统计机器翻译中短语切分的新方法
2017-03-16史红梅张艳君
刘 林,史红梅,张艳君
(山东农业工程学院,山东济南,250100)
统计机器翻译中短语切分的新方法
刘 林,史红梅,张艳君
(山东农业工程学院,山东济南,250100)
本文提出了一种新的短语切分方法,通过该方法可以将句子的短语切分进行概率化处理:首先把汉语语料库中次数>2次的词语串全部都识别出来,作为汉语短语,然后通过最短路径方式实现短语切分,同时应用Viterbi算法对短语出现频率进行迭代统计。
统计机器;机器翻译;短语切分;新方法
0 引言
二十世纪九十年代初期,国外科学家就根据信源信道思想提出了统计机器翻译模型,而自此之后,人们又很快在基于统计方法的机器翻译研究方面具有了巨大的进步。现如今,主流的统计机器翻译方法仍然是基于短语的统计机器翻译,因为该方法可以较好地处理短距离依赖和一些常用搭配问题。通常情况下,基于短语的方法的原理是将任意连续字符串均看作短语,自动在双语语料库中学习双语短语,然后进行以短语为单位的翻译。有科学家提出了对齐模板方法,即通过将单词映射到词类中对句子级和短语级进行两级对齐;另外还有学者提出了层次短语模型,即允许一个同步上下文无关文短语内均具备子短语。目前,众多科学家和学者仍旧在努力研究基于短语的新方法。
1 短语切分方法
基于短语的统计机器翻译系统的最小翻译单位就是短语,也即是说,将句子拆分成若干个短于,由每个短语的翻译而组成句子的翻译。汉语与英语的不同点在于其最小单位是字,词语是由字组成的,短语则是由词语组成的,而所谓的“短语切分”与汉语的切词类似,实际上就是在词语切分的基础上把句子切分成短语。故此,在短语切分之时可以借鉴汉语词语的切分研究方法进行研究。这里采用了N-最短路径法:根据短语库对已经分词的句子中全部可能的短语构造有向无环图,得出N条最优的路径。不过,其中需要解决两项问题:一者是如何得到短语库;二者是如何确定有向无环图的路径长度。
1.1短语查找
由于短语比之词语来说更加难以界定,不同人对短语的理解不同,因此很难像汉语切词一般通过人工来做短语库。对此,可以利用该方法中将任意连续的字符串看作短语的特点,自动于汉语单语语料库中抽取短语库。具体来说,这个短语查找的流程为:首先切分汉语语料库中的词语,详细记录每个词语出现的位置,并将其存储在WordMap中;然后找出表中每个词语所在文件中的对应位置,并据此向后搜索若干个词得到及保存词串,将相应计数加1;最后其中出现次数>2的重复词串即为短语库。在这过程中,若其中一个短语是另外一个短语的子串,且两者的出现次数相同,那么则保留长的那个。
1.2短语概率计算
短语概率指的就是有向无环图的路径长度,其可通过概率论的相关知识进行计算,具体的公式为:
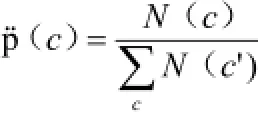
公式中,c指的是汉语短语,N(c)指的是汉语短语在语料库中出现的次数。
不过,仅通过这种概率估计方式所得到的结果是不够准确的,而本文所提出的这种新的短语切分方法应用了Viterbi算法对短语出现频率进行迭代统计,进而对短语的一元语言模型概率进行估计,所得到的结果更加准确。Viterbi算法的流程为:首先随机指定模型参数,然后计算出各训练样本的最大概率值,之后对概率进行重新统计、对模型参数进行更新,最后经多次迭代后得出逼近真实值的概率分布。
2 翻译模型与解码
统计机器翻译的核心就是翻译模型与解码,其中翻译模型的主要作用是反映对机器翻译过程的认识,解码的作用是搜索出最终译文。
2.1翻译模型
本文所提出的这种新的短语切分方法应用了Log-linear直接翻译模型,具体的公式为:
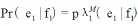
而在全部可能的翻译中,再选择概率最大的一个作为最终翻译:
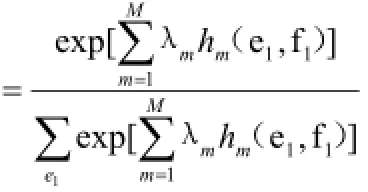
2.2解码
对于一个汉语句子来说,首先需要通过上述方法对其进行短语切分,取其中一个或以上最佳切分进行翻译。然后需要通过柱式搜索方法对每个切分结果进行单调解码,即按照从左至右的顺序对每个短语片段进行翻译,而不用调整顺序。为了加快搜索速度及节省内存,解码器可以只读进每个汉语短语中若干个最好的翻译,并限制搜索中每个栈的大小为m。Log-linear直接翻译模型采用的是最小错误率训练算法。
3 实验
笔者在相关测试集上对该方法进行了实验。本次实验所采用的是2005年863评测所提供的训练集,其中大约有英语词和汉语词各10M。通过SRI语言模型工具,利用该短语切分方法,对3-gram英语语言模型进行了训练。
3.1翻译模型训练
首先通过GIZA++[12],进行了汉语→英语和英语→汉语两个方向的训练,获得了词语对齐,然后通过grow-diag-final[2]进行了优化对齐,最后抽取短语,得到了翻译概率表。
3.2短语切分方法
作为基线系统,短语切分应用另一种方法:首先抽取语料库中的汉语短语作为短语库,以为短语切分的路径长度,然后通过最短路径方法进行短语切分。为了在搜索过程中取得翻译质量和翻译效率的平衡,每个句子宜取二十个最佳短语切分进行翻译。
3.3实验结果
本实验结果详见表1。

表1 实验结果
3.4问题分析
从结果中可以看出,相对于基线系统而言,该系统中通过使用短语切分模型能够提高其翻译质量,一般可提高0.5左右个百分点。不过,对于对话却会起到副作用,主要是由于:①该短语切分模型在训练中是单独使用的汉语语料,所以比较倾向于较短的短语,导致将本来就较短的句子切得更碎,降低了系统性能,而在双语短语库中长短语和短短语是俱存的;②疑问句在对话语料中所占的比重过大,而疑问句往往需要进行词序调整,但该系统是顺序解码,所以在这方面的表现较差;③对话语料在训练语料中约占了25%,这对于汉语的短语切分模型训练而言相对较少,所以影响了其作用;④篇章中的句子大多较长,并且新闻语料较多,其词序变化不是很强烈,所以通过短语切分模型能够有效切分出常见短语。
4 结语
本文提出了一种新的短语切分方法,并在相关测试集上得出了实验结果:对话0.2232、篇章0.1766。实验表明:对于篇章等长句子,通过使用短语切分模型能够提高其翻译质量,一般可提高0.5左右个百分点。
[1]何中军,刘群,林守勋. 统计机器翻译中短语切分的新方法[J].中文信息学报,2007,01:85-89.
[2]薛永增,李生,赵铁军,杨沐昀. 短语统计机器翻译的句法调序模型[J]. 通信学报,2008,01:7-14.
刘林, 1981年11月出生,性别男,民族汉,籍贯山东德州,学历大学本科,职称讲师,研究方向软件理论、机器学习。
A new method of phrase segmentation in statistical machine translation
Liu Lin,Shi Hongmei,Zhang Yanjun
(shandong agricultural engineering institute, jinan, shandong province, 250100)
this paper presents a new phrase segmentation method, the method can be sentence the phrase segmentation of randomization process: first of all, the number of Chinese corpora > two words list all identified, as Chinese phrases, then realize the shortest path phrase segmentation, at the same time using Viterbi algorithm to iterate phrases frequency statistics.
statistical machine; Machine translation; The phrase segmentation; The new method
项目:山东省高等学校科技计划项目--基于最大熵翻译模型的统计机器翻译系统的设计与实现(J13LN59)
