best-First algorithm. Keywords: Best-First algorithm; link structure; HITS algorithm; crawling strategy
10.11830/ISSN.1000-5013.201702012
2015-06-24
刘韶涛(1969-),男,副教授,主要从事软件体系结构与软件复用的研究.E-mail:shaotaol@hqu.edu.cn.
福建省科技厅科研基金资助项目(2011H6016)
TP 311
A
1000-5013(2017)02-0195-06
