大数据时代电子政务中XML文档相似性
2017-02-22任永昌
赵 震,任永昌
(1.渤海大学 信息科学与技术学院,辽宁 锦州 121013;2.东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
大数据时代电子政务中XML文档相似性
赵 震1,2,任永昌1
(1.渤海大学 信息科学与技术学院,辽宁 锦州 121013;2.东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
XML作为电子政务应用中的数据交换标准已经被广泛研究。随着大数据时代的到来,对电子政务中XML数据的管理也显得越来越重要。在XML数据的管理中,XML文档的相似性是XML数据集成、XML数据分类的关键。为了研究XML文档的相似性,针对XML文档进行了树形变换,并提取树节点的相应特征,然后分别利用这些特征对节点进行相应的相似性计算,再将得到的相似性利用ELM(超限学习机)算法进行拟合得到最终的节点相似性。在节点相似性的基础上提出了XML文档树的相似性比较算法,从而计算得到XML文档的相似性。实验部分在给出具体的评估指标的基础上,在两个不同的数据集上给出使用文中方法所得到的精确度、召回率、F-measure值以及相应时间的对比情况,通过实验验证了所提方法的性能优势。
XML文档;相似性;特征提取;拟合;数据集成
0 引 言
近年来,随着电子政务的快速发展,XML作为电子政务应用中的数据交换标准[1]越来越受到重视。众多学者在此基础上提出了许多基于XML的电子政务服务模型[2-4]。随着大数据时代的到来,对电子政务中XML数据的管理也显得越来越重要。XML数据的管理包括数据的存储和集成、数据的交换等。在XML数据的管理中,XML数据的相似性是XML数据集成[5]、分类[6]的关键。由于各个部门XML的数据源是独立构建的,不同部门应用中的XML数据结构是有差异的,首先要对这些数据进行识别,找出它们之间的相似性后再进行数据集成或分类。文中工作有利于解决政府各部门各类应用间的信息孤岛问题,对实现部门间协同工作十分重要。
XML数据管理问题是以往各国学者研究的热点[7-10]。提出了一些经典方法,对于解决XML数据管理问题十分重要。在XML文档的相似性研究中,XML文档可以表示为树,两者的相似性问题可以转化为两棵树的匹配问题,目前的解决方案主要有:将需要进行匹配的XML文档转化为树,利用基于树编辑距离的算法计算文档树的相似性[7-8];借助邻接矩阵来计算对应XML文档的相似性[9-10]。
文中在节点相似性的基础上提出了XML文档树的相似性比较算法,从而计算得到XML文档的相似性,并进行了实验验证。
1 XML文档及树形表示
XML作为可扩展标记语言,以半结构化的方式描述各种类型的数据。XML文档中允许使用自定义的标签来更准确地描述数据。下面给出一个XML文档片段,如图1所示。

图1 XML文档实例
XML文档可以用树形结构表示。按照文档对象模型(DOM),一个XML文档也可以表示为一个单根的有序标签树,其中的节点对应文档中的元素和属性。文中只比较树的结构相似性,所以省略元素和属性的值。图1中文档片段对应的树结构如图2所示。
2 树节点的特征相似性
对于XML文档树,树节点是最基本的数据项。一个节点可以是XML文档中的元素或属性。用SimNode(N1,N2)表示来自不同文档树节点N1和N2的相似度。
可以充分利用节点的特征来更精确地获得节点的相似性。标签名、节点深度、数据类型是最常见的用于计算节点相似性的特征。也就是说,利用节点的这些特征值计算得到来自不同文档树节点的相似性。根据不同的特征,可以得到不同的相似度。
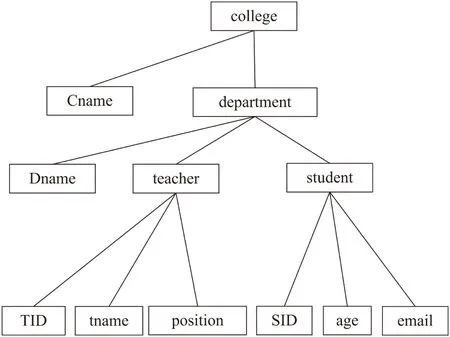
图2 XML文档树实例
(1)标签相似性度量。
标签名(Label)是最重要的节点特征。利用字符串匹配来计算标签相似度。当然字符串匹配的方法有很多,这里采用文献[11]中的方法来计算字符串的相似性。那么,节点的相似性可由式(1)得到:
(1)
其中,editDistance(L1,L2)是字符串L1转换为L2所需要编辑字符的最小代价。
(2)深度相似性度量。
只用节点标签来度量节点相似性是完全不够的,节点的深度是另外一个重要的考量节点相似性的特征。深度相似性需要考虑节点和它们最近共同祖先节点的深度。那么两个节点的相似性可由式(2)得到:
(2)
其中,d1和d2分别是节点N1和N2在相应文档树中的深度;d01和d02分别是N1和N2最近共同祖先N0在相应文档树中的深度。
(3)数据类型相似性度量。
节点的数据类型是另一个用来确定节点相似性的特征。具有相同数据类型的节点具有更大的相似性(SimDataType)。表1说明了不同数据类型节点相似性度量值。

表1 数据类型相似性列表
还有很多用于度量节点相似性的特征,用这些特征计算得到节点特征相似性S1,S2,…,SN。但是每一个单一的特征得来的相似性都不足以表示节点的相似性,因此,有必要将这些相似性拟合在一起,从整体上来考虑这些特征,以得到更合理的节点相似性。一般采用权重的方法得到最终的相似性[12-13],但是这种方法得到的结果误差较大。于是利用基于超限学习机的方法得到拟合的节点相似性。
3 超限学习机
超限学习机[14-15]是由黄广斌教授提出的单隐层前馈神经网络。超限学习机的最大优点是提供了非常快的学习速度,其隐藏层的权重和偏移值可以随机指定,并且输出权重可以通过矩阵计算而无需人工调节。
考虑N个任意样本(xi,ti)∈Rn×m,那么ELM可表示为:
(3)
其中,L为隐藏层节点数目;g()为激活函数;Wi为输入权重向量;βi为输出权重向量;bi为第i个隐藏节点的偏移量。
则存在Wi,βi,bi,使得
(4)
上面的等式可表示为:
Hβ=T
(5)
其中
问题简化为求解线性系统的最小二乘解。则输出权重β为:
β=H†T
(6)
其中,H†= (HTH)-1HT是H的伪逆矩阵。
计算得到输出权重β后,利用它得到:
ot=βh(xt)
(7)
ELM算法描述如下:
算法1:ELM。
输入:训练集D={(xt,yt)},t=1,2,…,T,激活函数g(x);隐藏节点数L;(whereL≤T);
输出:β。
Begin
步骤1:随机指定输入权重Wi和偏移量bi;
步骤2:计算H;
步骤3:计算β=H†T。
Returnβ
End
4 文档树的相似性计算
4.1 树节点的相似性
为了得到文档树的相似性,首先要获得文档树中节点的相似度。前文介绍了依据节点特征得到的特征相似性,这一节介绍如何利用超限学习机得到拟合的节点相似性。
用超限学习机拟合节点的相似性如图3所示。其中,S1,S2,…,Sn是根据节点特征得到的相互独立的相似度量值;S是经过ELM拟合得到的最终节点相似度。

图3 基于ELM的相似性拟合
拟合过程分为训练阶段和预测阶段。这一拟合模型目的是利用训练样本在输入变量(S1,S2,…,Sn)和输出变量(S)间建立一种映射关系。首先随机选择不同文档树中的节点作为训练样本,然后分别计算节点对的特征相似值S1,S2,…,Sn,再通过专家确定这些样本节点的最终相似性S,最后,通过超限学习机算法快速建立预测模型。算法描述如下:
算法2:SimNode。
输入:Node1,Node2;
输出:SimNode。
Begin
步骤1:分别计算特征相似度S1,S2,…,Sn;
步骤2:计算节点相似度SimNode=βH,β由算法1得到。
ReturnSimNode
End
4.2 文档树的相似性
给定文档树D1和D2,计算文档树的相似性。需要得到节点相似性大于给定阈值(θ)的节点数目。用这一数值与全部节点数目的比值来衡量文档中相似节点所占的比重,据此得出文档的相似性。算法3给出了计算文档树的相似性的具体算法。
算法3:SimDocument。
输入:D1,D2;
输出:SimDocument。
Begin
步骤1:遍历D1,D2中每个节点,nodei∈D1,nodej∈D2;
步骤2:计算每个节点对的相似度SimNode(nodei,nodej);
步骤3:如果SimNode(nodei,nodej)两棵树中相似节点对相似度大于阈值θ,则相似节点数目NumSimNode=NumSimNode+1;
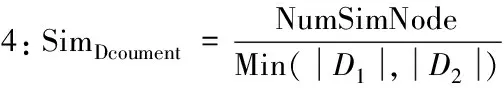
ReturnSimDocument
End
5 实 验
下面通过实验进一步评估文中提出的XML文档相似性计算方法的性能。评估相似性比较的性能主要考虑两方面:有效性和效率。
评估有效性主要有两个指标:精确度和召回率。下面简单介绍它们的定义。
精确度表示正确匹配的程度,召回率表示匹配的完整性,分别为:
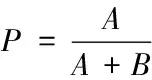
(8)

(9)
其中,A为正确匹配的XML文档数量;B为错误匹配的XML文档数量;C为没有被识别出的正确匹配的XML文档数量。
两者的调和平均值可以用F-measure来表示。
(10)
为保证数据的真实性,选用的数据集为DBLP和SigmodRecord。同时,需要将数据集分割为0.1M到2M的数据,以便对比算法响应时间。
图4显示了在DBLP和SigmodRecord数据集上使用文中方法所得到的精确度、召回率、F-measure值的对比情况。
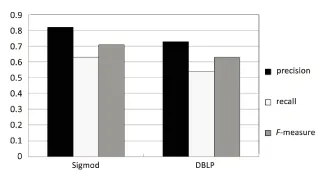
图4 DBLP和SigmodRecord数据集匹配有效性对比
从图中可以看出,SigmodRecord数据集上的有效性要优于DBLP数据集,这是因为DBLP数据集的结构比SigmodRecord复杂。
图5显示了在DBLP和SigmodRecord数据集上执行文中算法所得到的响应时间的对比情况。

图5 DBLP和SigmodRecord数据集响应时间对比
从图中可以看出,SigmodRecord数据集上的响应时间远小于DBLP数据集,由此可以看出DBLP数据集结构比较复杂。
6 结束语
在大数据的背景下,研究了电子政务中XML数据的相似性。首先将XML文档转换为对应的XML文档树,然后根据抽取的XML树节点的特征,计算对应的特征相似性,再使用基于ELM的算法得到XML节点的相似性,并给出了XML文档树的相似性比较算法,从而得到XML文档的相似性。通过实验验证了所提方法的正确性和有效性。
[1] 赵慧勤,赵慧玲.电子政务数据交换标准—XML语言[J].山西大同大学学报:社会科学版,2003,17(3):76-78.
[2] 钟福金,辜丽川,张友华.基于语义Web服务的电子政务模型研究[J].微电子学与计算机,2010,27(3):144-147.
[3] 陈 桦,麻风梅,韩艳艳.基于XML的异构数据集成模式的研究[J].微电子学与计算机,2009,26(1):137-139.
[4] 李冬睿.基于XML与Web Service的电子政务数据交换模型的设计与实现[D].桂林:广西师范大学,2008.
[5] Thomo A,Venkatesh S.Rewriting of visibly pushdown languages for xml data integration[C]//Proceedings of the 17th ACM conference on information and knowledge management.Napa Valley,California,USA:ACM,2008:521-530.
[6] Algergawy A,Mesiti M,Nayak R,et al.XML data clustering:an overview[J].ACM Computing Surveys,2011,43(4):25-41.
[7] Nierman A,Jagadish H V.Evaluating structural similarity in XML documents[C]//Proceedings of the ACM SIGMOD international workshop on the web and databases.[s.l.]:ACM,2002:61-66.
[8] Tekli J,Chbeir R.A novel XML document structure comparison framework based-on sub-tree commonalities and label semantics[J].Journal of Web Semantics,2012,11(3):14-40.
[9] Zhang X,Yang T,Fan B Q,et al.A novel method for measuring structure and semantic similarity of XML documents based on extended adjacency matrix[C]//Proceedings of international conference on service science.[s.l.]:[s.n.],2012:1452-1461.
[10] Chowdhury I J,Nayak R.A novel method for finding similarities between unordered trees using matrix data model[M].Berlin:Springer,2013:421-430.
[11] Lin Dekang.An information-theoretic definition of similarity[C]//Proceedings of the international conference on machine learning.Madison,Wisconsin,USA:[s.n.],1998:296-304.
[12] Algergawy A,Nayak R,Saake G.Element similarity measures in XML schema matching[J].Information Sciences,2010,180(24):4975-4998.
[13] Tekli J,Chbeir R.Minimizing user effort in XML grammar matching[J].Information Sciences,2012,210(10):1-40.
[14] Huang Guangbin,Zhu Qinyu,Siew C K.Extreme learning machine:theory and applications[J].Neurocomputing,2006,70(1-3):489-501.
[15] Huang Guangbin.An insight into extreme learning machines:random neurons,random features and kernels[J].Cognitive Computation,2014,6(3):376-390.
Similarity of XML Documents in E-government in Era of Big Data
ZHAO Zhen1,2,REN Yong-chang1
(1.College of Information Science and Technology,Bohai University,Jinzhou 121013,China; 2.School of Computer Science and Engineering,Northeastern University,Shenyang 110819,China)
XML has been widely studied as the standard of data exchange in e-government applications.With the arrival of the era of big data,the management of XML data in e-government is also becoming more and more important.In the management of XML data,the similarity of XML documents is the key of XML data integration and XML data classification.In order to study the XML document similarity,the XML document are transformed into tree,extracting the corresponding characteristics of the nodes of the tree,and then using these characteristics to calculate the similarity of nodes,and then the final node similarity can be obtained by the ELM(Extreme Learning Machine) algorithm.Based on the similarity of nodes,the algorithm of similarity comparison of the XML document tree is given,which can obtain the similarity of XML documents.Based on the given specific evaluation indexes,the accuracy,recall,F-measurevaluesandthecorrespondingtimeareobtainedthroughexperimentsintwodifferentdatasetsusingthemethodproposed.Theperformanceadvantagesoftheproposedmethodareverifiedbyexperiments.
XML documents;similarity;feature extracting;synthesizing;data integration
2016-03-28
2016-07-05
时间:2017-01-04
教育部人文社会科学研究青年基金项目(15YJC870028);辽宁省自然科学基金(2015020009);辽宁省哲学社会科学规划基金项目(L15BTQ002);辽宁省社科联2015年度辽宁经济社会发展立项课题(2015lslktglx-01)
赵 震(1977-),男,博士研究生,讲师,CCF会员,研究方向为人工智能与语义Web;任永昌,博士,教授,研究方向为云计算与软件项目管理。
http://www.cnki.net/kcms/detail/61.1450.TP.20170104.1039.076.html
TP
A
1673-629X(2017)01-0186-04
10.3969/j.issn.1673-629X.2017.01.042
