基于SOC FPGA的车载语音识别系统设计
2016-12-29成利江景新幸杨海燕
成利江,景新幸,杨海燕
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
基于SOC FPGA的车载语音识别系统设计
成利江,景新幸,杨海燕
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
针对车载语音识别系统对实时性要求高、小型化及低功耗等要求,提出了一种基于SOC FPGA的语音识别系统的设计方案。该系统采用软硬件结合的设计思路,语音信号采集及预处理部分由FPGA的Verilog DHL实现;特征参数提取及模式匹配算法由ARM核处理器在内核Linux系统上用C语言实现。硬件板级测试表明,该系统识别速度分别为DSP系统的4.59倍及嵌入式ARM系统的1.96倍。
语音识别;片上系统;可编程门阵列;梅尔倒谱
随着我国汽车的普及度不断提高,人们对汽车驾驶的舒适性和安全性要求也越来越高,因此在汽车上安装语音识别系统将拥有较好的市场前景。车载环境下的语音识别系统在保证识别准确率的前提下,必须考虑系统实时性及小型化等问题,否则难以保证高速状态下汽车的安全性。
鉴于此,设计了基于FPGA的语音识别SOC系统[1]。该系统利用FPGA的Verilog HDL语言及ARM硬核Linux系统下的C语言实现语音识别,包括对WM8731音频编解码芯片的配置及语音预处理、特征提取及模式匹配算法的实现等,并对语音分帧加窗及端点检测等模块进行了硬件优化,在Quartus II中对Qsys及各个Verilog HDL下的自定义模块进行连线,通过DS-5进行底层硬件与软件的设置及调试。
1 语音识别系统原理
语音识别由语音的训练过程和识别过程组成。在语音训练时,通过录入说话人的语音并对语音信号进行分析,得到各帧语音信号的特征参数,以此为基础建立语音模型;当进入语音识别模式时,系统对输入的语音数据进行与训练时相同的处理,并提取语音特征参数,将提取的语音特征参数与语音模板进行匹配,最后得到与输入语音匹配距离最接近的模板作为识别结果。语音识别系统实现流程如图1所示。

图1 语音识别系统流程Fig.1 Process of speech recognition
1.1 语音信号预处理
在对语音信号进行特征提取之前,要对语音信号进行预处理,主要包括AD转换、预加重、分帧加窗、端点检测。
1.1.1 语音信号预加重
受口唇辐射的影响,语音信号高频分量分辨率很低。为了增加语音的高频分量,使信号频谱变得平坦,对语音信号进行预加重处理。一般采用传递函数为H(z)=1-0.93z-1的一阶高通滤波器来实现预加重。
1.1.2 语音信号分帧加窗
由于人在发音时具有连贯性,在很小的时间段里语音信号接近不变,即语音信号是短时平稳的。因此可以将语音信号分为一些短段(帧)来处理。为了使帧与帧之间平滑过渡,分帧时采用交叠分段的方法,前一帧与后一帧的交叠部分为帧移[2]。分帧与帧移如图2所示。

图2 帧长与帧移Fig.2 Frame length and frame shift
语音分帧用一个有限长度的窗口进行加权的方法实现,窗函数沿时间方向移动,用以分析任意帧语音。加窗运算的定义如下:
(1)
加窗运算为一种卷积运算,语音识别比较常用的窗函数有矩形窗和汉明窗。矩形窗:

(2)
汉明窗:
(3)
式(2)、(3)中N为窗长。
1.1.3 语音信号端点检测
为了压缩语音信号帧长度,使语音信号更紧凑,需要提取语音信号的非静音部分,即语音信号的端点检测[3]。本系统采用短时能量和短时平均过零率双门限法进行端点检测。短时平均能量为:
(4)
短时过零率即语音信号帧中波形通过零点的次数。由于语音信号高频段的过零率比低频段高很多,因此可以用短时平均过零率来区分语音信号的清浊音。第n帧信号Xn(m)的短时平均过零率为:
(5)
其中:
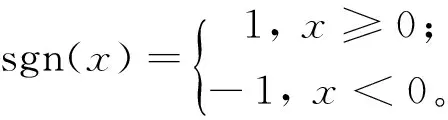
(6)
一般语音信号的非语音部分,En、Zn变化均不明显,而在非语音段和语音段的过渡阶段,这2个参数变化要明显得多,因此,可通过这2个参数的变化情况判断信号是否进入语音段。
1.2 语音信号特征提取
人耳对声波频率大小的感应与实际频率的大小近似成对数关系,因此,人对声音频率大小的感知并非呈现为线性关系;而MEL频率尺度与实际频率近似呈对数关系,其能较好地模仿听觉特性。听觉实验结果表明,利用MEL频率倒普系数(MFCC)作为特征参数,系统具有较高的识别率,同时其鲁棒性较好。MFCC的计算过程如下:
首先,需将时域信号转换成频域信号,也就是将语音帧时域信号Xn作离散快速傅里叶变换,得到语音信号的离散功率谱Pn(k),
(7)
再将Pn(k)通过三角滤波器组,计算各频带内的能量和,得到矢量参数:
(8)
最后,对Tn(m)作对数运算,将对数值通过离散余弦变换得到MFCC参数。离散余弦变换公式为:
(9)
其中:M为三角滤波器组的阶数;L为Mel频率倒普特征参数的维数。由于语音特征参数波动随其维数的增大而变小,一般取12~16维较为合适,本系统选取12维。
1.3 DTW模式匹配
动态时间规整(dynamic time warping,简称DTW)算法是一种将时间规整与距离测度计算相结合的非线性规整技术,其解决了测试语音与匹配模板语音长度不等的难题。
设待试语音特征矢量序列为R={R(1),R(2),…,R(n)},1≤n≤N。其中:R(n)为第n帧特征矢量;N为待测语音的总帧数。参考模板特征序列为T={T(1),T(2),…,T(m)},1≤m≤M。其中:T(m)为参考模板第m帧特征矢量;M为参考模板的总帧数。DTW算法通过时间规整函数m=ω(n),把待测模板的时间轴非线性地映射到参考模板的时间轴上,其表达式为:

(10)
最佳路径累加距离为:
2 系统设计方案
2.1 语音信号AD采样模块
根据语音信号的频率范围,本系统的采样频率设为8 kHz,整个采样过程由24位语音编解码芯片WM8731实现[4],通过I2C总线对芯片配置模式,其重点配置的寄存器参数有数据转换长度、采样频率、工作模式的设置、数据对齐方式。本系统采用16位数据转换长度,音频芯片设置为从模式,数据对齐方式为左对齐,一次采集数据的时长为3.2 s。由于该芯片输出为16位PCM码,用Q8格式的16位定点数表示PCM码。WM8731的配置字设置及定义如表1所示。

表1 WM8731控制字
2.2 预处理模块FPGA硬件优化
2.2.1 分帧加窗算法FPGA硬件优化
本系统一帧为256个采样点,帧移与帧长的比值为1/2,故帧移的采样点为128个;采用2个FIFO实现帧移动,FIFO的深度为256帧长。通过状态机实现2个FIFO之间的读写控制及输入输出的切换。控制过程的状态转移如图3所示。

图3 分帧模块状态机Fig.3 State process of frame shift
FIFO1、FIFO2的读写控制信号分别为r_1、r_2、w_1、w_2;stack_half_1为FIFO1的半满标志位,stack_half_2、stack_empty_2为FIFO2的半满标志位及空标志位。各个状态之间的转移操作如下。
S0:初始化状态。en_state为高电平时进入S1态。
S1:FIFO1写信号w_1置1,读信号r_1置1;FIFO2写信号w_2置1,读信号r_2置0。当stack_half_1为高电平时,进入S2状态。
S2:FIFO1写信号w_1置0,读信号r_1置0;FIFO2写信号w_2置0,读信号r_2置1;当stack_half_1及stack_half_2为高电平,stack_empty_2为低电平时,进入S3状态。
S3:FIFO1写信号w_1置1,读信号r_1置1;FIFO2写信号w_2,读信号r_2置0;当stack_half_1及stack_empty_2为高电平,stack_half_2为低电平时,进入S3状态。分帧模块的Modelsim仿真如图4所示。

图4 分帧模块仿真Fig.4 Simulation of frame shift
分帧后要经过加窗处理,该系统使用汉明窗[5],利用查找表的方法对数据实现加窗处理。先用Matlab生成256个点的窗函数值,存入深度为256的ROM中,用计数器链接ROM的地址线,当计数到256时计数器清零。用分帧后的信号乘ROM中对应点的值,得到加窗后的信号。
2.2.2 端点检测模块FPGA硬件优化
端点检测模块的准确性对整个语音识别系统至关重要,大部分无法识别的情况都是由端点检测不准确造成的。该系统由硬件实现端点检测,并对预进入语音段延长到10帧,增强系统实时性的同时,10帧的距离可有效地防止错误进入或退出语音段。
短时能量及短时过零率的计算模块的Modulsim仿真结果如图5所示。

图5 短时能量与短时过零率的仿真Fig.5 Simulation of short-time energy and short-time zero crossing rate
从图5可看出,输入testbench的仿真数据,第1帧的短时能量为26,2~9帧的短时能量为27,前10帧的短时能量平均值(能量门限)为23;第1帧的短时过零率为125,2~9帧的短时过零率为128,前10帧的短时过零率平均值(过零率门限)为111。
在端点检测单元中:en为输入使能标志位;energy、zero分别为输入帧的短时能量、短时过零率;前5帧信号的平均短时能量和短时过零率作为阀值分别记为Genergy、Gzero;counter1、counter2为帧计数器;确定起始语音帧和结束语音帧延续帧长寄存器分别为start_longth和finish_longth;寄存器frame_start、frame_end分别为起始帧、结束帧帧数。端点检测模块用状态机实现的具体步骤如下:
1)初始化各单元。
2)en有效时,帧信号经过子单元计算出输入帧短时能量与短时过零率,并得出前10帧信号的Genergy和Gzero。
3)端点检查单元进入待检测状态S0。
4)当energy>Genergy或zero>Gzero时,进入语音数据起点的临界状态S1,counter2开始计数,若energy 5)当energy 端点检测模状态机如图6所示。端点检测模块的Modelsim仿真结果如图7所示。 图6 端点检测模块状态机Fig.6 State process of point detecting module 图7 端点检测模块仿真Fig.7 Simulation of point detection 从图7可看出,当counter2=start_longth=9时,进入有效数据状态,此时frame_start寄存器的值为46;当counter2=end_longth=9时,进入静音数据状态,此时frame_end寄存器的值为79。 2.3 DTW模式匹配算法实现 DTW算法在孤立词识别中有较好的表现,故本系统采用DTW算法来实现模式匹配模块[5]。ARM处理器对之前提取的MFCC特征参数与训练阶段储蓄于内存的模板库词条进行DTW模式匹配,最终将匹配结果输出给LED控制器。C语言实现DTW模块流程如图8所示。首先对参数值初始化,设置模板库中的矢量词条数,并标记为rflag。然后分配距离矩阵的内存空间,读取当前模板库中的词条特征值矢量,读取待测词条特征矢量,计算各帧距离及帧最小累积距离。此时rflag加1,判断是否小于模板库词条的总数,若是,则返回输入参考模板步骤继续重复上面的测试;否则,结束测试,输出测试结果。 图8 DTW模块流程图Fig.8 Flow chart of DTW module 3.1 硬件部分 本系统采用Altera公司基于28 nm工艺的cyclone v系列FPGA。该FPGA使用带宽互联干线链接,将基于ARM硬核处理器的系统(hard processor system,简称HPS,)集成在FPGA核心芯片中。本系统的实现平台为DE1开发板,包括双核ARM Cortex-A9处理器、FPGA上64 MB SDRAM、HPS上1 GB DDR3 SDRAM、24位语音编解码芯片wm8731、若干外设及自定义组件。整个系统分为FPGA、HPS两部分,两者间的通信由AXI[6]桥实现,HPS端各外设与ARM之间由Avalon总线进行互联[7],并按需求配置各外设参数。本系统整体框架如图9所示。 FPGA部分语音信号首先由麦克风输入到WM8731芯片进行语音AD采样,采样得到的数据经过一级FIFO存入SDRAM中,然后以流水线方式经过预加重、分帧加窗、端点检测模块,并将处理后的数据由HPS-to-FPGA axi bridge供HPS读取,同时在Linux系统中的应用程序对数据进行MFCC处理并将处理后的数据存入DDR3中作为参考模板。通过LightWeight HPS-to-FPGA Bright来实现语音特征模板的存储模式和模板匹配模式的转换。在匹配模式时,Linux系统通过Avalon-MM总线读取DDR3中的模板对被测模板进行模板匹配[8],最后映射HPS外设区域PIO控制器物理地址到虚拟地址,得到pio_led的虚拟地址[9],将该地址对应各个特征模板,供应用程序调用输出。 图9 系统整体框架Fig.9 Framework of the system 3.2 软件部分 软件部分主要完成3个功能:1)获取FPGA端的语音数据,并对此数据进行MFCC处理后传输到HPS端的DDR3;2)通过轻量级HPS-to-FPGA桥总线,控制系统进行语音识别模式和采集模式的转换;3)将PIO_LED控制器物理地址映射到应用程序可以访问的虚拟地址。 程序中先用nmap()函数将HPS-to-FPGA桥和轻量级HPS-to-FPGA桥的物理地址空间映射到Linux内核虚拟地址空间,供应用程序访问虚拟地址。映射完成后,通过端点检测模块在Qsys中分配地址,以访问到此模块。部分代码如下: unsigned char GetBmpData,unsigned char*bit Countperpix,unsigned int*width, unsigned int*height,const char*filename,unsigned long*menory_vip_frame; lw_axi_virtual_base=nmap(null,hw_regs_span,(prot_read|prot_write),map_shared,fd,hw_regs_base); axi_virtual_base=nmap(null,hw_fpga_axi_span,(prot_read|prot_write),map_shared,fd,alt_axi_fpgaslvs_ofst); 为了实现对LED的控制,先在hps_led.h的头文件中找到pio_led在Qsys中分配的相对于lwaxi的基地址pio_led_base,pio_led位宽信息表示为宏定义pio_led_data_width。将pio_led的物理地址映射为应用程序可以访问的虚拟地址时,系统调用open函数打开memory设备驱动“/dev/mem”,调用mmap函数映射HPS的L3外设区域物理地址到虚拟地址,并表示为一个空指针变量virtual_base。通过virtual_base增加轻量级HPS-to-FPGA AXI总线相对于HPS的L3外设区域基地址的偏移地址和pio_led相对于轻量级HPS-to-FPGA AXI总线的偏移地址,计算得出pio_led的虚拟地址。pio_led的虚拟地址被定义为空指针h2p_lw_led_addr,应用程序可以直接用该指针变量访问pio_led控制器的寄存器。 部分关键程序如下: Virtual_base=nmap(null,hw_regs_span,(prot_read|prot_write),map_shared,fd,hw_regs_base); h2p_lw_led_addr=virtual_base+((unsigned long)(alt_lwfpgaslvs_ofst+pio_led_base)&(unsigned long)(hw_regs_mask))。 对LED进行控制时,应用程序将每个输出结果对应相应的输入写入PIO控制器,如“开窗”命令时,应用程序将0x0FFFFFF1值写到偏移地址为0的寄存器中,对应第一盏灯点亮,其他各个命令同理点亮其他LED灯。 在车载环境下对系统进行测试,将系统初始化,并对“开窗”、“关窗”、“左转灯”、“右转灯”、“雨刷”5个词分别进行100次识别。板级识别准确率如表2所示。 表2 板级识别准确率 在基于Cyclone V的设计中,利用Quartus II进行时序分析,在100 MHz的时钟频率下,关键路径仍然保有14 ns的余量。经过测试分析,分帧模块与加窗模块分别只需4.096 ms,而端点检测模块由于要先计算能量以及平均过零率,经过端点检测模块测试端点,再将数据存入SDRAM缓存,并根据端点检测结果对SDRAM中对应帧进行提取,数据手册查SDRAM的存取需要6个时钟周期,因此整个端点检测需要9个流水线流程,需要36.882 ms。MFCC及DTW模式匹配由ARM核软件实现,分别耗时31.011、18.387 ms。系统各模块耗时见表3。 表3 系统各模块耗时 嵌入硬核ARM Cortex-A9处理器的SOC FPGA语音识别系统在保证识别率的前提下,分别与PC、DSP及ARM上运行的语音识别系统进行实时性对比,结果如表4所示。从表4可看出,本系统的识别速度为PC机的9.24倍,DSP系统的4.59倍,ARM系统的1.96倍。 表4 不同平台实时性对比 以SOC FPGA架构设计了车载语音识别系统,相比传统的基于DSP的语音识别系统,基于FPGA的片上系统(SOC)具有体积小、功耗低、灵活性高、实时性好的优点。而与传统的ASIC系统相比,避免了流片的高成本风险,同时具有ASIC所不具备的灵活性。并且相对于基于ARM处理器的嵌入式系统,SOC FPGA系统具有FPGA实现简单算法时对大数据进行并行高速处理的能力和ARM硬核处理复杂算法时强大的软件编程能力,在保证识别率的同时兼顾实时性及稳定性。不足之处是在此车载语音识别系统中,并未考虑车载环境下的噪声因素,以后可以在FPGA部分加入去噪模块来提高系统的识别率,这也是SOC FPGA可定制及方便系统升级的一大优势。 [1] EZHUMALAI P,MANOJKUMAR S,ARUM C.High performance hybrid two layer router architecture for FPGAs using network-on-chip[J].International Journal of Computer Science and Information Security,2010,7(1):266. [2] 杨钏钏.基于FPGA的非特定人孤立词语音识别系统设计与实现[D].西安:西安电子科技大学,2014:37-38. [3] KEPUSKA V Z,HUSSIEN A.Robust speech recognition system using conventional and hybrid features of MFCC,LPCC,PLP,RASTA-PLP and hidden markov model classifier in noisy conditions[J].Journal of Computer and Communications,2015,3(6):1-9. [4] 王海荣.基于SOPC嵌入式数字存储音频采集与回放系统设计[J].山东农业大学学报(自然科学版),2014(2):223-228. [5] JING Xinxing,SHI Xu.Speech recognition based on efficient DTW algorithm and its DSP implementation[J].Procedia Engineering,2012,9(8):832-836. [6] LANDING E,KROGER B.Cephalopod ancestry and ecology of the hyolith “Allatheca” degeeri s.l.in the cambrian evolutionary radiation[J].Palaeogeography Palaeoclimatology Palaeoecology,2012,4(10):21-30. [7] ANONYMOUS.Altera's Quartus II Software Version 11.0 Features the Production Release of Qsys System Integration Tool[M].San Jose:Altera Corporation,2011:114-117. [8] KYUNG H M,PARK G,JONG W K.Design and implementation of performance analysis unit (PAU) for AXI-based multi-core system on chip (SOC)[J].Microprocessors and Microsystems,2011,34(2):102-116. [9] Patel J J,Reddy N,JIGNESHKUMAR J P,et al.Linux platform for data acquisition systems[J].Fusion Engineering and Design,2014,13(2):211-212. 编辑:张所滨 Design of SOC FPGA based on board speech recognition system CHENG Lijiang, JING Xinxing, YANG Haiyan (School of Information and Communication Engineering, Guilin University of Electronic Technology, Guilin 541004, China) Aiming at the high demand of real-time performance and miniaturization and low power consumption of speech recognition system in vehicle environment, an on-board voice recognition system is designed based on SOC FPGA. The system is designed by combination of software and hardware. Speech signal acquisition and preprocessing part realized by VDHL of FPGA. Characteristic parameters extraction and pattern matching algorithm are implemented by C language in the Linux kernel of ARM. Board-level hardware tests show that the system's recognition speed is 4.59 times of DSP system and 1.96 times of the embedded ARM system separately. voice recognition; system on chip; FPGA; MFCC 2016-03-06 广西自然科学基金(2012GXNSFAA053221);广西千亿元产业产学研用合作项目(信科院0168) 杨海燕(1975-),女,山西运城人,副教授,研究方向为语音信号处理。E-mail:yhy@guet.edu.com 成利江,景新幸,杨海燕.基于SOC FPGA的车载语音识别系统设计[J].桂林电子科技大学学报,2016,36(6):454-460. TP391.42 A 1673-808X(2016)06-0454-07


3 系统整体架构

4 系统测试


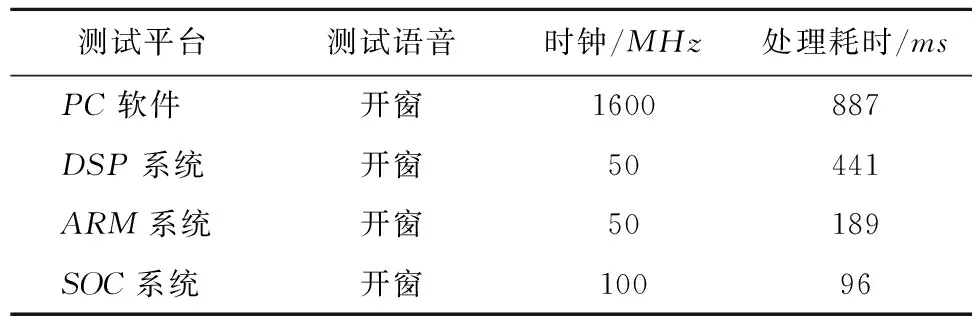
5 结束语
