大数据预测处理模式研究
2017-03-24王金海

摘 要:大数据的时代,数据的产生和收集是基础,数据挖掘是关键,在日新月异的应用背后,产生的是数据爆炸式增长和来自大数据分析的挑战,如何有效的利用这些数据也是一个难题。所以研究大数据各种预测的模型的研究就尤为重要,本文结合大数据时代的数据特点,研究大数据的预测处理模式,提出一种算法融合的模型框架,并通过实验数据集验证模式。
关键词:大数据;数据挖掘;特征工程;模型融合;Hadoop
1 研究背景及意义
大数据时代当前面临的挑战是根据大数据进行预测[1]研究,利用已知数据进行预测的模式产出,本文对大数据预测处理模式进行研究,同时创新性的提出一种融合算法模型框架,最后用數据集[3]来验证模型的准确性。
2 预测处理模式研究
基本处理模式
本文研究的大数据[4]预测处理模式主要分为几个过程,如下:
1.问题与业务理解
问题与业务的理解是对数据挖掘的需求进行确认,对预测与挖掘目标有一个明确的定义。
2.数据收集与预处理
原始的数据要倾国清洗或者预处理的方式,才能使最终的结果准确或者可用。
3.数据挖掘
a)特征工程
b)模型训练
c)模型评估
4.结果解释和评估
特征工程
特征工程[5]是将原始数据转化为特征,在进行特征工程的时候,影响其预测结果有三大因素:模型的选取是否合适,可以用的数据是否好用,提取的特征是否实用。
数据预处理
对数据进行挖掘之前,必须首先准备好挖掘的数据,需要对数据进行预处理,提高分类或预测的准确性、效率和可扩展性。
1.数据清理。数据清理是指在消除或者减少数据中噪声和处理缺失值数据预处理。
2.相关性分析。犹豫数据集中的许多属性与挖掘任务本身可能是无关的。
3.数据转换。利用概念分成,可以将数据泛化到更高层次的概念。
特征选择
特征选择是根据有意义的特征输入数据挖掘的算法和模型进行训练。特征选择是特征处理的核心部分。包括以下几种方法:
1.过滤特征[6]:该思路是自变量和目标变量之间的关联。
2.封装特征:该思路是通过目标函数来看是否加入一个变量。
3.嵌入特征:该思路是学习器来自动选择特征。
算法框架
本问研究内容创新性采用算法模型的融合方式,即多模融合的学习算法框架 ,建立组合预测方法,得到优选的预测处理模式,克服单个预测算法的缺点,提升了算法预测的准确性。
GBDT
GBDT算法是Boosting算法的一种具体实现形式,它是一种非线性的模型,每次迭代都是在减少残差的梯度方向新建一颗决策树,迭代多少次就会生成多少决策树。
LR
LR是广义的线性模型。LR模型可以很好的并行化,其是一种线性模型,其可以处理上亿条的训练样本。但是这种线性模型限制它的的学习能力,不能处理大量的特征。
GBDT与LR的融合
GBDT的决策树的通道可以直接作为LR输入特征使用。所以本文将两种算法结合,提出一种GBDT与LR融合的算法模型。这种模型相比如人工寻找特征和特征组合,这种方法省时省力,效率更高。经过融合算法模型进行特征和特征组合的自动发现,LR的输入特征来自GBDT生成的特征。
模型评价
模型评价是验证特征工程与算法框架的重要评测环节。一般采用均方根误差评价法。
其计算公式如下。
3 实验数据集分析
数据分析
通过分析某省部分公交线路的历史公交卡交易数据,分析推测乘客的出行习惯和偏好,从而建立模型,预测未来公交客流。即:根据公交线路历史刷卡数据,预测不同公交线路6点-21点各时段的客流情况。
特征工程
原始数据包含特征Use_city features、Line_name features、Terminal_id features、Card_id features、Create_city features、Deal_time features、Card_type features、Weather features。特征按照具体的内容又可以分为:计数、比值、Flag、时间间隔、时间层级、规则、排序、地理特征等八种。由于篇幅有限,这里不详细介绍各特征。
算法框架
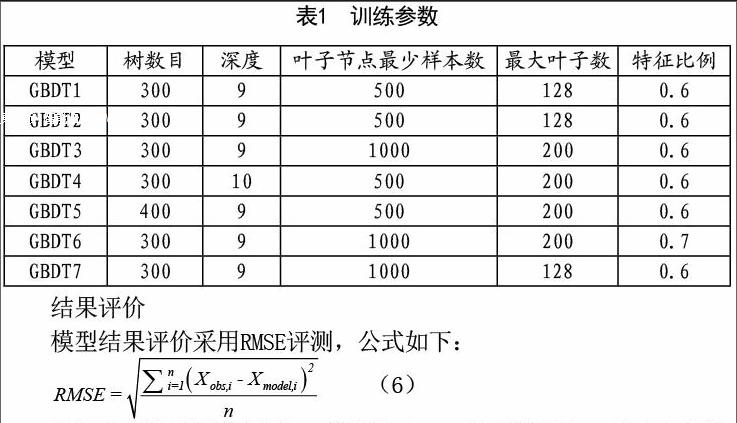
算法采用GBDT和LR融合算法,基本原理见图1,GBDT作为主要分类器,表3得到的训练参数是经过模型训练得到的。其中,GBDT3是单模型中评价效果最好的模型。经过GBDT生成的特征,下一步使用LR对GBDT生成的模型进行融合,把每个GBDT 模型对测试集的预测结果合并作为LR的训练集。
结果评价
模型结果评价采用RMSE评测,公式如下:
经过线下的预测集测试,7模型混合GBDT特征模型与LR融合的算法框架最终得到82%的评分值,说明整个预测模式效果很好。
4 结论
本文研究基于大数据的预测处理模式,研究了包括特征工程、算法框架、模型评价等大数据预测处理的关键步骤,提出多模融合算法:GBDT与LR融合算法,相比于传统算法,多模的融合算法结合了LR速度快、效率高,是一种精确、有效的预测处理算法。最后本文用真实的数据集验证了所研究的处理模式和多模算法的正确性。
参考文献
[1] 孟小峰, 慈祥, MengXiaofeng,等. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1):146-169.
[2] 李建中, 刘显敏. 大数据的一个重要方面:数据可用性[J]. 计算机研究与发展, 2013, 50(6):1147-1162.
[3] 应毅, 刘亚军, 陈诚. 基于云计算技术的个性化推荐系统[J]. 计算机工程与应用, 2015, 51(13):111-117.
[4] 赵娜. 大数据研究综述[J]. 电子测试, 2015, 14(5):87-90.
[5] Crone S F, Kourentzes N. Feature selection for time series prediction - A combined filter and wrapper approach for neural networks[J]. Neurocomputing, 2010, 73(s 10-12):1923-1936.
[6] Liu D, Li T, Liang D. Incorporating logistic regression to decision-theoretic rough sets for classifications[J]. International Journal of Approximate Reasoning, 2014, 55(1):197-210.
作者简介
王金海(1990-),男(满族),籍贯黑龙江,硕士研究生,在读学生,研究方向:智能信息处理。
