面向高考阅读理解鉴赏题语言风格判别方法
2017-03-12王素格李德玉谭红叶王元龙
陈 鑫,王素格,2,李德玉,2,谭红叶,2,陈 千,2,王元龙,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
在信息革命的浪潮中,人工智能应运而生并蓬勃发展,极大推动计算机语音识别、图像分析及文本语义理解能力。为了检验计算机对文本语义深层理解效力,国家863“超脑计划”牵头研制“高考机器人”,即利用人工智能程序模拟高考生,参与高考。高考语文考卷,不仅考察考生对文本理解的能力,还检验其对文本的鉴赏能力,其中语言风格是比较重要的考察内容。由于语言风格是说话者个人语言情感的流露,其情感色彩相比任何其他语言现象更为丰富[1]。例如,语言风格中“明朗”一般较多使用在情感色彩比较鲜明的词语情感表达中,而“含蓄”语言风格则用于描绘性辞格进行情感表达[2]。因此,语言风格类别的判别既能为鉴赏题解答技术提供支撑,也能为分析阅读材料作者的情感奠定基础。
由于语言风格体系复杂,类别标签繁多,传统的二元分类器(如SVM)对多分类问题解决效果都不尽人意。利用语言风格的层级化系统[3],研究基于层次结构的语言风格判别,既能缓解多分类对二元分类器带来的挑战,也可以灵活选择分类的层次,以满足高考对语言风格不同考察方式。例如:
题目1: 以③④段为例,简要分析本文语言的两个主要特点。
题目2: 本文的细节描写细腻而生动,从多个角度抒发着作者的生命感悟。请选择一个最打动你的细节进行语言特色分析。
题目1未提及特定的语言风格,为提高判别准确率,可进行粗粒度分类。而题目2针对语言风格“细腻”考察,则需进行细粒度分类。
通常,层次分类依赖的类别层次结构可由专家编制,也可通过聚类生成[4]。为了克服专家编制的类别层次结构主观性,Tang等[5]提出一种动态结构调整方法,该方法具有较高的时间复杂度,随后,Nitta[6]对其时间开销进行改进,但调整结构受限于最初层次结构。为了减小结构生成过程对专家知识的依赖性,Phongwattana等[7]基于欧氏距离,利用层次聚类获取类别层次结构,但欧氏距离仅能刻画簇间空间距离,并未对其语义距离进行度量。另外,Karypis等[8]提出一种动态的层次聚类算法,首先利用K近邻算法构建图,然后基于快速图分割算法METIS[9]将数据图划分为多个子簇,最后基于簇间相对互连性与相对相似性,对簇进行迭代合并,得到最终层次聚类结果。此层次聚类方法可对形状各异、大小不一的子簇进行动态聚合,被应用到文本、图像及高铁故障检测任务中[10],并取得理想的效果。
本文综合多名学者对语言风格的类别划分结果[1-3,11-16],结合高考对考生的考察要求,研究语言风格类别标签的判别问题。为了实现高效的语言风格的类别判断,将语言风格鉴赏转化为分类任务,并利用识别结果辅助语言风格鉴赏题解答。
本文第1节将确定语言风格层次结构;第2节展现基于层次聚类的类别层次结构获取算法、基于层次分类的语言风格识别及面向高考语言风格鉴赏题解答流程;实验数据和评价指标在第3节呈现;第4节对实验结果进行详细的分析;最后一节给出一个全文的结论与下一步的工作展望。
1 语言风格类别的层次划分
由于语言风格体系复杂,语言学家研究粒度存在差异。宗世海[11]从多个角度划分粒度,从篇幅划分,可为单篇文档、多篇文档;从作品集角度划分,可分为单个作者作品、某类作者作品、一个语体。丁金国[12]认为语言风格粒度具有层级化,可分为语体-文体-语篇三个层次,其中最小粒度的语篇可为一个句群、一个段落、一篇文章等。而高考对语言风格鉴赏是面向单篇文档或单个段落,因此本文的研究粒度设定为单个段落。
由于同一时期的不同学者对语言风格定义迥异,而同一学者在不同时期的语义风格定义也不完全相同[13],因此,语言学家对语言风格的类别划分差异较大。依据文献 [1-3]和文献[11-16],我们将语言风格的表达方式分为平面划分、对立划分、层次划分,其具体划分结果见表1。
根据表1,综合多名学者对语言风格的类别划分结果[1-3,11-16],结合高考对考生考察要求,本文将语言风格划分为12个类别,分别为幽默诙谐、细腻隽永、朴素自然、华丽典雅、含蓄深沉、简洁明快、雄浑豪放、清新婉约、率性旷达、严谨工整、舒缓和平、急骤猛烈。

表1 语言风格划分结果

续表
由于语言风格中存在对立类别,为了防止层次聚类中对立类别簇聚合,本文参考语言学家的对立划分结果[3,11,13,15-16],建立对立集R,即: {雄浑豪放—清新婉约,雄浑豪放—细腻隽永,急骤猛烈—舒缓和平,华丽典雅—朴素自然,含蓄深沉—简洁明快,率性旷达—含蓄深沉,率性旷达—严谨工整}。另外,依据丁金国[12]定义的类别层次结构(见图1),结合本文确定的类别标签,修改后的类别层次结构MH见图2。
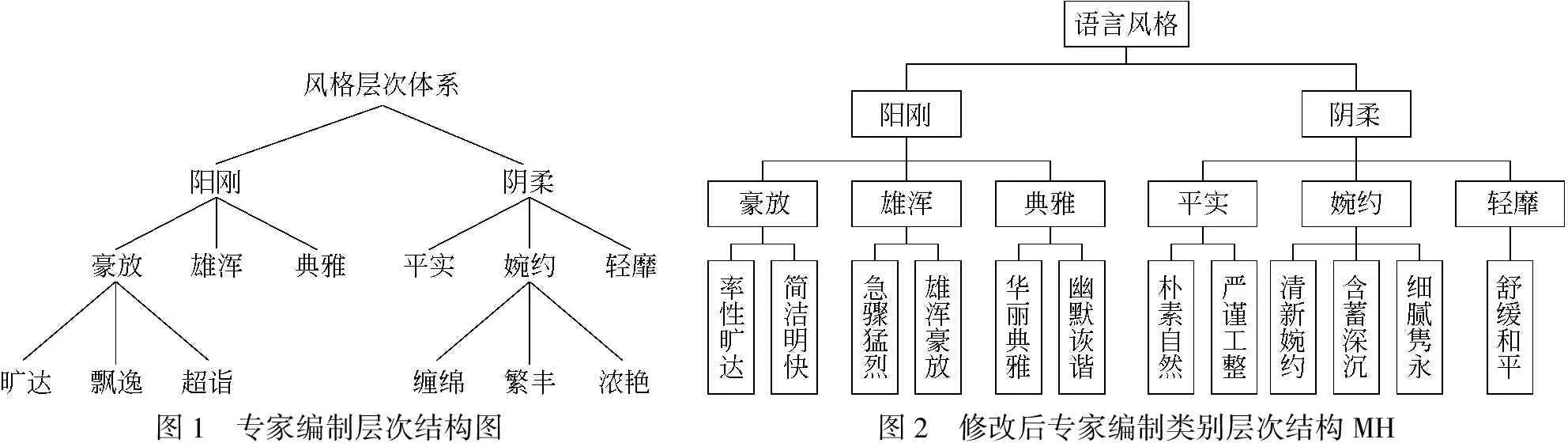
图1 专家编制层次结构图图2 修改后专家编制类别层次结构MH
2 基于层次结构的语言风格判别方法
为了适应高考不同考察要求,本文利用层次分类法判别语言风格,其分类策略可划分为全局处理策略、化繁为简策略、分而治之策略[4]。全局处理策略基于整个层次结构优化分类器,有较大的时间开销。化繁就简策略首先筛选与待分类样本相关的候选类别,然后利用对应分类器进行分类,虽可以灵活选择分类类别及分类器,但计算开销较大。分而治之策略依据层次结构逐层分类,虽存在错误累计问题,但时间开销较小。因此,本文采用分而治之的分类策略,用于语言风格的类别判别。
基于层次结构的语言风格判别,主要由获取类别的层次结构、判别语言风格两部分组成,具体流程见图3。
2.1 语言风格类别层次结构获取算法
在语言风格类别层次结构确定过程中,为减少对专家知识的依赖,本文利用层次聚类方法[8]获取语言风格类别层次结构。
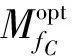
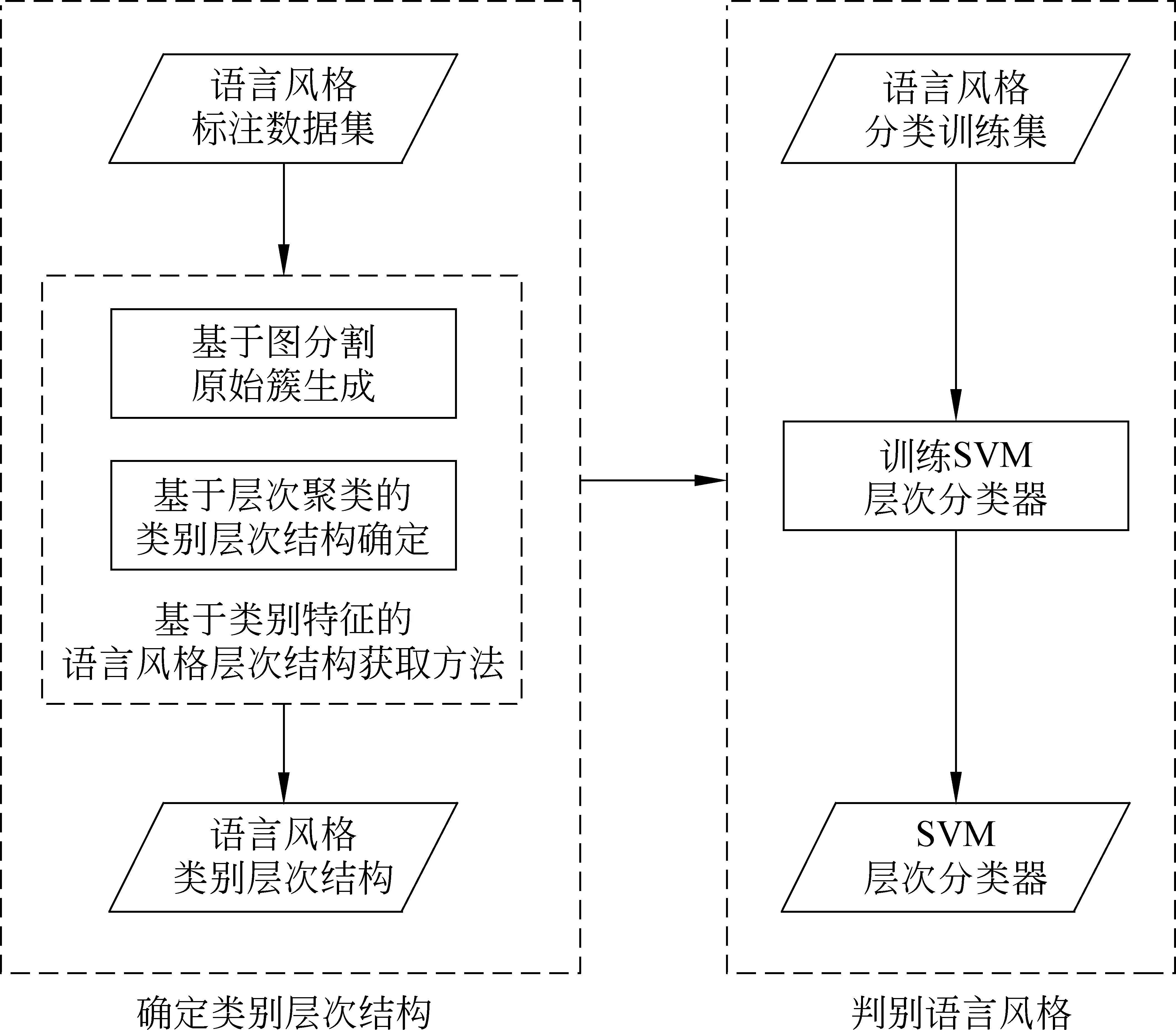
图3 基于层次结构语言风格判别方法流程图
其中,#ct(MfC)为MfC映射关系中ct的特征值。
在层次聚类过程中,本文采用Karypis[8]提出的算法,综合簇间相对互连性[见式(2)]、相对近似性[见式(3)]度量簇间相似性[见式(4)],迭代完成簇间合并。
其中,sci、scj代表两个簇,EC{sci,scj}为簇sci、scj的连接边,ECsci为簇sci的二等分极小割边。
RC(sci,scj)
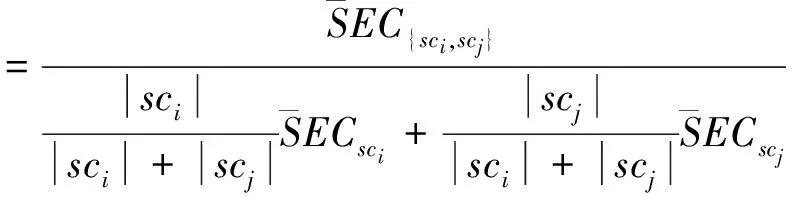
(3)
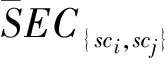
其中,α代表比例参数,用来度量簇间相似度计算过程中相对互联性与相对相似性的重要程度。
依据特征集FC,将语言风格样本表征为向量,采用KNN算法构造样本图,并利用图分割算法获取样本标签原始簇,最后利用层次聚类确定类别层次结构,具体见算法1。

算法1:语言风格类别层次结构获取算法
2.2 基于SVM层次分类的语言风格识别方法
为了对文本语言风格实时、高效地进行判别,并将类别层级结构信息保留于判别结果,本文基于2.1节确定的语言风格类别层次结构,采用“分而治之”的层次分类方法识别语言风格。另外,SVM作为一个以间隔最大化为学习策略的二元分类器,与2.1节中确定的二叉语言风格层次结构相吻合。因此,本文基于SVM层次分类,实现对语言风格的识别,具体流程见图4。
层次分类过程中,首先利用第1层分类器对数据集D进行分类,获得分类结果;然后依据分类结果, 寻找对应SVM分类器, 进行第2层分类; ……;直到获取最终的语言风格标签类别ck(1≤k≤m)。
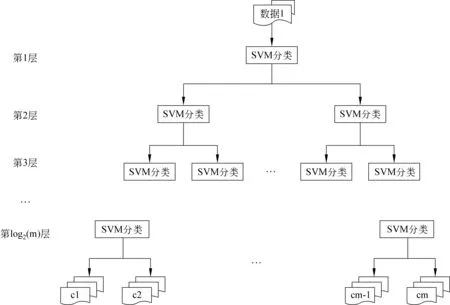
图4 基于SVM层次分类流程图
2.3 基于语言风格识别的鉴赏题解答
为了应对高考对语言风格的考察,本文将利用2.2节中训练的层次SVM分类器,完成对文本语言风格的识别。在高考鉴赏题解答过程中,根据题干选择分类层次,即若题干包括特定的语言风格,则确定分类层次为叶节点;如果题干未提及具体的语言风格,为提高识别准确率,则分类层次确定为叶节点的父节点。然后,基于2.1节确定的类别层次结构AH,利用2.2节中SVM层次分类器识别阅读材料段落语言风格,并结合语言风格作用知识库,生成答案,具体流程见图5。
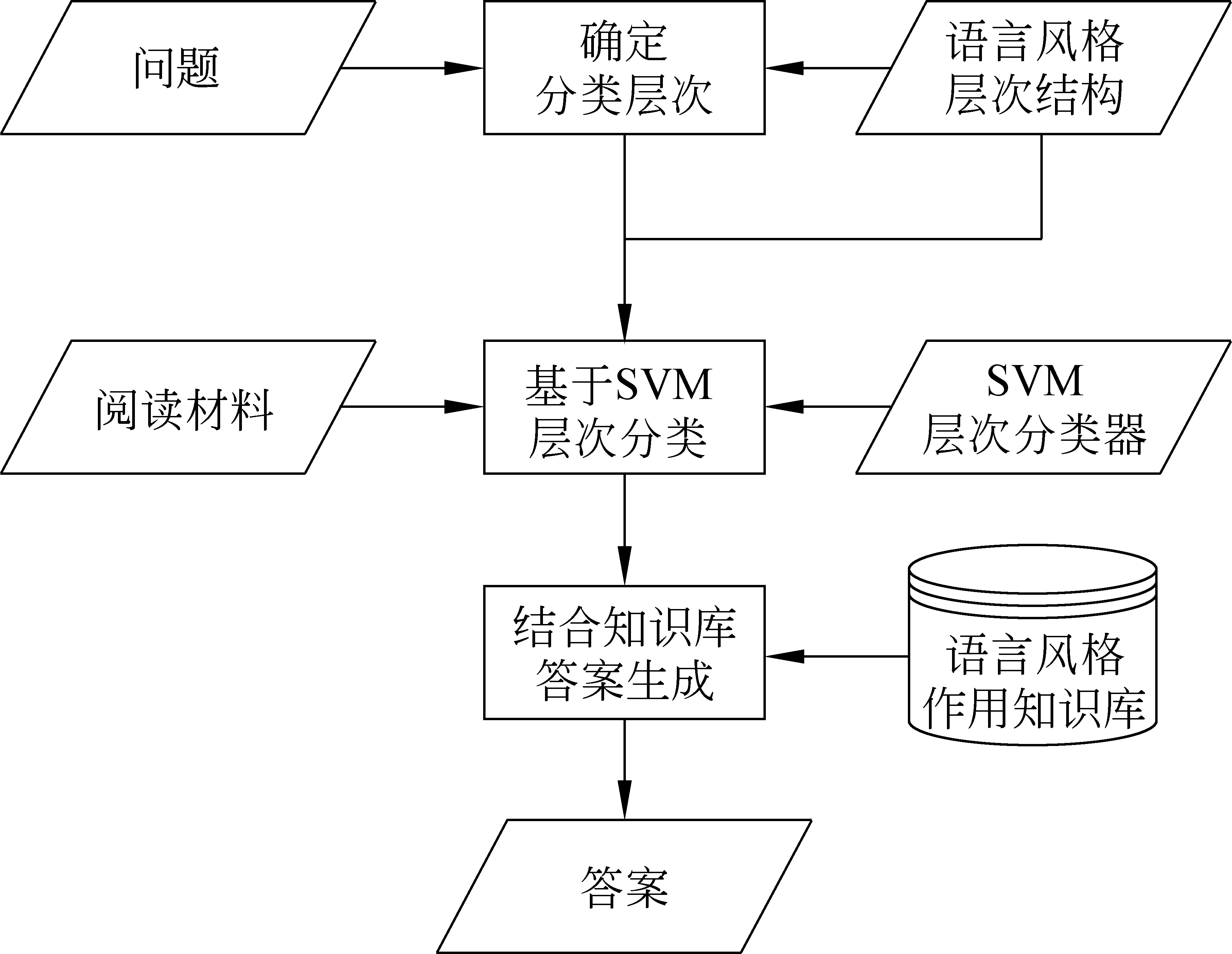
图5 面向高考阅读理解的语言风格鉴赏题解答流程
3 实验数据集及评价指标
3.1 实验数据集
数据集1收集人教版高中课文、全国高考(2002—2016)阅读理解材料,共计484篇,6 646段。利用第2节确定的类别标签进行人工标注,12种类别在数据集中的具体比例见表2。
数据集2为了避免数据不平衡性对类别层次结构获取造成影响,从数据集1中12个类别标注数据中分别选取36条数据,共计432条,作为类别层次结构确定方法验证数据。
3.2 评价指标
语言风格判别整个过程由类别层次结构获取、基于SVM层次分类两部分构成。类别层次获取过程中类别原始簇利用熵、纯度度量;层次分类结果则采用正确率A(accuracy)、准确率P(precision)、召回率R(recall)及F值度量。
(1) 生成原始簇的评价指标
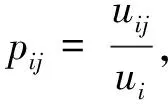

表2 语言风格标注语料类别占比
(5)
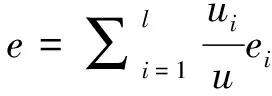
(6)
其中,l代表簇的个数,u代表整个聚类划分样本数。
其熵值越大,说明原始簇分布在各个类别越均匀,原始簇对类别刻画能力越弱。
簇的纯度度量: 簇的纯度为簇中最大类别所占比值,即纯度值越大,簇对单个类别刻画能力越强。聚类簇i的纯度计算见式(7),整个聚类划分的纯度计算见式(8)。
(2) 层次分类的评价指标
正确率A(accuracy)为测试集正确分类的样本数与测试集总样本数占比,其刻画层次分类总体分类准确性。除此之外,本文还利用准确率P(precision)、召回率R(recall)及F1值度量每个类别的分类效果。
4 实验结果与分析
本节针对语言风格判别过程中的类别层次结构生成、基于SVM语言风格层次分类进行实验,用于验证本文语言风格判别的有效性。
实验1语言风格类别层次结构的获取
语言风格类别是由多种因素决定的,其中词汇表达占有重要的地位[1,17]。例如,“丢掉、拿手、脑袋”这些词为口语词语,体现出“朴素自然”语言风格,而书面语“遗弃、擅长、头颅”则能表现出“华丽典雅”的语言风格。因此,我们选取词袋特征作为其表征单元,使用3.1节的层次聚类,设计了三组特征表征实验方案,用于获取类别层次结构,具体如下:
方案1仅使用词袋模型表征文本,记作baseline;
方案2在词袋模型的基础上,增加12维one-hot类别特征,指导层次结构生成;
利用2.1节介绍的算法,基于图分割的原始簇生成结果见表3、表4,层次聚类结果见图6。

表3 聚类原始簇熵值

表4 聚类原始簇纯度
观察表3和表4,随着将类别信息加入到特征后,图聚类生成的原始簇的熵值降低,纯度增加;并且方案3比方案2熵值更低,纯度更高,说明类别特征对图聚类原始簇生成有指导作用,并且一维特征优于“one-hot”方式,分析其中原因如下:
(1) 方案1图分割原始簇生成过程,由于缺少类别标签的指导,每个原始簇中包含多个类别,且各个类别比例差异不大,熵值大,纯度低,即初始簇不能刻画语言风格特定类别。
(2) 一维特征比one-hot特征区分类别能力强。
由于方案1及方案2图分割生成原始簇有较高的熵值、较低的纯度,皆无法明确表达簇与类别间对应关系。因此,将方案3生成的类别层次结构AH(见图6)作为之后层次分类依赖的层次结构。
实验2基于类别层次结构的层次SVM分类
在数据集1上,选取词袋为特征,词频为特征值,分别基于专家编制层次结构MH(见图2)、自动生成层次结构AH(见图6)、平面结构(即一层结构,baseline),采用5次交叉验证对语言风格进行判别。针对实验结果,本文从节点分类、整体分类两个角度分析实验结果。
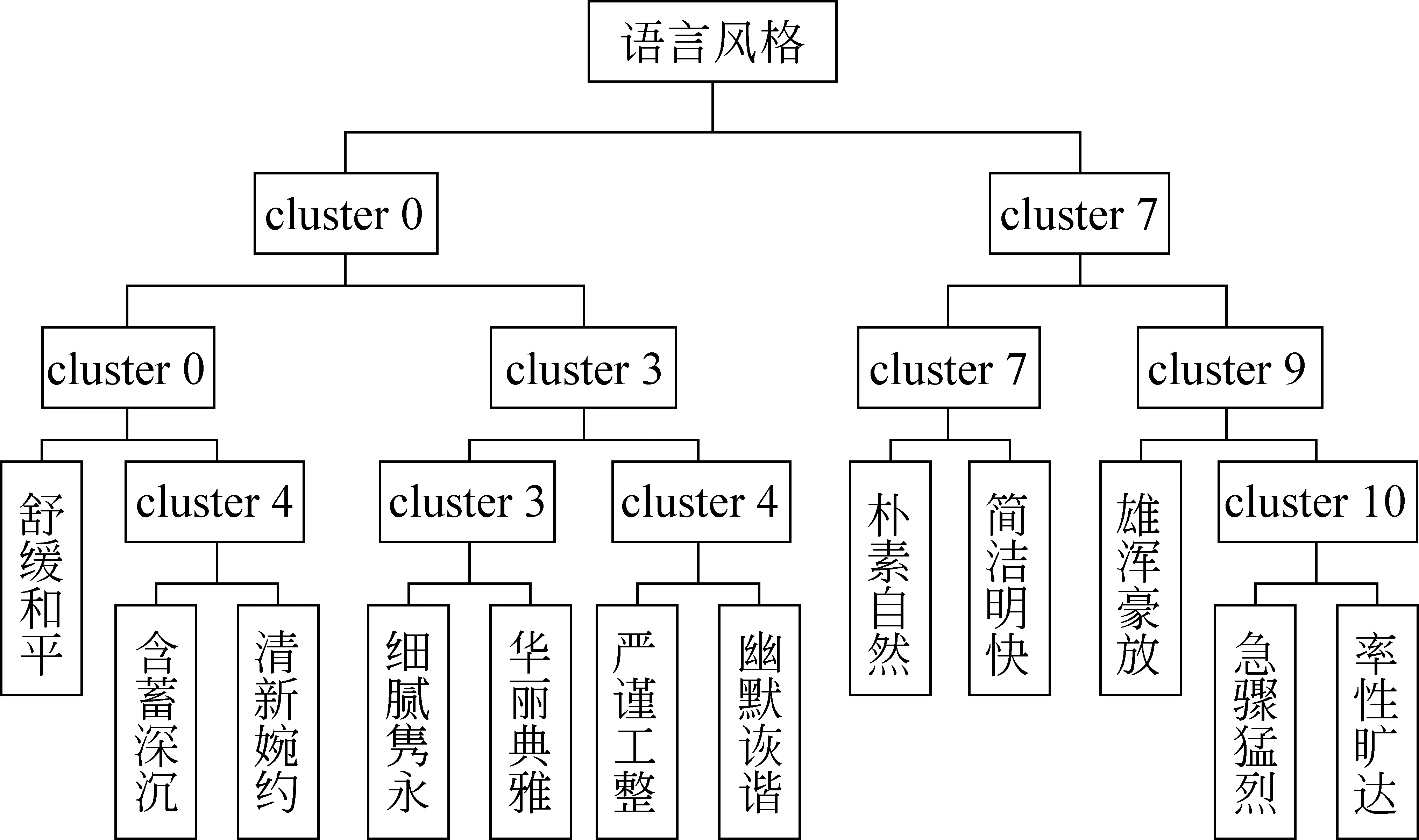
图6 自动生成语言风格类别层次结构AH
(1) 节点分类结果
为了验证层次分类过程中节点分类效果,又鉴于分而治之策略层次分类方法有错误累计的缺点,本文利用正确率A(accuracy)度量层次结构中每个节点的分类效果,具体结果见图7、图8。
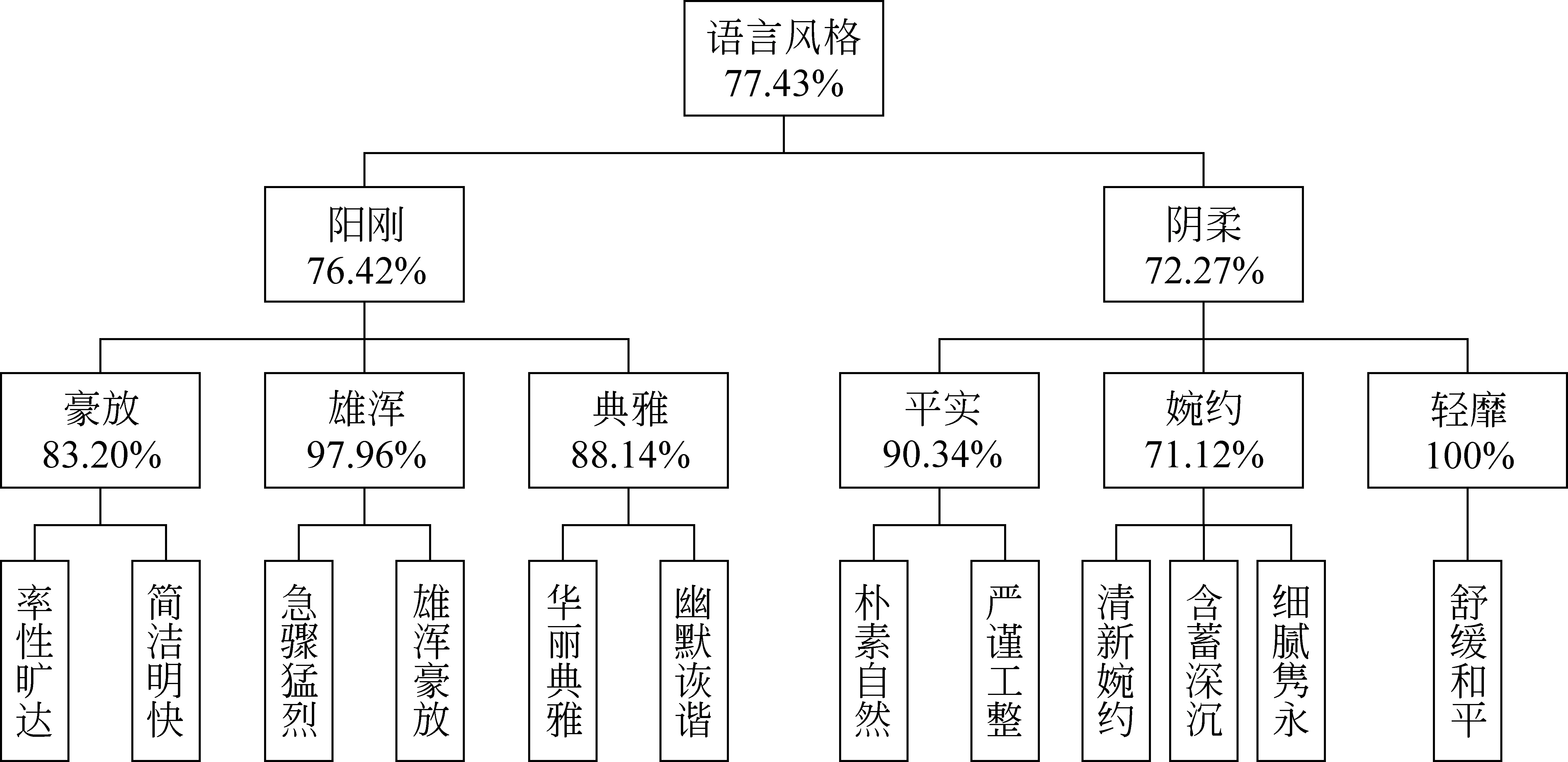
图7 MH节点SVM分类正确率
对比图7、图8中每个节点SVM分类正确率,除第一层外,AH最低正确率为76.11%, 最高正确率为98.12%,而MH中最低正确率为71.12%,最高正确率为97.96%。从而证明AH细粒度分类效果优于MH。另外,从图8中发现,“简洁明快”与“朴素自然”的分类正确率低,只有79.93%,这是由于两种语言风格用词一致性高造成的。
(2) 整体分类结果
为了验证层次分类过程中,结构对整体分类结果的影响,本文将利用正确率(accuracy)、宏准确率(Macro-Precision)、宏召回率(Macro-Recall)及宏F值(Macro-F)对分类结果进行评价,具体结果见表5。

表5 语言风格分类accuracy、Macro-Precision、Macro-recall及Macro-F
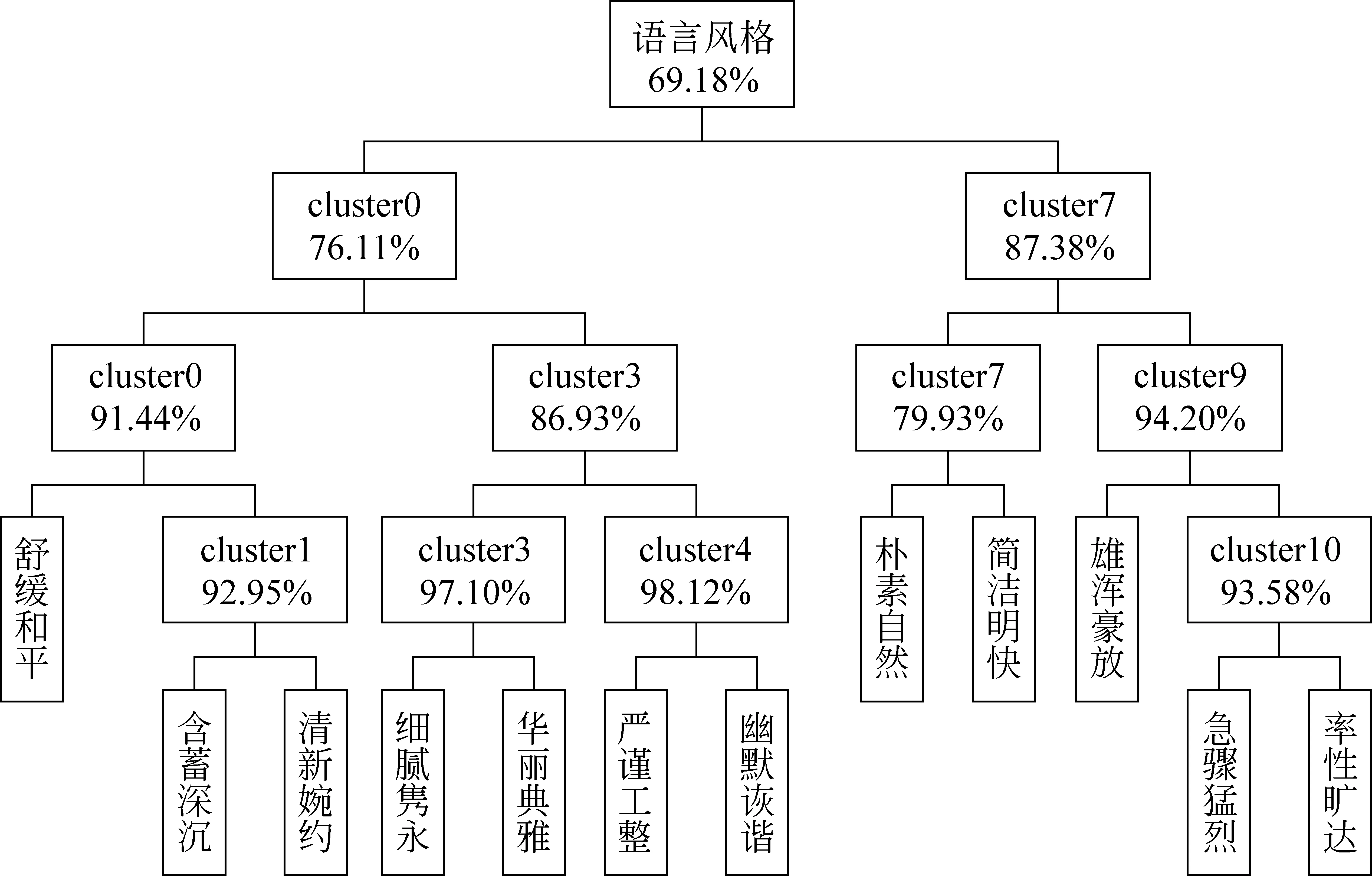
图8 AH节点SVM分类正确率
观察表5可以看出:
(1) AH 的Macro-Precision、Macro-recall、Macro-F均超过MH,即证明自动生成层次结构过程中,本文方法对语言风格类别间关联认识优于专家知识,说明本方法的层次结构划分由具体数据决定,可以根据数据的不同实现层次结构的动态调整。
(2) 语言风格识别过程中,类别层次结构确定与层次分类独立实现,未考虑两个子任务的关联关系,造成AH的Macro-Precision、Macro-Recall、Macro-F都低于平面结构。但AH结构具有层次性,在语言风格识别过程中能自由选择分类的层次,如第1节题目1,为提高准确率,分类过程中可以将其分类至叶节点上一层。从表5所示结果可以看出,AH第三层之前正确率均高于平面分类。
(3) 最终叶节点的分类的正确率,MH略优于AH。但在第二、三层分类正确率中,AH高于MH。结合图7、图8发现,AH中细粒度的分类效果也好于MH。
实验3基于语言风格识别高考语文鉴赏题解答
利用2.3节中语言风格鉴赏题解答流程,针对第1节题目1分别基于平面结构、基于MH、基于AH解答语言风格鉴赏题,记为方案1(baseline)、方案2、方案3。为了验证AH层次信息在答题过程中的有效性,设计方案4、方案5,即分别在MH第二层、AH第三层完成语言风格分类,实验结果见表6。
从表6结果看出,方案1与方案2分别从两段话中识别出一种正确的语言风格,方案3识别出“细腻隽永”与“含蓄深沉”两种正确语言风格,效果优于平面结构及MH结构。
方案4、5分别相对于方案2、3扩充识别语言风格的兄弟节点,然而方案4扩充的语言风格是错误的,方案5扩充的两种语言风格中“华丽典雅”为正确的语言风格,从而说明AH结构优于MH,且AH较平面分类能自由选择分类的粒度。

表6 2012年山东卷高考试题解答结果
5 结论与展望
语言风格作为高考重要考察点,为应对高考不同考察方式所需分类层次差异,缓解多分类对二分类器带来的挑战,本文利用层次分类方法识别语言风格,并结合知识库,完成语言风格鉴赏题的解答。实验证明,层次分类比平面分类具有更强的灵活性,并且基于自动获取结构分类效果好于专家编制结构。但层次分类叶节点的准确率低于平面分类,这是由层次结构获取与基于层次结构分类独立进行,未考虑其关联性造成。接下来的工作中,我们将综合考虑结构获取与层次分类,完成层次多分类任务,进一步提高语言风格识别效果。
[1] 丁金国. 关于语言风格学的几个问题[J]. 河北大学学报(哲学社会科学版), 1984(3):45-57.
[2] 郑荣馨. 语言表现风格论:语言美的探索[M]. 合肥: 安徽大学出版社,1999.
[3] 黎运汉. 语言风格系统论[J]. 渤海大学学报(哲学社会科学版),1996(3):100-105.
[4] 何力, 贾焰, 韩伟红,等. 大规模层次分类问题研究及其进展[J]. 计算机学报, 2012, 35(10):2101-2115.
[5] Tang L, Zhang J, Liu H. Acclimatizing taxonomic semantics for hierarchical content classification[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2006:384-393.
[6] Nitta K. Improving taxonomies for large-scale hierarchical classifiers of web documents[C]//Proceedings of the ACM Conference on Information and Knowledge Management, 2010:1649-1652.
[7] Phongwattana T, Engchuan W, Chan J H. Clustering-based multi-class classification of complex disease[C]//Proceedings of the International Conference on Knowledge and Smart Technology. IEEE, 2015:25-29.
[8] Karypis G, Han E H, Kumar V. CHAMELEON: a hierarchical clustering algorithm using dynamic modeling[J]. Computer, 1999, 32(8):68-75.
[9] Karypis G, Kumar V. A fast and high quality multilevel scheme for partitioning irregular graphs[J]. Siam Journal on Scientific Computing, 2006, 20(1):359-392.
[10] Xiao W, Yang Y, Wang H, et al. Semi-supervised hierarchical clustering ensemble and its application [J]. Neurocomputing, 2016,(173):1362-1376.
[11] 宗世海. 论言语风格的分类[J]. 语文研究, 2003,(3):42-46.
[12] 丁金国. 语言风格的研究平面[J]. 烟台大学学报(哲学社会科学版), 1991,(4):65-73.
[13] 黎运汉. 1949年以来语言风格定义研究述评[J]. 语言文字应用, 2002,(1):100-106.
[14] 陈继民. 品鉴散文的语言风格[J]. 中文自修, 1995,(12):17.
[15] 宋振华, 吴士文, 张国庆,等. 现代汉语修辞学[M]. 天津: 天津人民出版社, 1963.
[16] 戈娟. 初中现代散文语文教学研究[D]. 杭州: 杭州师范大学, 2016.
[17] 马琳. 论以语言要素为手段的语言风格构建[J]. 长江师范学院学报, 2004, 20(6):48-50.
