基于Hadoop的VPN访问日志分析平台的研究与实现
2017-01-09杨家桂陈劲松王平水
武 凌, 杨家桂, 陈劲松, 王平水
(安徽财经大学 管理科学与工程学院, 安徽 蚌埠 233030)
基于Hadoop的VPN访问日志分析平台的研究与实现
武 凌, 杨家桂, 陈劲松, 王平水
(安徽财经大学 管理科学与工程学院, 安徽 蚌埠 233030)
采用Hadoop分布式计算框架和数据仓库Hive构建一个日志分析平台,将VPN环境下不同系统或应用程序产生的多个相关的日志进行关联分析,以还原出通过VPN存取资源的轨迹行为,用以改善使用单机进行大量日志处理效率低下而且扩充性差的问题.平台产生的轨迹数据可以协助系统管理者找出数据外泄轨迹,了解资源是否被滥用,以及发现潜在的安全性威胁.
VPN; 日志; 审核跟踪; Hadoop; Hive
现今的信息化社会中,企业要维持日常运作,必须依赖各种通信软件与通信设备协同提供必要的信息服务.这些通信设施为便于管理,均会产生日志,让系统管理人员可由此得知该系统提供的特定服务的被存取与运作状态.对记录用户行为的日志的挖掘是越来越热门的研究方向[1].由于产生的日志信息越来越多,传统的依靠单一节点的计算能力已经不能满足需求.利用云计算和大数据技术,将消耗大量计算资源的复杂计算通过网络分布到多节点上计算的方式成了新的有效解决方案,Hadoop就是一个开发和运行处理大规模数据的软件平台.
传统的基于单机的日志分析处理的数据量很有限[2-3],如今Hadoop平台越来越多的应用在流量分析、日志分析等场景中,文献[4]设计了一种在分布式系统中基于Probe进行网络流量分析的机制,利用负载平衡机制让Hadoop集群中的每一个Slave节点使用flow-capture程序接收来自于nProbe的数据, 再利用MapReduce进行分析与处理.随着搜索引擎的广泛使用, 用户的查询日志受到较多的关注,Park[5]通过对韩国著名搜索引擎网站的搜索日志进行分析来研究用户的检索行为, 杨文峰[6]等人构建了一个更有价值的用户检索模型, 根据用户检索的位置和时间, 并运用马尔科夫模型来预测用户下一次的搜索模式.文献[7] 实现了一种基于Hadoop的海量日志数据处理模型, 将该模型应用于搜索引擎海量日志文件处理. 文献[8-9]都是采用了Hadoop和Hive分别设计了web日志分析系统、邮件日志分析系统. 文献[10]基于Hadoop和数据仓库平台, 通过改进K-means聚类算法对用户行为进行研究.
许多企业都架设了虚拟专用网VPN(Virtual Private Network) 服务器,让企业员工可由外部因特网连至企业内部网络.观察一般VPN Server产生的日志,其中较为重要的字段包括写入日志的日期、时间、用户名称、用户外部IP地址、用户被分配的内部IP地址、连接期间接收Bytes、连接期间送出Bytes、用户计算机名称等.通过上述字段,系统管理人员虽然可以知道在某个时间点是哪一个用户账号、用了哪一台计算机、由哪个外部IP地址连上了VPN Server,又通过VPN Server取得了哪个内部IP地址,还有本次连接共传输了多少数据量等.但仅靠VPN Server日志提供的信息却无法告诉系统管理人员这位用户在通过VPN Server进入到企业内网后,究竟存取了哪些计算机,又使用了哪些服务.因此系统管理人员还必须再通过网络数据包捕获工具如Sniffer、WireShark等,或是NetFlow工具如内建NetFlow的网络设备、ntop/nProbe、flow-tools等,来观察使用者在进入到内网后存取网络服务的行为.
如果要找出跨信息设备的系统性问题,就应该把这些设备或应用程序的相关日志集合起来,然后对这些日志进行关联与分析,这样才能找出问题并进行改善.同样,为强化企业信息安全与管理,如果想要了解员工远程通过VPN对企业资源的存取状况,自然也应该将多个相关的日志进行关联分析,从而得到完整的轨迹数据.所以必须把VPN Server日志与被捕获的数据包数据一起关联比对,才能将使用者的存取轨迹完整地呈现出来,如图1所示.
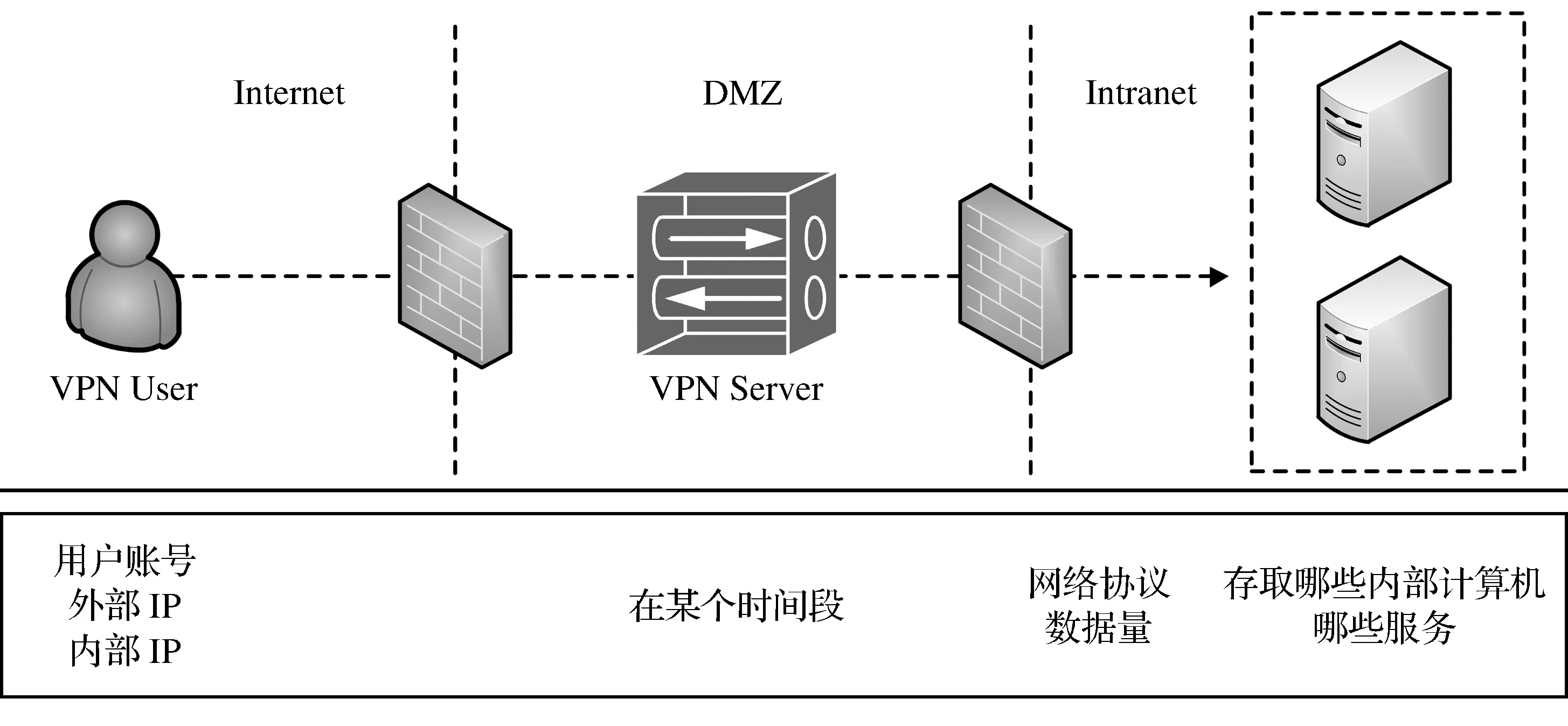
图1 轨迹数据各字段
因为通过数据包捕获工具产生的文件数据量较大(单日记录的文件大小可达到1~2 GB),如以单机处理,除了计算效率较差且无扩充的弹性之外,还有备份管理的问题必须考虑.因此在考虑了构建与维护成本、技术的适用性以及未来扩充的弹性等因素后,本文基于Hadoop的分布式计算架构设计了一个远程访问日志的分析模型,以协助管理者取得VPN用户的存取轨迹数据.
1 相关技术
1.1 数据包捕获技术
考虑到要将跨设备的异质性日志做关联整合,所以时间的一致性便成为关键.在捕获数据包方面,NetFlow是将一段时间的流量数据汇总累加,因此如果时间间隔过久,则将会造成不同日志间的数据对应错误,所以本文选择了tcpdump作为网络数据包捕获工具.tcpdump是一个很常用的工具,以Linux操作系统为例,在各发行版本中均附有tcpdump工具,而且搭配使用的数据包捕获链接库libpcap完整支持了源自BSD UNIX开发的BPF(BSD Packet Filter)功能.在运行时,BPF驱动程序必须将以太网卡切换至混杂模式,这样以太网卡驱动程序才会把在网络上收到的所有数据包复制一份给BPF驱动程序,BPF能根据各Filter不同的设定,把系统管理人员感兴趣的数据包筛选出来,并通过tcpdump输出结果.本文在实现时也是将BPF功能与tcpdump搭配使用,首先由BPF把来自于远程访问企业内网资源的数据包筛选出来再交给tcpdump处理,这样不但可以减轻tcpdump程序的负担,还可以减少日志文件的大小.
1.2 Hadoop与Hive
Hadoop是一个由通用计算设备组成,多设备上执行的分布式应用框架,它良好的性能和丰富的功能,为云计算的使用提供了较好的平台系统.Hadoop平台是目前大多数大数据处理的技术基础,目前该技术已经发展成熟,并随之产生很多基于该平台的大数据处理工具.Hadoop 2.X架构由Hadoop Common、HDFS、YARN与MapReduce Version 2(MRv2)等四个模块构成:Hadoop Common类似于操作系统,提供Hadoop其他模块共享的基础性功能;HDFS是一种分布式文件系统,提供Hadoop系统数据存储的功能,具有低成本、容错、高数据传输率等特性;YARN提供了分布式计算的基础,负责集群的资源管理与任务调度等工作;MRv2是可以在YARN之上执行的一种分布式编程与计算框架.
Hive是为了在Hadoop分布式系统上对大量数据进行分析而设计的数据仓库工具,其操作所提供的语言是HiveQL (Hive Query Language),在Hadoop平台上运作时Hive会先将HiveQL指令转换为MapReduce程序后再执行.HiveQL与关系型数据库使用的结构化查询语言SQL的大部分指令都兼容,相对于学习MapReduce程序使用的Java语言,HiveQL的学习门槛相对较低.
1.3 VPN
VPN就是在安全性较低的公众网络上(如Internet)模拟出一个安全性与便利性等同于专用网的虚拟连接.VPN使用了隧道协议(Tunneling Protocol)与加解密的技术来达到虚拟连接的效果.可供实现VPN的技术众多,目前应用最广的是基于IP的VPN技术.
在实现方式上,典型的VPN部署形式大致可以分为两类:
(1) Remote Access VPN:可让VPN Client由远程连接到专用网的连接方式,例如让在公司外的业务人员通过Internet仍可安全的获取公司的网络资源;
(2) Site-to-Site (S2S) VPN: VPN设备对VPN设备的连接方式,例如让企业的总部与分公司之间经由Internet建立的安全连接.
在本文中,企业远程访问日志便是获取自Remote Access VPN系统.
2 基于Hadoop的远程访问日志分析模型
本文设计的远程访问日志分析模型以Hadoop分布式处理平台为核心,主要由以下四个模块组成,如图2所示.

图2 访问日志分析模型
(1) Hadoop Common:提供分布式作业共享的通信机制、数据库等.
(2) HDFS (Hadoop Distributed File System):负责数据存储,除具备容错、数据一致性等特性外,适合大量数据的事后批处理分析,具有一次写入多次读取的特性.
(3) YARN (Yet Another Resource Negotiator) 与MRv2 (MapReduce Version 2):负责数据的分析与处理,可依据不同的分析需求,使用不同的算法模块.
(4) Hive:利用数据仓库工具Hive对存储在分布式文件系统上的数据进行处理,可以避免撰写复杂的分布式计算程序.
VPN Server产生的日志与捕获的数据包数据为模型的输入,轨迹数据为模型的输出,系统处理流程分为四个阶段:
(1) 数据搜集:搜集与保存本系统的输入数据.
① VPN日志数据:VPN日志由Microsoft Windows Server内建的路由及远程访问服务RRAS(Routing and Remote Access Service)产生,文件的数据量虽然不大,但字段多达60几个,且组合复杂,一次完整的VPN连接可能由1~4个不等的记录组成,我们通过Microsoft LogParser为基础撰写日志字段预处理程序,将VPN日志的必要字段筛选出来以减低后续与数据包进行关联处理的复杂度.② Packet Header数据:通过数据包捕获指令来取得.
(2) 数据输入:将被分析的VPN日志数据与Packet Header数据文件,在每天的特定时间点自动上传至平台的分布式文件系统上存储.
(3) 数据处理:由分布式计算模块对之前上传的数据进行处理与分析,并将处理结果直接显示在屏幕或存储在文件系统上.为简化分布式计算程序开发的复杂度,我们使用数据仓库工具Hive来进行开发.使用Hive的处理流程是在Hive中创建数据库及表,将数据导入至HDFS文件系统,然后撰写HiveQL程序并提交给Hive系统执行,Hive会将HiveQL程序转译为Map与Reduce分布式计算程序,再交给MapReduce计算框架执行,对位于HDFS的VPN日志与Packet Header数据进行关联与分析.
(4) 输出报表:将上一阶段分析的结果汇总成为管理报表,提供给管理者使用.
3 基于Hadoop的远程访问日志分析平台
3.1 实现环境
实现环境的网络架构采用一对防火墙的分离屏蔽式子网与双接口主机(Split-Screened Subnet with Dual-Homed Host),如图3所示.一台为外部防火墙,负责连接Internet与受屏蔽的子网;另一台则为内部防火墙,负责连接受屏蔽的子网与企业内部网络(Intranet).实现环境中的防火墙均支持3个以上的网络接口,所以可构建多个受屏蔽的子网,提供不同类型或不同重要等级的服务器受不同程度的保护,这些受屏蔽的子网又称为非军事区DMZ (Demilitarized Zone).因VPN Server与其他服务器的特性不同,所以在实现环境中有一个VPN专用的DMZ.
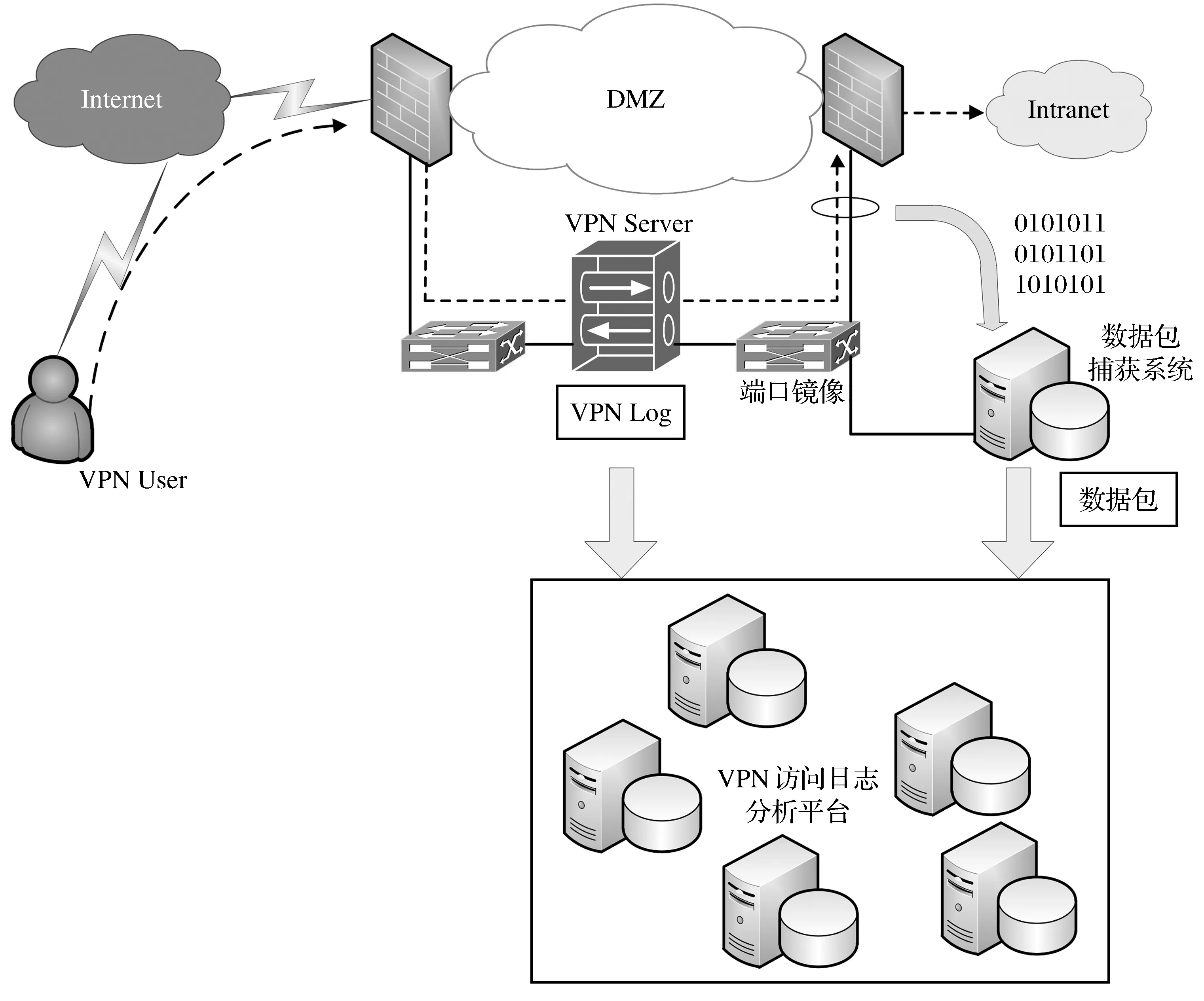
图3 平台实现环境
在此环境中,企业外部的远程使用者必须通过VPN Server才能存取位于公司Intranet网络的资源,所以在VPN Server上会留有VPN使用者的连接使用日志,即为VPN Log.本文使用安装了Windows Server 2008自带的“网络策略和访问服务”功能配置了一个简单的VPN Server,在“网络策略和访问服务”管理界面的“远程访问记录”选项中选中记录计账、记录身份验证请求,在“本地文件”选项中定义文件路径及文件名,则会将远程的访问日志记录为本地的文件.由于原始的VPN Log字段较多且格式较为复杂,因此先在VPN Server上执行日志字段预处理程序,以整理出便于阅读的信息,再将经过整理的VPN Log作为后续关联分析的输入之一.整理后的VPN日志字段包括开始时间、结束时间、连接时间、用户账号、外部IP、内部IP、网络原则、连接状态、账号验证成功或失败、VPN Server 接收的字节数、VPN Server 发送的字节数、用户主机名共12个,例如日志中的一条记录内容为2015-01-01 00:18:49、2015-01-01 00:28:16、00:09:24、A12345、11.22.33.44、10.93.251.25、WOL、Accounting-Request、Success、488162、7094392、USER-PC.
通过在交换机上配置端口镜像(Port Mirror),把位于VPN DMZ连接内部防火墙的网络端口上的数据包复制一份给数据包捕获系统(执行tcpdump程序的计算机)所连接的网络端口.执行tcpdump程序的计算机采用ubuntu linux12.04系统,我们在计算机上执行tcpdump命令,并使用-w参数直接将包写入文件中,这些捕获的数据包作为后续关联分析的另一个输入.tcpdump程序捕获的数据包记录包含了数据包形成时间、源主机、源IP、源端口、目的主机、目的IP、目的端口、协议、传送的字节数共9个字段,例如其中的一条记录为2015-01-01 00:19:44.123456789、USER-PC、10.93.251.25、7994、Web01、10.93.3.80、80、TCP、37.
3.2 系统架构
平台由5台服务器组成的集群构成,服务器使用的CPU为Intel Xeon X5650(双核),24GB内存,操作系统为CentOS6.4 64位,Hadoop环境使用了CDH5.3.0(Cloudera’s Distribution Including Apache Hadoop,其中包含了Hadoop 2.5.0、Zookeeper 3.4.5、Hive1.2.1),交换机为Cisco Catalyst 3750G-24TS.服务器名称分别为Master01、Master02、Slave03、Slave04、Slave05.平台采用 Zookeeper、Journal Node与ZKFC(ZooKeeper Failover Controller)等服务,在NameNode(NN)上实现了HA(High Availability).集群中每台服务器配置的相关角色如表1所示.
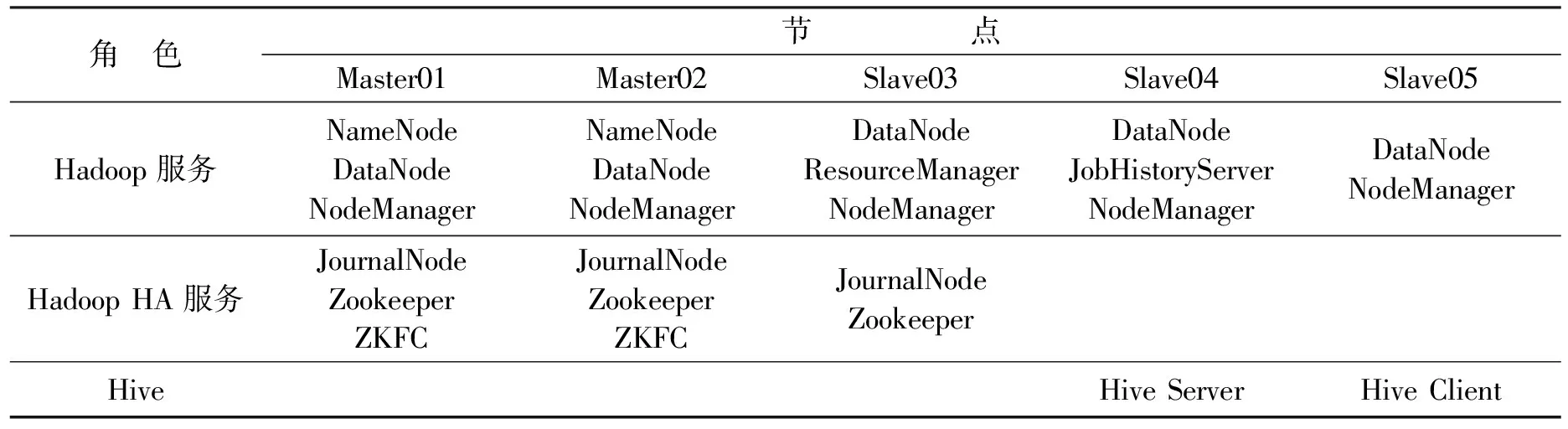
表1 服务器的相关角色
3.3 数据库设计
上传至HDFS的日志数据有VPN Server产生的VPN Log与捕获的数据包文件两种,为了能够采用HiveQL查询与分析这些数据,与关系型数据库一样,必须先在Hive中定义数据库和这两种数据的数据表.数据库名称为vpnlogdb,VPN Log的数据表名称为vpnlogs,数据包文件的数据表名称为vpnsessions.
(1) vpnlogs表字段、数据类型如表2所示.
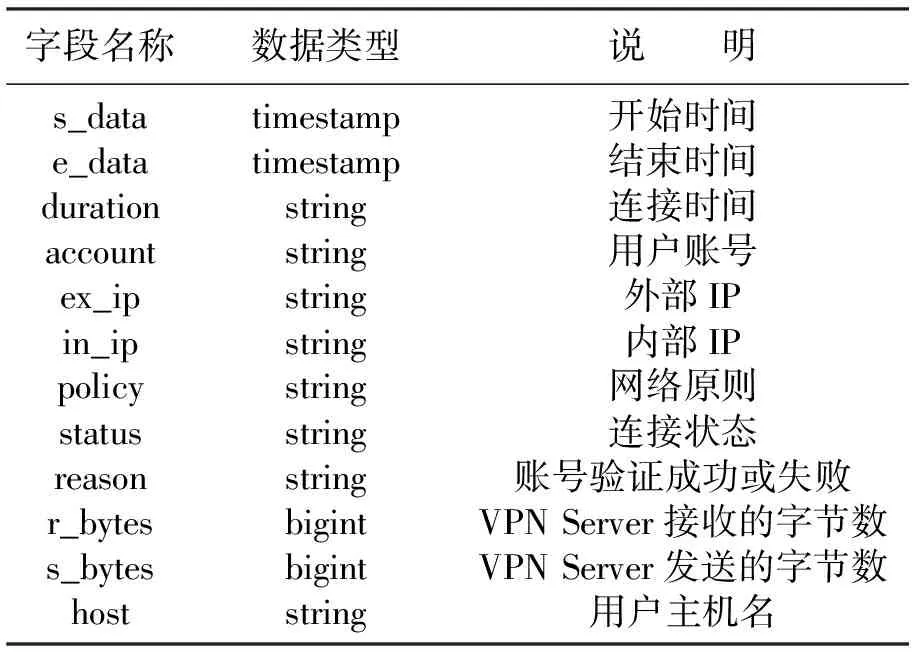
表2 vpnlogs表的字段与数据类型
表中各字段内容如下:
① s_date:用户计算机对VPN Server提出连接请求的时间,此字段合并了原始Log中VPN连接请求记录的Record-Date与Record-Time字段.
② e_date:用户计算机对VPN Server提出连接终止请求的时间,此字段合并了原始Log中VPN连接终止请求记录的Record-Date与Record-Time字段.
③ duration:VPN连接由开始至结束的时间长,此字段是将原始Log中的Acct-Session-Time字段由原来以秒为单位转换成为较易阅读的小时:分钟:秒(hh:mm:ss)格式.
④ account:通过VPN Server验证使用VPN连接的用户账号,此字段对应原始Log中的Fully-Qualified-User-Name字段.
⑤ ex_ip:用户计算机使用的Internet Public IP地址,此字段对应原始Log中的Calling-Station-Id字段.
⑥ in_ip:VPN Server分配给用户计算机的Private IP地址,本文中VPN Server指派给VPN Client的内部网络地址范围为10.93.251.0/24,此字段对应原始Log中的Framed-IP-Address字段.
⑦ policy:显示VPN用户账号使用的是哪一个网络策略(Network Policy),此字段对应原始Log中的NP-Policy-Name字段.
⑧ status:显示VPN连接的状态,例如收到连接请求(Accept-Request)、拒绝连接(Access-Reject)、连接完毕(Accounting-Request)等,此字段对应原始Log中的Packet-Type字段.
⑨ reason:显示账号验证成功或失败的原因,对应原始Log中的Reason-Code字段.
⑩ r_bytes:VPN连接期间VPN Server接收到的总数据量(Bytes),对应原Log中Acct-Input-Octets字段.


(2) vpnsessions表字段、数据类型如表3所示.
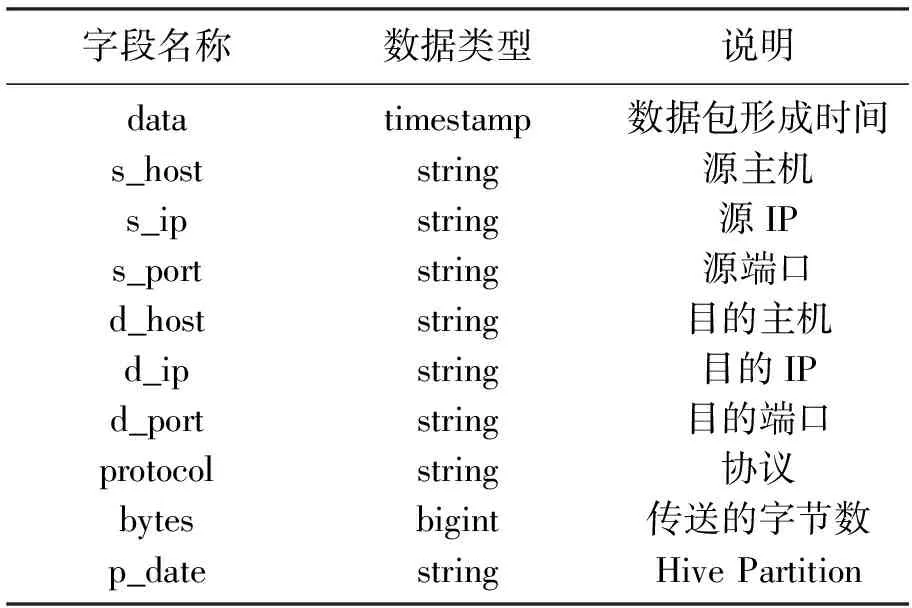
表3 vpnsessions表的字段与数据类型
① date:数据包被捕获时的时间戳,包含日期与时间.
② s_host:以源主机的IP(即s_ip字段的值)向DNS Server反查其是否有PTR(Pointer)记录,如有则字段值即为在DNS Server中登录的主机名,若无则本字段值为空.
③ s_ip:源IP地址.
④ s_port:源Port,用以区别使用的网络服务.
⑤ d_host:以目的主机的IP(即d_ip字段的值)向DNS Server反查其是否有PTR记录,如有则本字段值即为在DNS Server中登录的主机名,若无则本字段值为空.
⑥ d_ip:目的IP地址.
⑦ d_port:目的Port,用以区别使用的网络服务.
⑧ protocol:使用的传输层协议是TCP或UDP.
⑨ bytes:传送的数据包长度为多少个Bytes.
⑩ p_date:数据文件的日期,但非实际字段.
Hive为了提升数据查询的性能提供了将数据文件存放在HDFS不同分区(Partition)目录下,在撰写HiveQL查询时,在Where子句中加上分区过滤器(Partition Filter)来限制查询数据文件的范围以缩短查询时间.
4 分析平台应用场景
4.1 场景一
公司发生资料外泄事件,怀疑有员工在公司外部通过VPN下载数据后泄漏,此份数据由某部门管理,数据量大小约为1 GB.现要求审查该部门的所有员工通过VPN下载数据的轨迹,以过滤出可疑人物.
(1) 首先由vpnlogs表查询该部门所有员工在2015年2月份在单次VPN连接期间下载数据量总和超过1GB的记录.执行HiveQL程序可得到查询结果如图4所示.结果中的字段依次为:连接开始时间(s_date)、结束时间(e_date)、用户账号(account)、外部IP(ex_ip)、内部IP(in_ip),以及由VPN Server送出的总数据量(s_bytes).
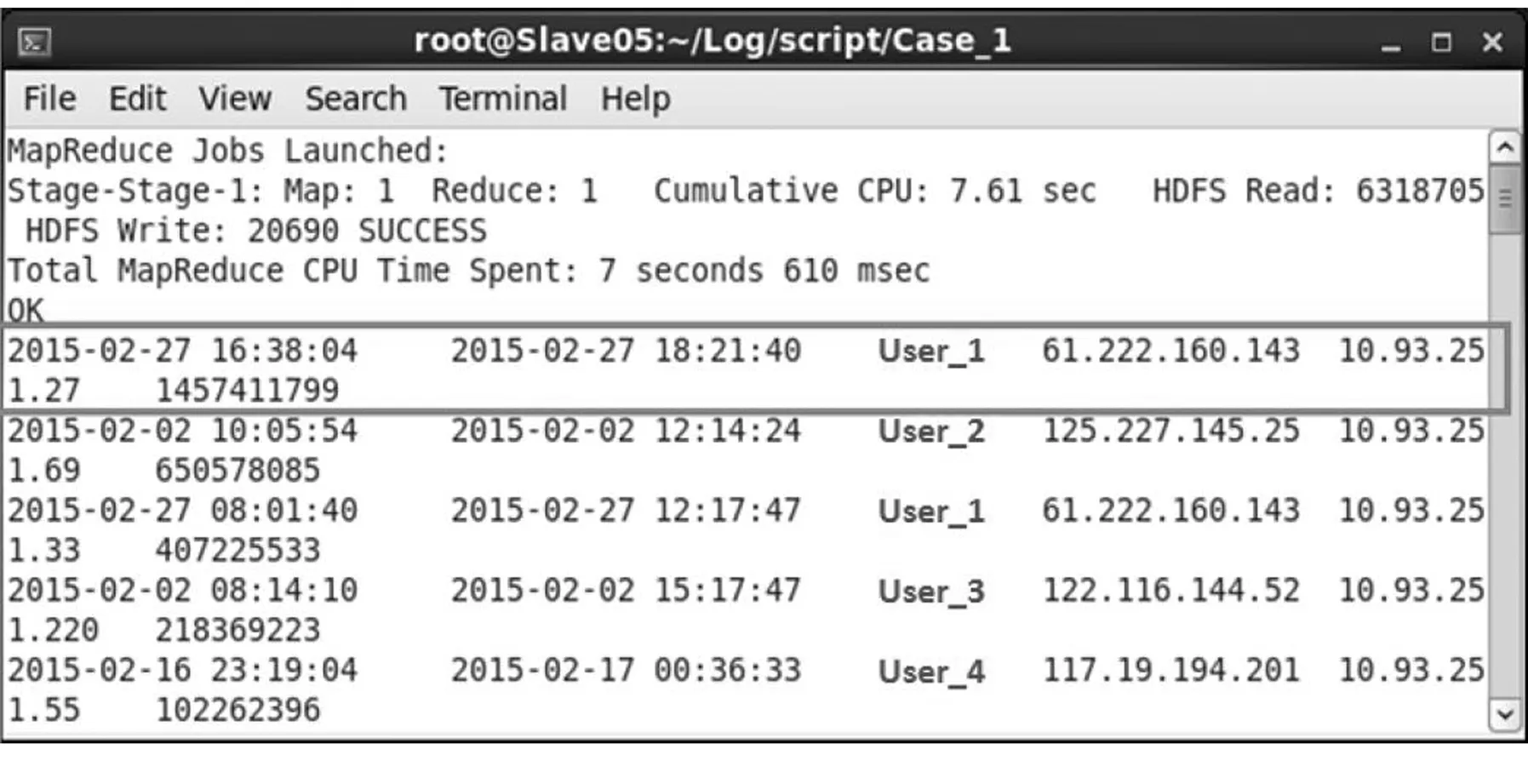
图4 单次VPN连接期间下载数据量总和超过1 GB的记录
(2) 在查出员工User_1于2015年2月27日有一次符合条件的记录后,将vpnlogs表与vpnsessions表做Cross join,进一步查询该名员工是否在该次VPN连接期间传输过单一1 GB左右的数据,以及是通过哪台计算机的哪个服务器(根据Port Number).在执行HiveQL程序后,得到结果如图5所示.结果中的字段依次为:此次VPN连接记录的开始时间(s_date)、结束时间(e_date)、外部IP(ex_ip)、目的IP(d_ip)、目的Port(d_port)、来源主机(s_host)、来源IP(s_ip)、网络协议(protocol)、来源Port(s_port),以及由这一对Socket建立的网络连接传输的累计数据量(total_bytes).由查询结果可以发现该名员工连接过10.88.33.15这台主机,并通过TCP Port 22 (Secure Shell)下载了1,041,980,449 B的数据.经过这两个步骤,便可以找出了该名员工下载数据的轨迹记录.
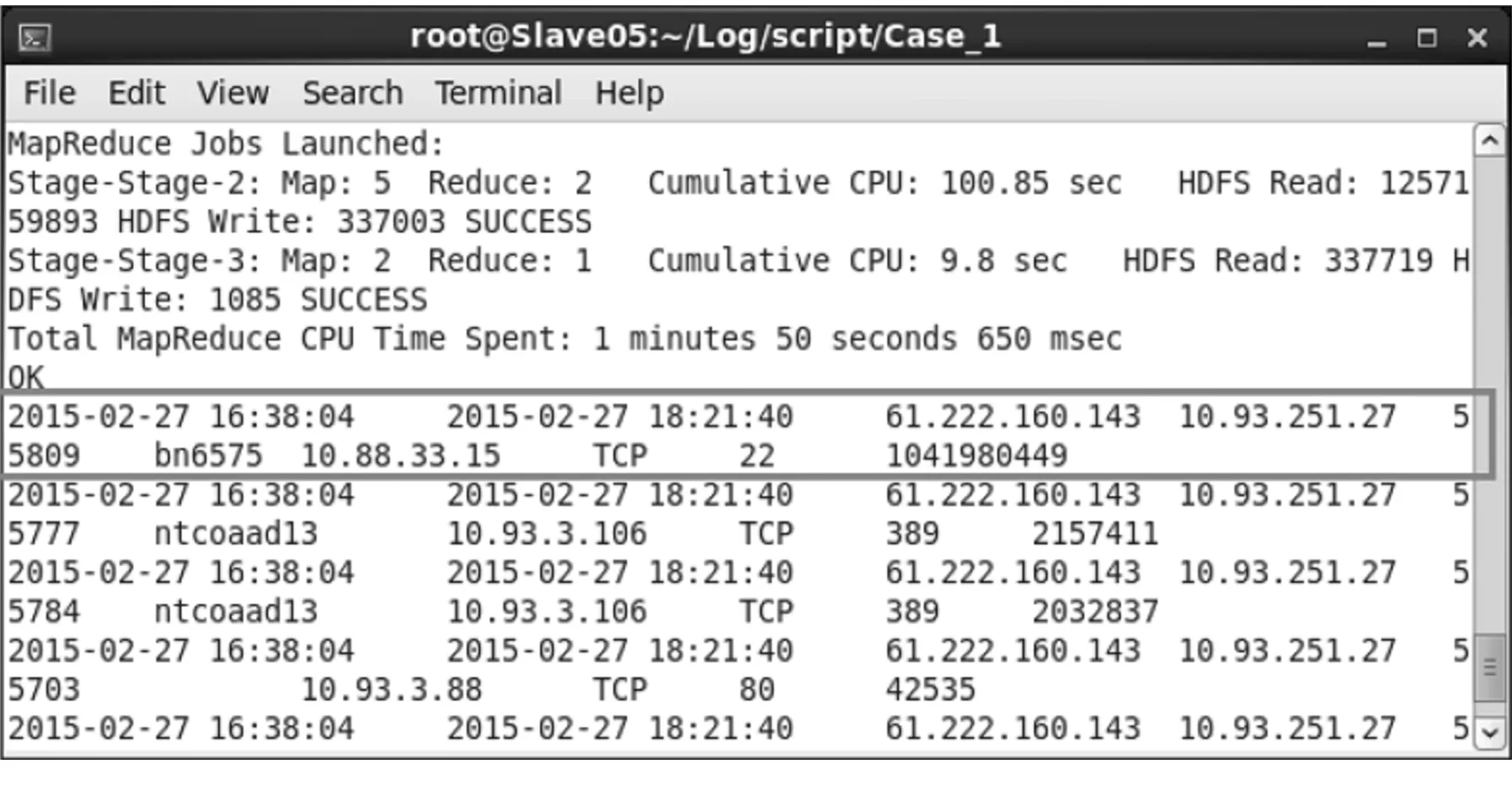
图5 VPN连接期间传输过单一1 GB数据的记录
4.2 场景二
某公司的某台计算机是以共享账号方式来操作,现在某部门的主管想审查某位员工在2015年2月24日下班后,是否通过VPN连上内部网络的这台计算机(IP为10.88.33.1)进行操作.
(1) 首先由vpnlogs表查询某位员工在2015年2月24日的VPN连接记录,再查询vpnsessions表,找到2015年2月24日连接到10.88.33.1的数据,将这两份数据通过HiveQL做Cross Join,最后再把数据包包头的时间落在VPN连接期间,且该笔记录的来源地址就是VPN Server配给某位员工账号的内部IP(10.93.251.31)的记录筛选出来.
(2) 执行HiveQL程序后,可得到结果如图6所示.结果中的字段依次为: VPN连接记录的开始时间(s_date)、结束时间(e_date)、外部IP(ex_ip)、来源IP(s_ip) 、来源Port(s_port)、目的IP(d_ip) 、网络协议(protocol)、目的Port(d_port).由结果可知,使用某特定账号的员工在2015年2月24日21:07:08 ~ 23:58:04的VPN连接期间,共计有3次连接到IP为10.88.33.1,且目的服务是TCP Port 5922(经查为10.88.33.1计算机的VNC Server使用的Port)的计算机.这些被筛选出来的记录,即为该员通过VPN Server存取公司内部资源的轨迹数据.
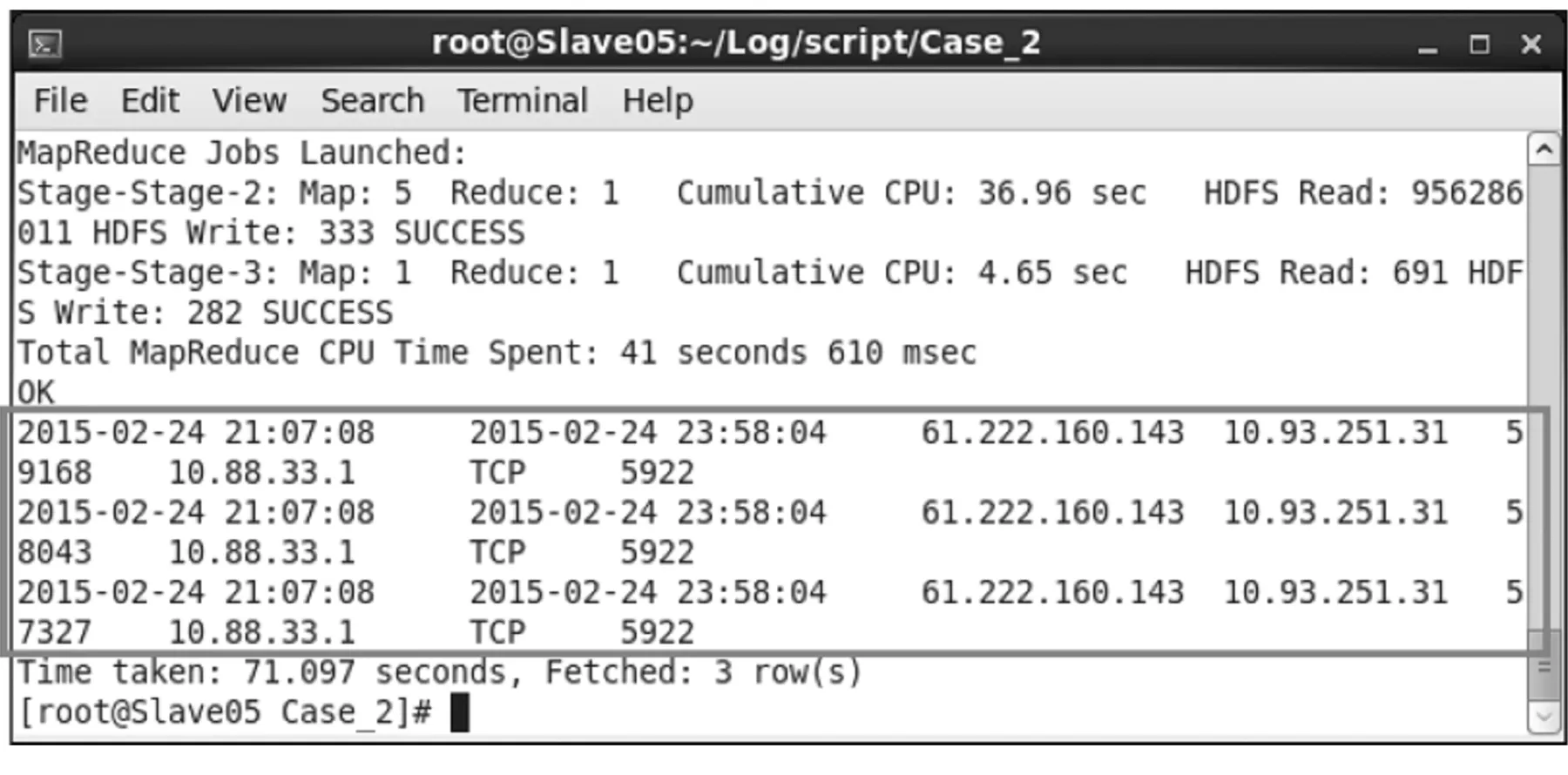
图6 某账号存取某台电脑的存取记录
4.3 场景三
管理员想知道在某段时间内VPN传输数据量的前5名使用者是谁,审查是否有网络资源被滥用的状况发生.以2014年10月1日单日的VPN传输数据量Top 5统计为例,先查询vpnlogs表中日期是2014年10月1日的VPN连接记录,再查询vpnsessions表中日期为2014年10月1日的数据包,再将这两份数据通过HiveQL做Cross Join.接着再把数据包被捕获时间(date)是在该笔VPN连接的开始(s_date)与结束(e_date)期间之内,并且数据包的来源IP(s_ip)或目的IP(d_ip)等于本次VPN连接内部IP(in_ip)的有效记录筛选出来,并以传输数据量作为排序的依据,以降序列出传输数据量最多的前5名,结果如图7所示.
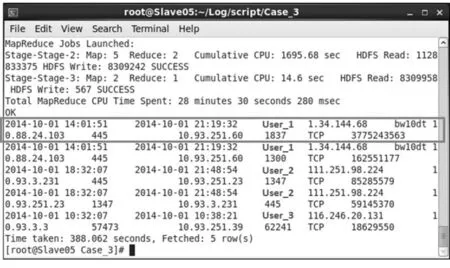
图7 单日单次连接传输数据量前5名的记录
结果中的字段依次为:开始时间(s_date)、结束时间(e_date)、用户账号(account)、外部IP(ex_ip)、来源主机(s_host)、来源IP(s_ip)、来源Port(s_port)、目的主机(d_host)、目的IP(d_ip)、目的Port(d_port)、网络协议(protocol)、由这一对Socket建立的网络连接传输的累计数据量(total_bytes),可以得知单次连接传输数据量最多用户账号是User_1,且构成此次网络连接的信息为:来源IP(10.88.24.103)、来源Port(445)、目的IP(10.93.251.60)、目的Port(1837)、网络协议(TCP),这样便可以分析出此次网络连接的行为是由客户端通过TCP Port 445,即SMB (Server Message Block)协议下载了约3.7 GB的数据,其余4条记录均可按照这种方式判读.最后可以再询问使用者本人,以判断是否有资源滥用的情况发生.
4.4 场景四
管理员想获取某一时段内VPN账号验证失败的数据,以便进一步分析是否有人尝试入侵,以2015年1月份的vpnlogs表为例,管理员通过验证失败数据的前5名分析哪些账号一再发生验证失败,并向使用者查证以确认是否为入侵尝试.
(1)先查询vpnlogs表2015年1月份VPN连接失败的记录,再以日期、账号、连接状态以及账号验证成功或失败来分组并汇总该组的验证失败次数,并将验证失败次数降序排序并显示前5条记录,结果如图8所示.结果中的字段依次为:日期(TO_DATE(s_date))、用户账号(account)、连接状态(status)、账号验证失败(reason),以及该账号验证失败累计的次数(times).

图8 VPN账号验证失败前5名记录
(2) 以排名第1的记录为例,再查询出在2015-01-04此账号(User_1)的所有VPN记录,结果如图9所示.结果中显示的字段依次为:开始时间(s_date)、结束时间(e_date)、用户账号(account)、外部IP(ex_ip)、连接状态(status)、账号验证成功或失败(reason),由结果可发现源IP均相同,且验证失败是分布发生在10点(10分钟,16次)、15点(3分钟,15次)、16点(1次)、19点(2分钟,9次)等时段共计失败41次,并在19点有两次验证成功的记录.根据验证失败模式判断,应该不是有人蓄意进行入侵尝试.最后再向使用者查证其使用状况,确认这些验证失败记录是因为用户在密码变更后,未实时更新VPN Client存储的密码内容,导致VPN Client一直使用旧的密码来进行登录验证.
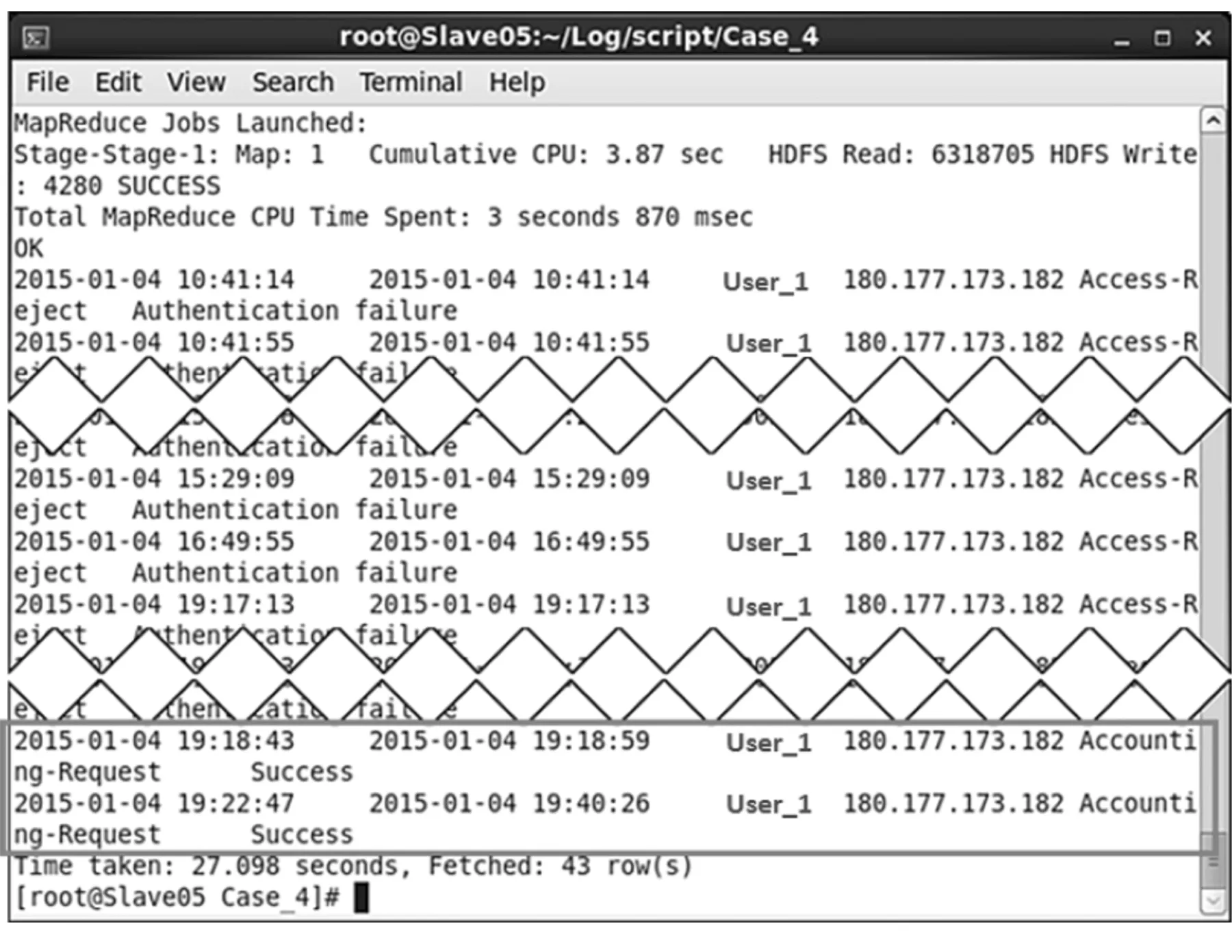
图9 验证失败次数最多的记录
5 结 语
本文实现了一个企业网络远程访问日志分析平台,把VPN Server产生的VPN日志数据与数据包包头数据进行关联分析,根据不同情境的管理需求产生所需的轨迹追踪报表,可以追踪部门数据通过VPN外泄时的轨迹,协助管理者审查员工在非工作时间对资源的使用状况,还可以让管理人员找出资源滥用者与发现是否有潜在的安全威胁.
本文构建的企业网络远程访问日志分析平台目前仅适用于离线的数据批处理,还不能满足实时数据分析.另外,本文仅就VPN Server日志与在网络传输的数据包数据做关联分析,如果想要再进一步了解使用者的完整操作行为的话,则必须把客户端与服务器端的日志纳入分析,甚至加入数据包包头之外的内容部分,这样便可得到最完整的端到端的轨迹数据.这两点都是以后研究的方向.
[ 1 ] 王赋聪. Web日志挖掘系统的研究与实现[D]. 北京:北京邮电大学, 2015. (WANG F C. Research and implementation of Web log mining system[D]. Beijing: Beijing University of Posts and Telecommunications, 2015.)
[ 2 ] 李路. 分布式入侵检测系统中的数据分析[J]. 沈阳大学学报, 2005,17(4):28-31. (LI L. Data analyzing of distributed intrusion detection system[J]. Journal of Shenyang University, 2005,17(4):28-31.)
[ 3 ] 张晓明,付强. SVM算法在Web服务蜜罐日志分析中的应用[J]. 沈阳大学学报(自然科学版), 2013,25(1):35-38. (ZHANG X M,FU Q. SVM algorithm in Web services honeypot log analysis[J]. Journal of Shenyang University(Natural Science), 2013,25(1):35-38.)
[ 4 ] LEE Y,KANG W,SON H. An Internet traffic analysis method with mapreduce[C]∥Network Operations and Management Symposium Workshops (NOMS Wksps), 2010:357-361.
[ 5 ] PARK S,LEE J H,BAE H J. End user searching: a Web log analysis of NAVER, a Korean Web search engine[J]. Library & Information Science Research, 2005,27(2):203-221.
[ 6 ] 杨文峰,李星. 网络搜索引擎的用户查询分析[J]. 计算机工程, 2011,27(6):20-21. (YANG W F,LI X. Analysis of user queries on the Web search engine[J]. Computer Engineering, 2011,27(6):20-21.)
[ 7 ] 王振宇,郭力. 基于Hadoop的搜索引擎用户行为分析[J]. 计算机工程与科学, 2011,33(4):115-120. (WANG Z Y, GUO L. An analysis of the search engine user behaviors based on Hadoop[J]. Computer Engineering & Science, 2011,33(4):115-120.)
[ 8 ] 刘永增,张晓景,李先毅. 基于Hadoop/Hive的web日志分析系统的设计[J]. 广西大学学报(自然科学版), 2011,36(Z1):314-417. (LIU Y Z,ZHANG X J,LI X Y. Design of Web log analysis system based on Hadoop/Hive[J]. Journal of Guangxi University (Natural Science Edition), 2011,36(Z1):314-417.)
[ 9 ] 宋梦馨. 基于Hive的邮件日志分析[J]. 信息系统工程, 2016(4):115-117. (SONG M X. Mail log analysis based on Hive[J]. China CIO News, 2016(4):115-117.)
[10] 潘家腾. 基于Hive数据仓库的用户行为模型研究[D]. 北京:北京邮电大学, 2015. (PAN J T. On users’ behavior model based on Hive data warehouse[D]. Beijing: Beijing University of Posts and Telecommunications, 2015.)
【责任编辑: 赵 炬】
Research and Implementation of VPN Access Log Analysis Platform Based on Hadoop
WuLing,YangJiagui,ChenJinsong,WangPingshui
(School of Management Science and Engineering, Anhui University of Finance & Economics, Bengbu 233030, China)
A platform is built for log analysis to process correlation analysis of multiple related log under different system or application program, which can restore the accessing resource’s behavior via VPN. The platform uses the Hadoop distributed computing framework and data warehouse Hive, which improves the efficiency of large number of log processing and poor extensibility of single host. The trail data generated can assist system administrator to identify data leakage path, which understands resources abuse and finds potential security threats.
VPN; log; audit trail; Hadoop; Hive
2016-07-20
国家社会科学基金年度项目(16BTQ085); 安徽省高等学校省级自然科学研究重点项目(KJ2015A106); 安徽财经大学校级教研项目(acjyyb2016098).
武 凌(1977-),男,安徽蚌埠人,安徽财经大学副教授.
2095-5456(2016)06-0488-09
TP 391
A
