属性样本同步粒化的AP熵加权软子空间聚类算法*
2016-12-23丁世飞
朱 红 丁世飞
(1.徐州医科大学医学信息学院,徐州,221005; 2.中国矿业大学计算机科学与技术学院,徐州,221116)
属性样本同步粒化的AP熵加权软子空间聚类算法*
朱 红1丁世飞2
(1.徐州医科大学医学信息学院,徐州,221005; 2.中国矿业大学计算机科学与技术学院,徐州,221116)
仿射传播(Affinity propagation,AP)聚类算法是将所有待聚类对象作为潜在的聚类中心,通过对象之间传递的可靠性和有效性信息找到合适的聚类中心,从而计算出相应的聚类结果,但不适用子空间聚类。将粒度计算引入到仿射传播聚类算法中,提出属性与样本同步粒化的AP熵加权软子空间聚类算法(Entropy weighting AP algorithm for subspace clustering based on asynchronous granulation of attributes and samples,EWAP)。EWAP首先去除冗余属性,然后在每次聚类的迭代过程中修改属性的权重值。在满足一定条件迭代终止时,就会得到构成各兴趣度子空间的属性权重值,从而得到属性集的粒化结果以及相应的子空间聚类结果。理论与实验证明EWAP算法既保留了AP算法的优点,又克服了该聚类算法不能进行子空间聚类的不足。
聚类;熵;加权;子空间;AP聚类
引 言
聚类算法是人工智能、数据挖掘和机器学习等领域的关键技术之一,在数据处理 、图像分析、电子商务、预测和医疗卫生[1-4]等方面有着非常广泛的应用。但是随着大数据时代的到来,产生了大量不一致数据、混合类型数据、高维稀疏数据、非有益数据和部分值缺失的数据等。典型的聚类算法在对这些数据集进行聚类时遇到了难题。例如在高维稀疏数据中,簇类只存在于部分属性构成的兴趣度子空间中,传统的全维聚类算法却不能搜索到隐含在属性子集上的簇类(这些数据集从全维空间来讲根本不存在簇类)。为此,1998年Agrawal提出了子空间聚类的概念[5]。在高维数据中挖掘可以聚类的属性子集中的簇类过程称为子空间聚类。子空间聚类的任务有两个:(1)发现可以聚类的子空间(属性子集);(2)在相应的子空间上聚类。依据属性对每个子空间的贡献,子空间聚类算法可分为硬子空间聚类算法和软子空间聚类算法。在硬子空间聚类算法中,一个属性必须且只能属于一个子空间,聚类则在这些子空间中进行,属性在每个子空间的权值要么是0,要么是1。软子空间聚类是在全维空间对整个数据集聚类,每个兴趣度子空间包含所有属性,但是每个属性在不同的兴趣度子空间被赋予[0,1]不同的权值,属性权值描述了属性与对应子空间之间的关联程度,权值越大说明该属性在这个子空间越重要,与该子空间的关联性也就越强。
依据不同的搜寻策略,子空间聚类又可以分成由底向上的聚类方法和由顶向下的聚类方法。这两种子空间聚类算法都要遍历所有维度的数据。由底向上的子空间聚类算法首先要在每一属性上寻找数据的密集单元,如果可以在两维属性空间合并某些密集单元,就会形成两维属性的密集单元,依此类推,形成k维属性的密集单元,最后形成在这k维子空间上的簇类。此方法的理论基础是关联规则中的先验性质:如果k-1维属性空间是不密集的,那么包含它的k维属性空间必定也是不密集的;如果k维属性空间是密集的,则它所包含的k-1维属性空间也必定是密集的。由顶向下的搜寻方法是首先将数据集分成n个簇类,给每个簇类赋予一定的权值,然后依据某种算法更新簇的权值,直到满足一定的终止条件。
依据属性与样本粒化的顺序子空间聚类算法可以分为同步和异步两种。这种分类方法认为子空间实际上是对数据集的全维属性集合粒化的结果,而聚类结果则是对样本或待聚类对象粒化的结果。异步方法是先通过对属性集粒化,找到兴趣度子空间,然后在各子空间内部对样本进行聚类。同步方法则是对属性和样本同时粒化,在搜索子空间的同时完成对子空间中样本的聚类。
Frey等于2007年提出了仿射传播(Affinity propagation,AP)聚类算法[6],具有不需事先确定聚类中心与类数等优点,在搜索最优航线、识别基因外显子、识别手写的邮政编码和人脸识别等方面应用效果良好[7-10],但该算法所有属性在聚类过程中同等重要。本文提出的属性样本同步粒化的AP熵加权软子空间聚类算法,将属性权重矩阵引入到AP算法中,在每次聚类的迭代过程中修改属性的权重值。满足一定条件迭代终止时,就会得到构成各兴趣度子空间的属性权重值,从而得到属性集的粒化结果以及相应的聚类结果。
1 K-Means熵加权软子空间聚类算法
1.1 W-K-Means算法[11]
在软子空间聚类算法中使用权值来描述属性对每个子空间的贡献,在此基础上实现子空间的聚类。常用方法是在传统聚类算法的迭代过程中增加属性权值的计算,从而获取不同子空间属性权值的集合。典型算法有:W-K-means[11],SCAD[12]和EWKM[13]。
属性权值对聚类结果的影响如图1所示。数据集有3个属性a1,a2,a3,在子空间a1,a2上的聚类如图1(a),在子空间a1, a3上的聚类如图1(b),在子空间a2,a3上的聚类如图1(c)。可见在a1, a3和 a2,a3上不能发现有效的聚类结果,数据集的簇类只存在于子空间a1,a2中。但若对3个属性赋权值0.48,0.45和0.07,然后在全维属性集a1,a2和a3上聚类得到结果如图1(d)。可见如果通过计算得到a1,a2和a3的权值为0.48,0.45和0.07,在此基础上聚类可以得到正确的聚类结果。这说明a1,a2在聚类中起重要作用,a3的作用则可以忽略,发现的子空间就是a1,a2。这样通过计算属性的权值就可以发现子空间。

图1 子空间聚类示意图Fig.1 The sketch of subspace clustring
设X={X1,X2,…,Xn}是n个对象的集合,可以聚类成为k簇,其中Xi={xi1,xi2,…,xim},m是每个对象所含的属性个数,C={C1,C2,…,Ck}是k个簇的聚类中心,W={w1,w2,…,wm}是m个属性的权重向量,β属性权重的一个参数。W-K-Means算法的目标函数是
(1)

1.2 EWKM子空间聚类算法
EWKM是一种通过熵加权对高维稀疏数据集进行子空间聚类的软子空间聚类算法。EWKM算法依然通过计算属性权重实现对属性的粒化,但不同的子空间属性集的权重向量不同。权重矩阵在EWKM算法开始时是随机指定的,但随着算法的迭代深入,权重矩阵不断修正,直到满足某种条件算法结束,从而得到各子空间属性的权重向量。
EWKM算法的的属性权重矩阵W={W1,W2,…,Wk}是k个簇的属性权重向量,其中Wl={wl,1,wl,2,…,wl,m}。目标函数是
(2)
其中限制条件是
(3)
根据目标函数最小化原则以及限制条件,在固定隶属度矩阵和类心矩阵的情况下,运用拉格朗日乘子技术,就能得到计算属性权值矩阵的迭代公式,这样每次迭代中重新计算属性权值,最终会得到兴趣度子空间及相应的聚类结果。
2 属性样本同步粒化的AP熵加权软子空间聚类算法
2.1 EWAP算法属性粒化的迭代算法
AP聚类算法没有考虑属性对整个空间或子空间的贡献,认为所有属性的重要度是一样的,所以无法去除噪声属性,不能搜索子空间及相应的簇类。EWAP算法将计算属性权重纳入到聚类之中,去除冗余属性后,在每次AP聚类的迭代过程中修改属性权重矩阵,最终完成属性集的迭代粒化,同时得到子空间及其聚类结果。

为达到搜寻兴趣度子空间的目的,给每个潜在的聚类中心赋予一个属性权值向量,每个对象则赋予一个隶属度, EWAP算法的目标函数变为
(4)
为了计算方便,式(4)修改为
(5)
考虑到算法针对稀疏矩阵也适用,采用熵加权的方法,式(5)修改为
(6)
约束条件为
(7)
用拉格朗日乘子法最小化式(6),求出属性权重矩阵的迭代公式,有
(8)
上式可以分解为k个独立的最小化问题,即
(9)
(10)
(11)
这样通过计算得到属性权值的更新公式为
(12)

隶属度矩阵迭代公式为
(13)
聚类中心的选择依据是E=A+R的对角线与所给阈值的比较结果。由于引入属性加权系数,AP聚类中计算A,R的公式发生了变化。原有的A和R矩阵都要乘以数据点所在类的属性权重矩阵W。
2.2 EWAP算法
EWAP使用仿射传播聚类算法对数据集聚类,但在每次迭代过程中都要修改属性权重,从而使得属性在每个兴趣度子空间的权重向量逐渐精确,最终完成属性集的迭代粒化,并同时实现在每个兴趣度子空间的样本集的粒化,实现子空间聚类。
输入:待聚类数据集
输出:子空间聚类结果
Step (1)初始化:计算n个待聚类对象两两之间的相似度值, 放在相似度矩阵S中;S对角线元素赋予相同的初始值并赋给参数p; 给矩阵R和A赋初始值; 给lam(引进参数lam是为了控制AP算法的震荡)赋初始值。
Step (2)迭代:
(1) 计算R
(a) Rold=R
(b)计算R
(c)R=WR
(d) 计算r(k,k), 放入R中
(e)R=(1-lam)×R+lam×Rold (2) 计算A
(a)Aold=A
(b)计算A
(c)A=WA
(d)计算a(k,k) , 放入A中
(e)A=(1-lam)×A+lam×Aold (3) 求出新的聚类中心 (4)依据式(13)更新隶属度矩阵U(5)依据式(12)更新属性权重矩阵W(6) 判断以下条件是否满足, 如果满足其中之一,则迭代终止:
(a)超过最大迭代次数;
(b)信息量的改变低于某一阈值;
(c)选择的类中心保持稳定。
Step (3) 输出聚类结果
3 实验与分析
3.1 算法准确率

(14)
聚类结果的查全率为
(15)
聚类结果的F度量为
(16)
聚类结果Cj的FScore为
FScorej=maxFji
(17)
所以整个聚类结果的FScore为
(18)
3.2 实验数据集
实验采用人工生成数据集和UCI数据集验证算法。人工数据集D1,D2,D3和D4的簇类分布在不同的子空间。数据集D1有5个属性,其中第4,5个属性是噪声,D1的簇类数为2。数据集D2有10个属性,分为2个子空间,簇类数为5。数据集D3有15个属性,分为3个子空间,簇类数为6。数据集D4有20个属性,2个子空间,簇类数为6。UCI数据集为Iris, Wine, Musk和Ionosphere。数据集特征如表1所示。

表1 实验数据集
3.3 实验结果与分析
实验将EWKM,EWAP和AP三种聚类算法在8个数据集上对准确率和运行时间做了比较,结果如表2,3所示。
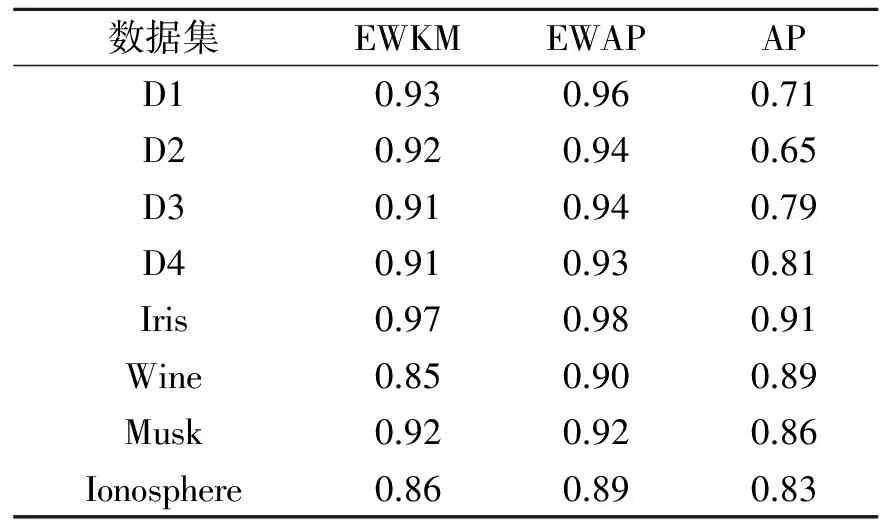
表2 EWKM,EWAP和AP算法准确率比较

表3 EWKM,EWAP和AP算法聚类时间比较
由表2可以看出,EWAP算法的准确率比EWKM算法稳定而且较高。主要原因是EWKM算法的初始聚类中心是随机确定的,聚类中心选择的好坏会对聚类结果的准确性产生很大影响。EWAP算法将所有待聚类对象作为潜在的聚类中心,所以算法结果稳定,准确率高。AP算法由于不适用于子空间聚类,所以准确率也较低。
由表3可以看出,由于EWKM,EWAP算法需要计算子空间,所以运行时间较长,效率较低,而AP算法效率最高。AP算法要在所有数据点之间传递消息,所以基于AP聚类的EWAP算法效率要低于基于K-means的EWKM算法。
4 结束语
本文将粒度计算的思想引入到仿射传播聚类中,使得AP算法拓展到子空间领域。提出属性样本同步粒化的AP加权软子空间聚类算法,在仿射传播聚类算法中引入属性的权重矩阵,使得每次聚类的迭代过程都可以修改属性权重矩阵,算法结束时同时找到了兴趣度子空间和在此之上的簇类,达到属性样本同步粒化的目的。EWAP算法虽然聚类结果有较高的精确度,也很稳定,但运行时间较长,需进一步改进算法提高效率。
[1] 郑馨,王勇,汪国有. EM聚类和SVM自动学习的白细胞图像分割算法[J]. 数据采集与处理, 2013,28(5):614-619.
Zheng Xin, Wang Yong, Wang Guoyou. White blood cell segmentation using expectation-maximization and automatic support vector machine learning[J]. Journal of Data Acquisition and Processing, 2013,28(5):614-619.
[2] Malyszko D, Stepaniuk J. Rough entropy hierarchical agglomerative clustering in image segmentation[J]. Transactions on Rough Sets XIII, 2011, 6499: 89-103.
[3] 刘金勇,郑恩辉,陆慧娟. 基于聚类和微粒群优化的基因选择方法[J]. 数据采集与处理, 2014,29(1):83-89.
Liu Jinyong, Zheng Enhui, Lu Huijuan. Gene selection based on clustering method and particle swarm optimization[J]. Journal of Data Acquisition and Processing, 2014,29(1):83-89.
[4] 夏利,王建东,张霞,等.聚类再回归方法在机场噪声时间序列预测中的应用[J]. 数据采集与处理,2014,29(1):152-156.
Xia Li, Wang Jiandong, Zhang Xia,et al. Application of cluster regression in time series prediction of airport noise[J]. Journal of Data Acquisition and Processing, 2014,29(1):152-156.
[5] Agrawal R, Gehrke J, Gunopulos D, et al. Automatic subspace clustering of high dimensionating data for data mining applications[C]∥Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data. [S.l.]: ACM Press, 1998: 94-105.
[6] Frey J, Dueck D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976.
[7] Jia S, Qian Y T, Ji Z. Band selection for hyperspectral imagery using affinity propagation[C]∥Proceedings of the 2008 Digital Image Computing:Techniques and Applications. Canberra, ACT: IEEE, 2008:137-141.
[8] Li G , Guo L, Liu T M, et al. Grouping of brain MR images via affinity propagation[C]∥IEEE International Symposium on Circuits and Systems, 2009(ISCAS 2009). Taipei: IEEE, 2009: 2425-2428.
[9] Dueck D, Frey B J, Jojic N, et al. Constructing treatment portfolios using affinity propagation[C]∥Proceedings of 12th Annual International Conference, RECOMB 2008. Berlin: Springer, 2008: 360-371.
[10]Kelly K.Afinity program slashes computing times[EB/OL].http:∥www.news.utoronto.ca/bin6/070215-2952.asp, 2007-02-15.
[11]Huang Z, Ng M, Rong H. Automated variable weighting in K-means type clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 657-668.
[12]Frigui H, Nasraoui O. Simultaneous clustering and attribute discrimination[C]∥Proceeding of the 9thIEEE International Conference on Fuzzy Systems. San Antonio, TX: IEEE, 2000:158-163.
[13]Jing L, Michael K, Ng, Joshua Zhexue H. An entropy weigh K-means algorithm for subspace clustering of high dimensional sparse data[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(8):1-16.

朱红(1970-), 女,博士,副教授,研究方向:数据挖掘,图像处理,粒度计算和机器学习,E-mail:zhuhongwin@126.com。

丁世飞(1963-), 男,教授,博士生导师,研究方向:人工智能,智能信息处理,模式识别,机器学习和数据挖掘,E-mail:dingshifei@sina.com。
Entropy Weighting AP Algorithm for Subspace Clustering Based on Asynchronous Granulation of Attributes and Samples
Zhu Hong1, Ding Shifei2
(1.School of Medical Information, Xuzhou Medical University, Xuzhou, 221005, China; 2.School of Computer Science and Technology, China University of Mining and Technology, Xuzhou, 221116, China)
Affinity propagation (AP) clustering algorithm considers all clustering objects as potential clustering centers, and messages of responsibility and availability are exchanged between objects until a high-quality set of clustering centers and corresponding clusters gradually emerge. But it is not appropriate for subspace clustering. To solve this problem, an entropy weighting AP algorithm for subspace clustering based on asynchronous granulation of attributes and samples (EWAP) is put forward through introducing the idea of granular computing into the affinity propagation clustering method. It removes the redundant attributes first, and then a step of modifying attribute weights is added to the clustering procedure for obtaining the exact weights value. At the end of iteration, the attribute weights of each subspace, an accurate result of attributes granularity and the corresponding clusters will be produced. The theory and practice prove that EWAP preserves the advantages of AP clustering and overcomes its shortage of unsatisfying subspace clustering.
clustering; entropy; weighting; subspace; AP clustering
国家自然科学基金(61379101)资助项目;江苏省自然科学基金(BK20130209)资助项目;江苏省高校自然科学基金(14KJB520039)资助项目;江苏省高校优秀中青年教师和校长境外研修计划资助项目。
2015-06-05;
2015-06-30
TP181
A
