基于多线程的分布式数据同步方法研究
2017-02-21王丽娜孙艳华山东协和学院计算机学院
王丽娜 孙艳华/山东协和学院计算机学院
基于多线程的分布式数据同步方法研究
王丽娜 孙艳华/山东协和学院计算机学院
在大数据时代,单一数据存储方式早已不能满足大数据、云数据的存储处理,本文提出一种分布式数据的同步方法,具体来说是涉及一种用于分布式环境下的基于多线程的数据同步方法,其特征在于数据能够在不占用当前服务资源的情况下进行高效传输。
多线程;数据同步;分布式
在分布式系统架构中,当用户界面需要操作或展示具体的业务数据信息时只需要到相应的分布式终端进行查询,为网络传输减轻负担的同时提高总体系统效率。在某个终端数据更新之后,为保证数据的一致性,差异数据要同步到其它各个终端服务器。分布式数据存储主要需解决的就是各终端系统服务器之间的数据一致性问题,根据时间特征性数据同步可分为实时数据同步和间歇性数据同步。分布式数据同步方法中数据传输安全性和数据同步效率是验证方案可行性的两大因素,为降低数据传输过程中的风险和提高数据传输效率,发明一种高效且安全的分布式数据同步方法是有必要的。
1.数据分布式原理
现今的分布式数据存储大多依靠产品或者服务本身对分布式环境下数据库服务器的数据进行同步,在互联网应用中比较通用的数据传输方式为基于WebService的数据同步机制。WebService实现数据同步原理如图1所示, SOAP消息文本数据携带较多的格式数据,且此种方式必须依托某项特定的服务或者产品,无论是在传输过程中还是在终端接受处理数据都会增加系统资源开销,影响传输效率的同时风险也随之增大。

图1 分布式统数据同步原理
在当前技术领域下怎样使数据同步更加自动化、提高数据传输安全性及效率是数据同步方案的度量标准。为解决以上所述问题,本发明提出多线程同步机制运用在分布式数据同步方案中,安全性和效率性同时得到保证。
2.基于多线程分布式数据同步方法架构
利用多线程同步机制使各分布式终端服务器之间的单个同步任务能够独立运行。在基于多线程分布式数据同步方法架构中,包括四个模块:差异数据捕获、触发创建同步线程、差异数据处理、数据持久化。
差异数据捕获,捕获处理在终端分支服务器端对业务数据操作产生的差异数据。在本发明方法的用户分析模块设有监听器与触发器,用于监听用户的请求行为,终端用户发出修改请求时被监听到,此时触发程序将会触发线程工厂(线程管理)进行数据同步线程的创建工作。与此将对用户的请求进行行为分析,初步得出在当前分布式终端所产生的同步数据包。
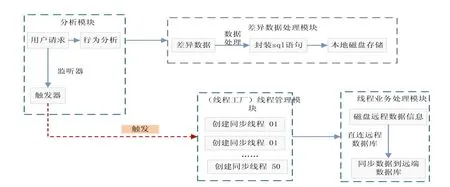
图2 基于多线程分布式数据同步方法处理模块
在捕获差异数据模块监听到用户请求时,主服务会触发线程工厂创建同步线程。在线程工厂创建线程之前由线程计数器判断当前服务器同步线程数,当线程数达到最大限额时会拒绝创建线程并提示当前任务繁忙请稍等。若线程数没有到达最大限额,根据线程数成阶梯状进行判断,如图2所示,线程数与等待时间的阶梯关系清晰可见。线程工厂在创建线程时会根据当前业务流程的需要创建符合该业务的同步线程,并根据主服务所传的数据类型将数据分配给对应的业务同步线程。
差异数据包装和整理,对所捕获的差异数据进行处理,产生格式化差异数据表或者能够直接运行的SQL语句。在本发明方法的差异数据处理模块完成对同步数据包的处理,当前运行的主服务响应用户请求,同时所产生的差异数据会存储在临时数据集中。业务同步线程对数据集中的数据逐条分析并将其转化为对应可执行的SQL语句,为保证数据在后续的传输过程中不出现丢失将处理后的数据包持久化到本地磁盘存储。在本地磁盘文件中存储了所需同步终端的数据库配置信息以及整理后的同步数据SQL。
当同步业务线程本地持久化数据之后就会脱离当前主服务的控制,单独运行,随后读取持久化到磁盘中的文件数据,根据所存储的各终端数据库信息以直连的方式连接到各终端数据库。数据传输过程中若出现异常,业务同步线程会延迟一段时间重新启动,待到数据全部传输完毕,并且没有出现异常时,业务同步线程会自动销毁本地磁盘数据,然后完成数据同步工作。
3.基于多线程分布式数据同步方法架构实施
本文提出的基于多线程分布式数据同步方法是针对由于网络、地域或数据量庞大等因素致使系统分布式部署的保持数据一致解决方法。其中任一分布式终端都可以作为发起数据同步请求的主服务.
在用户发起请求之前每个分布式终端的本地磁盘都要具有各终端服务系统的数据库配置信息,任一终端用户发起增加、修改或删除请求时,主服务负责响应,在主服务线程开启时系统会分配其一个临时数据集,所述临时数据集是存储用户一次操作请求所产生的异动数据。监听与触发程序负责将分析模块与线程管理模块关联,用户操作触发创建业务同步线程。
为保证业务同步线程在传输数据过程中数据完整性不丢失,将临时数据集中的数据本地磁盘存储,业务同步线程会将数据集中的数据进行逐条分析,转化为对应的可执行SQL语句并持久化到当前服务器磁盘中。若此时其它分布式终端还有数据同步请求,在当前业务同步线程没有脱离主服务控制之前,其它数据同步请求需要排队等待。在业务同步线程持久化数据完毕后将脱离服务控制,随后独立运行读取持久化到磁盘中的各终端数据库服务器配置信息。
4.结论
在当今大数据时代,数据的处理方式至关重要,数据的分布式处理方式是大数据处理的主要方式,分布式环境下数据的同步问题是当前研究的主要问题,基于多线程的分布式数据同步方法是在前人的基础上提出一种方式,还有待进一步研究。
[1]朱建华.分布式数据同步采集系统的设计与实现[D].安徽大学,2014.
[2]董立岩,毛锐,余谊诚,王利民,黄乐,殷涵.基于分布式多服务系统的数据同步方法[J].吉林大学学报,2011(4).
[3]卢宇,龚忠友,吴进营,苏伟达,朱丽,吴允平,蔡声镇.基于WEB服务的分布式异构数据同步设计[J].微计算机应用.2011(12).
