JADE结合ELA鉴别砂梨成熟度的共享性模型
2017-03-23刘辉军胡晓峰
焦 亮,林 敏,刘辉军,胡晓峰
JADE结合ELA鉴别砂梨成熟度的共享性模型
焦 亮,林 敏,刘辉军,胡晓峰
(中国计量大学 计量测试工程学院,浙江 杭州 310018)
提出了特征矩阵联合对角化(JADE)结合超限学习机(ELM)的稳健建模方法,并应用于砂梨成熟度的鉴别。砂梨近红外光谱是多种独立化合物光谱信号的随机线性混合,首先采用多元散射校正和小波变换去除原始光谱噪声,再利用JADE提取独立光谱,得到包含独立化合物浓度信息的混合矩阵;随后使用ELM算法,通过调节隐层节点个数建立稳健性强的成熟度鉴别模型。JADE利用高阶累积量全面提取原始光谱的幅值、相位信息,降低不同化合物之间的光谱干扰,而ELM隐层节点参数随机生成,两者的有机结合可使所建模型稳健性强,有利于模型的传递与共享。该方法应用于砂梨4种不同成熟度的鉴别,所建模型预测准确率为96.67%。
JADE;ELM;近红外光谱;砂梨成熟度;稳健建模
0 引言
近红外光谱技术是一种高效的无损方法,已经广泛应用于农业、工业等领域。学者们使用主成分分析(Principal Component Analysis, PCA)、偏最小二乘(Partial Least Squares, PLS)方法分析芒果、鳄梨[1-2]中可溶性固形物、干物质的含量,成功鉴别果实成熟度。传统分析方法(PCA、PLS等)是利用输入数据的二阶统计量,根据信号幅度的变化分析数据,容易出现原始数据特征信息丢失、流形结构被破坏、数据分类性能下降等问题,使所建模型稳定性较弱,不利于校正模型的转移与共享。校正模型的转移与共享能够大幅节省建模所需的经济成本,是目前研究热点之一,建立一个稳健性强,分析精度高,适用范围广的校正模型是模型传递与共享的基础[3]。近红外光谱技术对有效光谱信息的提取仍存在很多难点,如光谱复杂重叠,冗余信息量大,有效信息强度低等,且有效的光谱信息不仅存在于信号幅度中,更多存在于整个波形,需要使用高阶统计分析,以得到非高斯分布和非线性信息。如水果成熟过程中可溶性固形物、水分、酸度等的含量会发生变化[4]等,水果的近红外光谱可视为独立化合物基本光谱的随机线性组合,若将这些基本光谱组合方式的信息从原始光谱中提取出来,直接用于建立模型,对于模型的共享将大有裨益,特征矩阵联合近似对角化(Joint Approximative Diagona- lization of Eigenmatri,JADE)就是一种有效方法。
JADE是盲源信号分离(Blind Source Separation, BSS)的一种,以高阶统计量为基础[5],在源信号与混合通道参数均未知的情况下,提取具有统计独立性质的信号。Cardoso提出了特征矩阵联合近似对角化算法,对各种盲信号都具有较好的提取作用,是一种数值稳定,鲁棒性强的代数独立分量分析(Independent Component Analysis, ICA)方法,在信号分析的速度与精度上存在优势。已有学者将盲源信号提取应用于光谱数据处理领域,分解复杂样品的原始光谱,王功明[6]等针对红外光谱的黑色体系分析,利用快速ICA算法从颜料的混合光谱中提取出了基本颜料的光谱,Mishra[7]等应用高光谱技术结合JADE算法,提取花生粉和小麦粉谱图中独立成分并对其重构,实现了掺假样品的鉴别。
超限学习机算法[8](Extreme Learning Machine,ELM)是一种新型神经网络算法,它能够有效克服传统神经网络训练参数选取复杂、易陷入局部最优等问题,只需设置隐层节点数就可获得唯一的最优解。利用JADE分解光谱数据,得到独立化合物的浓度信息,降低基本光谱之间的干扰,能够提高后续分类算法的精度,ELM随机生成神经元,网络稳定性强,适用于模型转移。
本文提出JADE结合ELM算法,应用于砂梨成熟度的鉴别。首先使用多元散射校正和小波变换对原始光谱预处理,去除光谱噪声并对光谱数据有效压缩,以减少模型计算量,然后用JADE算法分解原始光谱,得到与独立化合物浓度有关的混合矩阵,最后将混合矩阵作为神经网络输入,样品成熟度作为网络输出,建立JADE结合ELM的成熟度鉴别模型。
1 JADE结合ELM模型理论基础
1.1 JADE算法提取光谱信息
JADE的特点是引入了多变量数据的四阶累积量矩阵,并作特征分解[9-10]。JADE算法可从混合信号中恢复各个未知源信号,有助于灰、黑色体系的数据分析。使用该算法需要满足以下前提:在忽略系统噪声情况下,各个未知源信号相互统计独立且服从非高斯分布;混合数据矩阵为可逆矩阵。鲜果样品可视为由多种化合物组成的混合体,样品的近红外光谱为化合物基本光谱的叠加组合,它们之间符合统计独立的条件,将未知近红外光谱体系表示成各化学成分的单组化学信号与其浓度的乘积,即:
=(1)
式中:表示实验中获取的近红外光谱矩阵;表示独立化合物的浓度矩阵;表示独立化合物基本光谱矩阵。因此选取适当的独立化合物个数,即JADE算法中的独立分量数,可以将光谱中统计独立的本征变量提取出来,从而摒弃光谱中冗余信息,达到降低建模难度,简化模型的效果。
当忽略系统噪声时,JADE算法的数学表达式为:
=(2)
将这个模型应用于近红外光谱提取时,式(2)中矩阵(n×k)为近红外光谱信号矩阵,包含个样品、个光谱点,矩阵(n×m)为混合矩阵,表示了独立光谱的叠加混合权重,矩阵(m×k)为潜在独立分量矩阵,包含个独立分量。的某一行等价某种符合统计独立的化合物基本光谱,的某一列等价矩阵中基本光谱在不同样品中的权重值。需要指出的是,JADE提取的独立分量是一种符合统计独立的分量,与实际的化学成分基本光谱未必吻合,需要选取独立分量数,提取反映完整光谱信息的混合矩阵,用于建立可靠的近红外校正模型。
1.2 ELM鉴别成熟度原理
超限学习机是由Huang等提出的一种针对单隐层前馈神经网络(SLFNs)的新算法[11],它突破传统人工学习方法的局限,更加向人脑学习方式靠拢。
一个具有个隐含层节点的单隐层前馈神经网络的输出可以用式(3)来表示:

式中:a和b表示隐含层节点的学习参数;=[1,2, …,]表示隐含层第个节点到输出层的连接权值;(a, b,)表示第个隐含层节点与输入的关系。若设激活函数为(),则有:
(a, b,)=(ax+b) (4)
任意选取个样本(x,t)∈R×R,这里x,∈R为输入,t∈R为目标输出。如果一个具有个隐含层节点SLFNs能以接近于0的误差来逼近这个样本,则存在,a和b有:
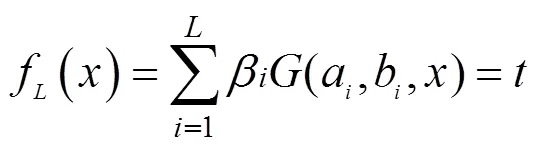
简化为:
=(6)
式中:被称作网络的隐含层输出矩阵,隐含层节点数通常比训练样本数小,因此训练误差虽不能精确到零,但可使训练误差逼近于零。输出权值可以由下式得到:
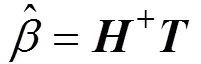
式中:+表示隐含层输出矩阵的Moore-Penrose广义逆。
ELM证明了神经元的生成可以独立于训练样本和其他节点,隐含层连接权值和隐含层神经元阈值根据激励函数随机设定,不需要调整。它具有学习速度快、泛化能力强等优点,适用于高维近红外光谱数据的分类。
2 实验步骤与数据
2.1 JADE结合ELM建模步骤
使用JADE结合ELM建模主要步骤如下:①对原始光谱使用传统方法预处理,去除光谱噪声;去除与样品性质缺乏相关关系的信息,压缩光谱并使光谱数据更加符合JADE算法的要求;②采用JADE算法对预处理后的光谱分解,选择适当独立分量数,得到混合矩阵和独立分量矩阵;③混合矩阵和样品特征矩阵作为模型输入,采用ELM算法建立分类模型,需改变隐层节点数,得到可靠的模型。采用JADE-ELM建立成熟度鉴别模型时,以模型的分类准确率和预测分类准确率为指标,分类准确率接近100%为宜。分类准确率定义如下:

2.2 数据获取
光谱采集使用德国蔡司公司的MCS600阵列式光纤光谱仪,扫描范围为450~1650nm。采谱后数据处理软件为MATLAB R2013a。
砂梨样本收集自某标准化商业果园。为保证果实成熟度准确性,选择果园内果树树势、管理水平相同的果实,于8月7号开始采样,采样间隔为7天,共进行4次,挑选大小一致,无病虫害和无机械损伤的果实,采后于实验室(避光,23℃)保存备用,分别得到七成熟、八成熟、九成熟和全熟样品共420个,分别记为成熟度类别Ⅰ、Ⅱ、Ⅲ、Ⅳ。
本文用Kennard-Stone算法划分420个样品,为使4种成熟度样品均匀分布在训练集、验证集和预测集中,以保证样品集的合理性和代表性。训练集用于建立模型,验证集用于模型参数优化,预测集用于模型可靠性检验。训练集有240个样品,验证集有120个样品,预测集有60个样品。4种成熟度样品的划分情况如表1所示。

表1 Kennard-Stone算法划分样本集结果
每次采收的果实放置24h后采集光谱,摄谱范围为果实赤道上均匀分布3点,取3次的光谱平均值作为样品原始光谱。图1为4种不同成熟度样品的漫反射光谱图。图1可见,不同成熟度样品的原始光谱存在差异,但光谱重叠严重,相似度很高,说明建立成熟度判别模型具有实际意义。
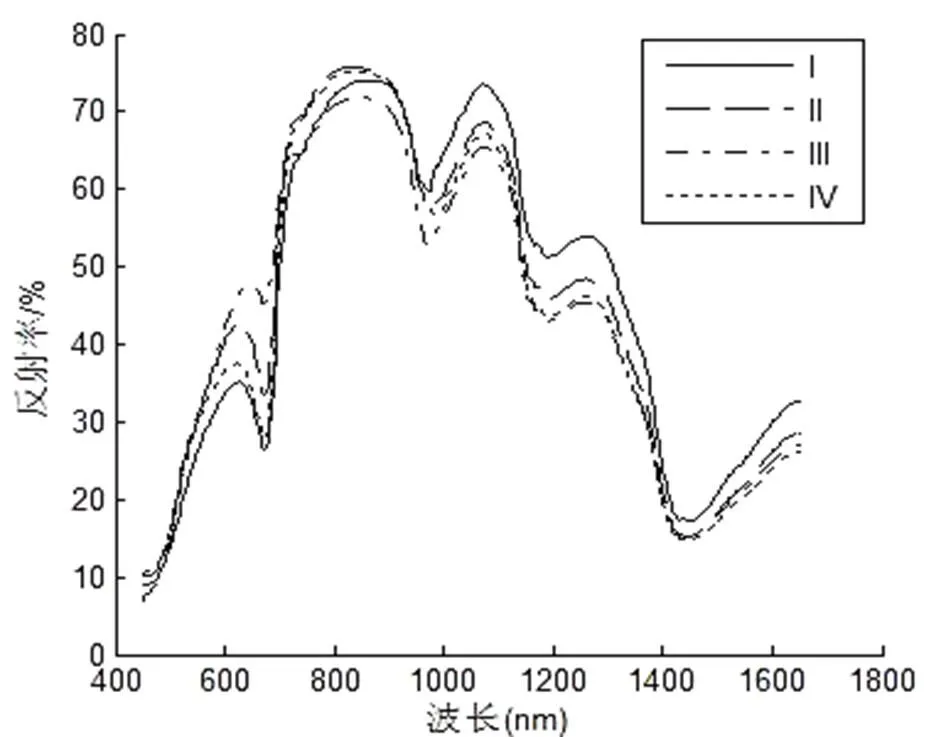
图1 不同成熟度砂梨的光谱图
3 实验结果与讨论
3.1 光谱预处理
原始光谱中包含电噪声、样品背景和杂散光等无关信息,同时,近红外光谱信息重叠严重,利用全波段进行建模分析时,光谱中的大量冗余信息会增加模型的复杂性,甚至影响预测精度,为减弱或消除各种干扰因素对校正模型性能的影响,需要对原始光谱预处理。经过多种预处理方法(平滑、一阶和二阶求导、多元散射校正、小波变换)的比较,首先使用多元散射校正消除原始光谱的基线漂移,然后使用离散小波变换压缩光谱数据,选取DB2小波基函数,进行5层小波分解。
3.2 JADE独立分量数选择
预处理后的光谱,已经基本去除噪声,使光谱数据更接近JADE算法的要求,有利于提取独立成分的准确性。使用JADE算法分解光谱,考察不同独立分量个数对模型的结果影响。本文将独立分量数初始值设为3,以1为步长增加至25,模型其他参数固定不变,比较分类准确率,独立分量数与分类准确率的关系如图2所示,可以看出,独立分量数增加过程中,分类准确率逐渐增大,在数值达到12以后准确率趋于平坦,独立分量增多模型计算量随之增大,因此选择最佳独立分量数为12。
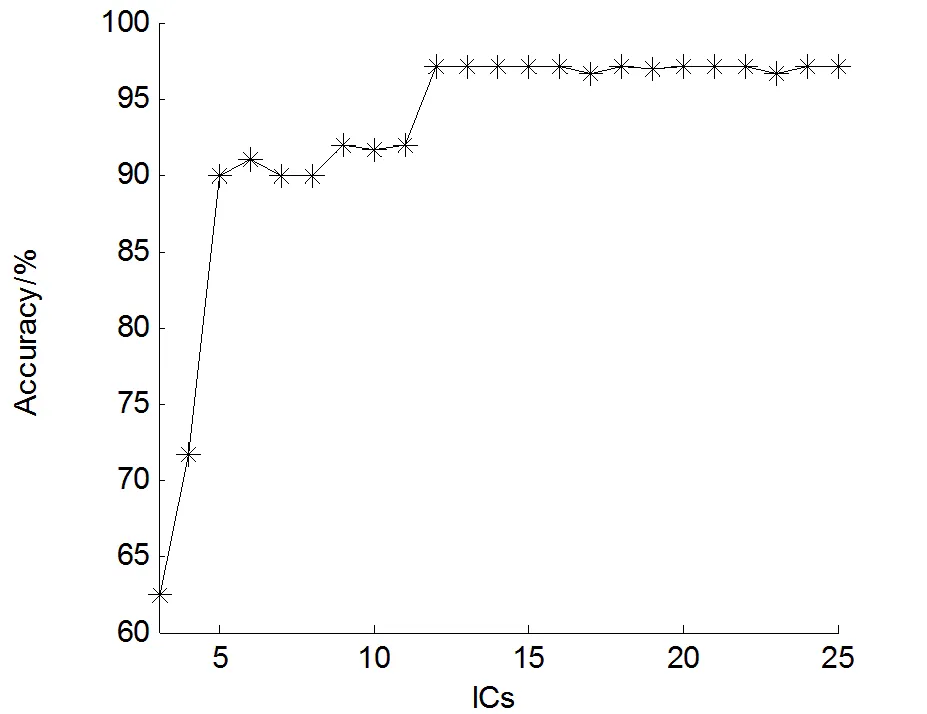
图2 独立分量个数(3~25)对训练集分类准确率的影响
3.3 ELM隐层节点数选择
以JADE分解后得到的混合矩阵和样品成熟度作为输入,使用超限学习机算法建立初始ELM分析模型。本文先分别选取“Sigmoidal”、“Sine”和“Hardlim”函数作为ELM模型隐含层激励函数。经过多次试验得到,“Sigmoidal”函数可获得较稳定的模型,具有较高判别精度。隐层节点数对模型的分类识别性能至关重要,本文将隐层节点数初始化设定为10,并以5为步长依次增加至50,在各隐层节点数取值下重复训练20次,得到最佳模型参数为25,此时训练集分类准确率为97.92%。
3.4 模型分类准确率分析
通过训练集建立JADE-ELM模型,使用验证集样品对模型参数优化,选择独立分量数为10,隐层节点数为25。将预测集样品原始光谱导入模型,对预测集60个样品分析,得到每种样品的分类判别情况如表2所示,表中可见,仅相邻成熟度(II、III成熟类别)样品出现2个误判,可能原因是果实样品在生长过程中营养缺乏或过剩,导致其有机物含量与同时期其他果实存在差异。分类模型分类最佳准确率达到96.67%,模型可靠,能够满足实际商业需求。
收集同批次未知样品,采集光谱并导入模型,模型输出即样品成熟度。需要注意的是,未知样品种类、培育状况要与建模集样品一致,否则该分析样品会被视为异物样品,无法准确判别。另外,可以将该样品补充到原校正集中,更新校正模型,使该模型适用性增强。
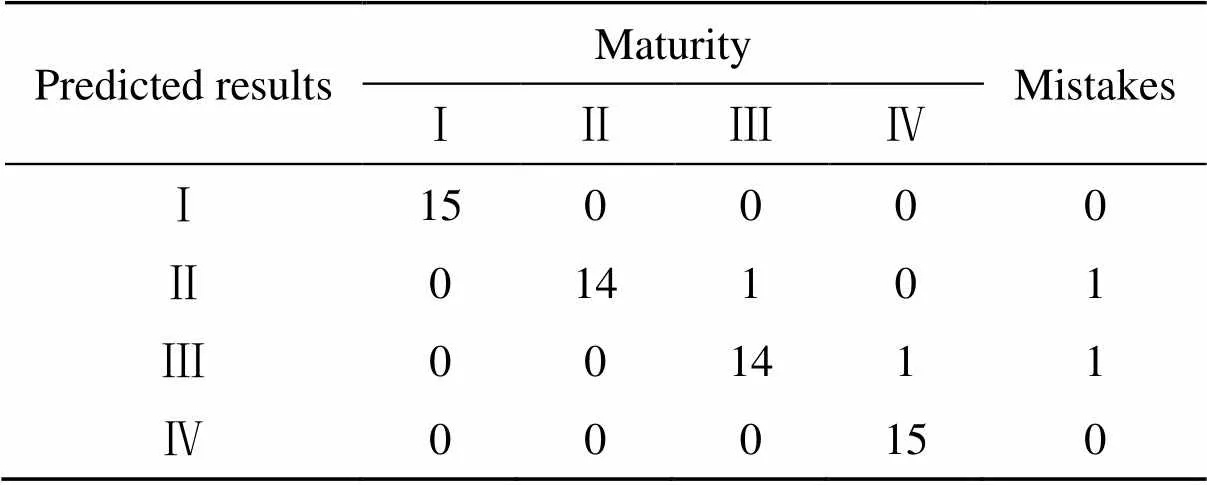
表2 样品预测集鉴别情况
4 结论
本文使用JADE结合ELM建立了鉴别鲜果成熟度模型,应用于砂梨的成熟度鉴别,选取独立分量数和隐层节点数分别为12和25,所建模型分类准确率为97.92%,将模型用于鉴别未知样品,预测集分类准确率为96.67%。JADE算法分解光谱,综合分析光谱数据幅值、相位等信息,得到包含独立化合物浓度信息的混合矩阵,有利于依据可溶性固形物、水分、酸度等信息鉴别鲜果成熟度;ELM算法建模,仅需调整隐层节点个数就可得到最优解,保证了在模型转移过程中模型的精度和稳定性。结果表明,该算法能够更好地改善鲜果成熟度鉴别模型的性能,所建模型稳定性好,精度高,丰富了近红外光技术建模算法,并为模型的传递与共享奠定基础。
[1] Marques E J, de Freitas S T, Pimentel M F, et al. Rapid and non-destructive determination of quality parameters in the ‘Tommy Atkins’ mango using a novel handheld near infrared spectrometer[J]., 2016, 197: 1207-1214.
[2] Olarewaju O O, Bertling I, Magwaza L S. Non-destructive evaluation of avocado fruit maturity using near infrared spectroscopy and PLS regression models[J]., 2016, 199: 229-236.
[3] Robert N Feudale, Nathaniel A Woody, TAN Huwei, et al. Transfer of multivariate calibration models: a review[J]., 2002, 64(2): 181-192.
[4] JIANG H, ZHU W. Determination of Pear Internal Quality Attributes by Fourier Transform Near Infrared (FT-NIR) Spectroscopy and Multivariate Analysis[J]., 2013, 6(6): 569-577.
[5] 贾春阳, 李卫华, 李小春, 等. 基于ICA的变化检测新方法[J]. 光电工程, 2013(12): 39-43.
JIA Chunyang, LI Weihua, LI Xiaochun, et al. A novel change detection method using independent component analysis[J]., 2013 (12): 39-43.
[6] 王功明, 刘志勇. 基于光谱表示和独立成分分析的混合颜料成分分析方法[J]. 光谱学与光谱分析, 2015, 35 (6): 1682-1689.
WANG G M, LIU Z Y. A composition analysis method of mixed pigments based on spectrum expression and independent component analysis[J]., 2015, 35(6): 1682-1689.
[7] Mishra P, Cordella C B Y, Rutledge D N, et al. Application of independent components analysis with the JADE algorithm and NIR hyperspectral imaging for revealing food adulteration[J]., 2016, 168: 7-15.
[8] HUANG G B, ZHU Q Y, Siew C K. Extreme learning machine: a new learning scheme of feed forward neural networks[C]//, 2004, 2: 985-990.
[9] Cardoso J F, Souloumica A. Blind beam forming for non-Gaussian signals[J]., 1993, 140(6): 362-370.
[10] HyvarinenA, Oja E. Independent component analysis: algorithms and applications[J]., 2003, 13: 411.
[11] HUANG G B, ZHU Q Y, Siew C K. Extreme learning machine: theory and applications[J]., 2006, 70(1-3): 489-501.
Sharing Model in Maturity Discrimination of Chinese Pears Based on JADE and ELM
JIAO Liang,LIN Min,LIU Huijun,HU Xiaofeng
(Measurement Test Engineering College, China JiLiang University, Hangzhou 310018, China)
The paper proposes an method of application of Joint Approximative Diagonalization of Eigenmatrix(JADE) algorithm and Extreme Learning Machine(ELM) for modeling steadily to discriminate maturity of different Chinese pears. The near infrared spectra of Chinese pears were linear combination of the different chemical components. To eliminate the noise, MSC and wavelet transform were used. Then the source signals were extracted from initial data set by JADE and a linear representation of non-Gaussian data was founded. By changing the number of neurons, ELM was used to build a discrimination maturity of different pears stability model. JADE was able to find more complete information of samples, and reduced the spectral interference. ELM has a high measurement precision and sets a few parameters. This method is the foundation of model transfer and sharing. Parameters of ELM algorithm were random, which made the model more stable. With Chinese pears as experimental samples, the model prediction accuracy was 96.67%.
JADE algorithm,extreme learning machine,near-infrared spectra,maturity discrimination of pears,modeling steadily
O657.33
A
1001-8891(2017)02-0194-05
2016-05-09;
2016-08-05.
焦亮(1993-),女,硕士,主要研究方向信号分析与处理,E-mail:931270678@qq.com。
国家重大科学仪器设备开发专项(2014YQ470377);浙江省公益技术应用研究项目(2015C37075)。
