基于深度特征的目标跟踪算法
2017-02-21张毅锋崔锦实
程 旭 张毅锋 刘 袁 崔锦实 周 琳
(1东南大学信息科学与工程学院, 南京 210096)(2南京船舶雷达研究所, 南京 210003)(3北京大学机器感知与智能教育部重点实验室, 北京 100871)
基于深度特征的目标跟踪算法
程 旭1,2,3张毅锋1,3刘 袁1,3崔锦实3周 琳1
(1东南大学信息科学与工程学院, 南京 210096)(2南京船舶雷达研究所, 南京 210003)(3北京大学机器感知与智能教育部重点实验室, 北京 100871)
针对跟踪过程中运动目标的鲁棒性问题,提出了一种基于深度特征的跟踪算法.首先,利用仿射变换对每一帧图像进行归一化处理.然后,利用深度去噪自编码器提取归一化图像的特征.由于提取的特征维数巨大,为了提高计算效率,提出了一种高效的基于稀疏表示的降维方法,通过投影矩阵将高维特征投影到低维空间,进而结合粒子滤波方法完成目标跟踪.最后,将初始帧的目标信息融入到目标表观更新过程中,降低了跟踪过程中目标发生漂移的风险.实验结果表明,所提出的视觉跟踪算法在6段视频序列上获得了较高的准确度,能够在遮挡、光照变化、尺度变化和目标快速运动的条件下稳定地跟踪目标.
视觉跟踪;深度学习;稀疏表示;模板更新
传统的目标跟踪算法大致可分为基于生成式模型的跟踪方法和基于判别式模型的跟踪方法两大类.前者将目标的第1帧信息作为模板,在跟踪过程中,将与目标模板匹配度最高的候选状态作为跟踪结果;这类方法包括增量视觉跟踪算法[1]、Fragment法[2]、视觉跟踪分解法[3]等;其缺点在于不能充分利用目标的背景信息.后者将跟踪作为二元分类问题,利用背景信息把目标从背景中分离出来;这类方法包括多示例学习法(MIL)[4-5]、跟踪学习检测算法(TLD)[6]、多任务跟踪法(MTT)[7]等,其跟踪性能优于前者.最近,Mei等[8-9]将稀疏编码理论引入到目标跟踪领域;Zhong等[10-11]在稀疏表示的框架下采用生成式模型和判别式模型相结合的方法来提升跟踪性能.上述跟踪算法大多采用人工设计的特征 (如直方图、HOG描述子等).然而,实验证明人工设计的特征不适合于所有目标.深度学习的发展为自动学习特征提供了可能.文献[12]利用辅助数据来离线训练深度网络,然后将离线训练的模型迁移到在线目标跟踪过程;文献[13]使用深度去噪自编码器(SDAE)[14]从大量辅助图像中学习通用的特征知识;文献[15]利用2层卷积神经网络(CNN)来应对复杂的目标表观变化.
本文提出了一种基于深度特征的视觉跟踪算法(DFT).首先,从大量图像中训练深度去噪自编码器,并利用其提取图像中的目标信息;然后,采用一种基于稀疏表示的降维方法,从大量的特征维数中选择出少量高效的特征维数;最后,将初始帧的目标信息融入到目标表观更新过程中,以降低目标发生漂移的风险.实验结果验证了DFT算法的高效性.
1 基于深度特征的视觉跟踪
1.1 特征提取
SDAE是指从几百万张图像中集中学习、重构原始图像,通过优化重构误差来提高深度学习网络对噪声的鲁棒性[15].它在无监督学习的框架下利用贪婪算法来训练多个自编码器.通过学习,将底层特征抽象为高层特征.SDAE由编码器和解编码器构成,是一种非线性多层网络结构,每层中包含有大量的网络节点及其相应的参数.本文利用离线训练的SDAE来提取视频中的目标特征,以实现在线跟踪.图1为DFT算法的实现流程图.
1.2 特征选择
深度学习的特征维数巨大,能够高效表示目标的特征维数却是少量稀疏的,这些稀疏的特征维数与目标有很大的相关性.利用SDAE对图像进行特征提取时,会产生包含有大量噪声或者与目标不相关的背景信息.网络底层的特征具有判别性,能够较好地刻画出目标类内的变化,高层的特征更具有语义的概念.基于以上考虑, 本文提出了一种高效的基于稀疏表示的降维方法, 利用其对SDAE提取的高维特征进行降维.

图1 DFT算法流程图
首先,利用一段视频序列的前10帧来构造字典.将前10帧的跟踪结果作为目标的正样本,在目标周围的背景区域随机采样n个样本作为背景模板.将每个采样图像变换成大小为32×32像素的图像,并将其拉直成列向量,通过SDAE后输出字典.构造的字典中包含目标模板和背景模板.字典中正负模板的构造过程如图2所示.
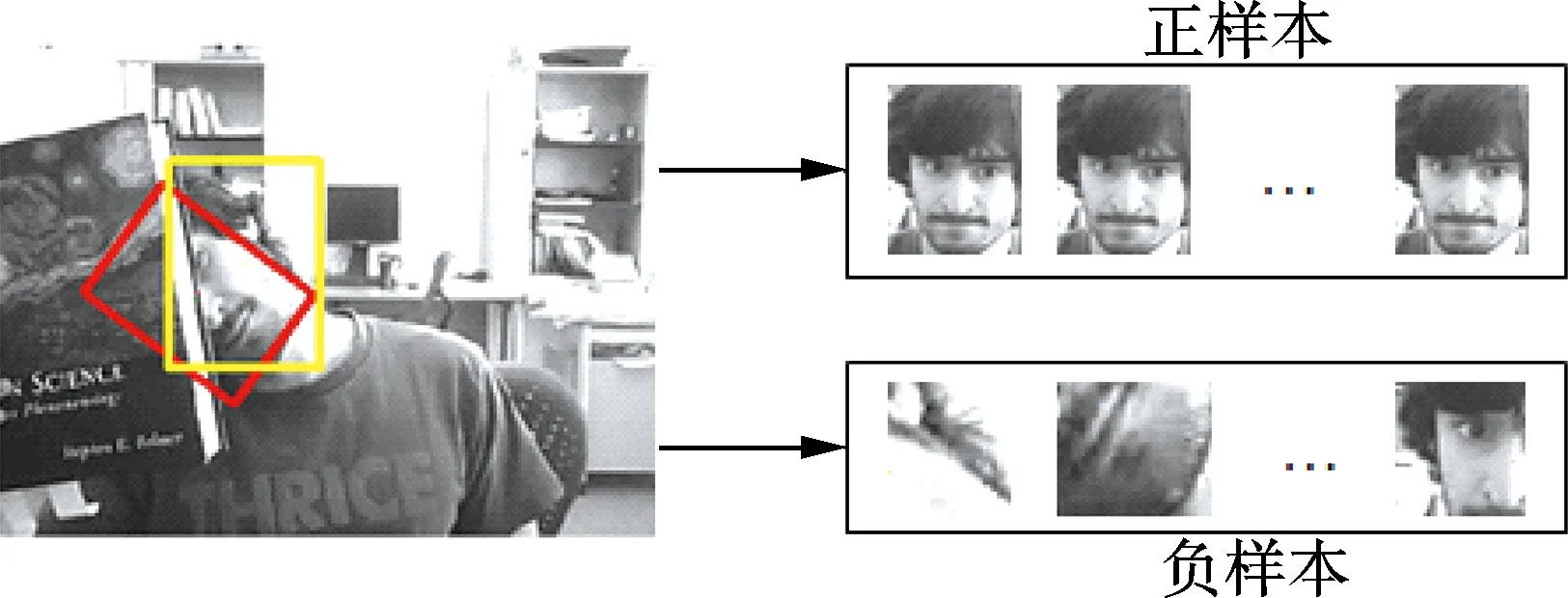
图2 字典中正负模板的构造过程
由于SDAE提取的图像特征是冗余的,本文采取稀疏表示的策略从海量信息中选择出有效的特征.特征选择的表达式为

(1)
式中,A∈RK×(m+n)为构造的字典,其中m和n分别为正、负模板个数,此处m=10,K为特征维数;s为稀疏系数向量;λ1为权重因子;p∈R(m+n)×1为A中每个原子的属性,+1表示原子中正模板属性,-1表示原子中负模板属性.
根据式(1)得到稀疏系数向量s,将s中的非零元素作为特征选择的依据.投影矩阵S中第i行第i列的元素Sii为
(2)
式中,si为稀疏系数向量s中的第i个元素.
利用式(2)将字典A和候选采样x投影到一个判别式空间上,实现对目标特征的选择.降维后的字典A′和候选状态x′可表示为
A′=SA,x′=Sx
(3)
利用式(3)便可从K维特征中选择出高效的判别特征.
1.3 目标跟踪
本文在粒子滤波框架下完成视觉跟踪的目标运动状态估计.通过一系列的目标观测值O1:t={o1,o2,…,ot}来对当前的目标状态做出估计,其目标状态xt的后验概率表达式为
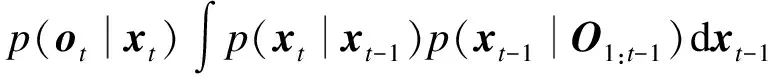
(4)
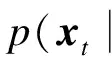
(5)
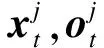
1.4 模板更新
本文提出了一种高效的目标模板更新策略来提高跟踪的鲁棒性.更新包括整个网络参数的更新和原始特征的更新.每运行10帧图像更新一次字典和目标模板.模板更新模型为
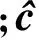
2 实验与结果分析
2.1 实验设置
本文算法在Matlab 2010b上实现,计算机配置为Intel Core 2 Duo 2.93 GHz,内存为2.96 GB.实验所选用的数据库中包含了挑战性的场景,如目标遮挡、光照变化、尺度变化以及目标快速运动.选取了7种基于浅层特征的主流跟踪算法,即IVT算法[1]、FragT算法[2]、VTD算法[3]、WMIL算法[5]、TLD算法[6]、APGL1算法[9]和SCM算法[10],并将本文算法与这7种算法进行了比较.
将一幅图像仿射投影为32×32像素的图像,并进行归一化处理.然后,把图像拉直成1 024维向量,每一维对应于图像中的一个像素,并将其作为编码器中第1层的1 024个网络单元.在网络的隐藏层中,每个编码器的网络单元都为输入层网络单元的一半,直到隐藏层网络单元数减为256.最后,在网络中添加了超完备滤波层,从而更好地提取图像的结构信息.
2.2 定量分析

表1 跟踪成功率
2.3 定性分析
图3给出了目标发生遮挡时不同算法的跟踪结果.图中,q为视频序列的帧数.由图可知,在Faceocc1序列中,目标于静态背景下运动,大多数算法都能够成功地跟踪目标.在Faceocc2序列中,大多数算法都产生了不同程度的漂移,部分算法甚至丢失了目标.在Caviar序列中,TLD算法在遇到遮挡、相似目标干扰时会逐渐丢失目标,WMIL算法由于训练器中混入了背景噪声而导致跟踪失败.本文算法则能够正确地跟踪3段序列的目标.
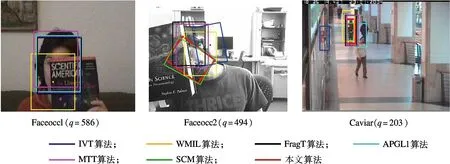
图3 目标发生遮挡时不同算法的跟踪结果
图4给出了光照和尺度变化下不同算法的跟踪结果.由图可知,在Singer1序列中,光照强度剧烈地变亮且目标尺度也发生了变化,WMIL算法、FragT算法和TLD算法跟踪失败;本文算法、VTD算法和SCM算法则能够适应尺度的变化而成功跟踪目标.在DavidIndoor序列中,本文算法、SCM算法、TLD算法和IVT算法能够成功跟踪目标,但都出现了不同程度的漂移.在Car4序列中,除WMIL算法和FragT算法外,其他算法都能够跟踪目标,但都伴随有不同程度的跟踪误差.

图4 光照和尺度变化下不同算法的跟踪结果
2.4 计算复杂度
SDAE为非线性的网络结构,每层中包含大量的节点和参数,使其在网络训练、参数更新以及在线特征提取方面耗时较大.为了提高运行速度,可在训练和跟踪过程中采用并行计算和图形处理单元加速技术.本文算法中采用了并行计算,运行速度得到了较大的提升.在6段视频上比较了IVT算法、WMIL算法、FragT算法、APGL1算法、MTT算法、TLD算法、SCM算法和本文算法的时间复杂度.结果显示,本文算法平均每秒钟能处理8帧视频图像,IVT算法的运算速度最快,平均每秒钟运行24帧图像.
3 结语
本文提出了一种基于深度学习的跟踪算法,利用深度学习实现对目标表观的高效表示,将离线阶段训练得到的信息融入到在线跟踪过程中.采用稀疏策略对高维特征进行降维,进一步提高了计算效率,并通过定期更新深度网络参数和目标的表观模型来及时捕获目标表观的变化,提高了对目标表观变化的适应性.最后,在粒子滤波算法框架下完成对目标的定位.遮挡、光照变化、尺度变化和目标快速运动条件下的目标跟踪实验结果证实了本文算法的高效性.但该算法也存在不足:在复杂场景下目标运动发生漂移时,该算法不能够及时纠正目标的漂移,导致跟踪失败;SDAE是利用大量图像数据离线训练得到的,在跟踪过程中,不合适的知识迁移将降低目标跟踪的精度,甚至使目标丢失.这些问题都有待于进一步的研究.
References)
[1]Ross D A, Lim J, Lin R S, et al. Incremental learning for robust visual tracking[J].InternationalJournalofComputerVision, 2008, 77(1): 125-141. DOI:10.1007/s11263-007-0075-7.
[2]Adam A, Rivlin E, Shimshoni I. Robust fragments-based tracking using the integral histogram [C]//2006IEEEConferenceonComputerVisionandPatternRecognition. New York, USA, 2006: 798-805.
[3]Kwon J, Lee K M. Visual tracking decomposition [C]//2010IEEEConferenceonComputerVisionandPatternRecognition. San Francisco, CA, USA, 2010: 1269-1276.
[4]Babenko B, Yang M H, Belongie S. Visual tracking with online multiple instance learning [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011, 33(8): 1619-1632. DOI:10.1109/TPAMI.2010.226.
[5]Zhang K, Song H. Real-time visual tracking via online weighted multiple instance learning[J].PatternRecognition, 2013, 46(1): 397-411. DOI:10.1016/j.patcog.2012.07.013.
[6]Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012, 34(7): 1409-1422. DOI:10.1109/TPAMI.2011.239.
[7]Zhang T, Ghanem B, Liu S, et al. Robust visual tracking via structured multi-task sparse learning [J].InternationalJournalofComputerVision, 2013, 101(2): 367-383. DOI:10.1007/s11263-012-0582-z.
[8]Mei X, Ling H. Robust visual tracking and vehicle classification via sparse representation [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011, 33(11): 2259-2272. DOI:10.1109/TPAMI.2011.66.
[9]Bao C, Wu Y, Ling H, et al. Real time robust L1 tracker using accelerated proximal gradient approach [C]//2012IEEEConferenceonComputerVisionandPatternRecognition. Providence, Rhode Island, USA, 2012: 1830-1837.
[10]Zhong W, Lu H, Yang M H. Robust object tracking via sparse collaborative appearance model [J].IEEETransactionsonImageProcessing, 2014, 23(5): 2356-2368. DOI:10.1109/TIP.2014.2313227.
[11]Cheng X, Li N, Zhou T, et al. Object tracking via collaborative multi-task learning and appearance model updating [J].AppliedSoftComputing, 2015, 31: 81-90. DOI:10.1016/j.asoc.2015.03.002.
[12]Li H, Li Y, Porikli F. Robust online visual tracking with a single convolutional neural network [C]//2014AsianConferenceonComputerVision. Singapore, 2014: 194-209. DOI:10.1007/978-3-319-16814-2_13.
[13]Wang N, Yeung D Y. Learning a deep compact image representation for visual tracking [C]//2013AdvancesinNeuralInformationProcessingSystems. Lake Tahoe, CA,USA, 2013: 809-817.
[14]Wang N, Li S, Gupta A, et al. Transferring rich feature hierarchies for robust visual tracking [EB/OL]. (2015-04-23)[2016-02-19]. https://arxiv.org/abs/1501.04587.
[15]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J].Science, 2006, 313(5786): 504-507. DOI:10.1126/science.1127647.
Object tracking algorithm based on deep feature
Cheng Xu1,2,3Zhang Yifeng1,3Liu Yuan1,3Cui Jinshi3Zhou Lin1
(1School of Information Science and Engineering, Southeast University, Nanjing 210096, China) (2Nanjing Marine Radar Institute, Nanjing 210003, China) (3Key Laboratory of Machine Perception of Ministry of Education, Peking University, Beijing 100871, China)
To solve the robustness problem of the motion object in the tracking process, a tracking algorithm based on deep feature is proposed. First, each frame in the video is normalized by affine transformation. Then, the object feature is extracted from the normalized image by the stacked denoising autoencoder. Because of the large dimensions of deep feature, to improve the computational efficiency, an effective dimension reduction method based on sparse representation is presented. The high dimensional features are projected into the low dimensional space by the projection matrix. The object tracking is achieved by combing the particle filter algorithm. Finally, the object information of the first frame is integrated into the updating process of the object appearance to reduce the risk of object drift during the tracking process. The experimental results show that the proposed tracking algorithm exhibits a high degree of accuracy in six video sequences, and it can stably track the object under the circumstance of occlusion, illumination change, scale variation and fast motion.
visual tracking; deep learning; sparse representation; template updating
第47卷第1期2017年1月 东南大学学报(自然科学版)JOURNALOFSOUTHEASTUNIVERSITY(NaturalScienceEdition) Vol.47No.1Jan.2017DOI:10.3969/j.issn.1001-0505.2017.01.001
2016-06-27. 作者简介:程旭(1983—),男,博士; 张毅锋(联系人),男,博士,副教授, yfz@seu.edu.cn.
国家自然科学基金资助项目(61571106)、江苏省自然科学基金资助项目(BK20151102)、北京大学机器感知与智能教育部重点实验室开放课题资助项目(K-2016-03).
程旭,张毅锋,刘袁,等.基于深度特征的目标跟踪算法[J].东南大学学报(自然科学版),2017,47(1):1-5.
10.3969/j.issn.1001-0505.2017.01.001.
TP391
A
1001-0505(2017)01-0001-05
