利用文本挖掘进行药物重新定位的步骤与工具
2017-03-21,
,
药物重新定位(Drug Repositioning)指药物新适应症的开发,即利用相关技术方法对已有药物进行重新筛选、组合或改造从而发现其新用途的过程[1]。新药的开发需要经历多次研发试验以及临床试验,因此需要消耗大量人力、物力和财力。但是对已存在药物进行重新定位,发现其新用途可以大大减少资源消耗,避免新药可能带来的风险。因此对药物的重新定位研究已成为当今很多研究人员和开发商关注的热点[2]。
“文本挖掘”技术为药物重新定位提供了新思路。Marti A.Hearst 将文本挖掘定义为使用计算机从不同的文字资源中自动抽取信息,发现之前不存在的信息[3]。因此使用文本挖掘技术可以从大量文本集合中预测新的关系,发现新知识。
近年来越来越多的学者尝试用文本挖掘技术发掘不同药物作用机制,不同疾病病理机制甚至不同药物副作用之间的相似性,以预测药物新的适应症,进行药物重新定位。本文介绍了文本挖掘在药物重新定位研究中的基本步骤和近年来利用文本挖掘技术进行药物重新定位常用的工具及部分成功范例。
1 文本挖掘技术应用于药物重新定位的研究现状
伴随着文本挖掘技术的进步,研究人员使用文本挖掘进行药物重新定位的研究也越来越多。笔者以([“Drug Repositioning”Mesh]) OR“Drug Discovery”[Mesh]) AND “Data Mining”[Mesh]为检索策略,在PubMed数据库中检索到相关文献200篇。使用中国医科大学医学信息学院崔雷教授等人自主研发的书目共现分析系统(Bibliographic Item Co-Occurrence Matrix Builder, BICOMB)[4]提取出这些文献的发表年代,统计不同年代的论文数量;剔除2016年发表的文献后,剩余197篇。对2009年到2015年发表的文献量进行累计统计,发现该类文献累积量近年来呈直线型增长(图1),说明近年来该领域的发展越来越受到重视。
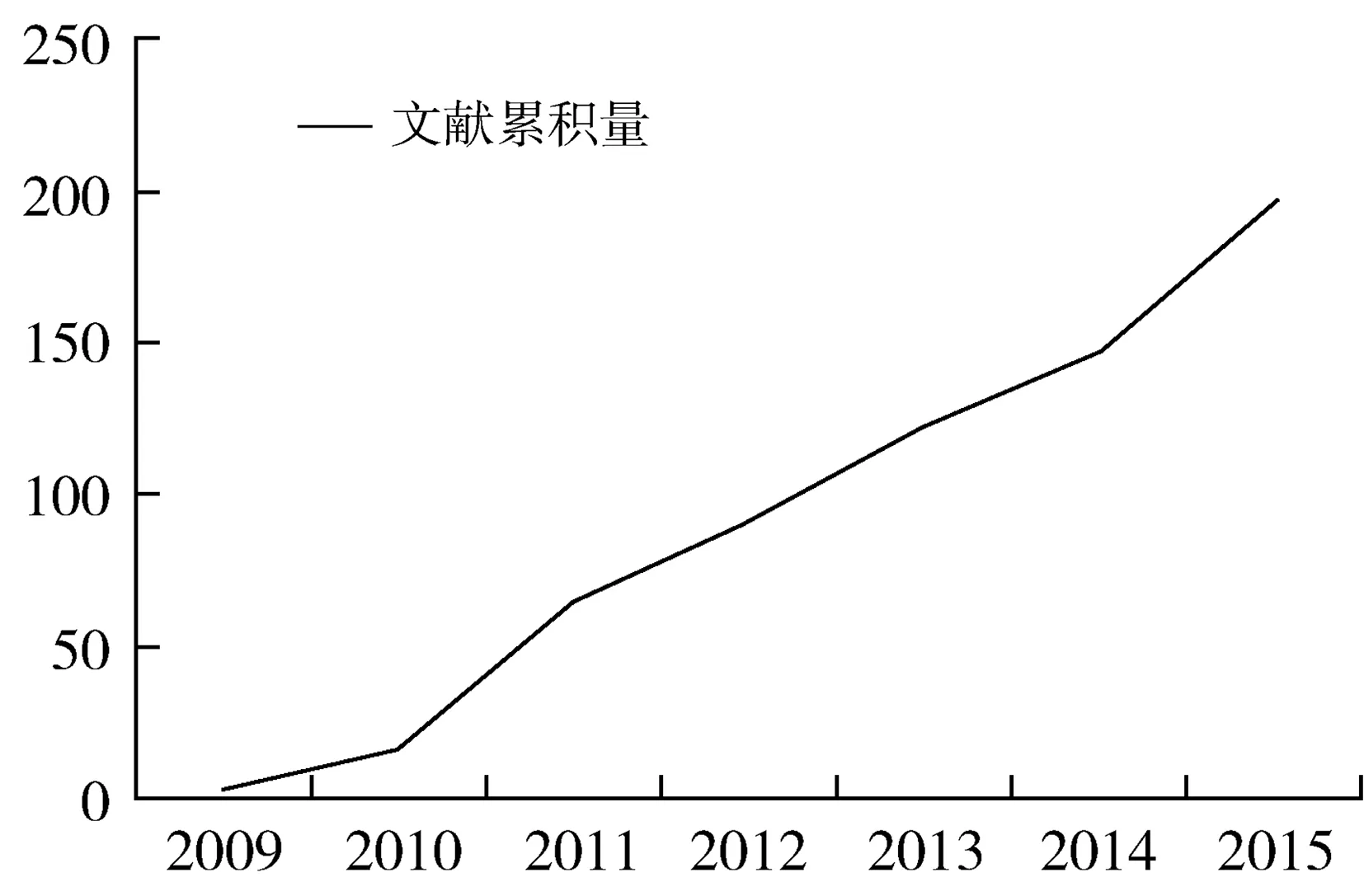
图1 2009-2015年利用文本挖掘进行药物重新定位相关文献累计增长
近年来,研究人员主要利用以下3种原理及方法发现药物新的适应症。一是通过发现某些生物大分子具有相似的结构预测它们可能与相同的药物结合,进而预测药物可以治疗一些其他病理机制相似的疾病[5-6];二是通过发现药物之间的相同副作用,假设这些药物可以用于相同的疾病,从而推测药物新的适应症[7-10];三是构建药物与药物、药物与靶点等物质之间的网络关系推测药物新的适应症,如不同药物作用之后基因表达谱具有相似性,从而预测药物对某些基因的作用,进而假设药物的新适应症[11]。
2 利用文本挖掘进行药物重新定位的步骤
对药物进行重新定位的文本挖掘包括信息检索、命名体识别、关系抽取、网络构建等基本步骤,但是对药物重新定位研究更加注重药物之间、药物与靶点之间的网络构建,并在发现药物新作用上更有其特殊的工具和算法。
使用文本挖掘技术进行药物重新定位的一般流程见图2。
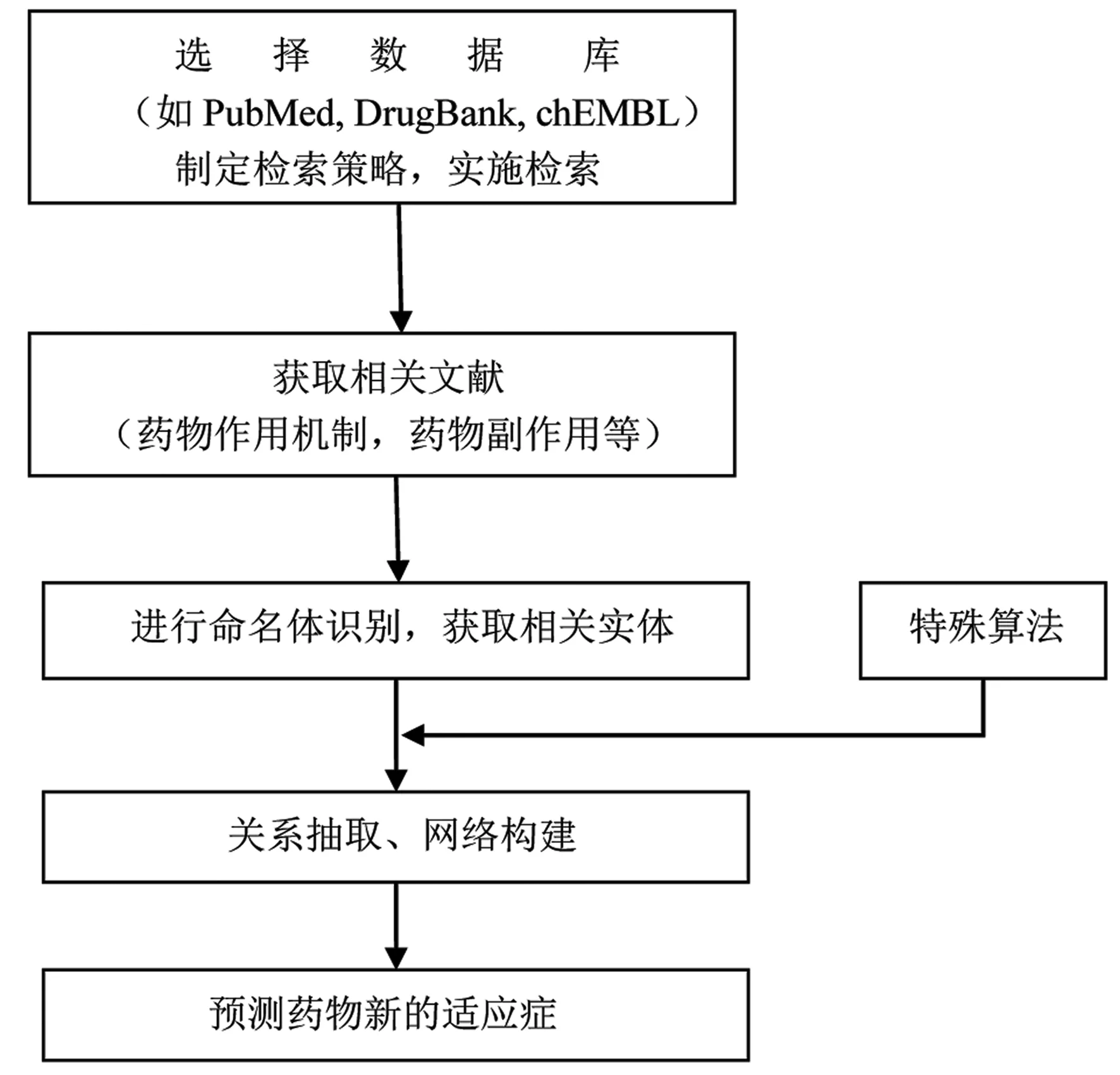
图2 使用文本挖掘进行药物重新定位研究的一般流程
3 利用文本挖掘进行药物重新定位的工具
3.1 信息检索数据库与工具
信息检索包括选择合适的数据库、制定正确的检索策略、实施检索3个步骤。研究者在该过程中得到关于该研究领域的相关信息,是文本挖掘的第一步,也是以后各步骤的重要基础。
生物医学最常使用的检索系统是PubMed,它包含MEDLINE数据库中全文和摘要等资源。如研究人员从MEDLINE数据库下载或收集某些期刊(如JournalofOncology)一段时间内发表的关于肿瘤的全部文献,并对它们进行分类、关系抽取、信号过滤,使用信号优先算法从文献中提取药物副作用的内容,挖掘出大量药物副作用;对得到的数据进行统计学分析,将通过统计学分析有意义的药物副作用与FDA中记录的药物副作用比较,发现大量的药物副作用在FDA中没有记录;再经过综合相关分析发现,具有相似或者相同副作用的抗癌药物之间可能在作用方式、毒性之间具有相似性,据此预测这些药物可用于相同的疾病,进而发现药物的新作用[7-10]。
除了科学文献外,其他文献资源,如专利、病例报告、FDA中的药物信息等也是生物医学领域信息的重要来源。如有研究人员从FDA药品说明书中抽取描述药物副作用部分,从中发现相关描述药物副作用的句子和语法树,并从这些语法树集合中提取与药物副作用相关的句法模式;然后他们又使用模式排序算法从中找到精确度和召回率较高的句法模式,并使用这些模式从MEDLINE数据库中抽取药物副作用,结果发现大部分药物副作用是FDA药品说明书上没有记载的[7]。
除了文献资源外,文本挖掘研究的一个新动态是与生物大分子数据库进行整合。如研究人员通过使用某些工具(TargetHunter等)在一些生物大分子数据库中(如ChEMBL[12]、Protein Data Bank)发现一些结构相似的蛋白或者其他有机分子,进而预测这些分子可与相同的药物或者配体结合,由此发现这些药物可用于其他一些病理机制相似的疾病,从而发现药物的新作用[5-6]。可以通过综述[13]了解更多此方面应用的例子。
3.2 命名体识别工具
命名体识别是将文献中表示某一特定概念的一个名词或者一个名词集标记并表示出来。由于一个生物实体可用多个不同关键词表示,因此不仅需要识别出基因、蛋白、药物等实体的名称,还要将概念与某一个特定的生物实体标识映射,即将文献集中所有表示某一特定概念的关键词都发掘出来[14]。
目前也出现了很多用于命名体识别的工具,如Whatizit (http://www.ebi.ac.uk/webservices/whatizit),可以识别出使用者输入的文本(MEDLINE摘要等模块)中的术语,并将其与生物医学数据库中相对应的实体名进行链接[15]。
Reflect (http://reflect.ws )主要用于标识基因、蛋白质以及一些小分子的名称,使用者输入名称后,系统可以列出该名称在网络中的各种表达方式,及其结构序列信息,供研究者使用[16]。
3.3 关系抽取及网络构建工具
关系抽取即利用特定工具或者方法将文献中有关系的命名体连接起来,如可以提取出药物与药物、药物与靶点等的关系,将多种实体根据相关关系进行连接便可构成网络。
Mantra(Mode of Action by Network Analysis,http://mantra.tigem.it)可用于构建药物网络(节点是药物,边的距离值代表药物之间的相似性)。用户可直接输入一种药物作为参考药物,提交之后系统会自动检索该药物在Mantra数据库中与该药物作用方式相似的药物构建药物网络,并提供可视化网络视图,用户可根据药物之间距离值大小及其是否属于同一团体发现与参考药物有相似作用的新药物[17]。如Francesco Iorio等人使用Mantra构建药物网络的原理是通过不同药物或者不同剂量的药物使用之后基因表达谱之间的相似性发现不同药物之间相似的作用方式及药物的新作用。他们发现PHA-690509,、PHA-793887和PHA-848125等可以抑制CDK,并预测法舒地尔可以促进细胞自噬[11]。
DTome (Drug-Target interactome tool)是一个基于Web的工具,它利用Web查询候选药物,然后提取整合包括药物不良反应之间、药物-靶点、药物-基因以及靶点/基因-蛋白质相互作用关系4种类型的相互作用关系构建网络[18]。Chu LH等人构建的外周动脉疾病(Peripheral Arterial Disease,PAD)的蛋白质相互作用网络,可将该网络与药物-靶点关系相连接识别PAD潜在的药物靶点。其中使用的药物-靶点关系就是从DTome从Drugbank[19]和PharmGKB[20]中提取到的。该研究发现了一些潜在的可以治疗PAD的促血管生成药(如尿激酶和卡维地洛)和抗炎药(如ACE抑制剂和maraviroc)及PAD的药物作用靶点[21]。目前也出现了一些整合了命名体识别、关系抽取和网络构建功能的工具。如HiPub可以自动识别和注释文本中的的基因、蛋白、药物等实体,并以文本中识别实体之间的关系构建网络。该工具的特点是允许用户手动添加相关文献的实体,允许用户自定义实体,并且提供其他资源的链接供用户了解新的实体及关系[22]。
4 应用实例
近年来已经出现了大量利用文本挖掘技术进行药物重新定位的研究。Zhang M从OMIM和PubMed数据库中获取阿尔兹海默症(AD)发病机制相关数据,从DrugBank和Therapeutic Target数据库中获取药物-靶点数据,再使用公用的“组学”数据(包括基因组学、表观基因组学、蛋白质组学、代谢组学数据)生成抗-AD蛋白列表。列表中包含524种AD相关蛋白质,其中18种可以作为75种现存药物新的候选靶点。他们开发了一个排序算法对抗-AD靶点进行排序,发现CD33和MIF可以作为现存的7种药物的最强的候选靶点,也发现了7种抑制抗-AD靶点的药物,即这些药物可被重新定位用于治疗AD的认知症状[23]。
Sun P等总结了近年利用计算机方法进行药物重新定位的研究,介绍了一些可使用的数据资源和一种基于n-聚类的新的数据融合模型,将模型与语义文本挖掘进行衔接。文章评价结果显示,利用药物-基因-疾病三角关系结合复杂的文献分析是一种为药物重新定位识别新的候选药物的好方法[24]。
5 结语
随着文献的迅速增长,越来越多的知识将被隐藏在海量信息中。信息复杂程度的不断增加也会使文本挖掘技术面临更多困难,同时越来越多的相关工具及加工过的数据库也不断出现,为人们提供更多解决问题的途径。现在利用文本挖掘进行药物重新定位可使用的大部分工具只能用于执行其中一到两个步骤。随着人们对应用文本挖掘进行药物重新定位研究的不断深入,将会出现越来越多的整合工具,更便于人们利用,以发现药物新的适应症。
文本挖掘为信息分析提供了利器,更有利于信息专业人员有针对性地为生物医学提供咨询服务、开展专题研究。药物重新定位只是其中的一个案例,医学信息专业人员应抓住机会,充分利用手中掌握的资源和工具,站到生物医学数据挖掘的前沿。
