基于STR的情感挖掘方法研究
——以航空公司质量评价为例*
2017-02-24史伟
史 伟
(湖州师范学院 商学院,浙江 湖州 313000)
基于STR的情感挖掘方法研究
——以航空公司质量评价为例*
史 伟
(湖州师范学院 商学院,浙江 湖州 313000)
情感挖掘现在常用来分析文本,以确定语料是正面的或是负面的。最近,情感挖掘已经扩展到用于解决更深入性的问题,诸如辨别主观命题中的客观成分,确定发表在微博、论坛和新闻中的文本数据集的来源和主题等。企业可以利用观点的极性和情感主题的识别,以获得对情感的驱动者和影响范围更深入的理解。这些信息可以帮助企业提高竞争智能,改进客户服务,获得更好的品牌形象,并且增强竞争力。本文提出了一种新的情感挖掘方法,它可用于检测文本的情感极性和情感主题。该方法包括一个情感主题的识别模型(STR),这个模型是在带有VEM算法的相关主题模型(CTM)的基础上构建的。然后基于微博上航空公司的数据,验证了本文方法的适用性和高效性。最后,基于本文方法输出的结果,计算了三大航空公司的航空质量等级,从而检测了它们的声誉。
情感挖掘;情感主题识别(STR);商务智能;数据科学
社交媒体如微博等的出现正改变和塑造着企业新环境和新竞争格局。消费者、非盈利组织和其它利益方能够在互联网上通过各种渠道表达对企业和它们品牌的意见和看法。人们运用一些特殊的方法和算法来处理这些意见并从中提取有用的信息和模式。其中一种具体的方法就是情感挖掘。情感挖掘包括对文本字符串的分析,以确定语料库是否包含负面或正面的观点或情绪(例如快乐、沮丧、无聊、兴奋或悲伤)。它同时也处理这些问题比如:从主观命题中区分出客观成分,确定一个文档中不同观点的来源,并总结作者在整个文本语料中的判断和态度[1]。情感主题识别(STR)就是试图为每一种情感找出最具代表性的主题。通过STR分析有可能会找到引起正面和负面情感的深层原因[2]。
情感挖掘,也被称为情感分析或意见挖掘,已经发展出一系列算法来识别在线文本的情感倾向(正或负),并确定文本是主观的还是客观的[3](P79-86)[4][5][6]。许多这类算法已经被广泛应用到多领域的情感相关问题中。Pang et al.的研究关注电影评论的情感倾向的确定[3]。其它研究也有关注博客中情感表达的平均水平,其目标是确定基于不同年龄和地域差异导致的幸福程度的总体趋势[7]。然而,很少有研究关注情感主题识别(STR)[8][9][10][11]。
在本研究中,我们提出了一种情感极性检测结合情感主题识别(STR)的新的情感挖掘方法。所提出的方法类似一个智能工具可用来回答情感的驱动力和影响范围等问题。本研究的主要贡献如下:
第一,该方法包括一个情感主题的识别模型(STR),这个模型是在带有VEM算法的相关主题模型(CTM)的基础上构建的 。第二,STR模型可通过计算航空质量排名获得相关信息,进而对航空公司的声誉进行评估[12]。基于微博上顾客对国内三大航空公司(中国国际航空、中国南方航空、中国东方航空)的情感表达,我们提出了对航空质量排名(AQR)评估的方法。本文提出的航空质量排名(AQR)的计算主要基于微博中的主观性文本,而不是通常的顾客调查。第三,开发了一个原型系统,主要通过微博中的案例研究进行该方法的应用。第五,开发了一种匹配观点性微博与主题词库的算法。第四,我们对开发的原型系统进行了评估。
本研究的具体安排如下:第二部分对情感挖掘中的STR做了文献综述。然后,我们在第三部分提出并讨论了本文的方法。第四部分,我们报告了一个实验,并讨论了其结果。本研究的评价阶段放在了第五部分。最后,我们在第六部分总结了本研究,并探讨了未来的研究方向。
一、文献综述
现有的关于情感分类技术的工作主要侧重于对社交媒体和消费者评价中的评论文本进行分类,将文本分为积极的、消极的或中性的类别。最近的研究工作中还有一个重点就是区分主观和客观文本。李光敏等分别从主题识别、主客观性分类、情感极性分类等方面介绍了情感类激素在国内外的研究进展,并列举出情感分析在网络舆情监控方面的应用和今后需深入研究的问题[5]。Pang and Lee提出的基于分类的切割方法,是结合了个人偏好和关系为基础的分类方法。他们提出了一个文本分类过程,就是不论是主观的还是客观的先将文档中的句子进行标注。然后,应用标准的机器学习分类器抽取结果。这个过程可以防止极性分类器考虑不相关的或潜在的误导性文本。接着,采用朴素贝叶斯方法和支持向量机(SVM)方法对主观数据集进行训练,并作为基础的主观性检测器。前者方法得到的分类结果更为准确[4](P271)。Pak and Paroubek运用多项式朴素贝叶斯分类器构建了一种情感分类器,这种分类器是基于贝叶斯定理的。该分类器采用词性(POS)分布估计在不同文本中词性(POS)标注的概率,并用它来计算后验概率。为了提高分类器的准确性,他们去除了不带有强烈情感的或呈现中性的短语或句子[6](P436-439)。
王磊等提出了一个基于主题特征与三支决策理论相融合的多标记情感分类方法,首先采用基于主题的情感识别模型判断句子的多标记情感类别,在此基础上结合三支决策理论,最终实现对文本篇章的多标记情感分类,取得不错的效果[13]。在最近的一项关于情感主题检测的研究中,Lin et al.提出了一种基于隐含狄利克雷分配模型(LDA)的新的概率建模框架称为共同情感主题模型(JST),这个模型能从文本中检测情感并同时确定主题。LDA模型是基于假设文档是包含混合主题的,其中每个主题都是文字的概率分布。JST是一个弱监督模型,它在文档和主题层间增加了额外的一层。这使JST成为一个四层模型,其中情感标注与文档相关联,主题又与情感标注关联,词语同时与情感标注和主题相联系[9]。相似地,Cai et al.开发了一种包括情感和主题检测方法的整体情感挖掘系统。他们的情感检测采用基于统计的方法,而主题检测则是基于逐点互信息和词频分布的方法[8]。Zhao et al.提出了一种分层的生成模型,称为用户情感主题模型(USTM),用于获取带有情感信息的用户主题。USTM提炼带有不同情感趋势的用户主题包括积极的、消极的和中性的。USTM是一种无监督的生成模型,在同时考虑主题和情感的情况下获取用户在主题层次的情感。通过USTM提取的每个主题都有一个情感标签。USTM旨在获得情感提炼的主题用于用户级情感分析的研究。作者通过一个中文数据集(IT类产品)和两个英文数据集(电影评论和安然电子邮件)进行了实验研究。他们发现当通过USTM提取的情感和主题是信息丰富和清晰的,USTM的性能在构建用户兴趣时就表现的更好[10]。
不同于以上这些工作,我们提出的方法不仅获取用户的情感,同时获取隐含于这种情感的主题。通过这种方式,模型提取的每种情感都有一些隐含的主题,并提供了不同消费者情感的总体情况和范围。该方法的目的是解释数据集中每种标注情感的驱动因素,并度量情感的整体宽度。先前关于情感分析的研究工作,首先从文档或社交媒体中抽取主题相关的文本,然后使用分类方法以确定每个特定主题下的文本情感倾向。不同于这些研究工作,我们的模型基于每种情感中的相关主题,给出了情感倾向的根本原因。
二、方 法
图1描述了我们所提出方法的框架。下面的各小节将分别解释这个框架中的不同步骤。

(一)数据准备
微博是一个社交网站,其中心活动就是通过网络或移动设备发布短信息。它主要用来分享信息和描述人们的日常生活,当然也用于信息传播。新浪微博是国内最大的微博网站,我们选择它作为收集数据的来源,并对我们的研究进行分析。我们的数据主要是讨论三家航空公司(中国国际航空、中国南方航空、中国东方航空)的微博评论文本。
收集相关微博文本后,我们就对这些数据进行情感分析。数据准备的过程按如下步骤进行:1.从微博中收集讨论一个特定主题(如东方航空)的相关网络评论。2.删除转发条目、html链接和标记。3.对每条给定的微博文本,去除标点符号、数字、@符号、人名和不必要的空间。
(二)情感词汇
知网2007版情感分析用词汇集作为中文情感关键词字典,该词汇集提供了正面评价词3730个,负面评价词3116个,正面情感词836个,负面情感词1254个[14]。
此外,为了确保从我们模型的算法中获得最大结果,我们应用带有VEM算法的相关主题模型(CTM)从微博中提取词条,并将它们列入词汇库中。这里的词条指的是针对每条航空质量排名(AQR)标准(准点率、拒绝登机、行李处理不当和客户投诉)的主题相关词,它们是从微博中经过过滤和去除停用词获取的。
(三)情感检测
确定情感极性可通过将微博文本与一个预定义的主观词库对比得到。已经有许多算法被应用到情感分类中。这些算法包括决策树[15](P81-93),K-近邻[16],神经网络[17](P317-332)和支持向量机(SVM)[18]。这些算法中,朴素贝叶斯方法是情感分类中比较流行的,因为其计算效率和相对良好的预测性能[19]。先前有关分类的文献就是用的朴素贝叶斯方法[20][21](P503-510)。朴素贝叶斯方法是基于贝叶斯规则的一种简单分类方法。这种方法通过读取一组实例,然后使用贝叶斯定理,以评估所有资格的后验概率。对于每个实例,选择最高的后验概率。朴素贝叶斯假设在给定类上的每个变量的特征值都是条件独立的,这就大大降低了计算成本[22]。因此,我们采用朴素贝叶斯算法进行我们的情感分析,这里应用3.0.2版本的R软件包[23]。之所以选择该软件,因为它是免费并开放源代码的。它还提供了用于定量分析和可视化数据的全面软件包。R还允许不同算法的集成,并提供了灵活的自定义代码,以产生预期的结果。
(四)情感主题识别模型
与情感检测结合使用的STR模型旨在揭示情感型主题中每种情感存在的根本原因。在我们的STR模型中,主题词使用带有VEM算法的相关主题模型(CTM)提取,并按照航空质量排名(AQR)标准(准点率、拒绝登机、行李处理不当和客户投诉)通过半监督方法对主题词进行分类。CTM是隐含狄利克雷分配模型(LDA)的扩展,允许主题间的相关性。在CTM中,主题的比例呈现正态分布。CTM采用另一种更灵活的主题比例分配方法,允许组件之间的协方差结构。CTM提供了一个潜在主题结构的更现实的模型,其中一个潜在主题的存在可能与另一个相关联。CTM支持更多的主题,并提供了一种探索数据的自然方法。用于拟合模型的方法是VEM算法。我们的STR模型采用R包topicmodels,目前提供拟合带有VEM算法的相关主题模型(CTM)的一个接口[11]。在topicmodels中,VEM算法代替了普通的EM算法,因为在E-step中的期望完全似然仍然很难处理[23]。Wainwright and Jordan对变分推理做了很好的介绍[24]。
情感主题匹配算法是基于微博将相关词条匹配给一些特定的情感主题。这种算法主要的思想是找到那些与主题情感相关的词条,其中主题情感是与主题情感词汇相关的。
(五)航空质量排名(AQR)
对航空质量进行排名这里采用较成熟的AQR方法。AQR是通过结合多个性能标准对航空质量进行评价的客观方法。AQR评分计算公式:

(1)
其中OT表示准点率,DB表示拒绝登机,MB表示行李处理不当,CC表示客户投诉(飞行问题,价格比较,预订、票务和登机,票价退款,行李,客户服务,残疾,广告,歧视,动物,其它),这些标准变量如表1所示。标准中的数据都是根据美国运输部提供的月度航空旅行消费报告确定[12],由于航空质量标准的国际一致性,这些数据对于其它国家航空公司同样具有参考价值。权重反映了消费者决策中标准的重要程度,而+/-符号反映了标准对消费者进行航空质量评级的影响方向。权重是根据65家航空公司的行业专家的意见判断而建立的,将消费者判断航空质量的重要性分为0-10不同等级[12]。AQR值越高表明航空公司声誉越好。

表1 AQR的标准、权重和影响方向
三、案例研究与结果
我们的研究主要针对中国的航空公司展开,首先对新浪微博上关于三家航空公司(中国国际航空、中国南方航空、中国东方航空)的评论文本进行情感分类:正面的、中立的或负面的。然后,我们运用提出的STR模型生成各个航空公司的主题。接着各个主题按四种AQR标准(OT、DB、MB和CC)进行分类。为了进行实验,我们使用R软件包开发了一个原型,这个原型支持第三部分所描述的方法。下文“情感检测结果”一节,对所获得的结果进行了讨论。本实验中所使用的微博文本主要包括中国国际航空2892条评论、中国南方航空3292条评论和中国东方航空897条评论。每条微博中都包含了一些关于这些航空公司的评论:正面的、负面的或中立的。根据上述据准备过程对收集的微博文本进行预处理。
(一)情感检测结果
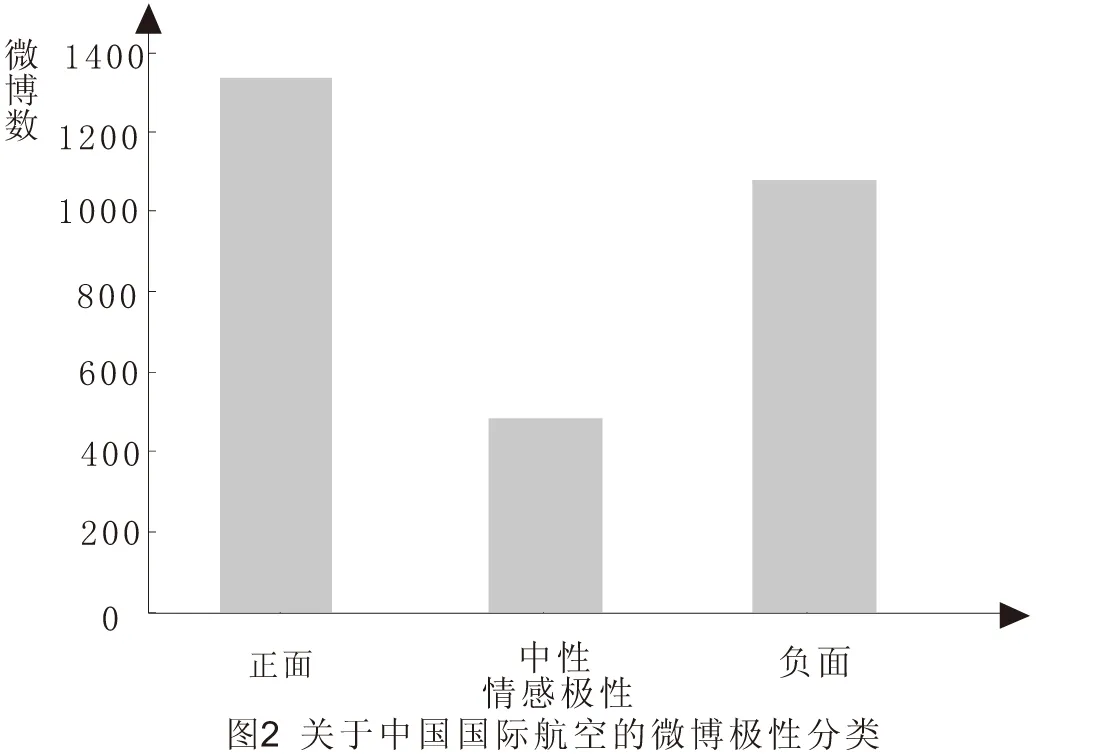
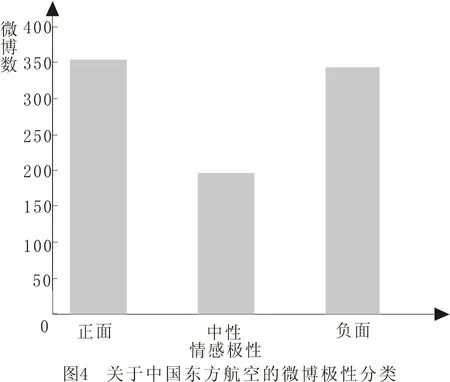
为了分析消费者针对三家航空公司(中国国际航空、中国南方航空、中国东方航空)的情感,我们采用朴素贝叶斯算法。正如前面所提到的,该算法针对主观性数据集表现的更为优秀,本文中该算法准确率达到了88.5%。图2显示了各航空公司的情感极性分类结果。
从图2可以发现,对于中国国际航空正面的微博数要多于负面的微博,各自约为46.1%和37.2%,剩下的就为中立的。中国南方航空大约有45.3%为正面,36.9%为负面,其它的为中立(见图3)。中国东方航空则大约有39.6%为正面,38.5%为负面,剩下的则为中立(见图4)。
(二)情感主题识别结果
如上所述,本研究的STR模型采用带有VEM算法的CTM模型。该模型从航空公司的微博中产生各种词条,这些词条被用来为每类AQR标准构建词汇库。总的来说,本研究构建了四类词汇库:准点率类词汇、拒绝登机类词汇、行李处理不当类词汇和客户投诉类词汇。建立的模型产生了相较于其它STR模型更好的性能表现,因为我们的模型将情感主题间的依赖性和相关性作为一个重要的因素考虑进了情感分析和STR中。STR模型帮助我们在每种AQR标准下正确地将微博数据中词条相关主题进行正负极的分类。

四、评 价
从STR模型中导出的情感主题列表被用来计算三家航空公司(中国国际航空、中国南方航空、中国东方航空)的AQR值。表3显示了每1000条微博得到的AQR计算结果。
如表2所示,我们的方法产生的模拟三家航空公司AQR的结果表明:中国国际航空居第一位,其次是中国南方航空,然后是中国东方航空。这一结果表明,我们基于情感相关主题的情感分析方法在了解每种情感产生的潜在原因上的有效性。这种方法的性能比目前AQR的方法[12]更便于对航空公司声誉的确定。
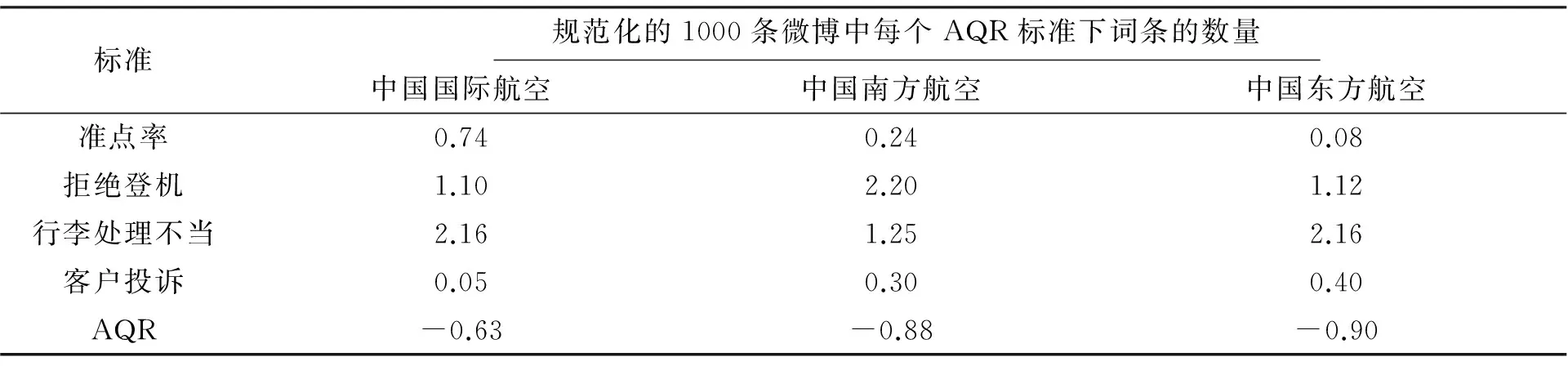
表2 AQR显示使用AQR评分标准得到的各航空公司计算结果
五、结 论
情感挖掘已经从简单的情感极性检测发展到认识这些情感的主题。我们提出的方法同时获得了用户情感和情感主题。以这种方式抽取出含有基本主题的每种情感,并提供了一种全面的不同用户情感的知识和范围。所提出的方法目的是回答数据集中每种情感驱动的相关问题,并检查情感的整体宽度。我们描述了如何运用所提出的STR模型对三家主要的航空公司(中国国际航空、中国南方航空、中国东方航空)进行AQR计算。
我们在有限数量的微博上测试了提出的方法,结果是比较理想的。同时我们也正在不断地收集三家航空公司的微博,并在不久的将来在更大的数据集中重新测试提出的方法。我们也将方法应用到其它领域,以评估所提出的方法。应该注意的是虽然基于情感词汇的方法能检测出基本的情感,但是这种方法有时在检测比喻性表达(如讽刺或挑衅)时是不足的。未来的研究应该试图提出解决这些不足的方法。
[1]PANG B, LEE L. Opinion mining and sentiment analysis [J]. Foundations and trends in information retrieval, 2008(1-2):1-135.
[2]MOSTAFA M M. More than words: Social networks’ text mining for consumer brand sentiments [J]. Expert Systems with Applications, 2013(10):4241-4251.
[3]PANG B, LEE L, VAITHYANATHAN S. Thumbs up? : sentiment classification using machine learning techniques[C]// Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. Association for Computational Linguistics,2002.
[4]PANG B, LEE L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts[C]// Proceedings of the 42nd annual meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004.
[5]李光敏,张行文,张磊,等. 面向网络舆情的评论文本情感分析研究[J].情报杂志,2014(5):157-160.
[6]PAK A, PAROUBEK P. Twitter based system: Using Twitter for disambiguating sentiment ambiguous adjectives[C]// Proceedings of the 5th International Workshop on Semantic Evaluation. Association for Computational Linguistics, 2010.
[7]DODDS P S, DANFORTH C M. Measuring the happiness of large-scale written expression: Songs, blogs, and Presidents [J]. Journal of Happiness Studies, 2010(4):441-456.
[8]CAI K, SPANGLER S, CHEN Y, ZHANG L. Leveraging sentiment analysis for topic detection [J]. Web Intelligence and Agent Systems, 2010(3): 291-302.
[9]LIN C, HE Y, EVERSON R, RUGER S. Weakly supervised joint sentiment-topic detection from text [J]. IEEE Transactions on Knowledge and Data Engineering, 2012(6):1134-1145.
[10]陈永恒,左万利,林耀进. 基于主题种子词的情感分析方法[J].计算机应用,2015(9):2560-2564.Zhao, T., Li, C., Ding, Q., & Li, L. User-sentiment topic model: refining user's topics with sentiment information[C]// Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics. ACM, 2012:10.
[11]BLEI D, LAFFERTY J. Correlated topic models [J]. Advances in neural information processing systems, 2006(18): 147.
[12]BOWEN B D, HEADLEY D E [EB/OL]. Airline Quality Rating 2012. (2016, April ) [2013]. http://www.airlinequalityrating.com/reports/2012aqr.pdf.
[13]王磊,黄河笑,吴兵,等.基于主题与三支决策的文本情感分析[J].计算机科学,2015(6):93-96.
[14]How Net [R/OL]. How Net' s Home Page.. http ://www.keenage.com.
[15] LEWIS D D, RINGUETTE M. A comparison of two learning algorithms for text categorization [C]// Third annual symposium on document analysis and information retrieval,1994.
[16]TAN S. Neighbor-weighted k-nearest neighbor for unbalanced text corpus [J]. Expert Systems with Applications, 2005(4): 667-671.
[17]WIENER E, PEDERSEN J O, WEIGEND A S. A neural network approach to topic spotting [C]// Proceedings of SDAIR-95, 4th annual symposium on document analysis and information retrieval, 1995.
[18]JOACHIMS T.Determining the sentiment of opinions [J].Making large scale SVM learning practical, 1999.
[19]CHEN J, HUANG H, TIAN S, QU Y. Feature selection for text classification with Na?倞ve Bayes[J]. Expert Systems with Applications, 2009(3): 5432-5435.
[20] ZHANG M L,PEA J M, ROBLES V. Feature selection for multi-label naive Bayes classification[J]. Information Sciences, 2009(19):3218-3229.
[21]FRANK E,BOUCKAERT R R. Naive bayes for text classification with unbalanced classes[C]// Knowledge Discovery in Databases: PKDD 2006. Springer Berlin Heidelberg, 2006.
[22]MITCHELL T M. Machine learning and data mining [J]. Communications of the ACM, 1999(11): 30-36.
[23]HORNIK K, GRÜN B. Topic models: An R package for fitting topic models[J]. Journal of Statistical Software, 2011(13):1-30.
[24]WAINWRIGHT M J, JORDAN M I. Graphical models, exponential families, and variational inference [J]. Foundations and Trends in Machine Learning, 2008(1-2): 1-305.
[责任编辑 铁晓娜]
An Approach to Sentiment Mining Based on STR
SHI Wei
(School of Business , Huzhou University , Huzhou 313000,China)
Sentiment mining has been commonly associated with the analysis of a text string to determine whether a corpus is of a negative or positive opinion. Recently, sentiment mining has been extended to address problems such as distinguishing objective from subjective propositions, and determining the sources and topics of different opinions expressed in textual data sets such as web blogs, tweets, message board reviews, and news. Companies can leverage opinion polarity and sentiment topic recognition to gain a deeper understanding of the drivers and the overall scope of sentiments. These insights can advance competitive intelligence, improve customer service, attain better brand image, and enhance competitiveness. This research paper proposes a sentiment mining approach which detects sentiment polarity and sentiment topic from text. The approach includes a sentiment topic recognition model that is based on Correlated Topics Models (CTM) with Variational Expectation-Maximization (VEM) algorithm. We validate the effectiveness and efficiency of this model using airline data from Twitter. We also examine the reputation of three major airlines by computing their Airline Quality Rating (AQR) based on the output from our approach.
sentiment mining; Sentiment Topic Recognition(STR); business intelligence; data science
2016-10-28
浙江省社科规划课题成果“基于微博的大数据挖掘:情感分析的视角”(项目编号:16NDJC079YB);浙江省自然科学基金资助项目“大数据背景下基于情感本体的中文微博挖掘:情感分析的视角 ”(项目编号: LY15G030023 );国家自然科学基金资助项目“在线消费者评论对商家销售业绩的影响: 情感分析的视角”(项目编号:71371144)
史伟,博士,副教授,从事商务智能与情感计算研究。
F562.6
A
1009-1734(2017)01-0051-08
