面向多关键字的模糊密文搜索方法
2017-02-22王恺璇李宇溪周福才王权琦
王恺璇 李宇溪 周福才 王权琦
(东北大学软件学院 沈阳 110819) (wkx_king@126.com)
面向多关键字的模糊密文搜索方法
王恺璇 李宇溪 周福才 王权琦
(东北大学软件学院 沈阳 110819) (wkx_king@126.com)
围绕多关键字的模糊匹配和数据安全性保障问题,展开对多关键字模糊搜索方法的研究,提出一种面向多关键字的模糊密文搜索方案.该方案以布隆过滤器(Bloom filter)为基础,使用对偶编码函数和位置敏感Hash函数来对文件索引进行构建,并使用距离可恢复加密算法对该索引进行加密,实现了对多关键字的密文模糊搜索.同时方案不需要提前设置索引存储空间,从而大大降低了搜索的复杂度.除此之外,该方案与已有方案相比不需要预定义字典库,降低了存储开销.实验分析和安全分析表明,该方案不仅能够实现面向多关键字的密文模糊搜索,而且保证了方案的机密性和隐私性.
云存储;布隆过滤器;可搜索加密机制;位置敏感Hash函数;多关键字模糊搜索
随着云存储的迅速发展以及用户对个人数据隐私性的愈加重视,如何对存储在服务器中的密文进行搜索就显得格外重要.可搜索加密方法(searchable encryption, SE)是解决密文搜索的有效方法.
可搜索加密方法首次由Song和Wagner等人[1]提出,开创了将搜索机制应用于关键字密文搜索的先河;2005年,Chang等人[2]提出了基于预定义字典的可搜索加密机制.这种机制不仅优化了关键字的搜索效率,而且还缩减了计算开销.但是,由于预定义字典的设定,同时也给用户带来了额外的存储开支.随后Dong等人[3]在2008年针对安全性进行了改进,提出了能够抵抗自适应性攻击的搜索加密模型.2015年,Revathy等人[4]提出了排序的搜索加密机制.以上几种搜索关键字均是基于对称密码学的精确的单关键字搜索机制,用户只能在一次搜索过程中发送1个单词,这种搜索机制与现实的搜索需求极为不符.
2014年,Cao和Wang等人[5]提出了多关键字可搜索加密机制.该机制在搜索时为索引和关键字构建向量,并通过向量运算实现了搜索结果的排序.2016年,文献[6]提出了多关键字的排序搜索方案,该方案利用树构建索引结构,减少了搜索时间.
从以上方案可以看出,不论是面向单关键字还是多关键字,现有研究都是针对精确搜索的.而针对用户输入错误关键字的情况,精确的单关键字搜索加密机制或者基于连接词的搜索加密机制还需要改进.研究学者在精确搜索的基础上相继提出了基于关键字的模糊搜索方案.Bringer等人[7]在2009年提出了面向明文的模糊搜索方案,该方案主要基于布隆过滤器实现数据存储.Van Liesdonk等人[8]在2010年研究了模糊关键字搜索加密方案,但这种方案最大的缺陷是需要用户额外花费时间来执行关键字的循环搜索.2010年,文献[9]实现了关键字模糊搜索的加密机制,但该方案需要用户付出庞大的数据存储空间,且只实现了基于单关键字的模糊密文搜索.之后在2013年,文献[10-11]也相继提出了不同的模糊关键字搜索方法.其中,文献[10]给出了单关键字可排序模糊关键字搜索方法,文献[11]提出的是一种可验证的模糊关键字搜索方案.
本文针对密文的多关键字模糊搜索展开研究,以提高搜索效率为目标,提出了一种面向多关键字的模糊密文搜索方案,该方案利用布隆过滤器和位置敏感Hash函数技术,能够有效实现多关键字的密文模糊搜索.主要研究内容包括:将上传文件利用对偶编码函数将其关键字转换成向量,再利用位置敏感Hash函数将其映射到布隆过滤器中;服务器在执行密文搜索时,需要先对输入的查询关键字进行上述转换,再通过计算安全索引参数和陷门的内积来搜索到符合条件的密文文件.与已有方案相比,本方案不需要提前设置索引存储空间,从而大大降低了搜索的复杂度;同时,该方案不需要预定义字典库,降低了存储开销.安全性分析表明方案不仅保证了可用性,而且满足了机密性和隐私性.因而,该方案具有重要的理论价值和应用前景.
1 预备知识
1.1 位置敏感Hash函数
位置敏感Hash函数于1998年由Indyk等人[12]提出,主要用于解决高维数据的搜索问题.
定义1. 位置敏感Hash函数.给定n个d维的点集S以及各点之间的相似性度量D,Hash族H={h:H→U}被称为(r1,r2,p1,p2)-敏感Hash函数,需要满足以下条件,对于q∈S:
如果v∈d(q,r1),那么Pr[h(q)=h(v)]≥p1;
如果v∉d(q,r1),那么Pr[h(q)=h(v)]≤p2.
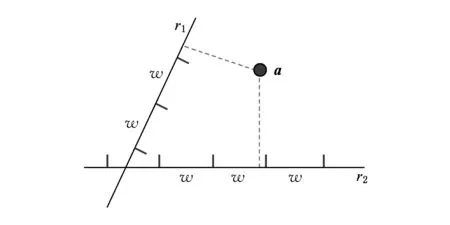
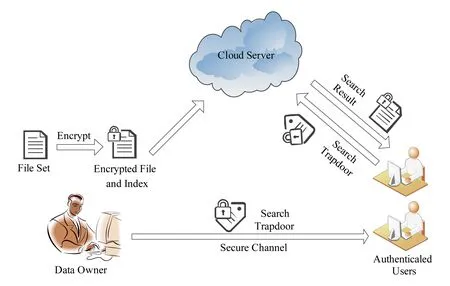
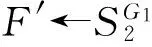
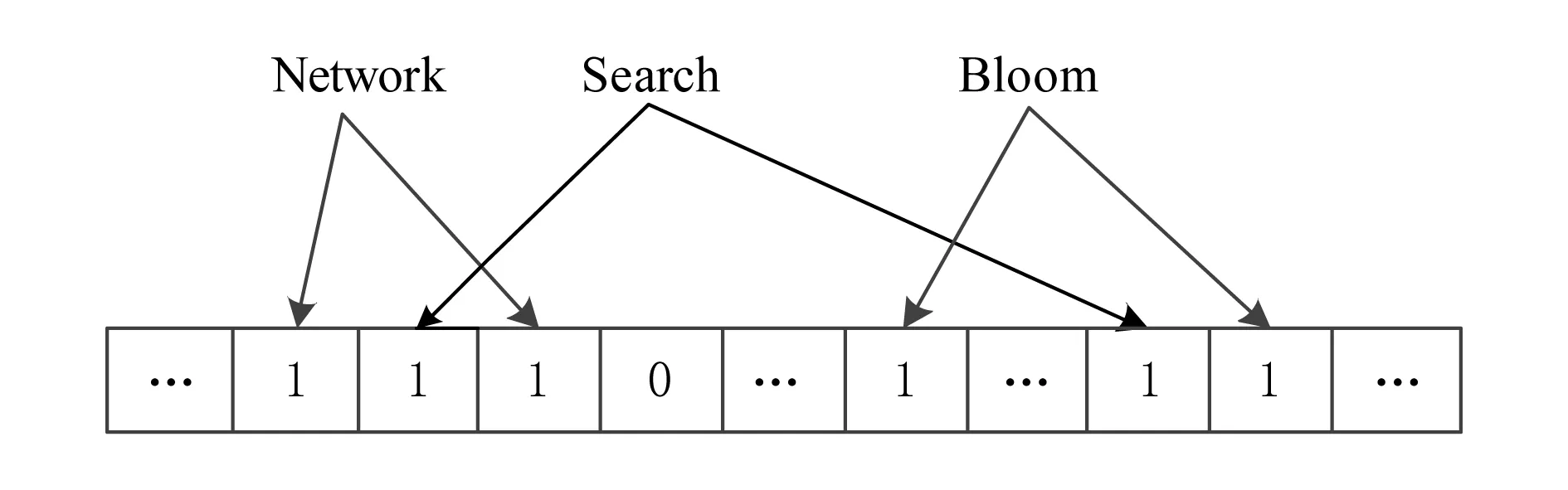
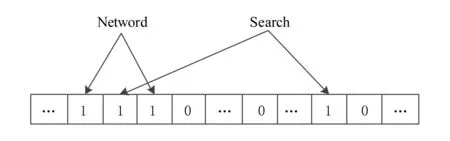
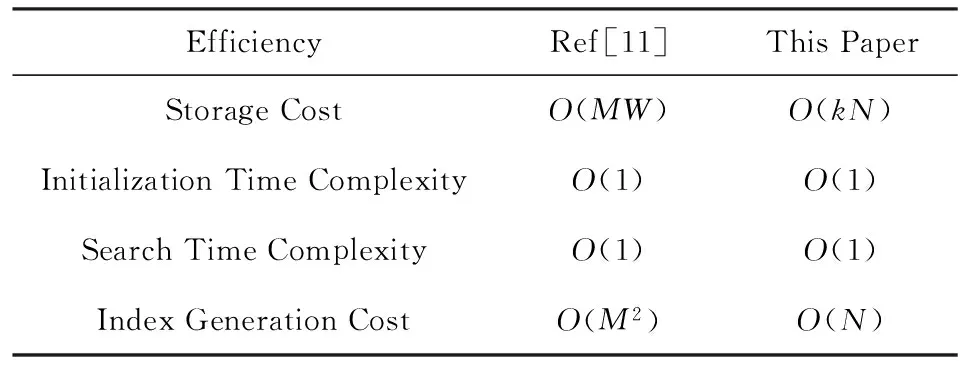
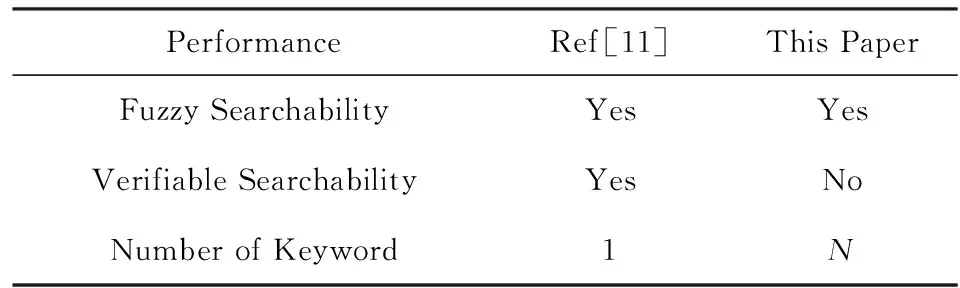
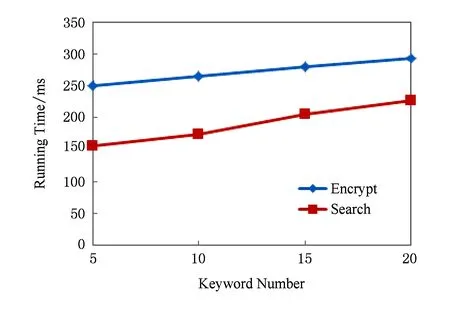
其中,r1 (1) 其中,参数a和b分别是d维的向量和[0,w]间的一个随机数,向量a中的每个元素都满足p-stable分布. 式(1)的计算过程实际是向量的映射过程,如图1所示.a·v即把向量a映射到以向量v为基向量的数轴上,如果将此数轴等分为w份,同时每份做上标记,a·v的值对应哪个区间就将这个区间的标记号作为向量a的Hash函数值. Fig. 1 p -stable distribution definition图1 p稳定分布定义图 p(c)=Pra,b[ha,b(v1)=ha,b(v2)]= 其中,fp是分布D的密度函数,p1=p(r1),p2=p(r2). 1.2 布隆过滤器 Bloom[14]在1970年提出了布隆过滤器(Bloom filter, BF)的概念.BF是一种概率型数据结构,主要用于判断某个元素是否存在于集合中. 布隆过滤器的主要工作原理是:运用一个m(单位为b)长的数组表示这个布隆过滤器,数组的每一位元素初始化为0.随后随机选择k个Hash函数,将数据域S={y1,y2,…,yn}中的n个元素分别一一映射到上面的数组中,当需要映射1个元素时,计算每个元素的k个Hash函数对应的k个Hash值,然后把数组中对应的位置设置为1.如果Hash值对应的位置已经设置成为1,就保留第1次作用的效果.如图2所示: Fig. 2 The sample figure of Bloom filter图2 布隆过滤器示例图 判断元素x是否存在于数据域中,计算元素x对应的上面的k个Hash函数的Hash值,如果该元素的所有Hash值对应的位置都为1,就说明元素x存在于数据域中. 向布隆过滤器中加入1个新的元素时,需要使用k个不同的Hash函数对其进行Hash计算,将这个元素映射到布隆过滤器的k个比特位中,同时将这些比特位设置为1. 查询某个元素是否存在于布隆过滤器中时,需要利用提前定义的k个Hash函数将其映射到BF的k个比特位上.如果这k个比特位对应的值都是1,则说明该元素存在于集合中, 只要有一个位置不为1,则此元素不存在于该集合中. 1.3 对偶编码函数 在面向密文的多关键字模糊搜索方案中,构建索引、构建陷门和关键字查询的过程都是基于向量的操作过程.数据拥有者输入的关键字都由字符组成,由于字符的不可计算性,需要将其转换成向量的形式. 定义2. 对偶编码函数.给定字符串S1=C1C2…Cn和二进制向量S2=b0b1…bm-1,S2中每位元素的初始值为0,其中n 1.4 距离可恢复加密方案 距离可恢复加密算法可以将数据库中的各个元素表示成1个多维的点,其中属性作为该点的维度,属性对应的值作为该维度上的值. 定义3. 距离可恢复加密(distance recovery encryption, DRE)[15-16].给定加密函数E以及加密密钥K,则数据库DB中的点p对应的密文为E(p,K).当且仅当E满足以下条件,E可称为距离可恢复加密.对于任意2点p1,p2,以及密钥K,存在函数f,使得 f(E(p1,K),E(p2,K))=d(p1,p2) 成立.其中d(p1,p2)为p1,p2的距离.如果函数f是欧氏距离计算函数,则E被称为距离保留转换函数. 本节将描述该方案的模型、形式化和安全性定义以及方案的详细设计. 2.1 模 型 如图3所示,方案中涉及3个实体:1)数据拥有者.该实体把数据外包给服务器进行加密存储.2)可信赖用户.该实体并不持有数据但是可以对数据进行搜索,最终获取需要的数据.3)服务器.此实体提供存储服务,存储用户的密文数据,并在收到用户的搜索请求时,执行密文的搜索操作. 数据拥有者在本地选择待存储的文件集,对其进行处理后上传到服务器端.文件集的处理包括2个部分:1)对文件进行加密,之后生成相应的密文;2)为待存储的文件设置索引,利用预定义的加密算法对其进行加密,最终生成加密索引.数据拥有者需要将处理之后的文件上传至服务器,由于存储文件和索引的工作由服务器负责,所以数据拥有者只需要执行上传操作即可,不需要再关心具体的存储细节. Fig. 3 Basic architecture图3 方案基本架构 各个实体的功能介绍如下: 1) 数据拥有者.它是一个特殊的可信赖用户,因为具体的明文是由数据拥有者确定,所以数据拥有者是3个实体中唯一能够与明文直接接触的实体.数据拥有者首先选择明文数据,然后加密这些明文,同时构建这些明文相对应的索引,最后把密文以及加密后的索引发送给云服务器进行存储.数据拥有者还需要选择可信赖用户(包括自己),并向其发送搜索陷门. 2) 可信赖用户.即数据拥有者授权的可信实体.它主要接收数据拥有者发送的搜索陷门,然后生成安全陷门,向服务器端发送搜索请求.接收到服务器发送回来的搜索结果后,对搜索结果进行解密,从而获取需要的明文数据. 3) 服务器.它主要进行数据密文以及索引密文的存储,同时对于数据拥有者以及可信赖用户发来的搜索请求进行相应的搜索以及应答. 对于基于布隆过滤器以及位置敏感Hash函数实现的面向多关键字的模糊密文搜索方案,在该方案中不需要设置预定义字典存储错误的关键字.根据上述描述提出面向多关键字的模糊密文搜索方案的基本架构. 2.2 形式化定义 本方案主要由4个主要算法组成:初始化算法、生成索引算法、生成陷门算法、搜索算法.形式化地表示为MKFS=(KeyGen,BuildIndex,Trapdoor,Search).下面分别对其进行具体的描述. 1)sk←KeyGen(1k):初始化算法.运行于数据拥有者端,主要用于生成密钥.输入安全参数1k,输出密钥sk.加密索引和查询关键字都需要该密钥.如果该密钥丢失,数据拥有者将无法从服务器端再获取目标数据. 2)I←BuildIndex(sk,F,W):生成索引算法.运行于数据拥有者端,主要用于生成文件对应的安全索引.输入密钥sk、文件标记序号F以及文件F对应的关键词集合δ,输出安全索引I. 3)t←Trapdoor(sk,Q):生成陷门算法.运行于用户端,用于加密查询关键字集合生成安全陷门.输入密钥sk以及查询关键词集合Q,输出安全陷门t.用于加密查询关键词集合Q,输出安全陷门t. 4)FR←Search(I,t):搜索算法.运行于第三方服务器端.输入安全索引和安全陷门,输出文件序列集合.主要进行安全索引与安全陷门的匹配,如果匹配成功就返回该索引对应的文件标识符;如果匹配不成功,则无返回结果. 当服务器端搜索到满足搜索条件的结果时,就将结果集合返回给用户,用户需要利用数据拥有者传送的搜索陷门进行解密,最后得到需要的目标文件. 2.3 安全性定义 根据本文提出的方案,在给出安全模型之前,首先定义以下几个与安全性模型相关的概念,方便后续的安全性定义. 定义4. 数据拥有者所持有的所有明文信息以及查询关键字归纳定义为明文信息集H=(F,W,Q).其中F为文件集合,W为各文件对应的关键字集合,Q为查询关键字集合. 定义5. 明文信息集H加密生成的密文信息集V(H).该集合包括文件集合F对应的密文集合Encs k(F),关键字集合W加密后对应的安全索引集合I和查询关键字集合Q加密后对应的安全陷门t. 定义6. 将服务器能够获取的信息统称为足迹集合Tr(H).Tr(H)主要由服务器搜索到的结果组成,即Tr(H)={Tr(w1),Tr(w2),…,Tr(wt)}. 为了更好更直观地评估搜索方案的安全性,本文根据敌手能够获取的资源SA将攻击模型分为3个级别. 级别1. 已知密文模型.在这个安全级别中,敌手只能获取密文信息V(H),即SA=〈V(H)〉.实际应用中,服务器除了能够获取密文资源外,无法获取其他任何的资源. 级别2. 已知密文与某些明文.在这个安全级别中,敌手除了能够获取密文资源,还能够获取一组明文信息H′∈H,但是敌手无法确认这些信息所对应的密文,即SA=〈V(H),H′〉. 级别3. 已知密文与某些明文以及这些明文对应的密文.在这个攻击模型中,敌手除了能够获取密文资源、一组明文信息H′∈H,还能够获取这些明文信息对应的密文V(H′),即SA=〈V(H),H′,V(H′)〉. 上述3个级别中,级别越高说明该方案安全性越高,所以如果一个加密方案能够抵抗级别高的攻击模型,那么该模型也能够抵抗级别低的模型.在上诉定义的3个级别的安全模型中,级别2与现实环境更接近.由于实际应用中,敌手无法在不知道密钥的情况下,由密文关联明文,所以级别3在实际应用中很少会发生. 在上述安全模型中,一个能够保证数据安全性的密文搜索方案应该满足以下安全特性: 1) 文件隐私性.文件隐私性表示存储在第三方服务器中的密文文件不应向服务器泄露任何与明文文件相关的信息. 2) 关键字隐私性.服务器能够获取的不仅是搜索结果,还能够获取安全索引以及安全陷门.关键字隐私性要求服务器无法通过安全索引以及安全陷门获取任何与关键字相关的信息. 3) 陷门不可链接性.服务器无法将获取到的一个安全陷门扩展到另一个安全陷门,即进行2次搜索操作时,输入同一组关键词,服务器无法对这2次生成的陷门进行区分. 除此之外,提出面向多关键字的模糊密文搜索方案能够抵抗选择明文攻击.方案的安全性证明主要是敌手和用户模拟器之间的交互性游戏. 定义RealS1(sk)为模拟器S1执行真实方案的1次实验,在整个实验过程中均使用真实的方案算法.用户首先执行初始化算法,然后分别根据敌手需要挑战的内容生成不同的内容,并保存已获取的信息构成VReal.该实验最终输出1个比特b作为输出结果. 定义IdealS2(sk)为模拟器S2的1次模拟仿真实验.与RealS1(sk)不同的是IdealS2(sk)实验中并不运行真实的算法,而是把真实算法中服务器可以获取的资源作为IdealS2(sk)实验的输入,然后模拟器通过生成随机数据作为实验输出.同RealS1(sk)一样,S2收集所有已获取的信息构成VIdeal.该实验最终输出1个比特b′作为输出结果. 选择关键字安全性指的是,存在任意模拟器,使得任意敌手都无法将VIdeal和VReal区分开来.即敌手无法真正区分整个实验过程中到底是真实的用户还是模拟器在与其进行交互.下面将给出面向多关键字的模糊密文搜索方案的安全模型的形式化定义. 定义7. 自适应选择关键字安全性.给定一个面向多关键字的模糊密文搜索方案,令A为一个敌手,S1,S2为2个模拟器.函数G1,G2,G3分别是在生成密文阶段、生成安全索引阶段、生成陷门阶段中实验RealS1(sk)和实验IdealS2(sk)之间互相共享的信息,即实验RealS1(sk)的泄露函数.下面是实验的交互过程: 实验RealS1(sk)和实验IdealS2(sk)在文件加密阶段的形式化定义如下: RealS1(sk): sk←KenGen(1k), F←S1(m), X←Enc(F,sk:S1), outputb1←S1(X). IdealS2(sk): sk′←KenGen(1k), X′←Enc(F′,sk′:S2), 实验RealS1(sk)和实验IdealS2(sk)在生成陷门阶段的形式化定义如下: RealS1(sk): sk←KenGen(1k), (l)←S1, Q←S1(l), t←BuildTrapdoor(Q,sk:S1), outputb2←S1(t). IdealS2(sk): sk′←KenGen(1k′), t′←BuildTrapdoor(Q′,sk′:S2), 实验RealS1(sk)和实验IdealS2(sk)在生成安全索引阶段的形式化定义如下: RealS1(sk): sk←KenGen(1k), (fi,t)←S1, Wi←S1(t,fi), I←BuildIndex(fi,Wi,sk:S1), outputb3←S1(I). IdealS2(sk): sk′←KenGen(1k′), 在前文已对敌手具有的能力进行了分析,并且定义了方案在安全目标为不可区分性的条件下的安全模型.下面利用敌手和挑战者之间的攻击游戏来定义面向多关键字的模糊密文搜索方案的安全性. 1) 挑战密文 ① 初始阶段.挑战者执行初始化算法KenGen(1k),密钥sk作为该阶段的输出结果. 如果完成上述游戏后,对所有的敌手A,均存在一个模拟器S,使: 其中p(sk)是以sk为输入的多项式,那么面向多关键字的模糊密文搜索方案针对密文是选择明文攻击安全的. 2) 挑战安全陷门 ① 初始阶段.挑战者执行初始化算法KenGen(1k),密钥sk作为该阶段的输出结果. 3) 挑战安全索引 ① 初始阶段.挑战者执行初始化算法KenGen(1k),密钥sk作为该阶段的输出结果. 2.4 算法详细设计 2.4.1 密钥生成算法 sk←KeyGen(1k):该算法用于方案的初始化、生成密钥,其中k需要取足够长,例如128 b,这样才能够有效阻止蛮力攻击.该算法的主要步骤如下: 1) 随机构建2个k×k维的矩阵M1,M2∈k×k; 2) 随机构建1个k维的向量S∈{0,1}k,为了使引入参数向量S的随机性最大化,S中0和1的数量需要大致相同. 3) 输出sk=(M1,M2,S)作为生成加密索引和生成陷门的密钥. 2.4.2 生成安全索引算法 I←BuildIndex(sk,F,W):该算法用于加密用户输入的索引.主要步骤如下: 1) 对于文件集合F={f1,f2,…,fn}中的每一个文件fi: ① 为文件fi构建一个k位的Bloom过滤器Bi; ② 对于文件fi所对应的关键字集合Wi={w1,w2,…,wt},使用对偶编码函数将其转换成向量集合V={v1,v2,…,vt},其中每个向量vi∈{0,1}676; ③ 对于向量集合V={v1,v2,…,vt}中的每个向量vi,使用位置敏感Hash函数{H1,H2,…,Hl}进行计算(H1(vi),H2(vi),…,Hl(vi)),并将结果插入到Bloom过滤器Bi中. 2) 将私钥sk中的S表示为S=(s1,s2,…,sk).对于每一个文件fi所得到的Bloom过滤器Bi, ① 随机选择参数r∈. 3) 输出I=(F,I1,I2,…,In). Fig. 4 Sample of generation security index图4 生成安全索引示例 根据上述生成安全索引的步骤,给出一组具体的示例.给定3个关键词:Network,Search,Bloom.先将这3个关键词转换成676 B长的数组表示,其中每个元素都表示每2个字符的组合,然后利用选择的l个位置敏感Hash函数(这个示例中l=2),计算单个关键词在布隆过滤器中对应的位置,最后该对应的位置置位为1.该示例的具体操作如图4所示: 2.4.3 陷门算法 t←Trapdoor(sk,Q):根据查询关键词集合生成安全陷门.主要步骤如下: 1) 构建1个k位的Bloom过滤器B. 2) 对于查询关键字集合Q={q1,q2,…,qt},使用对偶编码函数将其转换成向量集合V={v1,v2,…,vt},其中每个向量vi∈{0,1}676. 3) 对于向量集合V={v1,v2,…,vt}中的每个向量v,使用位置敏感Hash函数{H1,H2,…,Hl}进行计算,并将结果插入到Bloom过滤器B中. 4) 将私钥sk中的S表示为S=(s1,s2,…,sk).对于Bloom过滤器B: ① 随机选择数r′∈. ⑤ 令t=(t′,t″). 5) 输出陷门t. 针对上述给出的生成陷门的具体步骤,给定2个查询关键词对上述的步骤进行形象化的表示.假设给定的2个查询关键词为Netword,Search.对比索引示例图中的关键词,Netword与Network之间仅仅相差了1个字符,但是通过同一组位置敏感Hash函数计算后Netword在布隆过滤器中对应的位置与Network的位置相同.下面给出示例中2个查询关键词的布隆过滤器表示,如图5所示: Fig. 5 Example of generating the trapdoor图5 生成陷门示例 2.4.4 搜索算法 FR←Search(I,t):服务器根据陷门和加密索引执行搜索.主要步骤如下: 1) 令FR为一个初始为空的文件集合. 2) 将I表示为I=(F,I1,I2,…,In).对于其中的每一个Ii: ② 计算向量的数量积 (2) ③ 按排序算法将计算的向量内积作排序,将排序序列中的前λ条记录加入到结果集合FR中. 3) 输出FR作为最终搜索结果. 图6是通过2.4.2~2.4.3节中给出的生成安全索引的示例以及生成陷门的示例给出的最终搜索示例结果,按照上述搜索步骤,实际服务器执行的就是2个向量之间的内积,然后获取内积结果,找出对应的文件标识. 为了确保索引以及查询关键词经过上述加密后能否返回正确的结果,只要保证RI=Bi·B就说明该搜索方案能够实现面向多关键字的模糊密文搜索.下面就给出上述过程的正确性推导: 3)RI=Ii·t,安全索引与陷门作内积运算. 由上述推算结果可以看出,参数r′与最终的结果没有关系,所以可以随机选择. 由上述推算结果可以看出,参数r′与最终的结果没有关系,所以可以随机选择. 7) 通过5) 6)的推导,得出 RI={bi,j·bj,bi,j∈Bi,bj∈B}=Bi·B. 由7)中最终的推算结果,可知本文提出的面向多关键字的模糊密文搜索方案是正确的. 2.5 方案详细设计 本节将通过对数据拥有者、可信赖用户和服务器这3个实体间的交互对方案的详细设计进行描述. 1) 在初始化阶段,数据拥有者首先选定待存储的文件集;然后运行算法KeyGen(1k)为系统生成密钥. 2) 对于已选定的文件集,数据拥有者将采用传统的对称加密算法对其进行加密. 3) 数据拥有者为待存储的文件设置索引,即运行算法BuildIndex(sk,F,W)得到文件的安全索引;然后将加密后的文件集与安全索引一同存储到服务器中. 4) 数据拥有者根据判断选择自己的可信赖用户. 5) 当可信赖用户想要在服务器中搜索特定文件时,他将给定关键字集合,并将其发送给数据拥有者. 6) 数据拥有者在接收到用户发送的关键字集合后,运行Trapdoor(sk,Q)算法为关键字集合生成搜索陷门,并返回给可信赖用户. 7) 可信赖用户将搜索陷门发送给服务器进行搜索请求. 8) 服务器在接收到搜索陷门后将对搜索陷门和加密的安全索引运行Search(I,t)算法,得到的结果为加密的目标文件集;然后将目标文件集返回给可信赖用户. 9) 可信赖用户在接收到搜索结果后,通过数据拥有者的协助将搜索结果进行解密,得到最终的明文文件. 3.1 正确性分析 本文提出的面向多关键字的密文搜索方法既可对准确的关键字进行搜索,又可对模糊的关键字进行搜索.因此我们将从下面2个方面对方案的搜索结果的正确性进行分析. 1) 本文方案能够返回对于准确的关键字搜索的正确结果.如果查询关键字Q⊂WD,云服务器应该包含结果集中的文件D.回想一下在构建索引和查询的过程中,我们使用了相同的l个Hash函数hj∈H,1≤j≤l.那么在查询Q中被设为1的位置,同样在索引ID中也设为1.这就表明查询能够产生内积操作的最大值.因此,文件D一定包含在结果集中. 2) 本文方案能够以高的概率返回对于模糊的关键字搜索的正确结果.假设关键字w∈Q与关键字w′∈WD稍有不同,也就是说d(w,w′)≤r1,其中r1是位置敏感Hash函数中的距离阈值.如果对于所有l个位置敏感Hash函数有hj(w)=hj(w′),hi∈H,1≤i≤l,那么搜索结果将返回如同精确关键字搜索一样的内积操作最大值. 而如果d(w,w′)>r1,那么位置敏感Hash函数将它们散列在一起的概率就会非常低.因此,本文方案会以高的概率返回相当高的内积计算结果. 3.2 安全性证明 目前大多数的密文搜索方案或多或少会泄露用户的某些相关信息.本文在这些泄露信息存在的条件下,给出方案的选择关键字安全性证明.安全性证明过程中,将方案的执行过程描述成敌手与用户或者模拟器之间的交互游戏,证明对于所有敌手,都无法从搜索过程中获取除了允许泄露的信息之外的任何信息. 接下来首先分析在方案的密文生成过程、安全索引生成过程以及陷门生成过程允许向服务器泄露的信息,然后给出这些泄露函数的形式化定义. 1) 生成密文 2) 生成陷门 3) 生成安全索引 在生成陷门过程中,实验IdealS2(sk)可以了解在实验RealS1(sk)中关键字集合Q中每一个元素qi是否存在于文件fj中,可以将这些信息记为G3. 定理1. 如果文件加密方案、生成安全索引方案、生成陷门方案都是CPA安全的,则本文提出的面向多关键字的模糊密文搜索方案在随机预言机模型下是针对自适应选择关键字攻击的(G1,G2,G3) 安全的. 定理1表明,在给定上述泄露函数的情况下,本文提出的面向多关键字的模糊密文搜索方案在预言机模型下是安全的. 证明. 构造一个多项式模拟器,与敌手进行交互,在这个过程中,模拟器需要分别执行实验RealS1(sk)和实验IdealS2(sk),最后敌手无法区分收到的结果是实验RealS1(sk)的结果还是实验IdealS2(sk)的结果. 1) 生成密文阶段 初始阶段:挑战者执行初始化算法KenGen(1k),密钥sk作为该阶段的输出结果. 挑战阶段:敌手A选择想要挑战的明文信息F,并将其发送给挑战者,挑战者分别执行实验RealS1(sk)和实验IdealS2(sk). 生成随机参数b∈{0,1}.b=0时,将X发送给敌手;当b=1时,将X′发送给敌手. 猜测:最后,敌手输出对b的1个猜测b″. 密文加密采用AES加密方案,由于该方案是CPA安全的,因此,保证了对于任何多项式敌手来说,都无法区分模拟值X′与真实值X,即敌手获胜的概率是可忽略的. 2) 生成陷门阶段 初始阶段:挑战者执行初始化算法KenGen(1k),密钥sk=(M1,M2,S)作为该阶段的输出结果,其中M1,M2∈(×)k,S∈k. 挑战阶段:敌手A选择想要挑战的查询关键字Q,并将其发送给挑战者,挑战者分别执行实验RealS1(sk)和实验IdealS2(sk). 实验RealS1(sk):挑战者将Q作为输入,执行算法BuildTrapdoor(sk,Q),输出真实陷门值t. 实验IdealS2(sk):根据泄露函数G1,G2,按下面步骤生成模拟的陷门值. ② 执行BuildTrapdoor(sk′,Q′),输出安全索引模拟值t′. 生成随机参数b∈{0,1}.b=0时,将X发送给敌手;当b=1时,将X′发送给敌手. 猜测:最后,敌手输出对b的1个猜测b″. 由于加密查询关键字中参数r和密钥sk的伪随机性,保证了对于任何多项式敌手来说,都无法区分模拟值X′与真实值X,即敌手获胜的概率是可忽略的. 3) 生成安全索引阶段 初始阶段:挑战者执行初始化算法KenGen(1k),密钥sk=(M1,M2,S)作为该阶段的输出结果,其中M1,M2∈(×)k,S∈k. 挑战阶段:敌手A选择想要挑战的对于关键字W的安全索引,并将其发送给挑战者,挑战者分别执行实验RealS1(sk)和实验IdealS2(sk). 实验RealS1(sk):挑战者将W作为输入,执行算法BuildIndex(sk,fi,W),输出真实的安全索引Ii. 实验IdealS2(sk):根据泄露函数G1,G2,G3, 按下面步骤生成模拟的安全索引的值. 生成随机参数b∈{0,1}.b=0时,将X发送给敌手;当b=1时,将X′发送给敌手. 猜测:最后,敌手输出对b的1个猜测b″. 由于生成安全索引中参数r′和密钥sk的伪随机性,保证了对于任何多项式敌手来说,都无法区分模拟值X′与真实值X,即敌手获胜的概率是可忽略的. 综上所述,对任意多项式敌手,实验RealS1(sk)和实验IdealS2(sk)的输出是一致的,即存在可忽略概率negl(k),使得: 因此,本文提出的面向多关键字的模糊密文搜索方案在随机预言机模型下针对选择关键字攻击是(G1,G2,G3)安全的. 证毕. 4.1 性能比较 本节我们对本文方案与文献[11]进行对比.为了使得对比更加清晰,假设本方案中存储文件总个数为N,使用到的Bloom过滤器大小为k;文献[11]中关键字的总个数为W,模糊关键字集合大小的最大值为M. 表1给出了2个方案在效率方面的对比结果.与文献[11]相比,本文方案的存储代价与文件总个数呈线性关系,而文献[11]的存储代价与关键字总个数呈线性关系.从初始化时间复杂度和搜索时间复杂度上看,2个方案都有较好的效率.而对于索引生成代价,本文显然具有更少的代价. 表2给出了2个方案在性能方面的对比分析.首先,2个方案都能进行模糊关键字搜索,而文献[11]在此基础上还能够进行可验证搜索.但本文方案支持多关键字搜索,而文献[11]只能进行单关键字搜索. Table 1 Efficiency Analysis Table 2 Performance Analysis 4.2 性能测试 本节主要分析各个影响因素对系统耗时的影响;然后针对不同的影响因素,设计测试数据进行性能测试.该系统的测试指标可分为:文件的大小、文件对应的关键字个数和文件的数量.根据这3类测试指标的划分,设定3种测试数据.第1组数据主要用于测试文件大小对该系统性能的影响,所以需要设定固定数量的文件和每个文件所拥有的关键字个数;第2组数据主要用于测试文件拥有的关键字个数对系统性能的影响,因而需要提前设定文件的数量以及文件的大小;第3组数据主要用于测试系统中文件的数量对其性能的影响,也要将文件的大小固定在一定区间内,而且每个文件所拥有的关键字个数相同. 定义完测试数据后,要在模型系统中测试每一组数据在系统中的表现.影响系统耗时的主要操作分为:构建索引以及陷门、加密索引以及陷门、搜索.所以进行数据测试时,需要分别记录各指标对这些操作耗时的影响.现实应用中,模型系统中的客户端和服务器端分别在2台独立的计算机上运行,主机需要装载Windows 7旗舰版,内存一般为4 GB.性能测试实验中,仅用1台计算机模拟该系统.记录的结果都是每组数据10次运行后的结果的平均值. 实验1. 测试文件的大小对系统耗时的影响. 按文件大小所在区间分组,将测试数据分为4类,分别记为A类文件、B类文件、C类文件、D类文件,A类文件中文件大小为1~50 KB,B类文件中文件大小为100~300 KB,C类文件中文件大小为400~500 KB,D类文件中文件的大小为1 000~2 000 KB的值.这4类文件中都包含500个文件,且每个文件都包含4个关键字.该模块测试结果如图7所示: Fig. 7 Influence of file size图7 文件大小的影响 从图7可以看出,文件体积越大系统耗时越多.文件的大小对系统搜索过程几乎没有什么影响. 实验2. 测试文件的数量对系统耗时的影响. 按照文件的数量将实验的数据分为5组,第1组含有500个文件,第2组有1 000个文件,第3个有1 500个文件,第4组有2 000个文件,第5组有2 500个文件.每组文件集合中各文件的大小均在50~100 KB,而且每个文件所对应的关键字个数都为4.执行文件的上传操作,整理并分析每组操作的耗时,如图8所示: Fig. 8 Influence of file number图8 文件数量的影响 文件数量对加密过程和搜索过程耗时的影响如图8所示,随着文件数量的增多,系统在生成文件密文阶段所耗费的时间就越多,同样系统在搜索过程耗时也就越多. 实验3. 测试单个文件所对应的关键字个数对系统的影响. 按每个文件包含的关键字个数将实验数据分为4组,第1组数据中单个文件对应的关键字数量为5,第2组数据中单个文件对应的关键字数量为10,第3组数据中单个文件对应的关键字数量为15,第4组中单个文件对应的关键字数量为20.每组数据中一共包括100个文件,其中每个文件的大小都在50~100 KB之间.该实验结果分析如图9所示: Fig. 9 Influence of keyword number图9 关键字个数的影响 从图9可以看出,随着每个文件对应的关键字数量的增多,系统在生成安全索引阶段和搜索阶段的耗时就会增多.但通过对图中实验结果的详细分析可知,当关键字个数由10个变为15个时,系统对于搜索阶段的耗时仅由175 ms增长到205 ms.所以系统搜索耗时的增长幅度相对于关键字的增长幅度来说是比较小的.因而我们说文件对应的关键字个数对系统搜索阶段耗费的时间影响是可以忽略的. 本文深入系统地研究了国内外的可搜索加密机制,总结各方案的优缺点,并进一步研究了布隆过滤器以及位置敏感Hash函数等相关理论,提出面向多关键字的模糊密文搜索方案. 面向多关键字的模糊密文搜索方案使用布隆过滤器和位置敏感Hash函数技术,能够有效实现密文的多关键字的模糊搜索.利用对偶编码函数将关键字转换成向量,实现关键字的内积运算.在安全性方面,通过攻击性游戏,模拟用户和服务器之间的交互,并利用参数的随机性,证明该方法是选择关键字攻击安全的.因此,本方案具有很强的理论与实践意义. [1]Song D, Wagner D, Perrig A. Practical techniques for searches on encrypted data[C] //Proc 2000 IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2000: 44-55 [2]Chang Y C, Mitzenmacher M. Privacy preserving keyword searches on remote encrypted data[C] //Proc of Applied Cryptography and Network Security. Berlin: Springer, 2005: 442-455 [3]Dong C, Russello G, Dulay N. Shared and Searchable Encrypted Data for Untrusted Servers[M]. Berlin: Springer, 2008: 127-143 [4]Revathy B, Anbumani A, Ravishankar M. Enabling secure and efficient keyword ranked search over encrypted data in the cloud[J]. International Journal of Recent Advances in Science & Engineering, 2015, 1(1): 28-32 [5]Cao N, Wang C, Li M, et al. Privacy-preserving multi-keyword ranked search over encrypted cloud data[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(1): 222-233 [6]Xia Zhihua, Wang Xinhui, Sun Xingming, et al. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data[J]. IEEE Trans on Parallel and Distributed Systems, 2016, 27(2): 340-352 [7]Bringer J, Chabanne H, Kindarji B. Error-tolerant searchable encryption[C] //Proc of the IEEE Int Conf on Communications. Piscataway, NJ: IEEE, 2009: 1-6 [8]Van Liesdonk P, Sedghi S, Doumen J, et al. Computationally efficient searchable symmetric encryption[C] //Proc of Secure Data Management. Berlin: Springer, 2010: 87-100 [9]Li J, Wang Q, Wang C, et al. Fuzzy keyword search over encrypted data in cloud computing[C] //Proc of the IEEE on INFOCOM. Piscataway, NJ: IEEE, 2010: 1-5 [10]Zhou Wei, Liu Lixi, Jing He, et al.K-gram based fuzzy keyword search over encrypted cloud computing[J]. Journal of Software Engineering and Applications, 2013, 6: 29-32 [11]Wang Jianfeng, Ma Hua, Tang Qiang, et al. Efficient verifiable fuzzy keyword search over encrypted data in cloud computing[J]. Computer Science and Information System, 2013, 10(2): 667-684 [12]Indyk P, Motwani R. Approximate nearest neighbors: Towards removing the curse of dimensionality[C] //Proc of the 13th Annual ACM Symp on Theory of Computing. New York: ACM, 1998: 604-613 [13]Datar M, Immorlica N, Indyk P, et al. Locality-sensitive Hashing scheme based onp-stable distributions[C] //Proc of the 12th Annual Symp on Computational Geometry. New York: ACM, 2004: 253-262 [14]Bloom B H. Space/time trade-offs in Hash coding with allowable errors[J]. Communications of the ACM, 1970, 13(7): 422-426 [15]Zhang Zhen, Dai Guanzhong, Liu Hang, et al. Safe and resumable secret key management mechanism based on database encryption[J]. Computer Measurement and Control, 2008, 16(10): 1469-1471 (in Chinese)(张贞, 戴冠中, 刘航, 等. 一种基于数据库加密的安全可恢复密钥管理机制[J]. 计算机测量与控制, 2008, 16(10): 1469-1471) [16]Zhang Chuanrong, Yin Zhonghai, Xiao Guozhen. Authenticated encryption schemes without using Hash and redundancy functions[J]. Acta Electronica Sinica, 2006, 34(5): 874-877(in Chinese)(张串绒, 尹忠海, 肖国镇. 不使用Hash和Redundancy函数的认证加密方案[J]. 电子学报, 2006, 34(5): 874-877) Wang Kaixuan, born in 1992. Master in Software College, Northeastern University. Her main research interest is searchable encryption. Li Yuxi, born in 1990. PhD candidate. Her main research interest is secure cloud storage (eliyuxi@gmail.com). Zhou Fucai, born in 1964. PhD, professor and PhD supervisor. Senior member of CCF. His main research interests include cryptography and network security, trusted computing, and critical technology in electronic commerence. Wang Quanqi, born in 1992. Master. His main research interest is mobile computing (wqq_7622@126.com). Multi-Keyword Fuzzy Search over Encrypted Data Wang Kaixuan, Li Yuxi, Zhou Fucai, and Wang Quanqi (SoftwareCollege,NortheasternUniversity,Shenyang110819) Cloud computing is one of the most important and promising technologies. Data owners can outsource their sensitive data in a cloud and retrieve them whenever and wherever they want. But for protecting data privacy, sensitive data have to be encrypted before storing, which abandons traditional data utilization based on plaintext keyword search. Around the multi-keyword fuzzy matching and data security protection problems, we propose a multi-keyword fuzzy search method on the encrypted data. Based on the Bloom filter, our scheme uses dual coding function and the position sensitive Hash function to build file index. In the meantime, it uses the distance recoverable encryption arithmetic to encrypt the file index, consequently achieving the function which is facing the multi-keyword to fuzzy search over the encrypted data. Meanwhile, the scheme does not need to set index storage space in advance, which greatly reduces the complexity of the search. Compared with the existing solutions, the scheme does not need predefined dictionary library which lowers the storage overhead in consequence. Experimental analysis and security analysis show that the proposed scheme not only achieves the multi-keyword fuzzy search over the encrypted data, and guarantees the confidentiality and privacy. cloud storage; Bloom filter (BF); searchable encryption; position sensitive Hash function; multi-keyword fuzzy search 2015-12-21; 2016-10-10 国家科技重大专项基金项目(2013ZX03002006);辽宁省科技攻关项目(2013217004);中央高校基本科研业务费专项资金(N130317002);沈阳市科技基金项目(F14-231-1-08) This work was supported by the Major National Science and Technology Program (2013ZX03002006), the Liaoning Province Science and Technology Project (2013217004), the Fundamental Research Funds for the Central Universities (N130317002), and the Shenyang Science and Technology Project (F14-231-1-08). 周福才(fczhou@mail.neu.edu.cn) TP309.2
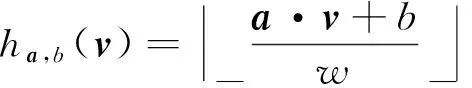
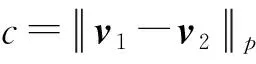
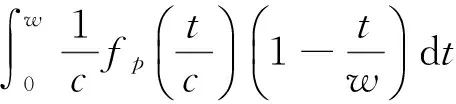

2 多关键字模糊密文搜索方案
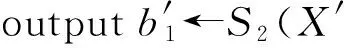

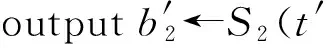
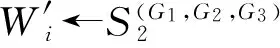
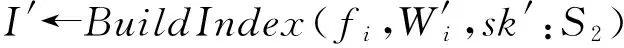
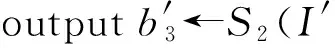
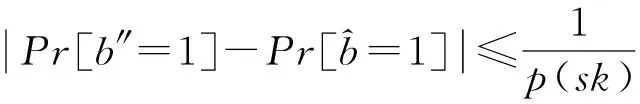
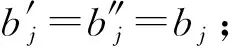

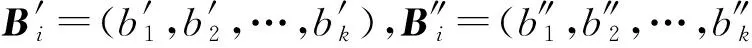
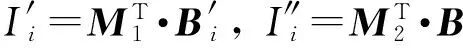
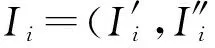
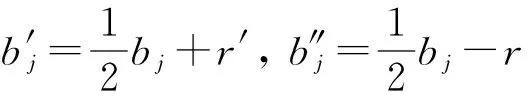

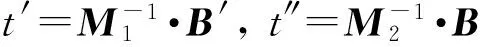
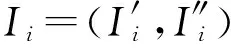
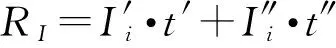

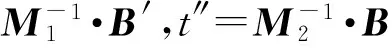
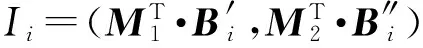
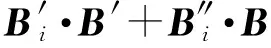
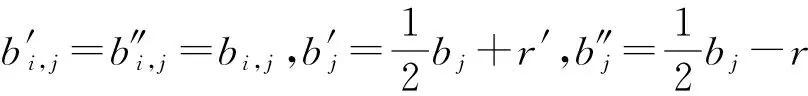

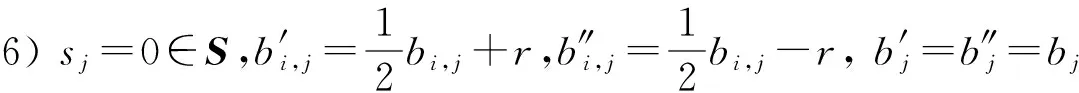
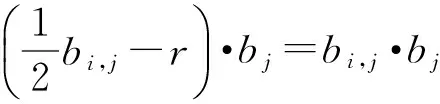
3 方案分析


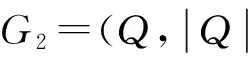

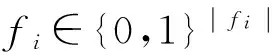
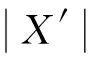

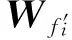
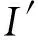

4 测试分析


5 总 结




