基于Logistic回归模型的企业信用风险研究
2017-03-20张小花
张小花
(安徽大学 经济学院,安徽 合肥 230601)
基于Logistic回归模型的企业信用风险研究
张小花
(安徽大学 经济学院,安徽 合肥 230601)
随着上市公司的信用问题和频繁的信贷危机的出现,投资者是越来越多地关注上市公司的财务状况和信用风险分析。利用色诺芬经济金融数据库中我国一般上市公司的企业财务数据来设计有效的指标体系,采用将信用风险定义为“因财务状况异常而被特别处理(ST)”的方法,选择了代表企业财务状况的19个关键指标作为备选分析指标, 并运用Logistic 回归过程中向后逐步法从中选择了6个对因变量影响显著的财务指标,以此建立数学模型来分析研究上市公司的信用风险。最后通过在数据库中查找数据,验证了模型具有较高的准确性。
Logistic回归模型;信用风险;ST
0 引言
上市公司是资本市场的重要组成部分,其信用状况直接影响金融市场的稳定和投资者的利益。近年来,随着规模的证券市场的扩大以及欧美次贷危机的影响,我国上市公司也逐渐暴露出越来越多的问题。因此准确地分析企业信用危机和财务状况对投资者、债权人,以及经济发展决策部门都有重要的现实参考意义。
自上世纪80年代Logistic回归分析法逐渐取代传统的判别分析,国外学者Martin(1977)对1975~1976年期间23家破产银行建立Logistic回归模型,并比较了Z分数模型、ZETA模型和Logistic回归模型的预测能力,它证明了Logistic回归模型是优于其他的。南开大学李萌(2005)研究表明,Logistic模型具有高准确率的预测和泛化的能力,是一种有效的信贷风险评估的方法。
一、二元Logistic回归分析的理论概述
(一)Logistic回归模型原理
二元Logistic回归类问题建立回归模型时,先将目标概率做Logit变换,将因变量的值映射到0~1之间。设因变量为y,取值为0表示事件不会发生,为1会发生。记影响y的n个自变量为Xi(x1,x2,…,xn),事件发生的条件概率为p(y=1|xi)=pi,得到如下的Logistic回归模型:
(1)
其中pi代表在第i个观测中事件发生的概率,事件发生与不发生的概率之比被称为事件发生比,记为Odds。对Odds作对数变换,得到Logistic回归模型的线性模型如下:
(2)
(二)Logistic回归模型的参数估计和假设检验
本文采用极大似然法进行研究。基本思想是先建立似然函数:
对数似然函数为:
对求导并令其为0,求出函数达到最大时的参数估计值,再计算第i个公司存在信用风险的概率pi,若Pi≥0.5,判定为存在信用风险,反之判定为信用正常类型的公司。
本文采用的是Wald检验。Wald检验就是用u或者卡方c2检验推断各参数是否为0,其中μ=bj/Sbj,c2=bj/Sbj其中Sbj为回归系数的标准误。基本步骤如下:1、确定假设:
2、构造似然比:
3、确定临界值:根据给定的显著性水平α,确定λα,使得
4、确定拒绝域:
若原假设成立,似然比应接近1,反之似然比足够大时,拒绝原假设接受备择假设。
(三)逐步回归中的变量筛选
Logistic逐步回归的变量筛选的方法与线性回归逐步筛选方法相似,但所用的统计量不再是F统计量,而是似然比统计量和Wald统计量。Wald检验结果分析:在结果输出中,所有关于B的检验都是Wald检验,sig值证明了B是否具有统计学意义。sig<0.05证明B具有统计学意义。
(四)Logistic回归模型的拟合度检验
本文采用Hosmer-Lemeshow检验法,H-L拟合优度检验通常是将样本数据根据预测概率分为两组,依据观测频数和期望频数来构造卡方统计量,然后根据卡方分布计算P值并对Logistic模型进行检验。设检验水准为0.05。原假设为:因变量的观测值与模型预测值不存在显著差异,若P值小于0.05则拒绝原假设,表明模型对原始数据的拟合效果差,反之则接受。显然H-L拟合优度检验中P值是越大越好。
二、上市公司的企业信用风险实证研究
(一)研究样本选择
考虑到数据的真实性和权威性,本文所用的数据均来自CCER①(中国经济研究服务中心)中一般上市公司的2010年—2014年的财务数据。选入研究的有效样本企业185家,其中26家ST样本企业,占所有公司的14%,涉及各个行业,比例合适。在研究中我们将ST公司视为存在信用风险,非ST公司视为不存在信用风险。
数据来源:http://www.ccerdata.cn/(色诺芬经济金融数据库)
(二)影响因子选择
选择了主要能够反映一般上市公司的偿还能力、盈利能力、成长能力和营运能力4个方面的财务指标:股票代码、股票简称、总资产、所有者权益合计、净资产收益率、资产收益率、净利润率、总资产增长率、营业利润增长率、流动比率、存贷流动负债比率、现金流动负债比率、资本充足率、债务资本比率、债务资产比率、存贷周转率、应收账款周转率、流动资产周转率、资产周转率、固定资产周转率。
(三)变量标准化预处理和回归分析的参数设置
本文数据结果是基于IBM SPSS Statistics 22.0实验环境分析所得。由于总资产和所有者权益合计两指标不是比率变量,故对其标准化,用Zx3和Zx4存储变量x3和x4标准化后的数据。
由于目标变量只有2个,即存在和不存在信用风险,故采用二元Logistic回归分析,另外由于所选指标较多,为了在最后的回归方程中保留更多的自变量,故采用向后逐步法,并采用Hosmer-Lemeshow拟合度检验模型。
(四)结果分析
给定0.05的显著性水平,采用向后逐步选择变量方法,总共经过了14步迭代,最终保留6个指标,因子系数对应的显著性都小于0.05,说明6个系数都通过了显著性检验。
诗话是中国古代文学批评特有的形式之一,肇始于宋代欧阳修《六一诗话》。诗话的内容复杂,如同笔记般风格轻松随意,“以资闲谈”,“内容固然以诗为主,但又不限于诗,实可以‘驳杂’二字括之”[10]466-467。清诗话在《诗经》学方面,也有表现,出现一些以诗话形式专门讨论《诗》的专著,而在诗话中片段式论《诗》的情况,更是随处可见,汇聚起来洋洋大观,这里仅就论《诗》专著进行讨论。
1、数据摘要信息
原始数据中的185个案例都用来建模,没有缺失信息。
2、Hosme-Lemeshow检验
根据目标变量的预测概率把结果分为个数大致相等的10个组,由于预测值相等的观测被分在一起,所以各组的观测数不一定相同。结果表明观测值和预测值都大致相同,所以模型拟合的效果是很好的,具有一定的可信性。
原假设为模型能够很好地拟合原始数据。检验结果:Sig=0.857>0.05,表明不能否定原假设,即认为该模型能够很好地拟合实验数据。
3、模型
由表1倒数第二列可知,变量X6、X7、X12、X14、X16、X20的显著性都小于0.05,故选入模型,表明这些自变量对方程的贡献都是显著的。下表给出了最终模型的系数估计值,由“B”列的系数可以得出二元Logistic回归模型如下:
(3)
其中:X6资产收益率、X7净利润率、X12存货流动负债比率、X14资本充足率、X16债务资本比率、X20资产周转率。利用上面的模型作出预测,从而得到是否存在财务危机的概率函数如下:
(5)
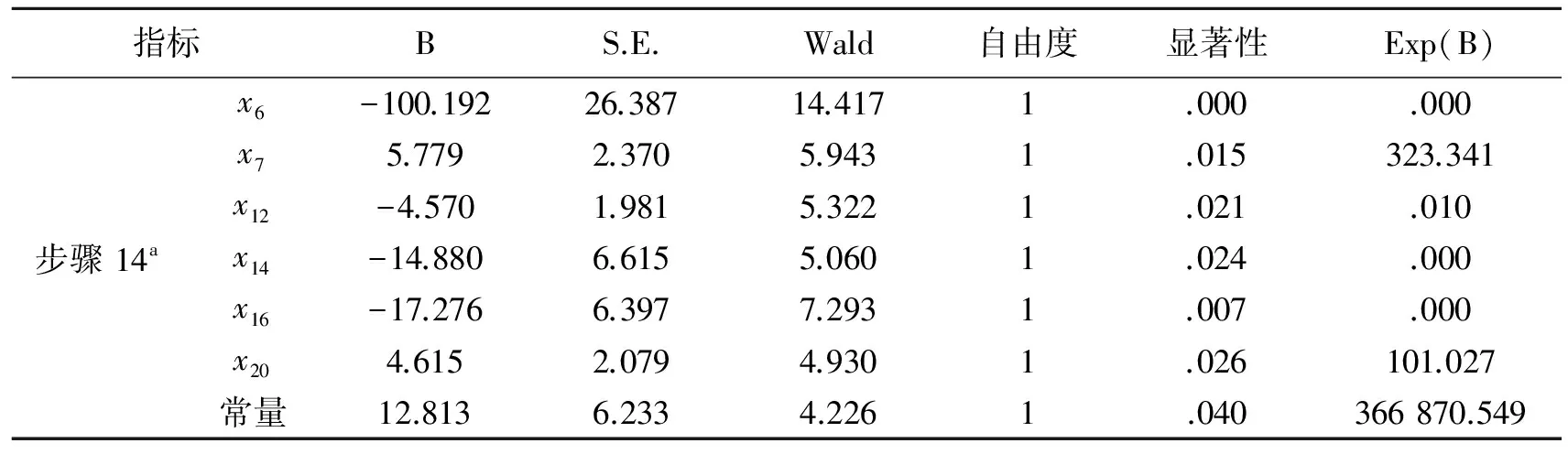
表1 模型回归结果
“Exp(B)”列的系数反映了影响因子变动1个单位而引起的发生比Odds的变化率,可见影响因子“净利润率(x7)”和“资产周转率(x20)”对Odds比的影响最大。
4、预测结果分析:
由结果可知在整体预测准确率达到了95.1%。原数据未被ST的公司有159家,经过模型判别有2家公司被判定为ST公司,有157家被判定为非ST公司,准确率为98.7%。在原始数据里有26家ST公司,经过模型判别后有19家仍然被判定为ST公司,7家被预测错误,判定为非ST公司,模型准确率为73.1%。
后期我们在数据库中查找模型预测为ST的21家公司,从后验的角度看有19家在2014年被沪深交易所列为ST公司,模型准确率为90.5%。
注释:
① CCER资本市场中财务数据分为金融企业财务数据、一般企业财务数据、首次公开发行前财务数据库。
[1]Pang, S. J. An Application of Logistic Regression Model in Credit Risk Analysis[J]. Mathematics in Practice & Theory, 2006,36(9):129-137.
[2]Doumpos, M, Zopounidis, C. Model Combination for Credit Risk Assessment: A Stacked Generalization Approach[J]. Annals of Operations Research, 2007,151(1):289-306.[3]Konglai, Z., Jingjing L, Konglai, Z, et al. Studies of Discriminate Analysis and Logistic Regression Model Application in Credit Risk for China’s Listed Companies[J]. Management Science & Engineering, 2010,112(4):178-184.
[4]张延波,彭淑雄.财务风险监测与危机预警[J].北京工商大学学报(社会科学版),2002(5):57-60.
[5]宋力,李晶.上市公司财务危机预警模型的实证研究[J].财经论丛,2004(1):84-90.
[6]胡小燕.企业财务风险管理中的危机预警系统研究[J].企业经济,2005(3):150-151.
[7]刘彦文.上市公司财务危机预警模型研究[D].大连:大连理工大学(硕士学位论文),2009.
[8]李建中,武铁梅.基于因子—logistic模型的房地产业上市公司财务预警分析[J].哈尔滨商业大学学报(社会科学版),2010(5):89-93.
[9]刘亚娜.我国小微企业信用评价体系研究[D].哈尔滨:哈尔滨理工大学(硕士学位论文),2014.
[10]赵荣花.基于财务和非财务因素的企业信用评价研究[D].南京:南京理工大学(硕士学位论文),2014.
Studies of Logistic Regression Model Application in Credit Risk for Companies
ZHANG Xiaohua
(SchoolofEconomics,AnhuiUniversity,Hefei230601,China)
With the appearance of listed companies’ credit issues and frequent credit crisis, investors are increasingly concerned about the financial status and credit risk analysis of listed companies. This paper uses the enterprise’s financial data of average listed companies in China, which are from Xenophon economic and financial data base, to design effective index system. This article uses the method which makes credit risk be defined as “for abnormal financial position and the special treatment (ST)”, chooses the 19 key indicators on behalf of the enterprise’s financial situation as alternative analysis indicators, and uses backward step by step in the process of Logistic method to choose the 6 indicators which have significant effects on the dependent variable,so as to establish the Logistic regression model to analyze the credit risk of listed companies. At last, the data from the database verifies that the model has high accuracy.
Logistic Regression model; credit risk; ST
2016-12-17
张小花(1993-),女,安徽芜湖人,硕士研究生,研究方向:经济统计。
F224.0
A
1009-9735(2017)01-0110-03
