基于多模态神经网络的图像中文摘要生成方法
2017-03-12刘泽宇马龙龙
刘泽宇,马龙龙,吴 健,孙 乐
(1. 中国科学院 软件研究所 中文信息处理研究室,北京 100190;2. 中国科学院大学,北京 100190)
0 引言
自然语言处理(natural language processing,NLP)和计算机视觉(computer vision,CV)是当前的研究热点。NLP集中于理解自然语言,对文本产生过程建模,实现分词、词性标注、命名实体识别、句法分析和多语言机器翻译等。CV则集中于理解图像或视频,实现分类、目标检测、图像检索、语义分割和人体姿态估计等。最近融合文本和图像信息的多模态处理问题引起了研究者的极大兴趣。图像的自然语言描述(Image Captioning)是多模态处理的关键技术,它能够完成图像到文本的多模态转换,帮助视觉障碍者理解图像内容。该技术最早由Farhadi[1]等人提出,给定二元组(I,S),其中I表示图像,S表示摘要句子,模型完成从图像I到摘要句子S的多模态映射I→S。该任务对于人类来说非常容易,但给机器带来了巨大挑战,因为模型不仅要理解图像的内容,还要产生人类可读的摘要句子。
当前的研究主要针对图像生成英文摘要,对于中文摘要的生成方法研究较少。由于中文词语含义丰富,句子结构复杂,因此图像的中文描述问题更具有难度。本文在现有研究的基础上提出了基于多模态神经网络的中文摘要生成模型。编码过程中,使用单标签视觉特征提取网络和多标签关键词预测网络提取多模态特征。解码过程中,融合多个神经网络的输出生成摘要。本文的贡献在于构建了基于多模态神经网络的图像中文摘要生成模型,探索了序列模型中特征融合的方法,验证了本文方法在中文图像摘要任务上的良好性能。
1 相关工作
当前的图像摘要算法大致可以分为三类,分别是基于检索(retrieval-based)的方法、基于模板(template-based)的方法和基于神经网络(neural network-based)的方法。
1.1 基于检索的方法
基于检索的方法早期研究较多,该方法将图像摘要问题看作信息检索问题。算法在数据集C中寻找查询图像Iq的相似子集M=(Im,Sm),合理地组织摘要句子集Sm,输出Iq的摘要结果Sq。Ordonez[2]等人在规模为一百万的图像摘要数据库中检索,提出了首个模型IM2TEXT。Torralba[3]等人构建了Tiny Image数据库,该数据库使用WordNet中的单词为每张图像建立多个标签。Gupta[4]等人从图像Iq提取短语描述,并将短语描述作为关键词,在摘要数据集内检索输出Sq。Hodosh[5]等人提出KCCA方法学习多模态空间表示,该方法使用核函数提取高维特征,并使用最近邻方法进行检索。
1.2 基于模板的方法
基于模板的方法用计算机视觉技术检测出图像中的对象,预测对象的属性和相互关系,识别图像中可能发生的行为,最后用模板生成摘要句子。E-lliott[6]等人提出了首个基于模板的方法VDR,该方法用依存图表示对象之间的关系,同时使用句法依存树生成摘要。Desmond[7]等人改进了VDR方法,提出了从数据自动生成依存图的算法。Kulkarni[8]等人提出了Baby Talk模型,该模型使用检测器识别对象、属性和相互关系,采用CRF算法打标签,最后使用模板生成摘要。Mitchell[9]等人使用图像检测技术生成多个短语片段,然后使用句法树和替换规则生成图像摘要。
1.3 基于神经网络的方法
基于神经网络的方法来源于机器翻译,这些方法大都由编码器和解码器组成。编码器获取图像的特征表示,解码器产生句子。Mao[10]等人提出了基于神经网络的图像摘要生成模型m-RNN,该模型使用CNN对图像建模,使用RNN对句子建模,并使用多模态空间为图像和文本建立关联。Vinyals[11]等人提出了谷歌NIC模型,该模型将图像和单词投影到多模态空间,并使用长短时记忆网络生成摘要。Jia[12]等人提出模型gLSTM,该模型使用语义信息引导长短时记忆网络生成摘要。Xu[13]等人将注意力机制引入解码过程,使得摘要生成网络能够捕捉图像的局部信息。Li[14]等人构建了首个中文图像摘要数据集Flickr8k-CN,并提出中文摘要生成模型CS-NIC,该方法使用GoogleNet[15]对图像进行编码,并使用长短时记忆网络对摘要生成过程建模。
2 多模态神经网络图像摘要生成模型
现有的图像摘要生成模型大多基于编码器解码器架构,编码器对图像进行编码得到视觉特征,解码器对视觉特征进行解码生成句子,从而完成从图像到文本的多模态转换。本文充分利用多模态信息,编码过程同时提取图像特征和文本特征,解码过程融合多模态特征对摘要建模。
2.1 模型框架
图1所示是多模态神经网络摘要生成模型的框架。编码器由两个神经网络组成,一个是单标签视觉特征提取网络,另一个是多标签关键词特征预测网络。视觉特征V(I)∈n是单标签分类网络的隐藏层输出,刻画了图像的深层视觉特征,侧重于视觉信息,采用实数向量编码。关键词特征W(I)=[w1,w2,…,wm],0≤wi≤1是多标签分类网络的输出层结果,反映了关键词在摘要中出现的概率,侧重于文本信息,采用概率向量编码。解码器由多模态摘要生成网络构成,该网络融合单标签视觉特征和多标签关键词特征,输出是图像的中文句子摘要。编码器基于卷积神经网络对特征建模,解码器基于长短时记忆网络对序列建模。由于中文摘要数据集规模有限,使用协同训练的方法降低了神经网络的泛化性,因此三个神经网络在不同的数据集上单独训练。对于足够大的摘要数据集,协同训练是理想的选择。

图1 多模态神经网络摘要生成模型框架
2.2 单标签视觉特征提取网络
对于多模态数据集C中图像I,单标签视觉特征提取网络CNNV(I)完成了I→V(I)∈n的特征映射,其中网络输入为图像I,输出为视觉特征向量V(I)。视觉特征提取网络CNNV采用GoogleNet Inception V3[16]结构。单标签视觉特征提取网络使用了迁移学习的思想,该网络在大规模单标签分类数据集ImageNet[17]上进行训练,在图像中文摘要数据集Flickr8k-CN上测试。与训练过程不同,测试过程中提取的视觉特征向量V(I)是神经网络隐藏层特征,能够体现图像模态的整体信息。对于多模态数据集C中原始图像I,首先对图像进行缩放和裁剪,得到大小为299×299的三通道RGB彩色图像I′。然后使用表1描述的结构对图像I′进行处理,该结构使用不同的Inception模块组处理输入矩阵,将多个模块组的处理结果拼接起来得到高度结构化的特征表示。最后通过池化层对特征进行聚合得到图像的整体特征。考虑到单标签分类任务和视觉特征提取任务的差异性,我们使用Dropout正则化和归一化处理(batch normalization, BN)[18]来提高模型在摘要数据集上的泛化能力。表1给出了单标签视觉特征提取网络的设置。
2.3 多标签关键词特征预测网络

表1 单标签视觉特征提取网络的设置


down(·)用下采样函数对每组特征的平均值进行计算。线性层对xk进行投影,最后通过sigmoid函数输出关键词特征W(I):
如图2所示, 训练过程在多模态图像摘要数据
集上进行,多分类标签用摘要的分词结果构建,相应关键词出现记为1。对于T个关键词特征和N个训练数据(Ii,Li),其中i={1,…,N},Li=(li1,li2,…,liT),神经网络的损失函数可以表示为式(4)形式:

图2 多标签关键词预测网络
2.4 多模态摘要生成网络
对于视觉特征V(I)和关键词特征W(I),多模态摘要生成网络RNN(V(I),W(I))完成了V(I),W(I)→S(I)的映射,其中S(I)为图像I的中文摘要。本文使用长短时记忆网络对摘要生成过程建模,网络t时刻的计算过程为ht,ct=LSTM(xt-1,ht-1,ct-1),其中xt∈d为t时刻的输入,ct∈d为细胞单元状态,ht∈d为隐藏单元状态,LSTM(·)函数表示为下列形式:
(5)
其中,it∈d为输入门,ft∈d为遗忘门,ot∈d为输出门。根据长短时记忆网络的特点,本文提出四种基于多模态神经网络的摘要生成的方法CNIC-X、CNIC-C、CNIC-H和CNIC-HC。如图3所示,t>-1时,对摘要句子中词向量st∈z做投影,当作t时刻的输入,即xt>-1=WSst。t=-1时,多模态摘要生成网络对特征进行融合,计算t=0时刻的隐状态h0和c0,四种多模态摘要生成方法如下。
(1) CNIC-X将视觉信息和关键词信息相加作为t=-1时刻的输入x-1。其中WV和WW为投影矩阵。
(2) CNIC-H将视觉信息作为t=-1时刻的输入x-1,并使用关键词信息W(I)对t=-1时刻的隐藏单元状态h-1初始化:
(3) CNIC-C与CNIC-H类似,使用关键词信息W(I)对t=-1时刻的细胞单元状态c-1初始化:

图3 多模态摘要生成网络
(4) CNIC-HC使用关键词信息W(I)对t=-1 时刻的隐状态h-1和c-1同时进行初始化:
多模态摘要生成网络将t时刻的输出ot作为p(st|s0,…,st-1,W(I),V(I))的概率估计,训练的目标是使似然函数J(θ)最大化,从而估计模型参数θ:
3 实验与结果
本节在图像中文摘要数据集上进行实验,对多个模型的摘要生成质量进行评测。实验中比较的模型包括谷歌NIC[11]、人民大学CS-NIC[14]以及本文提出的CNIC、CNIC-X、CNIC-H、CNIC-C、CNIC-HC和CNIC-Ensemble。
3.1 数据集
本文使用的数据集为Flickr8k-CN*http://lixirong.net/datasets/flickr8kcn,该数据集是雅虎英文数据集Flickr8k的中文扩展,图像数据来源于雅虎的相册网站Flickr,数据集包含8 000张图像,每张图像都有五个人工标注的中文摘要,从不同的角度描 述图 像的内容(见表2)。本文遵循文献[14]中的方法来构造训练集、验证集和测试集。其中训练集6 000张图片,共3万个句子描述,验证集和测试集各1 000张图片,共1万个句子描述。此外,测试集包含了人工标注的结果以及对英文数据集人工翻译的结果,与文献[14]一致,本文同时针对上述两种测试集进行评测。

表2 Flickr8kCN数据集中图像与摘要示例
3.2 实验设置
(1) 单标签视觉特征提取网络设置
该网络在大规模单标签分类任务ImageNet[17]上进行训练,使用衰减率为0.9的RMSProp优化算法进行学习,初始学习率为0.045。测试过程中,该网络在图像摘要数据集上提取特征,特征向量为网络隐藏层输出。
(2) 多标签关键词预测网络设置
训练集6 000张图像3万条摘要共包含 270 463个单词,词典大小为4 473。考虑到低频词训练数据较少,本文仅保留词频大于40的高频词作为多分类标签。如表3所示,最终过滤后的类标签共四类319个。本文使用带有动量的随机梯度下降算法学习模型参数, 其中批处理个数为10,动量值为0.9,初始学习率为0.01,同时实验使用了权值衰减算法改进训练过程,衰减比例为0.000 5。各参数的初值从高斯分布N(0,0.01)中抽样得到,在训练过程中不断更新,直至收敛。

表3 高频词特征
(3) 多模态摘要生成网络设置
本文将词频数大于4的1 559个单词作为集内词构建词向量字典,同时将其他低频词当作集外词。词向量字典使用矩阵表示,本文对1 559个单词进行编号,序列开始符“
(4) 评测指标
本文使用BLEU-1,2,3,4[21]、METEOR[22]、Rouge[23]和CIDEr[24]六种指标衡量摘要生成结果的质量。其中BLEU指数同时采用了长度惩罚和非长度惩罚的计算结果,它反映了生成结果与参考答案之间的N元文法准确率。METEOR测度基于单精度加权调和平均数和单字召回率。Rouge与BLEU类似,它是基于召回率的相似度衡量方法。CIDEr是基于共识的评价方法,优于上述其他指标。
3.3 实验结果与分析
本节分别评估了基于单标签视觉特征编码的谷歌NIC、人民大学CS-NIC,基于多标签关键词特征编码的CNIC,以及基于多模态神经网络的CNIC-X、CNIC-H、CNIC-C、CNIC-HC模型。其中CNIC仅考虑关键词信息编码,在解码过程中,将W(I)作为序列t=-1时刻的输入对摘要生成过程建模。本节进行了三方面比较分析,主要包括:
(1) 基于视觉特征编码的NIC、CS-NIC与基于关键词特征编码的CNIC性能比较,主要分析使用图像的不同信息编码对于摘要生成结果的影响;
(2) 基于多模态融合的摘要生成模型与基于单一特征编码的NIC、CNIC和CS-NIC的性能比较,主要验证多模态融合方法的有效性;
(3) 基于多模态融合的不同方法CNIC-X、CNIC-H、CNIC-C、CNIC-HC之间的性能比较,主要分析几种多模态融合方法的优劣。

图4 各模型在验证集上的困惑度随迭代次数变化的曲线
本文遵循文献[11]的方法,使用模型在验证集上的困惑度选取最优模型。如图4所示,NIC在10万次迭代达到最优,CNIC-H、CNIC-C和CNIC-HC在13万次迭代达到最优,CNIC、CNIC-X在17万次迭代达到最优。由于文献[14]没有提供验证集上的相关信息,本文无法绘制CS-NIC的困惑度曲线。
如图5所示,本文使用文献[25]中的类别激活映射方法(class activation map, CAM),对概率最大的七个关键词特征可视化。关键词特征的可视化结果能够反映特征在图像中的位置信息, 例如特征“人”的可视化结果中激活程度较高的区域描绘了“人”所在的位置;特征“草地”的可视化结果中,激活程度较高的区域勾勒出了“草地”的轮廓。
图6给出了CNIC-HC模型的中文摘要生成结果,我们用柱状图表示了概率最大的八个关键词特征。图(a)和(b)是成功的摘要生成结果;图(c)和(d)是失败的摘要生成结果,图(c)的结果中没有体现“人”站在“河马”身上的信息,而图(d)的结果中没有出现“驴”这一实体。经过统计,“河马”和“驴”在训练语料中的词频为0和4,由于词频小于5为集外词,所以生成结果中不包含“河马”或“驴”这两个单词。
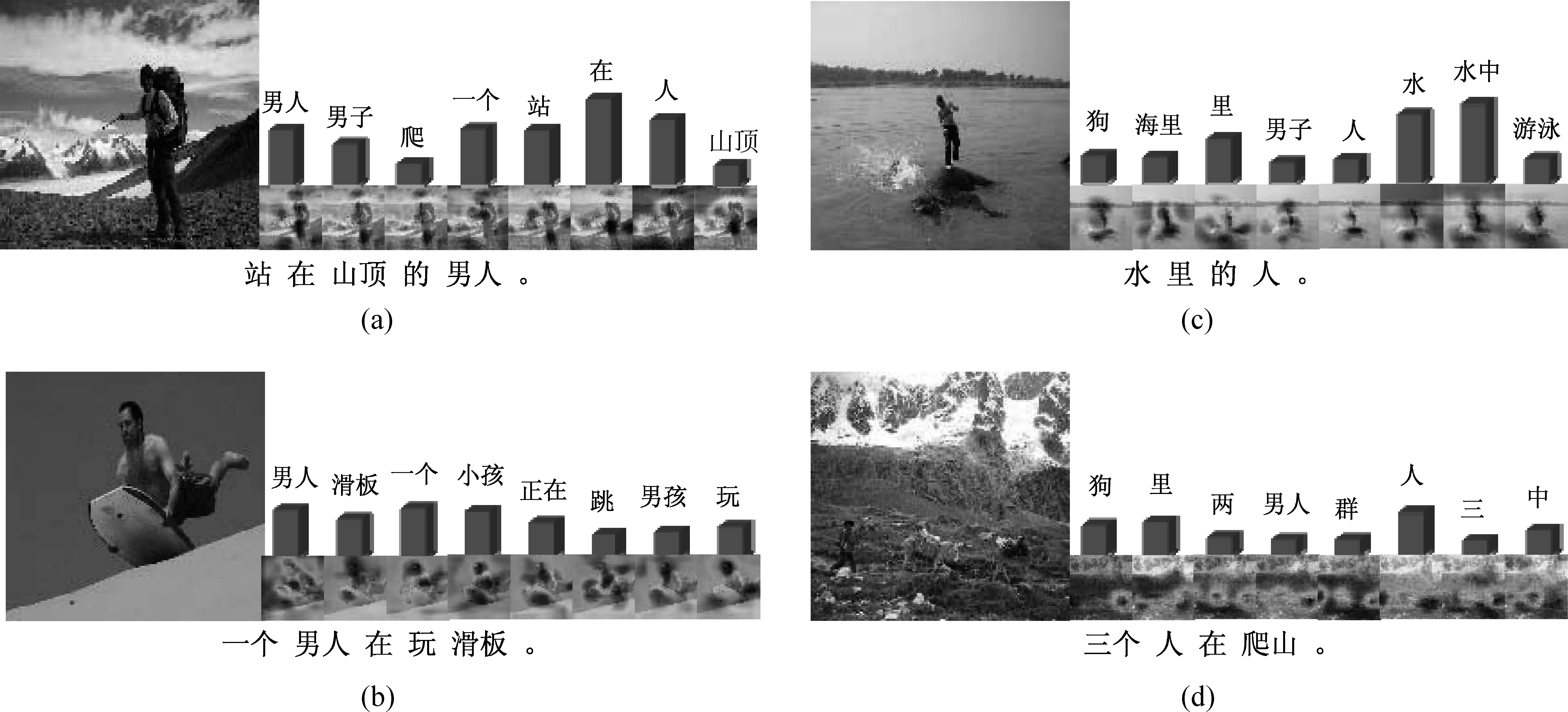
图6 CNIC-HC模型生成的中文摘要结果示例
表4给出了各模型在人工标注的测试集上的实验结果,可以看到使用单标签视觉特征编码的NIC优于使用多标签关键词特征编码的CNIC,而采用多模态融合的方法性能优于使用单个模态编码的模型,CNIC-HC优于其他融合方法。CNIC-Ensemble代表模型CNIC-X、CNIC-H、CNIC-C、CNIC-HC集成的结果,对于各模型生成的摘要,本文选取最大概率的结果输出。表中括号内的BLEU值是使用长度惩罚因子(Brevity Penalty, BP)的结果,括号外的BLEU值没有使用长度惩罚因子。文献[14]中没有对BLEU-4、METEOR、Rouge和CIDEr进行测评,因此本文无法列出CS-NIC的这些指标。

表4 各模型在人工标注的测试集上的性能比较
表5给出了各模型在人工翻译的测试集上的性能比较,实验结果与表4基本一致,使用单标签视觉特征编码优于使用多标签关键词特征编码,使用关键词特征能够显著提高模型性能,CNIC-HC优于其他多模态融合方法。本文提出的多模态融合方法优于现有的中文摘要生成模型,在该数据集上集成模型取得了最好结果。由于翻译结果与标注结果存在差异,各模型均在人工标注的数据集上进行训练,所以表5的各项参数低于表4。通过观察可以发现翻译的句子长度大于标注的句子长度,因此可能包含更多的摘要信息。

表5 各模型在人工翻译的测试集上的性能比较
4 结束语
本文提出了基于多模态神经网络的图像中文摘要生成方法,我们使用单标签视觉特征提取网络和多标签关键词预测网络改进编码过程,使用长短时记忆网络融合多模态信息。本文提出四种多模态融合模型CNIC-X、CNIC-H、CNIC-C和CNIC-HC,在8 000张图像4万条摘要信息的Flickr8k-CN数据集上实验。结果表明本文提出的模型产生了更好的中文摘要结果。
目前,我们提出的模型在视觉特征提取中仅考虑图像的全局特征,没有利用局部特征。在未来的工作中,我们将引入注意力机制,综合考虑图像的全局特征和局部特征生成目标摘要。
[1] Ali Farhadi, Seyyed Mohammad, Mohsen Hejrati, et al. Every picture tells a story: Generating sentences from images[C]//Proceedings Part IV of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece: Springer, 2010:15-29.
[2] Vicente Ordonez, Girish Kulkarni, Tamara L B. Im2Text: Describing images using 1 million captioned photographs[C]//Proceedings of the Advances in Neural Information Processing Systems: 25th Annual Conference on Neural Information Processing Systems Granada, Spain: NIPS,2011: 1143-1151.
[3] Torralba A, Fergus R, Freeman W T. 80 million tiny images: A large data set for nonparametric object and scene recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(11):1958-1970.
[4] Gupta A, Mannem P. From image annotation to image description[C]//Proceedings of Neural Information Processing- 19th International Conference, ICONIP 2012. Doha,Qatar:Springer, 2012, 7667:196-204.
[5] Micah Hodosh, Julia Hockenmaier. Sentence-based image description with scalable, explicit models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2013. Portland, OR, USA:IEEE,2013: 294-300.
[6] Elliott D, Keller F. Image description using visual dependency representations[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013. Seattle, Washington, USA:ACL,2013: 1292-1302.
[7] Desmond Elliott, Arjen P. de Vries. Describing images using inferred visual dependency representations[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing. Beijing, China: The Association for Computer Linguistics, 2015: 42-52.
[8] Girish Kulkarni, Visruth Premraj, Vicente Ordonez, et al. BabyTalk: Understanding and generating simple image descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,35(12): 2891-2903.
[9] Margaret Mitchell, Jesse Dodge, Amit Goyal, et al. Midge: Generating image descriptions from computer vision detections[C]//Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics. Avignon, France: ACL, 2012: 747-756.
[10] Mao J, Xu W, Yang Y, et al. Deep captioning with multimodal recurrent neural networks (m-rnn)[J]. arXiv preprint arXiv:1412.6632, 2014.
[11] Oriol Vinyals, Alexander Toshev, Samy Bengio, et al. Show and tell: A neural image caption generator [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015: 3156-3164.
[12] Jia X, Gavves E, Fernando B, et al. Guiding the long-short term memory for image caption generation[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015: 2407-2415.
[13] Kelvin Xu, Jimmy Ba, Ryan Kiros, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//Proceedings of the 32nd International Conference on Machine Learning. Lille, France:JMLR.org,2015:2048-2057.
[14] Li Xirong, Lan Weiyu, Dong Jianfeng, et al. Adding Chinese captions to images[C]//Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval. New York, USA:ACM,2016: 271-275.
[15] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the 32nd International Conference on Machine Learning. Lille, France:JMLR.org,2015: 1-9.
[16] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA:IEEE, 2016:2818-2826.
[17] Olga Russakovsky, Jia Deng, Hao Su, et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision, 115(3): 211-252.
[18] Sergey Ioffe, Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on Machine Learning. Lille, France:JMLR.org,2015: 448-456.
[19] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXivpreprint arXiv:1409.1556, 2014.
[20] Bisiani R. Search, beam. Encyclopedia of Artificial Intelligence. 2nd edt. 1992: 1467-1468.
[21] Kishore Papineni, Salim Roukos, Todd Ward, et al. Bleu: A method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia, PA, USA:ACL,2002: 311-318.
[22] Michael Denkowski Alon Lavie. Meteor universal: Language specific translation evaluation for any target language. Michael J. Denkowski, Alon Lavie. Meteor Universal: Language Specific Translation Evaluation for Any Target Language [C]//Proceedings of the 9th Workshop on Statistical Machine Translation, Baltimore, Maryland, USA: A C,2014: 376-380.
[23] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries [C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics. Barcelona, Spain: ACL, 2004:10-18.
[24] Ramakrishna V C. Lawrence Zitnick, Devi Parikh. CIDEr: Consensus-based image description evaluation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015: 4566-4575.
[25] Zhou Bolei, Aditya Khosla,gata Lapedriza, et al. Learning deep features for discriminative localization[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA:IEEE Computer Society, 2016: 2921-2929.
