基于汉语框架语义网的篇章关系识别
2017-03-12李国臣张雅星
李国臣,张雅星,李 茹,3,4
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 太原工业学院 计算机工程系,山西 太原 030008;3. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;4. 山西省大数据挖掘与智能技术协同创新中心,山西 太原 030006)
0 引言
篇章关系识别是篇章分析中重要的子任务,它研究的是篇章中两个篇章单元的关系。例如,本文给出一个简单篇章: “令人欣喜的是,现在媒体对会议进行了相当广泛的评论和报道。”通过对该篇章中的两个篇章单元进行篇章关系识别,可以得到前置篇章单元“令人欣喜的是”与后置篇章单元“现在媒体对会议进行了相当广泛的评论和报道”的篇章关系为解说关系。
目前,篇章关系的分析主要是面向英文,其中最主要的原因是英文的篇章分析理论体系比较完善。英文的篇章分析理论体系主要有修辞结构理论(rhetorical structure theory,RST)和宾州篇章树库(penn discourse TreeBank,PDTB)。
修辞结构理论[1]是由美国学者William C. Mann和Sandra A. Thompson 等首创于1988年,是一套关于自然语篇结构描写的理论体系。基于RST的篇章关系识别主要有两个子任务: ①基本篇章单元的生成;②根据RST对篇章单元之间的篇章关系进行分析。根据话语效果的位置,RST将篇章中的修辞关系分为两个大类: 并列型的“多级核心(multinuclear)关系”和主从型的“核心(nuclear)/辅助(satellite)关系”。其中并列型关系分为对比、结合、列举、多级核心重述和序列,主从型关系分为“表述”和“主题”关系。目前,已有许多学者在修辞结构理论篇章树库(rhetorical structure theory-discourse TreeBank,RST-DT)[2]上展开了研究和实验。Marcu[3]提出了一种无监督的方法来识别篇章关系,该方法从训练语料中抽取词对信息作为基本特征训练贝叶斯分类模型,其中某些句间关系分类模型取得了93%的准确率。
宾州篇章树库[4]主要标注与篇章连接词相关的篇章关系。宾州篇章树库根据两个篇章单元之间是否存在连接词,将篇章关系分为显式篇章关系和隐式篇章关系。其中隐式篇章关系又分为替代词汇化(AItLex)、基于实体一致性关系(EntRel)、没有关系(NoRel)。宾州篇章树库还另外对所有的篇章关系定义了一个三层的语义结构: 第一层是种类,第二层是类型,第三层是子类型。其中,第一层包括四种最常见的语义: 扩展(expansion)、时序偶然(contingency)、对比(comparison)和时序(temporal),第二层包括16类语义,第三层包括23类语义。在篇章关系识别方面,Pilter[5]等人在连接词识别的基础上使用朴素贝叶斯方法依据连接词和句法信息特征对第一层显式关系进行识别,其准确率达到了94.15%。Lan[6]等人在交互结构优化多任务学习框架下,抽取论元的动词、极性等基本语言学特征训练基于现实语境的隐式论元对数据的主分类器和基于人造伪隐式论元对数据的辅分类器,提升隐式关系推理性能至42.30%。
在汉语方面,孙静[7]等人在自建的汉语篇章结构语料库(Chinese discourse TreeBank,CDTB)上进行了隐式篇章关系的识别。张牧宇[8-11]等人在哈工大中文篇章关系树库(HIT-CDTB)上进行了篇章分析的相关研究。目前篇章关系分析方法主要采用短语结构、依从句法、词共现等一些篇章的浅层特征进行分析,虽然这些特征对篇章关系分析具有很大的作用,但是篇章关系识别是一项有挑战性的任务,仅依靠这些浅层特征不能有效地完成篇章关系识别任务。篇章分析只有在分析了篇章上下文知识、理解了有联系的篇章单元的语义之后,才能更好地分析出篇章单元之间的语义关系。因此,本文在苏娜[12]基于汉语框架语义所构建的理论体系上进行篇章关系的识别。在该理论体系中,篇章由与该篇章内容相关的框架集组合而成,具体描述为: 较小的框架集描述的场景按照篇章关系组合形成更大的场景,并进一步再与相邻的框架集所描述的场景组合,最终形成一棵具有层次的篇章框架语义结构树,描述一个完整的最大的语义场景。根据该理论体系,每个篇章单元的场景可以由框架集进行描述,因此,每个篇章单元都可以由相应的框架集代替。本文找出可以代替要分析的篇章单元的场景的框架集,用该框架集中的核心框架来代替该语义场景,因此将分析两个篇章单元间的关系改为分析两个框架的关系。而且在本文所用的方法中,用框架语义识别篇章关系,可以有效改善篇章关系识别性能。
本文在第1节简单介绍了汉语框架语义网;在第2节具体介绍了篇章关系识别的步骤;在第3节描述了实验设置并对实验结果进行分析;在第4节总结全文并展望未来的研究工作。
1 汉语框架语义网介绍
汉语框架语义网(Chinese FrameNet,CFN)[13-14]是山西大学在Fillmore提出的框架语义学基础上所构建的,以加州大学伯克利分校的FrameNet为参照,以汉语真实语料为依据,是一个供计算机使用的汉语词汇语义知识库。该知识库包括框架库、句子库、词元库三部分。
框架库以框架为单位,对词语进行分类描述。框架是一些与激活性语境相一致的结构化范畴系统,它是存储在人类认知经验中的图示化情境,是理解词语的背景和动因,场景内容可以是一个动作、一个活动事件、一个实体或者一个抽象体的状态。框架承担词包括动词、形容词、名词、成语及一些约定俗语,它们是能够激起汉语框架语义网某个框架所对应的语义场景的词语,是标注工作的着眼点,称为词元。一般情况下,一个框架包括多个词元。在实际例句中出现的可以激起框架语义场景的词元是目标词。
例1篇章单元“这位负责人表示这些年各地高度重视保障工资支付工作。”中的目标词有“表示”“重视”。“表示”与“重视”可以激起的框架分别为“陈述”“重视”,也即“表示”为框架“陈述”的词元,“重视”为框架“重视”的词元。以“表示”为例对该篇章单元进行分析后可得:
2 基于汉语框架语义网的篇章关系识别
本文基于汉语框架语义网识别篇章关系,通过使用篇章单元对的框架集合,对篇章单元对的框架对进行抽取,得到框架对关系表,将待测篇章单元对的核心目标词对对应的框架对与框架对关系表进行对照,得到待测篇章单元对的篇章关系。篇章关系识别的具体流程如图1所示。

图1 篇章关系识别流程图
本文对篇章关系的识别主要包括以下三个步骤:
(1) 将已标注语料分为训练数据集和测试数据集,对训练数据集进行框架对的抽取,得到框架对与对应关系的映射,计算每个框架对的最大概率关系,生成框架对关系表;
(2) 抽取特征训练核心目标词识别模型,对测试数据集的篇章单元对进行核心目标词的识别,生成核心目标词对;
(3) 将测试数据集的核心目标词对对应的框架对与第一步生成的框架对关系表进行对照,得到测试数据集对应的篇章关系。
2.1 框架对关系表生成
2.1.1 框架对抽取
对所标注语料进行框架对抽取的具体步骤为:
(1) 抽取前置篇章单元的所有框架,获得框架集合FrameSet1,FrameSet1包含m个框架{Frame11,Frame12,…,Frame1m};同理,抽取后置篇章单元的所有框架,获得框架集合FrameSet2,FrameSet2包含n个框架{Frame21,Frame22,…,Frame2n};
(2) 对FrameSet1和FrameSet2中的所有框架进行两两配对,形成所有可能的框架对{Frame1i,Frame2j}i =1…m,j = 1…n;
(3) 该篇章单元对形成的所有的框架对都对应于该篇章单元对已经标注的篇章关系;
(4) 对所有的篇章单元对进行上面三个步骤,得到所有训练集形成的框架对与对应关系的映射。
下面以例2为例,对抽取框架对的步骤进行详细说明。
例2篇章单元对: 在新的历史时期中国梦的本质是国家富强、民族振兴、人民幸福,我们的奋斗目标是到2020年全面实现小康社会。
前置篇章单元: 在新的历史时期中国梦的本质是国家富强、民族振兴、人民幸福
后置篇章单元: 我们的奋斗目标是到2020年全面实现小康社会
篇章关系: 并列关系
在例2中,前置篇章单元和后置篇章单元包含的目标词和对应框架如表1所示。
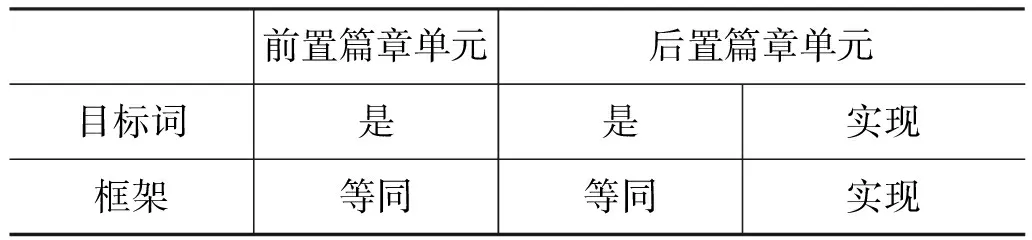
表1 篇章单元对的目标词与框架
从表1可以看出,前置篇章单元的框架集合FrameSet1为{等同},后置篇章单元的框架集合FrameSet2为{等同,实现},则对FrameSet1和
FrameSet2中的框架两两配对形成的框架对为{等同,等同}、{等同,实现}。根据该篇章单元对的篇章关系为并列关系,则这两对框架对的对应关系为并列关系。对所有的篇章单元对进行如例2所示的步骤,得到所有训练集形成的框架对与对应关系的映射。
2.1.2 框架对的最大概率关系
将得到的所有框架对以及每个框架对在不同篇章单元对中的相应关系进行不去重合并,得到框架对与篇章关系的关系映射表Fmap。
借助关系映射表Fmap,本文对每种框架对最可能对应的关系进行计算。将篇章关系的11种关系进行编号i,i∈{1,2,…,11}。特定框架对{Frame1i,Frame2j}i =1...m,j = 1...n在关系映射表Fmap中对应这11种关系出现的频次分别为ri,i∈{1,2,…,11},在关系映射表中出现的总数为n。本文用ri除以n计算特定框架对{Frame1i,Frame2j}i =1...m,j = 1...n在每种关系上的分布概率,其分布概率最大的数值对应的关系r为该框架对的篇章关系,计算i的公式如式(1)所示。
例2中的框架对{等同,等同},在关系映射表中对应递进关系出现1次,对应解说关系出现1次,对应因果关系出现4次,对应并列关系出现9次,其余关系类都没有出现,则出现总次数为15次。分别用1,1,4,9除以15,可以得到概率最大的出现次数为9次的并列关系,则框架对{等同,等同}对应的篇章关系为并列关系。
本文对关系映射表Fmap中的每种框架都进行上述计算,得到框架对关系表FRmap。获得FRmap的算法如下:

算法1:获取框架对关系表FRmap算法输入:篇章单元对集合D={D1,D2,...,Dn},每个篇章单元对Di的前置篇章单元Di1和后置篇章单元Di2的篇章关系Ri输出:框架对关系表FRmap1.FORDiIND2. FORDijINDi //j∈{1,2}3. 获得Dij的框架集合FrameSetj={Framej1,Framej2,....,Framejm}4. ENDFOR5. FORFrame1xINFrameSet16. FORFrame2yINFrameSet27. Frame1x与Frame2y配对,并将{Frame1x,Frame2y,Ri}放入表Fmap8. ENDFOR9. ENDFOR //得到篇章单元对Di前置篇章单元的所有框架和后置篇章单元的所有框架的两两配对 10.ENDFOR 11.FORFmapiINFmap12. IF!Fmapi∈FRmap //只进行框架对的对照13. 根据公式(1)计算框架对Fmapi的篇章关系,并将该框架对和对应篇章关系放入表FRmap14. ENDIF15.ENDFORReturnFRmap
2.2 核心目标词识别
识别核心目标词的着眼点是篇章单元中的一个词,识别该词是否是核心目标词,因此本文将这项任务看做分类问题来解决,使用最大熵模型构建分类模型。
在本实验中,用向量X表示篇章单元,用y表示候选目标词是否是核心目标词,p(y|X)为预测X为y的概率,熵定义为:
采用拉格朗日乘数法求解最大熵,计算公式为:
其中,fi表示每个特征,n表示特征总数,λi为特征的权重。
抽取词形、词性、当前词前一个词的词性、当前词后一个词的词性、依从关系来分别表示训练集数据和测试集数据,用最大熵分类模型在训练数据集上进行训练,在测试数据集上进行识别,得到篇章单元的核心目标词。
2.3 篇章关系识别
将测试数据集中的篇章单元对进行核心目标词识别,得到每个篇章单元的核心目标词,从而可以得到篇章单元对的核心目标词对,得到所对应的框架对。
将篇章单元对的核心目标词对对应的框架对与FRmap进行对照,得到该框架对对应的篇章关系。该篇章关系就是待测篇章单元对的关系。下面以例3为例,对篇章关系的识别步骤进行说明。
例3篇章单元对: 仅2012年全国共发生0到12岁儿童伤亡交通事故11 117起,造成12 153名儿童伤亡。
前置篇章单元: 仅2012年全国共发生0到12岁儿童伤亡交通事故11 117起
后置篇章单元: 造成12 153名儿童伤亡
例3中,前置篇章单元的核心目标词是“发生”,所属框架为事件;后置篇章单元的核心目标词是“造成”,所属框架是因果。因此可以得到该待测篇章单元对的核心目标词对对应的框架对为{事件,因果},与框架对关系表FRmap对照,可以得到{事件,因果}的篇章关系为承接关系,所以该篇章单元对的篇章关系为承接关系。
本文基于框架语义的篇章关系识别算法如下:

算法2:篇章关系识别算法输入:待测篇章单元对D,框架对关系表FRmap输出:待测篇章单元对的篇章关系1.FORDiIND //i∈{1,2}2. 将Di经过核心目标词识别模型,识别出核心目标词Wi3.ENDFOR4.将核心目标词对{M1,M2}在FRmap中查找对应的篇章关系RReturnR。
3 实验设置与结果分析
3.1 实验语料
3.1.1 篇章关系
本文所采用的篇章关系[12]是基于黄伯荣和廖序东的《现代汉语》中关于复句以及句群之间关系分类体系而建立的。该篇章关系结构分为三层。第一层根据篇章单元之间意义是否平等分为联合关系和偏正关系。第二层中,联合关系可分为并列关系、承接关系、递进关系、选择关系、解说关系。偏正关系可分为条件关系、假设关系、因果关系、目的关系、转折关系、属于关系。该体系在传统的偏正关系中加入“属于关系”这一类别,属于关系表示篇章的意图以及意图的所有者的所属关系。第三层根据前后篇章单元的功能分为24类。在该篇章关系中,如果无法区分篇章单元之间的关系,就将其归为承接关系中的连贯关系。前两层篇章关系如表2所示。

表2 前两层篇章关系
3.1.2 篇章语料库
本文研究的是相邻的两个篇章单元之间的关系,并且本文的实验方法是基于汉语框架语义网的,因此所用语料必须具有下列特点:
(1) 具有前置篇章单元和后置篇章单元;
(2) 前置篇章单元和后置篇章单元必须且至少包含一个可以激起框架的目标词。
本文对所获得的语料都进行了人工标注,对每对篇章单元对都标注了框架与篇章关系。这些语料主要来源于新闻语料和语料库在线。语料中各个篇章关系的分布概率如表3所示。

表3 篇章语料库
在训练识别核心目标词模型时,本文使用哈尔滨工业大学信息检索研究中心的语言处理集成平台LTP[15]对语料进行预处理。实验语料的统计结果如表4所示。

表4 标注语料
3.2 评价标准
本文使用准确率Acc(Accuracy)、精确率P(Precision)、召回率R(Recall)和F值F作为篇章关系识别性能的度量指标。假设i∈{1,2,…,11},分别对应11种篇章关系中的一种,Ri为实验中预测出关系为i的个数,Ci为实验中预测正确的关系为i的个数,Ai为测试集中关系为i的个数,则:
(1) 计算11种关系总的性能时,本文将准确率、精确率、召回率和F值表示如下:
(6)
(8)
(2) 分别计算每种关系的性能时,本文将准确率、精确率、召回率和F值表示如下:
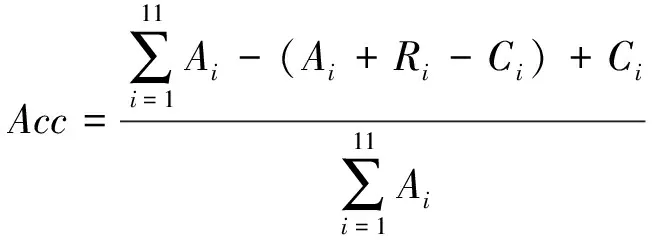
(9)
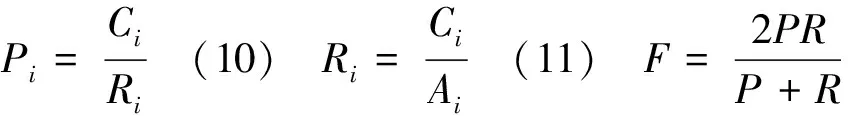
(12)
3.3 实验结果与分析
3.3.1 框架对关系表FRmap的生成
本文选用了2 774篇篇章单元对作为训练数据集生成框架对关系表FRmap,200篇篇章单元对作为测试数据集。
生成的框架对关系表FRmap共有2 216对不同框架对,其中11种篇章关系的分布概率如表5所示。
3.3.2 核心目标词的识别
本文对要测试的200篇篇章单元对即400个篇章单元经过预处理,然后用生成的核心目标词识别模型进行识别。识别结果如表6所示。

表5 FRmap

表6 核心目标词识别结果
经过分析,识别核心目标词正确率不高的原因是: 训练语料无法包含所有的目标词,存在未登录词,使得核心目标词的识别存在困难。对于篇章单元对,对各位专家学者提出的思想观点、意见建议,要认真归纳、研究、吸收。识别后置篇章单元“要认真归纳、研究、吸收”的核心目标词时,经过核心目标词识别模型的识别,目标词“归纳”“研究”“吸收”为核心目标词的概率相同,无法准确判断核心目标词。
3.3.3 篇章关系的识别
按照本文所说实验步骤进行,所得到的最终结果如表7所示。

表7 篇章关系识别结果
通过表7可以看出,“选择类”没有识别出来,“目的类”和“假设类”的识别率较低,这是由于数据稀疏引起的,在所有语料中,“选择类”仅有五例,“目的类”所占比例为6.36%,“假设类”所占比例为3.03%。“承接类”和“递进类”的识别效率低,则是由于承接类和递进类的语义比较相近,比较难以区分这两个类别。“属于类”识别效果最好,这是由于“识别类”的篇章单元多由“说”“称”“强调”等可以激起“陈述”框架词语进行引导,而且属于类的实例也比较多,因此“属于类”效果最好。
在测试集中,将每个篇章单元对中的框架都进行两两配对,生成框架对的步骤与生成框架对关系表FRmap的步骤一样。将生成的每一对框架对都和FRmap进行对照,得到框架对对应的篇章关系,将该篇章单元对的所有框架对对应的篇章关系进行统计,篇章关系相同的进行相加,最后出现最多的关系为该篇章单元对的关系。所得实验结果如表8所示。
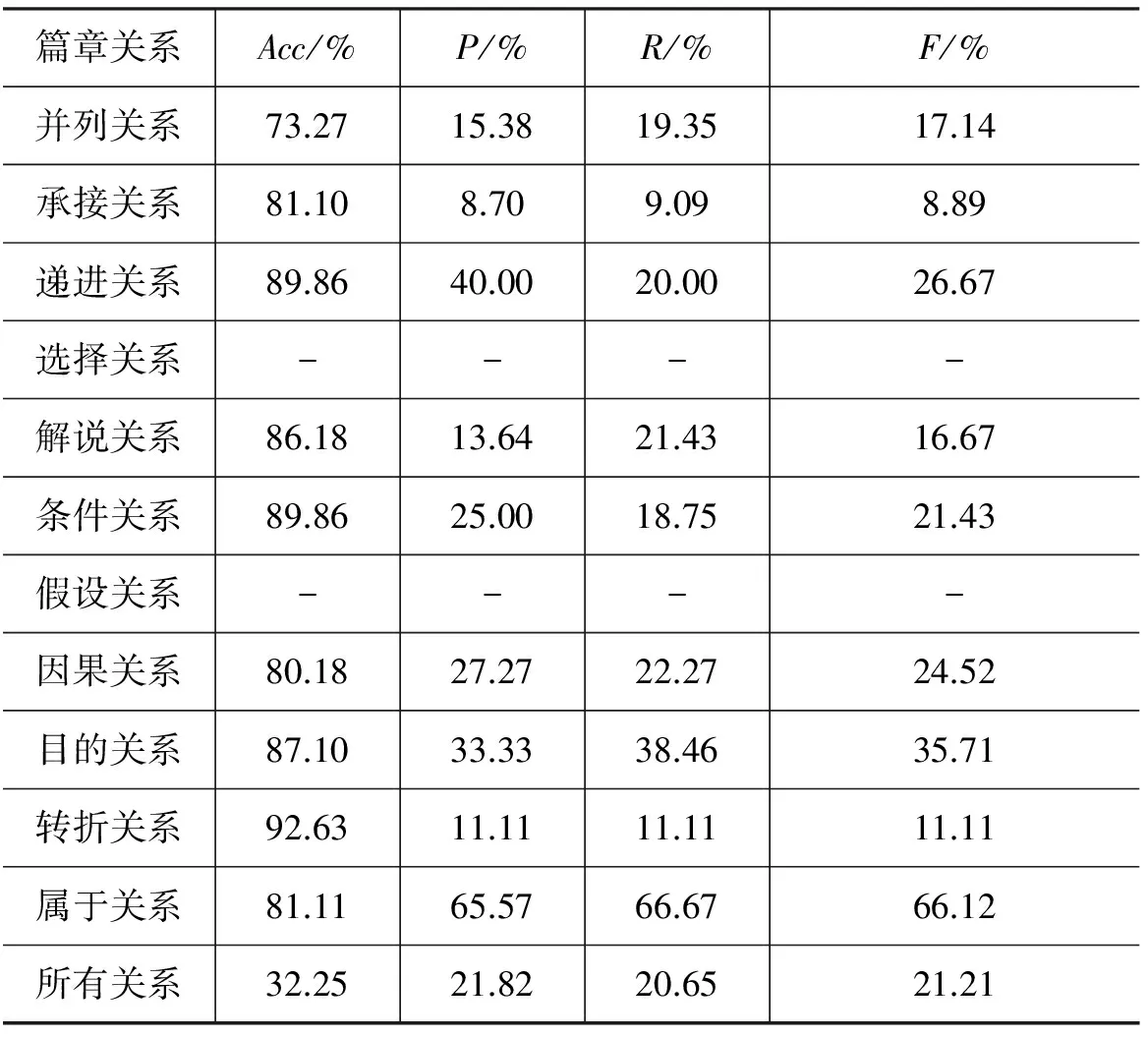
表8 篇章单元时关系识别结果
表8中,“选择类”和“假设类”都没有识别出来,这是由于数据稀疏引起的,在整个语料中,“选择类”仅仅有五例,“假设类”所占比例为3.03%。与表7对比可以发现,表7中只有“选择类”没有识别出来,说明该方法更加依赖于语料规模的大小。图2中对两个实验的精确率进行对比。
通过图2可以看出,表8的篇章关系识别结果只有“递进类”和“目的类”比表7好,因此可以看出识别篇章单元的核心目标词可以提高识别篇章关系的准确率。这是由于表8所示的实验采用的是简单配对的方法,触发核心框架的概率小,所形成的框架对无法较好地表达篇章单元的核心语义,因此识别篇章单元对的篇章关系效果差。
我们运用严为绒等[16]的方法,计算待测篇章单元对中的框架对的互信息,选取互信息排序前四的框架对,将每一对框架对都和FRmap进行对照,得到框架对对应的篇章关系,将在这四个篇章关系中出现次数最多的关系判断为待测篇章单元对的篇章关系。在本文语料库上进行测试,所得结果如表9 所示。
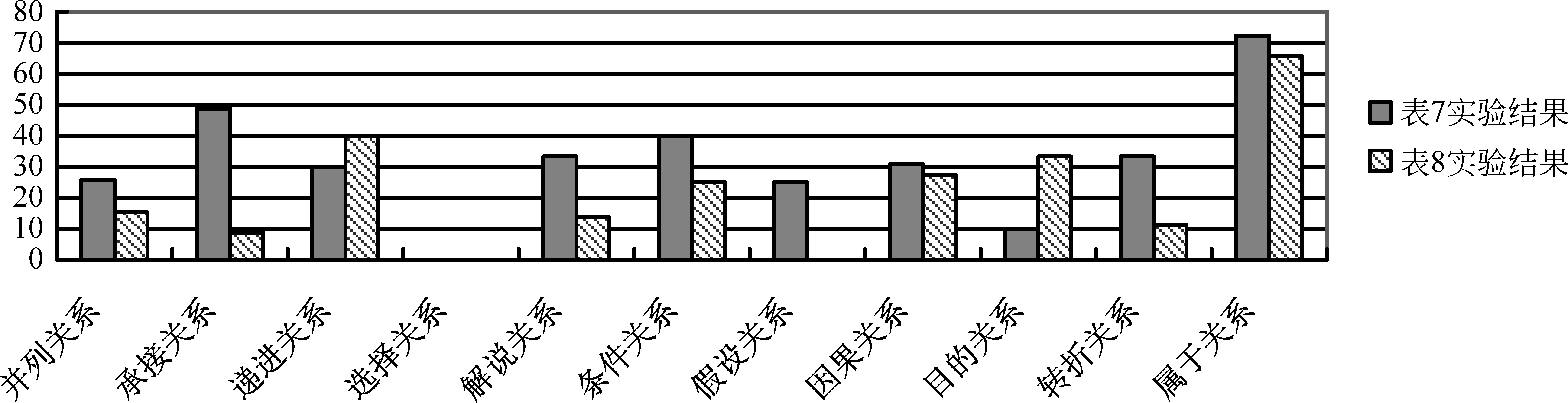
图2 实验结果对比

识别方法Ours(核心框架)Ours(简单配对)互信息Acc/%43.5532.2534.65
对比结果显示,运用核心框架进行识别的性能最好。造成这一结果最主要的原因便是本文的语料规模较小,而互信息对语料的依赖性较大。目前,有关中文篇章关系的语料库规模都较小,因此本文的算法对中文篇章关系分析有更大的适用性。
5 总结与展望
本文基于汉语框架语义网识别篇章关系,研究了如何在框架语义层面进行篇章关系的识别。基于汉语框架语义所构建的理论体系中篇章是由与该篇章内容相关的框架集组合而成的,因此本文用核心框架代表篇章单元。在识别核心框架过程中,本文用的是最大熵分类模型。在该实验中由于所用语料有限,因此最大的问题便是数据稀疏问题,导致框架配对中无法包含所有的框架对,在未来的工作中可以在这方面进行优化,同时有效使用汉语框架语义网的相关资源,如框架的语义角色、框架关系等。
[1] Mann W C,Thompson S A. Rhetorical structure theory: Toward a functional theory of text organization[J]. Text,1988,8(3):243-281.
[2] Carlson L, Marcu D, Okurowski M E. Building a discourse-tagged corpus in the framework of rhetorical structure theory[C]//Proceedings of 2nd SIGdial Workshop on Discourse and Dialogue,2001:1-10.
[3] Marcu D, Echihabi A. An unsupervised approach to recognizing discourse relations[C]//Proceedings of the
40th Annual Meeting on Association for Computational Linguistics(ACL),2002:368-375.
[4] Prasad R,Dinesh N,Lee A,et al. The Penn discourse treebank 2.0[C]//Proceeding of the 6th International Conference on Language Resources and Evalution(LREC),Marrakech,Morocco,2008:2961-2968.
[5] Piter E, Nenkova A. Using syntax to disambiguate explicit discourse connectives in text[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers,2009: 13-16.
[6] Lan M,Xu Y,Niu Z Y. Leveraging synthetic discourse data via multi-task learning for implicit discourse relation recognition[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics,2013:476-485.
[7] 孙静,李艳翠,周国栋,等. 汉语隐式篇章关系识别[J]. 北京大学学报(自然科学版),2014,50(1):111-117.
[8] 张牧宇,宋原,秦兵,等. 中文篇章级句间语义关系识别[J]. 中文信息学报,2013,27(6):51-57.
[9] 张牧宇,秦兵,刘挺. 中文篇章级句间语义关系体系及标注[J]. 中文信息学报,2014,28(2):28-36.
[10] 姬建辉,张牧宇,秦兵,等. 中文篇章级句间关系自动分析[J]. 江西师范大学学报(自然科学版),2015,39(2):124-131.
[11] 张牧宇,秦兵,刘挺. 中文篇章关系任务分析及语料标注[J]. 智能计算机与应用,2016,6(5):1-4.
[12] 苏娜. 基于框架语义的汉语篇章连贯性研究[D]. 山西大学硕士学位论文,2016.
[13] 李茹. 汉语句子框架语义结构分析技术研究[D]. 山西大学博士学位论文,2012.
[14] 郝晓燕,刘伟,李茹,等. 汉语框架语义知识库及软件描述体系[J]. 中文信息学报, 2007,21(5): 96-100.
[15] 刘挺,车万翔,李正华. 语言技术平台[J]. 中文信息学报,2012,25(6):53-62.
[16] 严为绒,朱珊珊,洪宇,等. 基于框架语义的隐式篇章关系推理[J]. 中文信息学报,2015,29(3):88-99.
