融合概念对齐信息的中文AMR语料库的构建
2017-03-12卜丽君曲维光薛念文
李 斌,闻 媛,宋 丽,卜丽君,曲维光,薛念文
(1. 南京师范大学 文学院,江苏 南京 210023;2. 南京师范大学 计算机科学与技术学院,江苏 南京 210023;3. 闽江学院 福建省信息处理与智能控制重点实验室,福建 福州 350121;4. 布兰迪斯大学 计算机学院,美国 沃尔瑟姆市 02453)
0 引言
句子语义的自动分析,是继词法分析、句法分析之后自然语言处理学界寻求突破的重点课题。但是关于句子语义的理论众说纷纭[1-3],又缺乏大规模的语义标注实践,使得语义自动分析研究停滞不前。究其原因,语义不同于句法,语义结构很难像句法结构那样简明地表示出来。在这种背景下,以美国南加州大学Kevin Knight为代表的欧美多位学者近年共同提出了AMR(abstract meaning representation,抽象语义表示)的句子语义表示方法[4],标注了英语《小王子》等文学、新闻、生物领域的语料。AMR较好地解决了句子语义表示的三个难题: ①以句法语义为重点,兼顾词汇语义,允许增删原句词语,表示能力强[5];②表示方法简明直观,人工标注一致性已到达0.83,并建立了四万多句的大规模英语语料库;③统计机器学习方法在英语AMR自动分析上已经取得了0.62左右的F值[6]。
不过,除了分析精度不高,尚在初创期的AMR也存在三个问题: ①忽略虚词、形态变化的各种语法意义和复句关系;②AMR图上的概念没有与原句的词语对齐,而自动对齐的F值仅有90%左右[7],这就意味着对齐问题解决后自动分析还有一定提升空间;③其他语言的语料还很少,图结构的跨语言有效性有待进一步论证。因此,补充一定的语法意义,增加复句关系和对齐信息,提高AMR的自动分析效果,增加更多语种的AMR语料,深入探讨AMR的语言学理论价值[8],就成为目前该领域最为迫切的研究内容。而目前,中文AMR的语料库规模很小,只有1 000多句缺少概念对齐的《小王子》语料[9],亟需调整标注方法,扩大语料规模。
本文根据AMR的基本理论和原则,给出了融合AMR语义图与原句对齐的一体化人工标注方案和软件平台,结合汉语的特点制定汉语AMR的标注体系和标注规范,建立了近7 000句的中文AMR(下文简称CAMR)语料库。然后,针对汉语中的语义图、非投影树、环等结构进行统计分析,阐述对齐版CAMR语料库的价值。
1 AMR简介与语料标注体系
AMR是一种抽象的句子语义的表示方法,不同于传统的树形(tree)结构,它将一个句子的语义抽象为一个单根有向无环图(a single rooted, acyclic, directed graph)。所谓“抽象”是指,把句子中的实词抽象为概念节点,把实词之间的关系抽象为带有语义关系标签的有向弧,忽略虚词和由形态变化体现的较虚的语义(如冠词、单复数、时态等),同时还允许补充句子中省略或缺失的概念。AMR虽采用图结构,但其单根的要求使得句子依然以依存树结构为主体,层次鲜明。下面以实例来说明AMR作为句义表示方法的两个优点。
(1)采用图结构处理论元共享问题。AMR与传统句义表示方法的主要差异在于对论元共享现象的处理。例如,在英语句子“He wants to eat the apple”及汉语翻译“他想吃苹果”中,传统的句法分析方法,如短语结构文法和依存文法,都限于树形结构,会舍弃“他-吃”这个施事关系;而AMR则将两个关系都保留,形成图结构,解决了“他”同时作为“想”和“吃”的arg0(施事)问题。图1给出了AMR的两种展现形式: 图示法(上)和文本缩进法(下)。
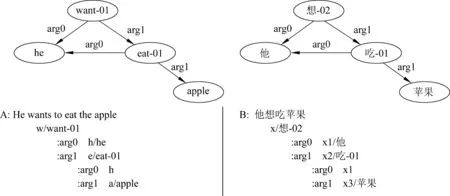
图1 论元共享形成的图结构示例
句A和句B中,每个概念节点都有一个字母编号,关系arg0、arg1等取自PropBank的论元关系[10]。“want(想)”作为句子唯一的根节点,“he”和“他”的编号分别为h和x1,是“want(想)”的arg0(施事),也是“eat(吃)”的arg0(施事)。为了明确谓词及其论元之间的语义关系,AMR标注了谓词在PropBank词典中的具体义项,如谓词“want-01”,表示此处的“want”使用的是其第一个义项的论元框架。
(2)允许重新分析和补充概念,能更完整地表示一个句子的语义。AMR更为灵活之处在于允许根据整体语义来增删概念节点,这样能够弥补传统的句法表示的缺陷。图2中,句C和句D给出了“The dancer has gone”及其汉语翻译“跳舞的走了”的AMR表示。AMR可以根据上下文将“dancer”重新分析为跳舞的arg0(施事)person(人)。中文则可以添加出概念person,作为“跳舞”的arg0。AMR的这个特点,解决了传统的句法表示方法无法应对的省略和词内分析困境,具有较高的语言学价值和应用价值。

图2 概念补充的句子示例
此外,AMR还允许删除一些在意义上冗余的实词,使得句子的基本意义更加简明。比如,“他回答道”可以省略“道”。
AMR在句子语义表示方面的优点,使其一经问世就获得了学界的高度关注,从2014年到2016年,自然语言处理领域的ACL、EMNLP、NAACL等国际顶级会议出现了多篇关于AMR自动分析和应用的论文,2016年的国际语义评测SemEval也进行了英文AMR自动分析的专项评测[6]。相比之下,国内AMR的相关研究较少。比较相近的工作有哈工大的语义依存语料图库[11]和武汉大学的概念依存图库[12]及自动分析技术,两者都采用依存图结构来表示句子的语义,但没有AMR的概念补充、删除和替换的抽象机制未限制为单根,存在多根的情况,其标注体系与规范也尚未公开。北京大学探索汉语“意合语法”的“词库-构式”知识库采用的是生成词汇学和构式语法的理论框架[13],与AMR差别较大。中文《小王子》AMR语料库只有1 000多个句子,没有进行概念对齐[9],对标注体系的介绍也不够完整。因此,本文基于6 000多句的标注实践,着力介绍中文AMR的概念对齐标注方法及标注体系的特色,最后用统计数据说明该语料库的理论与应用价值。
2 融合概念对齐的中文AMR的标注体系
中文AMR沿用了英文AMR的体系和规范,本着与英文AMR保持兼容、兼顾汉语特点、提高标注质量的原则,我们进行了三个方面的改进: ①增加概念对齐信息,并将其融合到语料标注过程中;②增加复句关系的标注;③对中文特殊现象的标注予以具体规定。
2.1 概念对齐
中文AMR语料库的构建之初,使用的是美国南加州大学的AMR标注工具*https://www.isi.edu/cgi-bin/div3/mt/amr-editor/login-gen-v1.7.cgi。。在标注中文语料时发现三个较大的缺点: ①对于一个句子,哪些词已经标注过,哪些词没有标注过,没有任何提示。当一个句子过长时,标注人员特别容易重复标注或者漏标一些词语。②由于需要输入汉字,来回切换中英文输入法较为耗时。③每个概念都分配了一个标签,但除了区分不同的概念外,并没有什么更好的用途,如“p/person”中“/”左边的“p”。而这三个问题,都源于AMR不做概念对齐。如果有了概念和词语的对齐信息,则可以直接利用词语编号代替词语的手工输入,减少中英文切换,同时记录下来哪些词语已经被标注过。
如果用词语在句子中的编号作为概念标签,就可以做到概念对齐。不过,AMR没有做概念对齐,肯定有特殊的考虑。比如,英文词语有形态变化,而概念没有,所以很难直接用词语编号来代表概念,另外,AMR有时将teacher(教师)这样的词内部分析为“person :arg0-of teach”,也使得利用编号进行概念对齐存在较大困难。然而,汉语几乎没有形态变化,在大多情况下,概念和词的形式是一样的。只是汉语中的一些特殊结构和用法,如重叠式(认认真真)、离合词(帮了一个忙)、错别字(窝-我)等,给对齐方案的设计带来了困难。因此,我们提出了以词语编号为基础的概念对齐标注方法,解决以下四个问题: ①做到了概念和词语的对齐;②应对重叠式、离合词等形式变化和错别字问题;③极大减少输入法来回切换,基本用英文输入,减少了汉字输入时间。④使用词语高亮警示,防止标注时漏标词语。
具体方案为双层编号法,即根据每个概念对应的词语的编号和词内的字的编号来做对齐。在一般情况下,只需输入“x+词语编号”即可表示一个概念。表1给出了具体的标注样例,每条输入语句为“支配概念的编号 :语义关系 被支配概念的编号(校正概念)”。

表1 CAMR对英文标注法的对齐改进及输入过程
从概念对齐的标注方法来看,在CAMR图上的每个概念都尽可能地对应到原始句子的词语乃至标点上。离合词“帮忙”用x2_x8表示;疑问词“谁”对应词语编号x1,并标出amr-unknown(表示未知的概念);错别字“窝”的编号为x4,将其校正为“我”;疑问语气interrogative,则对应问号“?”的编号x9。
对于词内分析、分词错误等特殊情况,则使用词内的汉字编号方法解决对齐问题。例如“土地/拥有者”这个例子,“拥有者”作为一个词不容易标出和“土地”的关系,需要进行内部拆分,标注如表2所示。

表2 词内编号拆分标注示例
x2_3表示的是第二个词的第三个字“者”,x2_1_2则表示第二个词的前两个字“拥有”。这种方式比较直观,便于标注人员记忆,也便于后期编程统计处理。即使出现类似x2_1_2_3_4_5_6等较长的情况,录入稍显麻烦,也比用中文输入法打出每个汉字快,而且这种情况出现极少,不会对标注造成影响。
相比于英文AMR的标注方式,CAMR的双层编号法基本不需要输入中文,大量减少了中英文输入法切换,减轻了标注人员的操作量。稍微耗时的则是离合词这样少见的需要输入多个词语编号的情况。对于普通的句子来说,一个词的编号很简单,输入速度快。表3给出了一个大致的估算,如果不计编号合并和拆分的情况,每条关系的输入平均可以节约四次敲击,节约23%的录入时间。即使计入编号合并、拆分、纠正错别字等复杂情况,综合考量,相比英文AMR,人工录入的时间也较少。

表3 一般情况下英文AMR和CAMR标注方法输入一条关系的效率估算
根据双层编号法,我们开发了CAMR专用的人工标注平台CAMR AnnoKit,既做到了概念对齐,又可以校正词形、修改错别字,同时极大减少输入法来回切换,基本用英文输入,减少了汉字输入时间。还借助对齐信息,使用词语高亮警示,防止漏标词语,标注速度和质量有了明显的提高。
2.2 标注体系
CAMR大体上沿用了英文AMR采取的OntoNotes的标注体系,使用了五个核心的语义关系标签、44个非核心语义关系标签以及109个专名概念。
(1)语义关系。核心语义关系是指谓词自身的事件框架的若干语义角色,包括五种: arg0(原型施事)、arg1(原型受事)、arg2(间接宾语、工具等)、arg3(起点、属性等)、arg4(终点)。而英文非核心语义关系则为40种,我们新增了四种。CAMR共使用44种标签来表示一般的非核心语义角色关系,这些标签参考了AMR的标注体系,并根据中文的特点进行了修改和补充,考虑到与AMR的兼容性,CAMR的非核心语义角色关系标签仍然使用英文单词,如表4所示。

表4 中文AMR非核心关系
注: 加*的表示中文AMR新增的四种关系。
下面重点说明一下我们增加的关系标签,tense(时)、aspect(体)、cunit(中文特殊量词)、perspective(方面)。在英文AMR的体系中,语义较虚的时、体等是不予标注的。按这个标准,中文的特殊量词(如个、只等)也被排除在外。但我们觉得句子中的时、体和中文量词的信息相当重要,能够使句义更为完整,值得标注出来,且不会耗费多少时间与精力。perspective则是我们不得不增加的关系类型,如“他在经济上独立了”,“经济”和“独立”的关系,难以用AMR的关系来标注,所以把“经济”作为“独立”的perspective。
(2) 复句关系的表示方法。AMR对于复句关系重视不足,仅有cause、condition、concession等几种语义关系和and、or两个概念。关系和概念纠缠在一起,不利于统计分析和计算应用。我们统一设置了10个概念而非关系来表示小句之间的复句关系(见表5),每个小句由编号基于1的argx来建立关系。因为关系往往只关联两个成分,而像并列、时序、递进复句的小句成分往往多于两个。例如,我们增加的时序(temporal)概念,在处理复句“她吃晚饭后,去跳舞,又逛了夜市”时,将temporal作为根节点,arg1为“她吃晚饭”,arg2为“她去跳舞”,arg3为“她逛夜市”。

表5 CAMR的10种复句概念
(3) 专名体系。在专名方面,AMR给出了一个含有109个专名的体系, 用于专有名词的标注和缺失概念的标注。如“北京”标注为“city :name 北京”,“跳舞的”补充“person”,标注为“person :arg0-of 跳舞”。表6中,每行为一大类,一个大类的代表词放在第一位,其他则为下位小类的标签。如事物的小类不明确,则用大类;如果大类也不明确,则使用顶级标签thing(事物)。
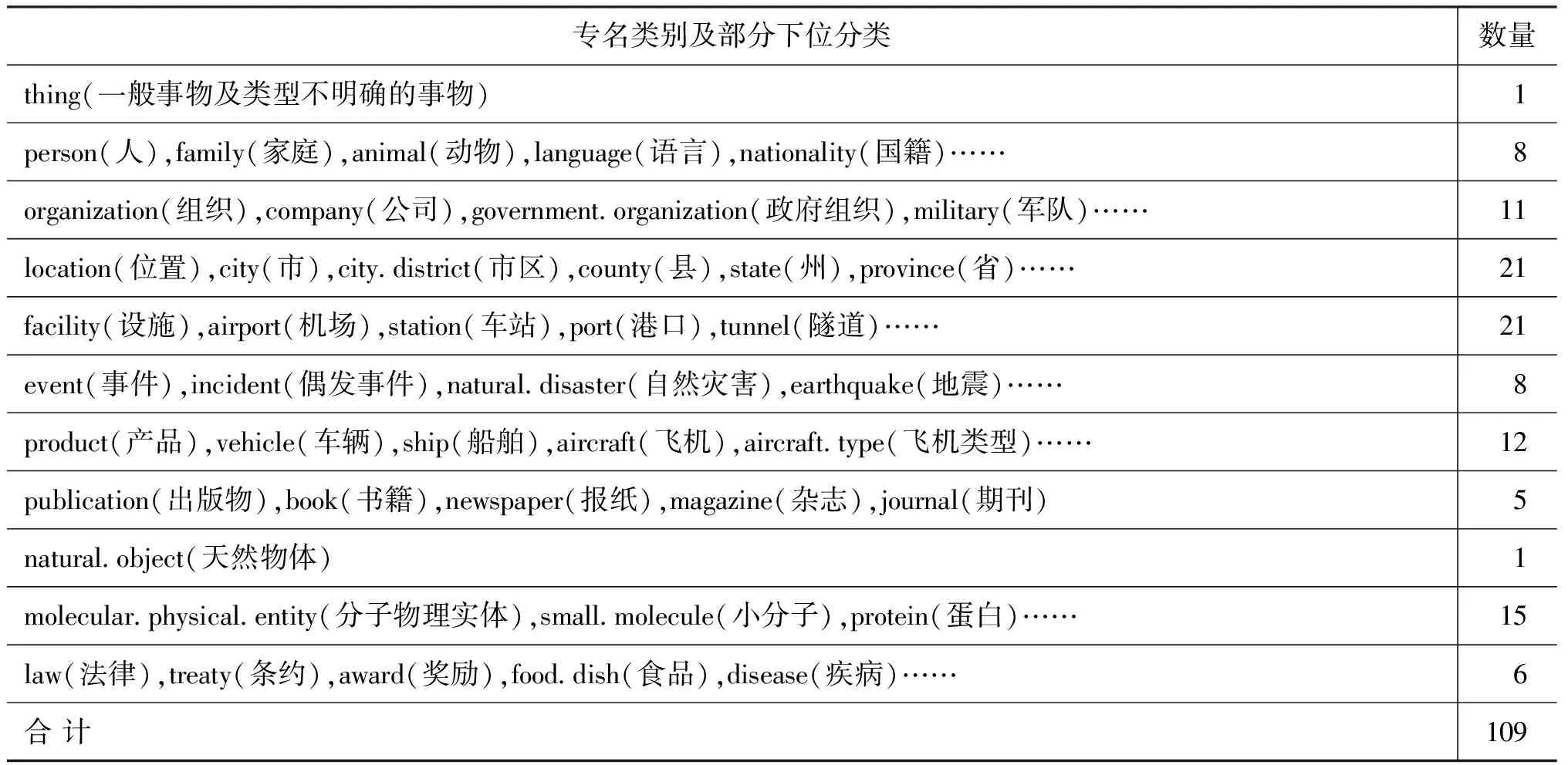
表6 专有名词(Name Entity)类别表
(4) 其他概念和关系。CAMR延续了AMR关于时间、日期、地址、度量衡等具体概念和单位的标注方法,皆参考了AMR标注规范1.2.2版[14]。
2.3 汉语特殊现象的规定
汉语的特殊语言现象的标注方法,依然以英文AMR的标注规范为基础,将汉语特殊结构的语义用概念或语义关系表示出来。限于篇幅,下面仅略微介绍主要的方面,详细的标注规范,请参考已公开的版本*http://www.cs.brandeis.edu/~clp/camr/res/CAMR_GL_v1.2.pdf。。
(1) 首先是增加对汉语特殊量词、时和体的标注,还增加了perspective(方面)这一关系,详见上文。
(2) 对重叠式进行还原,如“看看”还原为“看”,“开开心心”还原为“开心”,“打扫打扫”还原为“打扫”等。如果重叠式有特殊而明确的含义,也予以标注,如“年年”按照AMR处理频率表达“每年”的方式进行标注。
(3) 对汉语离合式一般采取“合”的方式,如“游了一下午泳”处理为“游泳”持续的时间为“一下午”。
(4) 对于连动、兼语结构,一般按照论元共享进行处理,如上文“他想吃苹果”,“想”支配“吃”,且“想”和“吃”共享arg0“他”。
(5) 对动补结构,根据其语义进行标注,如“走不了”处理为“不能走”、“唱哭”处理为“哭”是“唱”的结果。
3 语料分析
3.1 人工标注及基本统计
基于CAMR的对齐一体化标注工具,我们标注了宾州中文树库CTB8.0语料(以下简称CTB)的网络媒体语料6 923句(原语料共7 022句,其中99句存在断句错误或句子意义错乱,未予标注)。在其中随机抽样的500句语料上,双人标注一致性达到0.83的Smatch值[15],与英文AMR基本相当。标注时,谓词所采用的语义角色框架则使用中文谓词库(CPB)的谓词框架词典[16]。该词典是从CPB标注语料中抽取出来的,含有每个谓词在不同义项下的语义角色框架,共收录了24 510个中文谓词(包括动词、形容词等)的26 650个义项的不同语义角色框架。这部词典较好地覆盖了CTB和《小王子》的语料。少量没有覆盖到的谓词,其语义角色则根据标注规范从AMR规定的语义关系中选取。下面给出基本的统计数据和对于图、环、非投影树及较为重要的现象的统计分析。
在6 923个句子中,平均句长为22.36个词,平均概念数为19.24个,回边6 778条,3 360个句子是图,比例为48.53%。平均每句添加2.92个概念,其中0.84个概念为专名添加, 2.08个概念是额外添加的。复句概念属于添加出来的概念节点,我们增设的概念temporal(时序)和progression(递进)允许多个argx的出现,在语料标注中确实体现出了优点。语料中共有206个temporal复句,最多有6个分句;progression 复句251个,最多3个分句,说明本文的标注方法对复句关系的描写能力要比用关系标签更好。
3.2 图结构
文献[9]已经统计了中文《小王子》AMR语料中图结构的比例约为36%。我们统计了英文AMR语料11 875句中图结构的比例,平均为49%。本文新标注的CTB语料则为48.53%,图结构句子的比例与英文AMR语料相当(表7),基本可以说明图结构在中英文语料中的普遍性。
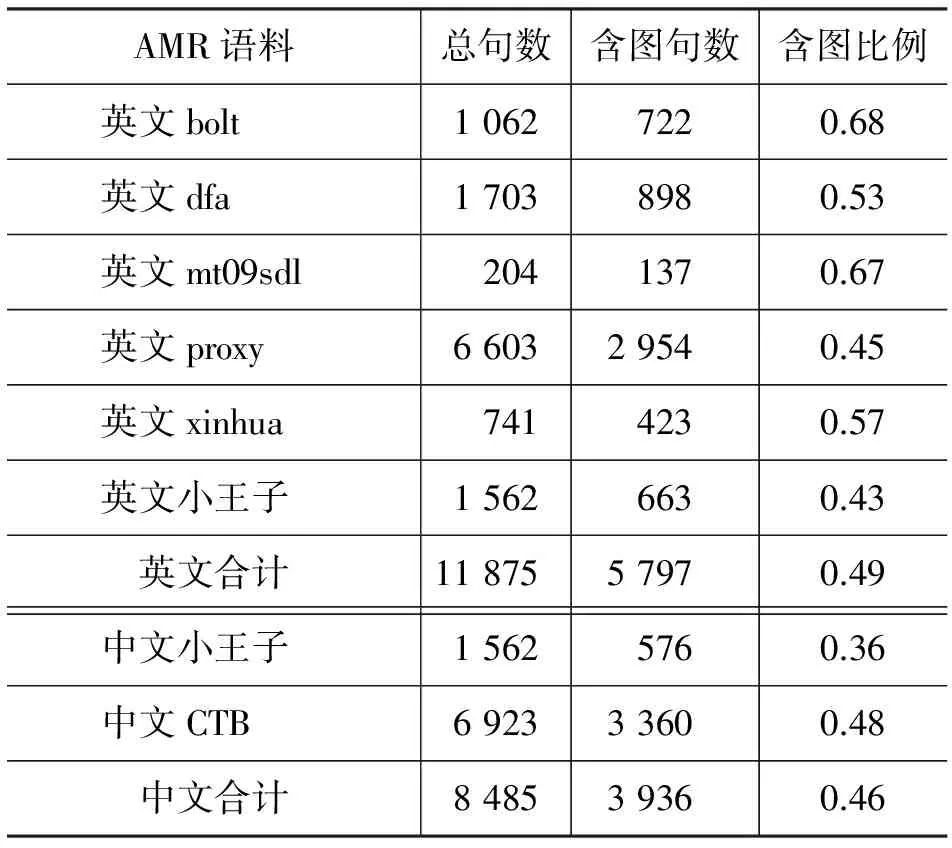
表7 中英文AMR语料含图结构的句子统计
我们观察了图结构在句长上的分布,发现随着句子长度的增加,图结构出现的比例越来越高。图3给出了句长和图结构的分布曲线,5个词以上的句子才开始出现图结构,20个词以上的句子中,图结 构出 现的比例则超过了50%。在超过65个词之后,几乎全是图结构,偶有几个句子不是图,造成了下降的尖峰。这也说明,和一般的句法分析问题相似,长句分析仍然是自动分析算法的难点。
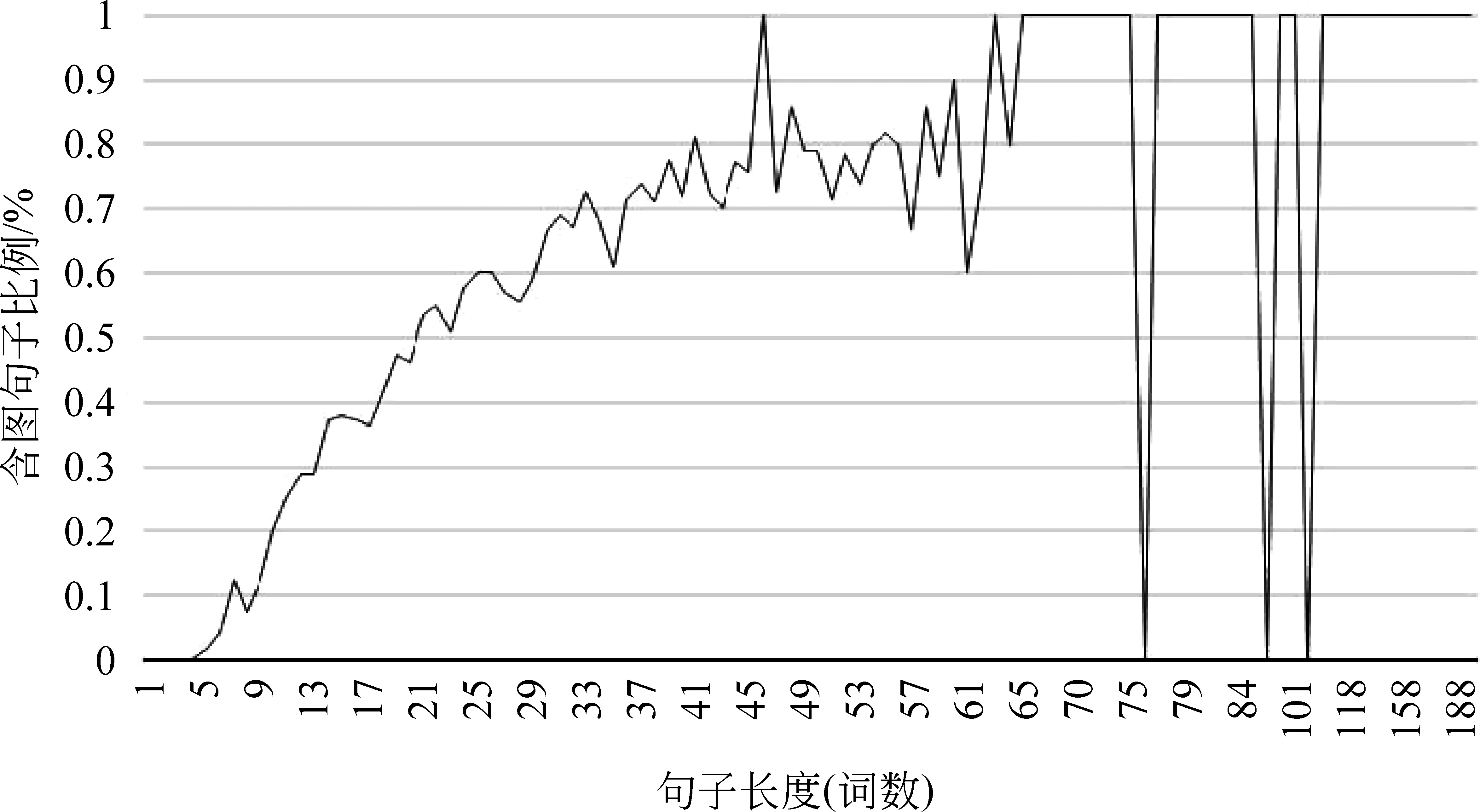
图3 中文CTB语料句子长度与图结构的关系
从回边和概念添加的情况看,自动分析难度也较大。在图结构的句子中,平均每句含2.02条回边。从全部句子来看,回边的数量最小值为0,最大值为14,方差为1.41。而对于添加的概念来说,最小值为0,最大值为26,方差为2.42。这对于机器自动判别哪里增加边和概念来说,确实具有挑战性。从目前英文的自动分析结果来看,添加概念和判定概念之间的关系效果都不理想[6]。不过,语料的统计也可以提供一些有用的信息。根据文献[9]统计中英文《小王子》语料的结果,仅arg0、arg1和arg2三种关系造成的论元共享就分别占到回边总数的85.79%和75.11%。而在CTB语料中,这三种关系造成的论元共享比例为86.43%,说明在自动分析给初始特征时,除了树形结构,也应给出语义角色SRL的自动标注结果。对我们标注的CAMR语料来说,复句关系的判定也最好能够先行给出。
3.3 环
虽然AMR采用有向无环图来表示句子的语义结构,但是在具体标注中,英文语料约0.3%的句子出现了环(cycle)[14],即一个概念节点经过其他节点重新指向了自己。例如表8中的句子,“英雄”是“敢于”的施事arg0,“救”是“敢于”的arg0,而“英雄”又是“救”的施事arg0,形成了一个环。为了避免打印环时形成死循环,我们采用的方式是,对于出现两次以上的概念编号,仅输出其第一次出现时的子树,后续出现则只打印其编号。

表8 带环的句子示例
当然,这也可以说是AMR的体系所导致的,动词短语“敢于救”做定语时,“敢于”在上层,则要使用反关系argx-of形成“英雄-敢于”的关系,加上“英雄-救”的关系,便会形成环。如果不使用反关系,则会导致一个句子出现多个根(“感谢”和“敢于”),丧失了树形主干,破坏了整体结构,所以被AMR舍弃。这种技术上的处理,可以进一步引发语言学上的探讨。比如在依存文法中,一般将“敢于”处理为“救”的状语,也不标注其论元结构。AMR的标注方法则兼顾各个谓词的论元结构,不掩藏问题,能够更好地表示句子的语义结构,却引发了环。我们在设计标注软件时,对于带环的句子在输出时进行了约束处理,使其避免出现死循环的情况。
在CAMR语料中,有76个带环的句子,约占句子总数的1%,这个比例超过了英文AMR语料的0.3%。这些带环的句子,基本上都是由动词短语做定语引发。而CAMR所标注的丰富的论元结构,能够有助于发现和讨论“环”的问题。
3.4 非投影树结构
非投影树是依存语法中存在的特殊现象,指的是依存树上的节点垂直投影到句子上出现交叉的现象。这种现象对于语言学来说,具有较高的研究价值,对于自动分析的算法来说存在挑战性。如图4中的句子“他看到一条狗昨天,瞎的”,在依存树向原句做投影时,就会出现“昨天”和“瞎”的交叉。非投影的句子在英文等其他语料库的建设中几乎是普遍存在的,而在汉语研究和语料库建设中尚未引起重视。
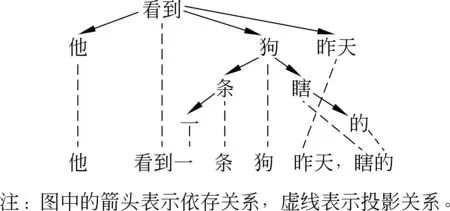
图4 依存树的非投影句示例
非投影结构之前极少被讨论,原因是依存语法在早期严格排斥非投影树,只允许投影树的存在[17-18]。而在欧洲语序自由语言语料标注过程中,学者们感到投影树的限制太强,不利于表示句子的结构,于是提出突破投影树,采用无限制的依存树(unrestricted dependency trees)进行句子结构的描写[19]。之后,多种语言的描写都采用了这种无限制依存树。文献[20]对12种语言的依存树库进行了非投影树的统计,西班牙语最低1.72%,荷兰语最高36.44%,其他语言如日语5.29%、阿拉伯语11.16%、捷克语23.15%、德语27.75%等,均有着较多的非投影树。虽然国际上也有中文依存分析的评测CoNLL06、07和其他语料,但这些依存树库在人工标注时有意识地遵循了投影树原则,或者是从短语结构树库转换而来,所以无法统计出中文语料的非投影树。文献[21]对“中文非投射语义依存现象”进行了讨论,但实际研究的是超越树结构的图结构,并不是严格的非投影树。
在缺乏对齐信息的英文AMR语料上很难进行非投影树的数量统计。而本文的融合对齐信息的CAMR语料,可以做出具体的统计分析。AMR虽然采取了有向无环图结构,但主体架构依然是单根树,加之我们的对齐信息,使得我们能够从语料中获取含有非投影子树的句子。CAMR语料中有 2 238个句子含非投影子树,占句子总数的32.3%。经过初步分析,非投影句主要有两种情况,一种是话题化,如“软环境,我看行”。如果恢复为投影树则为“我看软环境行”。而过去的中文依存树库在标注过程中把话题作为主语,没有很好地表示出句子的语义结构。第二种是源于AMR的体系将情态词作为谓词的父节点。例如,“他可以住这儿”,按AMR的规范,“可以”作为“住”的父节点,就会导致非投影子树。当然,还存在离合词造成的非投影等其他几种情况。

表9 非投影句的CAMR标注示例
英文AMR缺乏对齐信息,难以提取非投影句,中文CAMR融合对齐信息的一体化标注体系能有效地获取非投影句,并易于定位非投影结构。关于非投影结构的细致分析和理论探讨,我们将另文展开。
4 结论与未来工作
针对AMR语料缺乏对齐信息的不足及中文AMR标注过程中存在的问题,本文首先提出了融合概念对齐信息的一体化标注方法和标注平台,解决了中英文输入法频繁切换的问题,增加了错别字纠正和未标注词高亮功能,提高了标注效率。其次,在标注体系上针对中文的语言现象进行了概念和关系的调整。然后,在标注完成的6 923句的CTB语料上,对图、环和论元共享问题进行了统计分析,为自动分析提供了相应的建议。最后,借助中文CAMR的对齐信息,我们得以统计出含中文非投影子树的句子比例,这对于语言学研究和自动分析算法的设计都具有较大价值。
在今后的工作中,我们将继续扩大中文AMR的语料标注规模,进行语言学理论研究和自动分析算法研究。首先,将CTB语料标注完整,并扩展至其他领域语料,发布给学界使用。其次,借助CTB中已有的树形结构和对齐信息,比较AMR和传统句法树的异同与价值。最后,在较大规模的中文AMR语料基础上进行自动分析技术的研究,建立中文AMR自动分析系统。
[1] Katz J J, Fodor J A. The structure of a semantic theory [J]. Language, 1963,39(2), 170-210.
[2] Montague. Universal Grammar[J]. Theoria, 1970, 36: 373-398.
[3] Jackendoff R. Towards an explanatory semantic representation[J]. Linguistic Inquiry, 1976, 7(1): 89-150.
[4] Banarescu L, Bonial C, Cai S, et al. Abstract meaning representation for sembanking [C]//Proceedings of the 7th Linguistic Annotation Workshop, Sophia, Bulgaria, 2013: 178-86.
[5] Bos J. Expressive power of abstract meaning representations[J]. Computational Linguistics, 2016,42(3): 527-535.
[6] May J. SemEval-2016 Task 8: Meaning representation parsing[C]//Proceedings of SemEval-2016, San Diego, California, 2016: 1063-1073.
[7] Pourdamghani N, Gao Y, Hermjakob U, et al. Aligning English strings with abstract meaning representation graphs[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 425-429.
[9] 李斌,闻媛,卜丽君,等. 英汉《小王子》AMR语义图结构的对比分析[J]. 中文信息学报,2017,31(1): 50-57.
[10] Palmer M, Daniel G, Paul K. The Proposition Bank: An Annotated Corpus of Semantic Roles [J]. Computational Linguistics, 2005, Vol.31(1): 71-106.
[11] Wang Y, Guo J, Che W, et al. Transition-based Chinese semantic dependency graph parsing[C]//Proceedings of China National Conference on Chinese Computational Linguistics. Yantai, China. 2016: 12-24.
[12] Chen B, Ji D. Chinese semantic parsing based on dependency graph and feature structure[C]//Proceedings of the International Conference on Electronic14 and Mechanical Engineering and Information Technology, 2011, 4: 1731-1734.
[13] 袁毓林,詹卫东,施春宏. 汉语“词库—构式”互动的语法描写体系及其教学应用[J]. 语言教学与研究,2014(2): 17-25.
[14] Banarescu L, Bonial C, Cai S, et al. Abstract meaning representation (AMR) 1.2.2 specification[DB/OL]. [2015]. https://github. com/amrisi/amr-guidelines/blob/master/amr.md.
[15] Cai S, Knight K. Smatch: an evaluation metric for semantic feature structures[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria, August 4-9, 2013: 748-752.
[16] Xue N, Xia F, Chiou F, et al. The penn Chinese TreeBank: Phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 11(2): 207-238.
[17] Hays D. Dependency theory: A formalism and some observations[J]. Language, 1964,40(4): 511-525.
[18] Percival W K. Refelections on the history of dependency notions in linguistics[J]. Historiographia Linguistica, 1990,17(1-2): 29-47.
[20] Havelka Jirí. Beyond projectivity: multilingual evaluation of constraints and measures on non-projective structures[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL), Prague, Czech Republic,2007: 608-615.
[21] 郑丽娟,邵艳秋,杨尔弘. 中文非投射语义依存现象分析研究[J]. 中文信息学报,2014,28(6): 41-47.
