tsk-shell:一种话题敏感的高影响力传播者发现算法
2017-02-22笱程成程学旗
笱程成 杜 攀 贺 敏,3 刘 悦 程学旗
1(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190)2(中国科学院大学 北京 100049)3 (国家计算机网络与信息安全管理中心 北京 100029) (gouchengcheng@gmail.com)
tsk-shell:一种话题敏感的高影响力传播者发现算法
笱程成1,2杜 攀1贺 敏1,2,3刘 悦1程学旗1
1(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190)2(中国科学院大学 北京 100049)3(国家计算机网络与信息安全管理中心 北京 100029) (gouchengcheng@gmail.com)
在社交网络中,挖掘高影响力的信息传播者,对微博服务中内容的流行度分析和预测是非常有价值的任务.与众多相关方法相比,k-shell分解(k-core)方法因其简洁高效、平均性能好的特点吸引了越来越多的研究人员的兴趣.但是,目前k-shell方法着重考虑节点在网络中的位置因素,而忽略了话题在信息传播中的影响.因此,为了利用用户历史数据中蕴含的话题对消息的传播概率进行细粒度的建模,提出了一种话题敏感的k-shell(topic-sensitivek-shell, tsk-shell)分解算法.在真实Twitter数据集上实验表明,在发现topk高影响力传播者任务中,tsk-shell比k-shell的性能平均提高了约40%,证明了tsk-shell算法的有效性.
高影响力传播者;k-shell分解;社交网络;信息扩散;传播概率;微博
发现高影响力的传播者在各种应用场景中越来越重要,如社交推荐、病毒式营销、流行度预测、品牌管理等.针对该任务,学术界目前提出了多种方法[1-3],比如基于PageRank[4]的方法[1]和基于k-shell分解的方法[2],其中,基于k-shell分解[2]的方法被证明是目前最有效的方法[3]. 从信息传播的角度看,消息的爆发或流行主要是由2个因素造成的:一方面,网络结构对消息的传播具有较大的影响,如果一个消息传播过程中的转发者有较多的朋友,则该消息就能有机会被更多的人看见,就越能获得更大的传播机会;另一方面,消息本身的内容对消息的传播有重要影响,如具有吸引力和爆炸性话题的消息具有较大的概率被广泛地传播.
一般来讲,对于不同的话题或领域,各个用户感兴趣的程度不同,因而,同一用户在不同话题或领域中的传播影响力是随着话题或领域的不同而改变的[5-8],例如,Kevin Durant可能是NBA全明星赛中是最有影响力的传播者,但肯定与Geoffrey Hinton在机器学习领域的影响力没办法相比.在众多传统的用户影响力分析模型中,k-shell及其变种以网络拓扑分析为基础,能够有效地衡量网络传播过程中的用户影响力,但基于k-shell分解的方法及其扩展往往只关注拓扑结构对传播能力的影响,而实际应用场景往往更加复杂.首先,不同用户之间交互的频度明显不同,有亲疏之别;其次,用户交互的强度也会随着内容或领域的变化而改变,如某些粉丝只评论和转发某类感兴趣的话题,而不理睬其他的话题.针对前者,文献[9]提出了加权的k-shell分解算法,在金融、贸易等网络中进行的实验表明,考虑权重信息的k-shell分解要好于原始的k-shell分解,但是加权的k-shell分解算法仍然侧重于拓扑分析,并没有充分考虑信息在网络上传播的内容因素,比如不同的话题在不同的边上产生传播的可能性也不尽相同,仅靠拓扑信息难于捕捉话题变迁在网络传播过程中对于传播者影响力的影响.
本文提出了话题敏感的k-shell(topic-sensitivek-shell, tsk-shell)分解算法,在发挥k-shell基于拓扑的传播影响力分析优势的同时引入基于内容的传播影响力分析,即分析用户及其好友在不同话题上的转发行为特征,更加真实地建模社交网络上用户之间的传播影响机制,从而更加有效地发现社交网络上的高影响力的传播用户,为社交推荐、病毒式营销、流行度预测、品牌管理、甚至突发性预测等诸多应用提供有效支持.tsk-shell算法与传统加权的k-shell分解算法的区别在于,传统加权k-shell算法在k-shell算法的基础上,通过量化拓扑结构属性赋予网络边权[9],其权重的计算无法与传播的内容关联,不会随着传播内容的变化而变化;而tsk-shell则试图将网络拓扑结构和网络传播内容2种异质关联的信息有效地融合起来,从而将经典k-shell算法扩展出内容分析的能力,使其能够融合网络拓扑结构和网络传播内容2种常用却异质的信息,进一步提升其在社交网络传播者影响力分析上的优势.
1 相关工作
总的来讲,社交网络中发现高影响力传播者的研究可以大致分成3类:1)基于网络拓扑的方法;2)拓扑和用户行为联合建模的方法;3)拓扑和信息内容联合建模的方法.
基于网络拓扑的方法纯粹以网络结构为用户传播影响力的分析基础,其代表性方法主要包括度中心性、介数中心性(betweenness centrality)、k-shell[2]分解方法等.度中心性是一种比较直接的方法,认为网络中用户节点的度越大,则该用户影响力越高;介数中心性是指网络中所有最短路径中经过该点的边的比例,比例越高,节点影响力越大;k-shell分解方法描述了节点在网络中的位置信息,越靠近网络核心的节点影响力越高.文献[2]证明在复杂网络中,在只有一个传播源点的前提条件下,最有效的传播者不是度中心性最大的节点,也不是介数中心性指示的位于网络中心的节点,而是由k-shell分解算法得到的位于网络核心的节点.k-shell算法时间复杂度为O(N+E)[10],N和E分别表示节点数和边数,由于时间复杂度低,其经常被应用于大规模网络的分析.但是,k-shell算法会造成多个节点被分配到同一个索引值ks,而属于同一ks索引值的节点无法区分其传播能力.为了克服上述弱点,Zeng等人[11]提出了基于混合度(mixed degree decomposition, MDD)的k-shell分解算法,MDD在计算节点权重时同时考虑了剩余边和删除边,达到了更加细致的划分效果.文献[9]同时考虑了网络中节点度和连边权重的影响,提出了加权k-shell分解方法,该方法可以更准确地估计一个节点的重要程度.上述基于网络拓扑的方法,优点是直观、速度快,但缺少对网络用户行为或网络信息内容的建模能力,因而对网络上信息传播过程中用户真实的传播影响力的分析能力还有进一步提升的空间.
联合用户行为和拓扑建模的方法中,代表性方法是IP[12](influence and passivity). IP提出了与HITS类似的算法来迭代计算用户的影响力和被动性(passivity),其中一个用户的影响力打分取决于他影响的用户个数以及这些用户的被动性打分.一个用户的被动性打分,取决于他试图影响他但被他拒绝的用户个数及其影响力打分.容易看出IP算法中计算影响力和被动性的方式,与HITS算法中迭代计算网络节点hub值和authority值的方式类似.该类方法的先进性在于它不但充分利用网络拓扑结构,而且能够利用用户的行为特征帮助提升传播影响力建模的准确性.但同样地,该方法仍然没有深入到传播信息的内容层面进行分析,无法区分用户在不同话题上的传播影响力大小.此外,相较k-shell算法而言,该算法的时间复杂度也比较高.
信息内容和网络拓扑联合建模的方法中,具有代表性的是TwitterRank[1],TAP(topical affinity propagation)[13]等.TwitterRank在PageRank算法的转移概率中加入了话题和用户活跃程度来度量用户的兴趣.TAP提出了话题因子图(topical factor graph, TFG)模型来建模网络用户在不同话题下的影响关系,在共同作者网络、引文关系网络和电影-导演-演员-编剧关系网络定量和定性分析上都取得了不错的计算效果,其算法若采用传统的子集和法求解,计算复杂度高,无法适应大规模数据,针对该问题,作者又提出了一个并行的分布式求解算法.此外,作者实验的3个网络都很容易获得规范的元信息数据,比如论文话题类别、电影类别等,而在Twitter、微博等社交媒体网络上常常无法直接获得这类关键信息.
综上所述,传统的发现高影响力传播者的算法,要么脱离话题建模用户的社会影响力[2,9,11-12];要么认为话题影响力是固定的[1,13],无法跟随内容的变化而改变,消弱了实践应用价值.而k-shell算法具有简单、直观、高效等特点,因此,本文在考虑网络拓扑结构的基础上,向k-shell引入话题和用户交互行为的作用,提出了tsk-shell算法,以期在保持其简洁高效优势的同时,扩展出其利用社交网络中内容话题的能力,提升其建模社交网络用户传播影响力建模的有效性.
2 话题敏感的k-Shell分解
传统k-shell分解方法,通过递归的方式依次删除网络中度最小的节点,将网络划分成不同的子结构.对属于不同子结构的节点赋予一个k-shell索引值,ks反映了节点在网络中的位置,ks越大,节点越靠近网络中心,其传播影响力被认为越大,反之,ks越小,节点离网络中心越远,其传播影响力被认为越小.社交网络中传播者的影响力不但与拓扑结构有关,而且是随着不同的话题发生变化的,为了区分不同话题下的用户传播行为,我们需要在考虑拓扑影响的同时,建模话题对传播行为的影响.直观的想法,是将用户之间基于话题的转发关系,同k-shell框架下节点“度”的概念关联起来.借鉴Garas等人[9]提出的方法,融合拓扑结构和话题影响力权重的节点度计算方式,如式(1)所示:
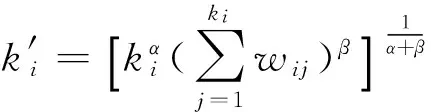
(1)

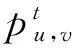

(2)
用户的话题影响力被转化为社交网络中关系的权重,然后,加权的k-shell分解算法被用来寻找消息集合D所代表话题中最有影响力的传播者.tsk-shell首次将话题影响力和k-shell分解方法结合起来寻找社交网络中话题相关的高影响力传播者.
2.1 话题加权的社交网络结构
tsk-shell算法的关键在于如何根据Twitter网络中的历史数据和网络结构生成一个话题敏感的加权网络.算法考虑了以下3种因素:1)用户产生内容,用户的兴趣反映了其对话题的偏好程度,而用户的历史消息(包括原创和转发)可以用来推断用户在不同话题上的兴趣分布;2)用户的关注关系,由于Twitter网络中的同质性[1]的现象,关注关系表示了用户之间兴趣的相似性,可以在一定程度上反映用户之间的话题影响力,但是这种影响力是一般意义上的、定性的,不能够精确度量用户在某个话题上的影响力;3)用户的转发行为,转发行为是用户对某个话题感兴趣的重要特征,也是网络中信息传播的动力.
基于上述观察,Twitter网络中的用户产生内容、关注网络和用户转发行为,被联合用来建模两两用户之间的话题传播影响力.对于社交网络中存在连接关系的任意2个用户,用户之间的影响力被定义为某个话题分布下的条件概率.在Twitter网络中,由于关注关系是有向的,影响力也是有方向的,即影响力的方向是从被关注的用户指向关注他的用户.为了描述方便,预先定义一组符号,如表1所示:

Table 1 The Symbol Table表1 符号表

在考虑话题的情况下,转发的消息被映射到一个主题向量空间中,t,Ru v,V三个变量的关系表示如图1所示:
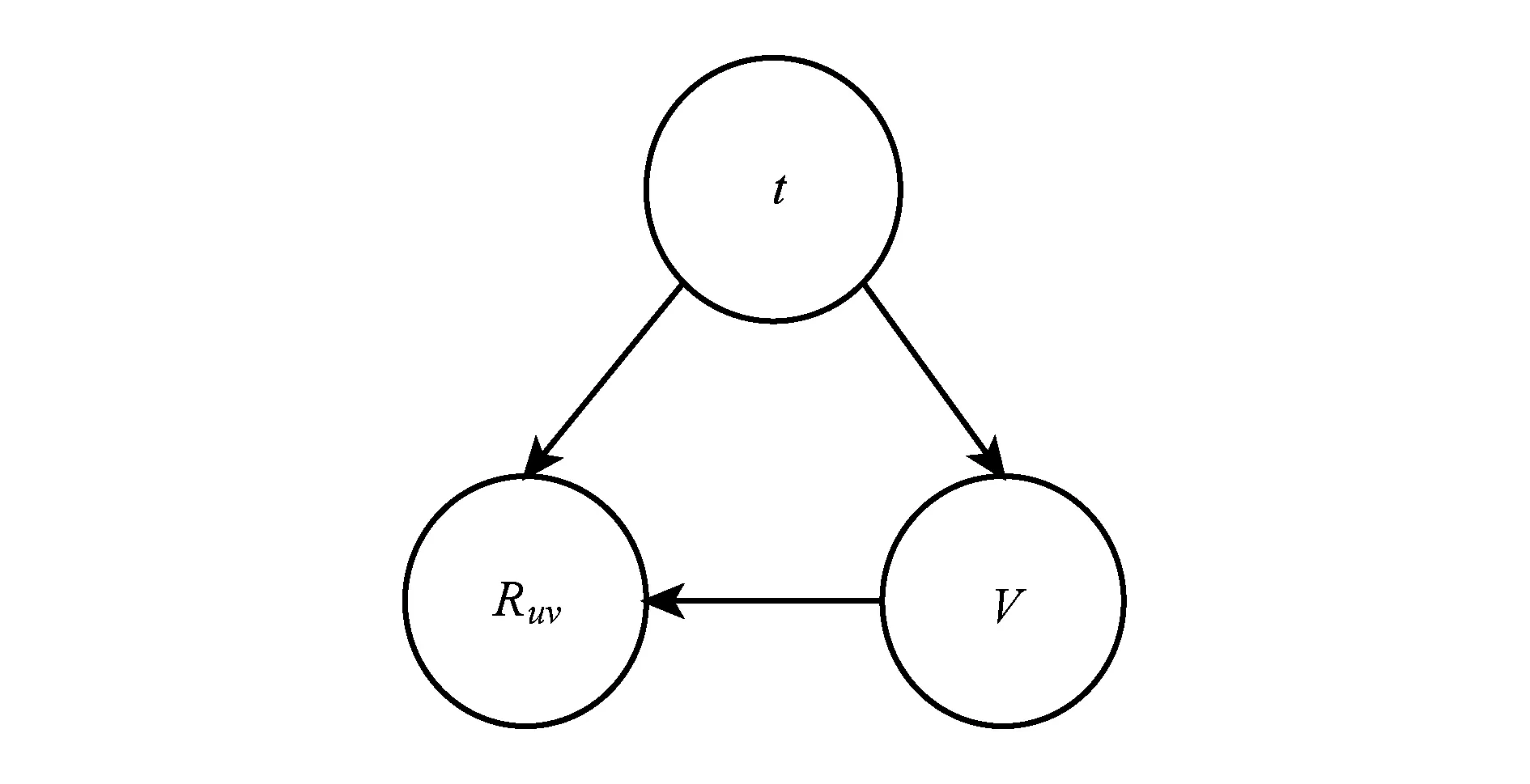
Fig. 1 Graphical representation of topical influence图1 话题影响力的概率图表示
用户v对u在话题t下的影响力可以定义为条件概率P(Ru v|Vt),即对于主题t,在事件V已经发生的条件下事件发生的概率.由于P(Ru v|Vt)不便于直接求解,通过贝叶斯公式得到式(3):
(3)
P(t|V) 表示用户v发布的消息中主题t出现的概率,可以用式(4)表示:
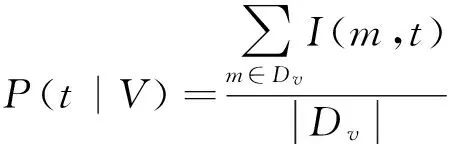
(4)
其中,I(m,t)为指示函数,若消息m的主题为t,则I(m,t)=1,否则I(m,t)=0.P(Ru vt|V)表示在Dv中被用户u转发且主题为t的概率,可以通过式(5)计算:

(5)
综合式(3)~(5),可得出式(6):
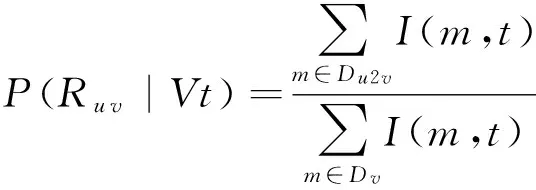
(6)
事实上,一条消息可能包含不止一个主题,为了更加细粒度地划分话题,我们以词为单位进行统计,设P(t|m)表示消息m中主题为t的词出现的概率,则式(6)可以进一步表示为式(7):
在实际应用中,话题常常由多条描述相关内容的消息集合组成,对于某个给定的待预测的消息集合D,按照式(2),在消息集合D上,用户v对u的话题影响力可以由式(8)计算:

(8)
最后将P(Ru v|VD)作为社交网络中关系的权重,执行带权重的k-shell的分解得到消息集合D代表的话题下的高影响力传播者.式(7)中的P(t|m),通过LDA[14]( latent Dirichlet allocation)主题模型对用户历史消息进行估计得到,式(8)中的P(t|D)通过训练好的LDA模型推断得到.
2.2 tsk-shell算法
按照2.1节描述,tsk-shell算法的完整过程如算法1所示:
算法1.tsk-shell算法.
训练阶段:
1) 由LDA模型得到每个消息的主题分布P(t|m);
2) 由式(7)计算社交网络中相连用户之间主题相关的转发概率P(Ru v|Vt).
预测阶段:
1) 由LDA推断出待预测消息集合的主题分布,即话题;
2) 利用式(8)计算该话题下,网络中相连用户之间的转发概率P(Ru v|VD);
3) 结合式(1)的权重计算,迭代计算加权网络中每个节点的k-shell索引值;
4) 按照k-shell索引值估计该话题下用户传播影响力的大小.
算法1的过程分为训练和预测2个阶段,在训练阶段,将社交网络中的连接关系转化为主题相关的转发概率图;在预测阶段,首先推断出待预测的消息集合话题的主题分布,接着计算出话题加权的社交网络,最后采用加权的k-shell分解方法计算出每个用户的k-shell索引值,作为用户话题相关的传播影响力的估计.
3 实验评估
在本节中,我们通过真实的Twitter网络中传播实例对算法的效果进行了验证,我们首先给出了tsk-shell关于几个基准方法,如PageRank、度、k-shell在效果上的定量对比;然后为了给出一个直观认识,我们又给出了tsk-shell和传统k-shell方法在医改话题上的定性对比结果.
3.1 数据集
原始数据集为2009-06-01—2009-12-31采集的Twitter数据集,其中包括4.76亿条tweets消息[15].
实验抽取2009年6月和7月的数据作为训练数据,在经过分词去除高频和低频词,得到历史tweets数(包括发布和转发)大于等于3的有效用户数3 200 521个.在有效用户的tweets中,从包含转发关系,即含有RT @name和via @name字符串模式的tweets中,进一步提取用户间的转发关系,共发现存在有效转发消息的用户对3 352 337个.将有效用户的历史数据用LDA模型进行训练,设主题个数k=100,得到每个消息的主题分布,然后,通过式(7)计算每个有效用户对在各个主题下的影响力权重.
实验抽取2009年8月的数据作为预测数据.利用主题模型选取其中流行的3个话题预测,即甲型H1N1流感疫情、奥巴马医保改革和迈克尔·杰克逊逝世作为预测数据.利用每个话题的高频关键词抽取相应的转发tweets和参与的用户,利用文献[16]采集的社交关系构建用户的关注关系网络,利用式(8)计算每个特定话题下的关系权重.在执行加权的k-shell分解算法时,式(1)中的参数取α=1,β=1.
3.2 评估标准
在社交网络的信息传播中,信息传播过程可能从少数的几个点开始,沿着网络的社交结构进行传播;此外,用户也可能会通过搜索引擎或外部的环境获取并发布信息,这造成了影响信息传播因素的多样性和分析的困难.在本实验中,为了简化问题,便于分析,采用了文献[3]中的方法,即假设信息的传播只发生在封闭的社交网络中,并沿着可见的社交网络结构进行,任一用户在某一话题传播过程中的影响力定义为,在该话题传播结束后经过N跳影响的用户总数,实验中取N=2.该方法的优点是,既考虑了用户对直接邻居的影响,又考虑了用户对间接邻居的影响,即用户的直接影响力和间接影响力[17].图2表示在Twitter网络上的信息传播示意图,节点表示用户,边表示关注关系,如节点A和节点C之间的有向边表示C关注了A.信息传播的过程如下:最开始用户A发表了一条消息,A的粉丝E,C,F转发了这则消息,接着C的粉丝B、F的粉丝、H和J转发这条消息,在H的粉丝I转发了该消息后传播结束.最终,节点A影响的范围为集合SA={B,C,E,F,H,J},节点F最终影响的范围为集合SB={H,I,J}.用户节点的影响力可以定义为最终影响范围的集合大小,即A的影响力为|SA|,B的影响力为|SB|.通过该方法,可以在话题传播结束后,计算出每个参与传播用户的真实影响力大小.在实验中,待预测的话题中涉及用户的真实传播影响力由此计算得出.
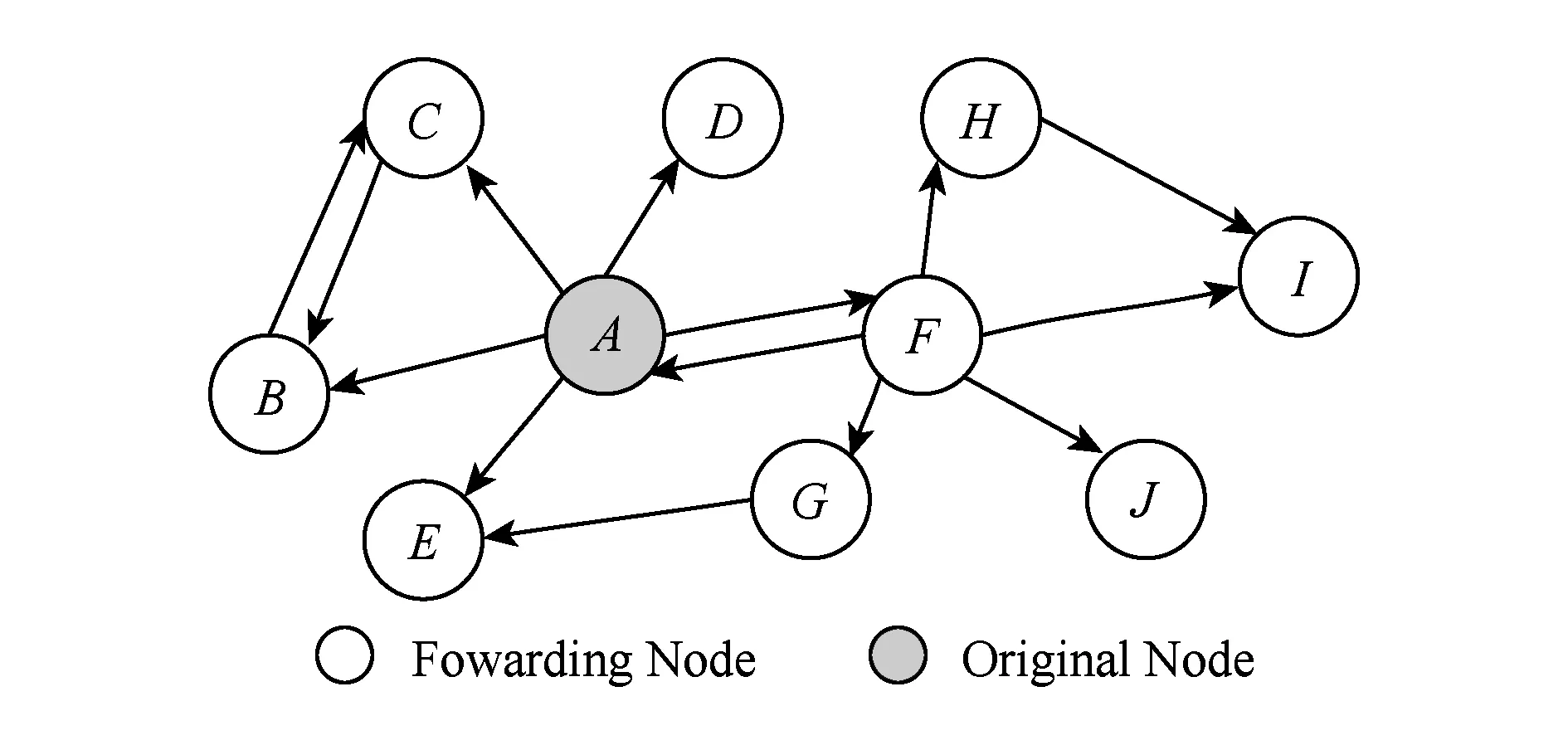
Fig. 2 Schematic diagram of the information propagation图2 信息传播示意图
3.3 tsk-shell算法效果
1) 定量比较
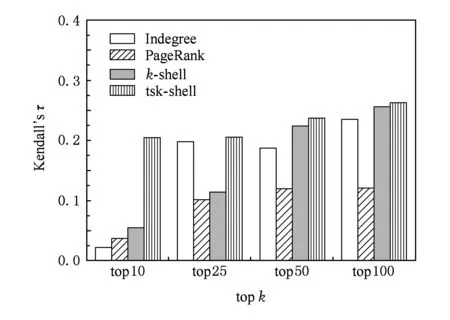
本节将文中提出的算法tsk-shell与常用的寻找高影响力传播者的度中心性,k-shell和PageRank等算法进行对比,比较各种算法在预测传播者影响力的正确性.其中,k-shell是目前证实的最好的发现有影响力传播者的算法.上述4种算法的结果预测了用户传播影响力的相对大小,为用户的一个排序,该结果将和3.2节中的评估标准进行比较.本文采用Kendall’sτ和Spearman’sρ这2种相关系数进行序的相似性比较,他们用来计算预测的用户影响力排序和标准的用户影响力排序之间的统计依赖关系,定义如下:
对于长度为n的样本向量X和Y,分别将其转化为每个样本对应的排序向量x和y,对于任意的2个观测值(xi,yi)和(xj,yj),如果xi>xj且yi>yj,或者xi (9) 其中,cc表示一致观测对的数量,dc表示不一致观测对的数量.Spearman’sρ的定义为式(10): (10) 其中,di=xi-yi,表示2个排序值之差. Fig. 3 Comparison of algorithms’ prediction performance (Kendall’s τ)图3 算法预测性能比较(Kendall’s τ) 由于每个话题在传播过程中的影响因素的复杂多样性,每个话题传播的过程不尽相同,因此,文中取算法对所有话题预测性能的平均值作为最后的结果.图3和图4分别比较了4种算法分别运用Kendall’sτ和Spearman’sρ这2种相关系数的比较结果.可以得出,本文提出的tsk-shell算法在发现最有影响力的topk个传播者方面超过了传统的算法,其中比最好的k-shell算法性能平均提高了40%. Fig. 4 Comparison of algorithms’ prediction performance (Spearman’s ρ)图4 算法预测性能比较(Spearman’s ρ) 2) 定性比较 为了给出一个更为直观的认识,表2给出了在奥巴马医改计划话题中分别利用k-shell和tsk-shell算法得出的排名top 10的高影响力传播用户. Table 2 Top 10 Users in the Obama Health Care Topic表2 在奥巴马医改话题中排名top 10的用户 可以看出,2种结果中相同的用户只有Barack-Obama和TheOnion,表示考虑了话题因素后结果有了显著的变化.直观上看,tsk-shell算法更加合理,如BarackObama是当时奥巴马发布Twitter的账号,在奥巴马医改计划这个话题中,奥巴马无疑是最有影响力传播者,要高于用户reimagin;另外,tsk-shell算法发现的top 10高影响力传播者中还有曾担任小布什总统高级顾问的著名政治评论家Karl Rove. k-shell算法是目前发现社交网络中高影响力传播者的效果较好的算法之一,但主要依赖拓扑结构分析用户的传播影响力,而缺少考量话题在信息传播中的影响.本文基于不同用户对不同话题感兴趣的程度不同、同一用户在不同话题下的影响力存在差异这一假设,将用户间的话题影响关系建模进社交网络中用户的度的概念,从而使传统k-shell算法在保留拓扑结构分析能力、简洁高效特性的同时,扩展出利用网络传播内容的话题信息的能力,提出了话题敏感的tsk-shell算法.该算法建模了话题对信息传播的影响,并结合用户交互行为和社交网络结构一起来发现特定话题下的高影响力传播者.本文在Twitter数据集上利用真实的传播实例对算法进行了验证,实验结果证明了话题对信息传播具有重要影响,以及tsk-shell算法在发现话题相关的高影响力传播者应用中的有效性. [1]Weng Jianshu, Lim E, Jiang Jing, et al. TwitterRank: Finding topic-sensitive influential twitterers[C] //Proc of the 3rd ACM Int Conf on Web Search and Data Mining. New York: ACM, 2010: 261-270 [2]Kitsak K, Gallos K L, Havlin S, et al. Identifying influential spreaders in complex networks[J]. Nature Physics, 2010, 6(11): 888-893 [3]Pei Sen, Muchnik L, Andrade J S, et al. Searching for superspreaders of information in real-world social media[J]. Scientific Reports, 2014, 4: 5547-5547 [4] Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the Web, SIDL-WP-1999-0120[R]. Palo Alto: the Stanford InfoLab, 1999: 1-14 [5] Barbieri N, Bonchi F, Manco G. Topic-aware social influence propagation models[J]. Knowledge and Information Systems, 2013, 37(3): 555-584 [6] Bi B, Tian Y, Sismanis Y, et al. Scalable topic-specific influence analysis on microblogs[C] //Proc of the 7th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2014: 513-522 [7] Wu Xindong, Li Yi, Li Lei. Influence analysis of online social network[J]. Chinese Journal of Computers, 2014, 37(4): 735-752 (in Chinese)(吴信东, 李毅, 李磊. 在线社交网络影响力分析[J]. 计算机学报, 2014, 37(4): 735-752) [8]Ding Zhaoyun, Zhou Bin, Jia Yan, et al. Topical influence analysis based on the multi-relational network in microblogs[J]. Journal of Computer Research and Development, 2013, 50(10): 2155-2175) (in Chinese)(丁兆云, 周斌, 贾焰, 等. 微博中基于多关系网络的话题层次影响力分析[J]. 计算机研究与发展, 2013, 50(10): 2155-2175) [9]Garas A, Schweitzer F, Havlin S. Ak-shell decomposition method for weighted networks[J]. New Journal of Physics, 2012, 14(8): 1-17 [10] Batagelj V, Zaversnik M. AnO(m) algorithm for cores decomposition of networks[J]. Advances in Data Analysis and Classification, 2011, 5(2): 129-145 [11]Zeng An, Zhang Chengjun. Ranking spreaders by decomposing complex networks[J]. Physics Letters A, 2013, 377(14): 1031-1035 [12]Romero M D, Galuba W, Asur S, et al. Influence and passivity in social media[C] //Proc of the 20th Int Conf Companion on World Wide Web. New York: ACM, 2011: 18-33 [13]Tang Jie, Sun Jimeng, Wang Chi, et al. Social influence analysis in large-scale networks[C] //Proc of the 15th ACM Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2009: 807-816 [14]Blei D, Ng A, Jordan M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(1): 993-1022 [15]Yang J, Leskovec J. Patterns of temporal variation in online media[C] //Proc of the 4th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2011: 177-186 [16]Kwak H, Lee C, Park H, et al. What is Twitter, a social network or a news media?[C] //Proc of the 19th Int Conf on World Wide Web. New York: ACM, 2010: 591-600 [17]Liu Lu, Tang Jie, Han Jiawei, et al. Mining topic-level influence in heterogeneous networks[C] //Proc of the 19th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2010: 199-208 Gou Chengcheng, born in 1985. PhD candidate. His main research interests include Web search and mining, machine learning and social network. Du Pan, born in 1981. PhD. His main research interests include Web search and mining, machine learning and social network (dupan@software.ict.ac.cn). He Min, born in 1982. PhD. Her main research interests include natural language process, Web mining and information security(heminsmile@163.com). Liu Yue, born in 1971. PhD. Associate professor. Her main research interests include information retrieval and Web mining(liuyue@ict.ac.cn). Cheng Xueqi, born in 1971. PhD. Currently professor and PhD supervisor in the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include network information security, large-scale information retrieval and knowledge mining (cxq@ict.ac.cn). tsk-shell: An Algorithm for Finding Topic-Sensitive Influential Spreaders Gou Chengcheng1,2, Du Pan1, He Min1,2,3, Liu Yue1, and Cheng Xueqi1 1(CASKeyLaboratoryofNetworkDataScienceandTechnology(InstituteofComputingTechnology,ChineseAcademyofSciences),Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049)3(NationalComputerNetworkandInformationSecurityManagementCenter,Beijing100029) Discovering influential spreaders is a valuable task in social networks, especially for the popularity prediction and analysis of online contents on microblogs, such as Twitter and Weibo. Thek-shell decomposition (k-core), which identifies influential spreaders located in the core of a network, attracts more attention due to its simpleness and effectiveness compared with various related methods, such as indegree, betweenness centrality and PageRank. However,k-shell method only considers the factor of the network position of nodes and ignores the impacts of the content itself in information diffusion. The content itself plays an important role in the process of diffusion. For example, ones just retweet their interested tweets in microblogs. The spread ability of users depends not only on topology structures but also on the published contents, and therefore a unified model considering the two aspects simultaneously is proposed to model users’ influence. Specifically, the topics hidden in user generated contents (UGC) are exploited to model the users’ propagation probability and a topic-sensitivek-shell (tsk-shell) decomposition algorithm is proposed. Experimental studies on a real Twitter dataset show that the tsk-shell outperforms traditionalk-shell by 40% on average in the task of finding topkinfluential users, which proves the effectiveness of the tsk-shell algorithm. influential spreader;k-shell decomposition; social network; information diffusion; propagation probability;microblogs 2015-09-15; 2015-12-25 国家“九七三”重点基础研究发展计划基金项目(2012CB316303, 2014CB340401);国家“八六三”高技术研究发展计划基金项目(2015AA015803,2014AA015204);中国科学院重点部署项目(KGZD-EW-T03-2);国家自然科学基金项目(61232010,61572473,61303156,61502447);国家242信息安全计划基金项目(2015F028);山东省自主创新及成果转化专项(2014CGZH1103);欧盟第七科技框架计划项目(FP7)(PIRSES-GA-2012-318939) This work was supported by the National Basic Research Program of China (973 Program) (2012CB316303, 2014CB340401), the National High Technology Research and Development Program of China (863 Program) (2015AA015803, 2014AA015204), the Key Research Program of the Chinese Academy of Sciences (KGZD-EW-T03-2), the National Natural Science Foundation of China (61232010, 61572473, 61303156, 61502447), the National 242 Information Security Program (2015F028), the Shandong Province Independent Innovation and Achievements Transformation Special Program (2014CGZH1103), and the 7th Framework Programme of Europe Union (FP7) (PIRSES-GA-2012-318939). TP391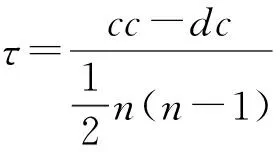



4 结 论





