一种利用局部结构信息的加权哈希图像检索算法
2016-12-22张胜杰查宇飞李运强李寰宇杨源
张胜杰,查宇飞,李运强,李寰宇,杨源
(1.空军工程大学航空航天工程学院,710038,西安;2.空军工程大学空管领航学院,710051,西安)
一种利用局部结构信息的加权哈希图像检索算法
张胜杰1,查宇飞1,李运强1,李寰宇2,杨源2
(1.空军工程大学航空航天工程学院,710038,西安;2.空军工程大学空管领航学院,710051,西安)
针对图像检索领域中现有哈希算法仅考虑数据的全局信息,同时平等地对待每一维投影数据,导致得到的哈希码不能很好地保持原始数据的相似性的问题,提出利用图像数据局部结构信息的加权哈希(WLSH)算法。该算法同时考虑原始图像空间的局部结构信息和投影数据的各维方差,首先利用数据之间的相似性构建关系矩阵,进而获得原始图像数据的局部结构信息;然后通过迭代量化的方法寻找最优的正交旋转矩阵,使得投影以后的量化误差最小;最后通过权重矩阵平衡各维方差,保证每一维的单位编码信息相同,从而实现对原始数据最优的保距映射。在图像库上的实验结果表明,WLSH算法应用于图像检索时在查准率和查全率上比主成分分析-迭代量化方法分别提高了3%和2%。
投影函数;局部结构信息;迭代量化;平衡各维方差;图像检索
目前,最近邻搜索已经被广泛地应用于数据压缩、模式识别、文档检索等领域。进入大数据时代,如何快速地进行图像检索成为亟待解决的问题。哈希学习[1]通过学到数据的二进制哈希码表示,使得哈希码尽可能地保持原空间中的近邻关系,节省了存储空间,提高了查询速度,在大数据的最近邻搜索中被广泛应用。
数据独立哈希算法包括局部敏感哈希(locality sensitive Hashing,LSH)算法[2]以及它的拓展算法[3-4],通过随机生成一个投影矩阵作为哈希函数,使得相似的样本以较高的概率映射到同一个哈希桶中,但这些算法需要较长的哈希码才能取得理想的精度。数据依赖哈希算法[5-8]从原始数据中学习出哈希函数,只需较短的哈希码就能取得理想的精度。谱哈希(spectral Hashing, SH)算法[5]将编码过程视为图分割过程,对高维数据进行谱分析,通过放松约束条件将问题转化成拉普拉斯特征图的降维问题从而求得哈希函数。数据依赖的多索引哈希算法[6]采用自适应投影的方法使得哈希表中的元素下标接近于均匀分布,进而提升查询速度。线性嵌入哈希算法[7]利用相关性预测函数保持高维数据与其编码之间的邻近关系,构建线性哈希映射矩阵,获得紧致的哈希编码,提高了图像与编码间的相关性,实现了高精度的图像检索。基于哈希的目录索引算法[8]将Hash表与B+树结合从而高效地索引目录的子索引节点。另外,主成分分析哈希(principal component analysis hashing,PCAH)算法[9]通过主成分分析(PCA)学得投影矩阵。投影之后的各维度方差各不相同,但其将每一维度编码成相同的码长,从而降低了检索性能。迭代量化(iterative quantization,ITQ)哈希算法通过学习一个最优的正交旋转矩阵平衡各维方差,进而减小量化误差,但其不能保证平衡之后的各维方差完全相等。监督哈希算法[10-11]利用数据的类标信息可以取得很好的检索性能,但是类标信息有限且很难获得。半监督哈希算法[12]利用少量的标注样本和大量的未标注样本学习得到哈希函数。非监督哈希算法[9,13]不需要数据的类标信息,但存在诸多限制条件而使性能受到一定影响。
以上传统的哈希算法均存在2点不足:一是仅考虑数据的全局信息;二是平等地对待每一维的投影数据,导致得到的哈希码不能很好地保持原始数据的相似性。针对这2点问题,本文同时考虑原空间的局部结构信息和投影数据的各维方差,提出了加权局部结构哈希(WLSH)算法。该算法首先利用数据之间的相似性构建关系矩阵,挖掘原始数据的局部结构信息,继而创建局部结构变换矩阵,对原始样本数据进行线性变换得到一种局部结构数据。然后,将该数据作为训练样本进行主成分分析得到投影函数,通过迭代量化寻找最优的正交旋转矩阵,使得量化误差最小;最后通过权重矩阵平衡各维方差,保证每一维的单位编码信息相同,从而实现对原始数据最优的保距映射。
1 加权局部结构哈希
选取n个样本构成样本集合X={x1,x2,…,xn},xi∈Rm,m为样本的维度。学习哈希函数的目的就是为了得到哈希码,即h:X→Y∈{1,-1}n×k,哈希函数表示为h(xi)=sgn[f(xi)],f(xi)为投影函数,Y为哈希码矩阵形式,k为哈希函数的个数,sgn(·)表示符号函数。
1.1 局部结构数据
为了保持原始数据空间与汉明空间数据结构的一致性,谱哈希(SH)算法[5]挖掘数据内部的谱性质,通过约束经哈希映射后的二进制编码中某一位(bit)结果为-1或1的概率相等以及二进制哈希码的每一位不相关,从而建立目标函数如下
(1)


(2)
式中:N(x,s)表示样本x在U中最近的s个锚点,本文设置s=5。
通过相似矩阵Z,可以计算对称关系矩阵A=ZZT,进而可求得A的标准化形式
(3)
式中:Q=D-1/2Z∈Rn×d。这里,定义Q为局部结构变换矩阵,该矩阵是由锚点图相似矩阵z(x)变换得到,包含了丰富的局部结构信息。下面将引出由该矩阵变换所得的局部结构数据。

(4)

(5)

主成分分析是一种非常经典有效的降维算法,虽然在变换过程中存在一定程度上的信息损失,但其绝大部分能量能被保留在前k个最大的特征值对应的维度上。哈希算法目的是通过尽可能少的维度去保留尽可能多的能量,从而实现快速图像检索,虽然PCA变换存在一定程度的信息丢失,但并不影响对图像进行快速检索。

图1 局部结构特征提取和变换示意图
图1是局部结构特征提出和变换示意图。图1表示对原始数据X进行局部结构特征提取得到对称关系矩阵A,然后由学习得到的局部结构变换矩阵Q对原始数据进行线性组合得到局部结构数据。
1.2 迭代量化方法
迭代量化方法[9]通过旋转主成分方向使得各主成分方向的方差尽量保持平衡。随机生成两组满足高斯分布的数据集,并将这两组数据集分别进行无旋转、随机旋转、最优旋转的操作,最终得到如图2所示的可以形象表达迭代量化方法的示意图。图中点代表训练样本,线代表主成分方向。当对这些训练样本进行二值量化,由图2a可知,同一类样本被不同的哈希编码序列表示了出来,即相似的样本落在了不同的哈希桶中。图2b对主成分方向进行了一次随机旋转,使得同一类样本尽能多地落在相同的哈希桶中。图2c是通过迭代量化方法得到的投影向量及哈希码编码序列,可以看出,相似的训练样本落在了相同的哈希桶中。
为了寻找到最优的正交旋转矩阵R,目标函数可表示为

(6)
式中:V=XH*表示训练样本经主成分分析后的投影数据;H*为投影函数;Y代表哈希码矩阵;‖·‖F表示F范数。
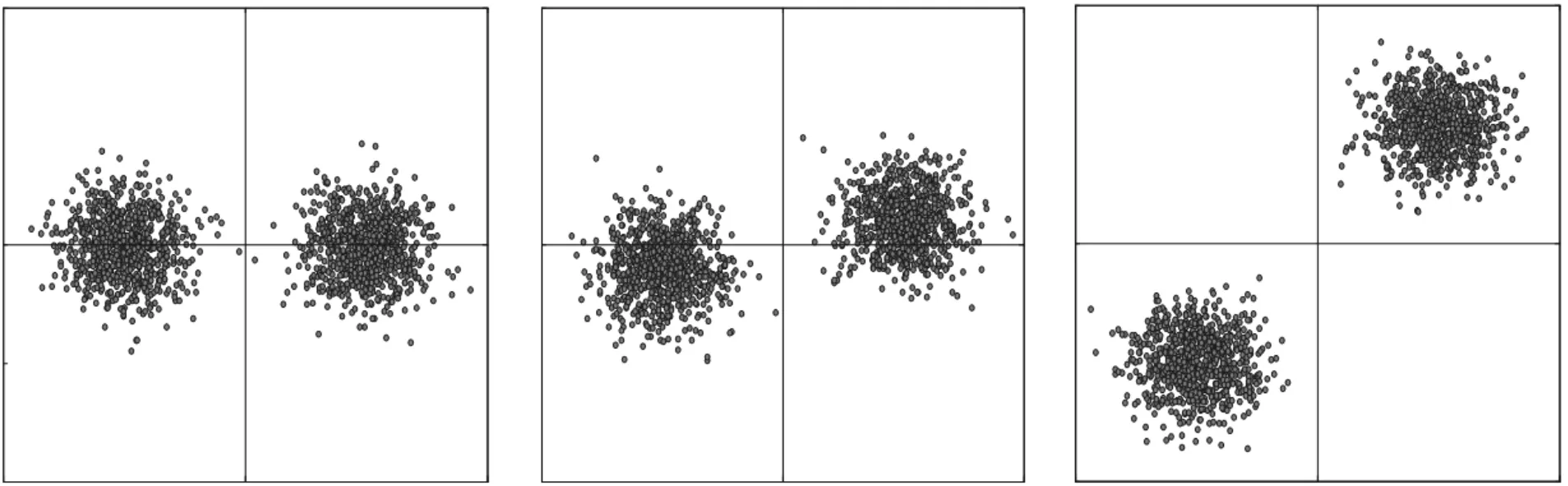
(a)无旋转 (b)随机旋转 (c)最优旋转图2 迭代量化方法示意图
1.3 加权平衡方法
迭代量化方法[9]通过不断迭代降低量化误差,从而使得每维方差趋于相等,然而,这种方式并不能获得相等的方差。本文采用CIFAR-10数据库[16]分别在随机正交旋转(PCA-RR)、10次和50次迭代3种情况下对投影数据进行单位化方差与投影数据的比特数关系实验,结果如图3所示。

图3 3种情况下单位化方差与投影数据比特数的关系
同样,经过迭代量化后同样满足方差大小与信息量大小的一致性。在哈希码编码序列上,方差越大的维包含的信息量越大,则需分配的权重值也应更大,因此可以求得每一位哈希码对应的权值为
(7)
2 模型构建及其优化
2.1 模型构建

(8)
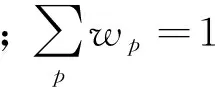
2.2 模型优化
这一小节将对模型进行优化。为了解决上述问题,运用固定一个变量,求解另一变量的方式对模型进行优化求解。
2.2.1 固定W计算H对每一维哈希码的权重进行初始化,将各维权重设为等值,并且约束权重之和等于1,则初始化权重矩阵表示为W=k-1E,其中k是哈希码的长度,E是单位矩阵。将初始化权重矩阵代入式(8),则目标函数变为
s.t.HTH=I
(9)
然后,应用投影函数H*,得到投影数据V=XH*,选择符号函数sgn()作为编码函数,即可求得哈希码Y=sgn(XH*)。
然而,主成分分析得到的投影数据各主成分方向的方差(或信息量)通常各不相等,迭代量化算法通过旋转主成分方向使得旋转后各方向的方差尽量保持平衡。该方法的目标是通过寻求最优正交矩阵R,最小化量化误差

s.t.RTR=I
(10)
采用迭代量化方法去逼近量化误差最小值,其交替进行的步骤如下。
(1)初始化R为随机正交矩阵。
(2)固定R,更新Y=sgn(XH*R)。
(3)固定Y,更新R。目标函数变为
(11)

(4)当量化误差足够小时,所得到的正交矩阵R和哈希码Y即为所求,实验表明当迭代次数在40~60时,算法趋于平稳,本文选择迭代50次。最终可以求得最优正交旋转矩阵R及H=H*R。
2.2.2 固定H求解W在上一小节中,固定W,通过优化目标函数式(8),解得了投影函数H。图3表明,迭代量化方法求得的方差并不完全相等,还存在差异性,为了进一步平衡各维方差差异,提出了加权平衡的方法。本小节将利用已经求得的投影函数H,求解每位哈希码上分配的权重W。首先,求解每位哈希码的方差vt=var(yt);然后结合公式(7),即可求得权值
(12)
总结WLSH算法流程如下。
输入 原始样本数据X={x1,x2,…,xn},xi∈Rm,哈希码维度k,迭代次数t,构建锚点图的参数[14]。
初始化W=k-1E。
(2)运用局部结构数据,计算投影函数
(3)fori=1:t;
(4) 固定R,更新Y
Y=sgn(XH);
(5) 固定Y,更新R
(6) end for;
(7)用式(12)计算权重矩阵W。
输出 投影函数H=H*R,权重矩阵W。
2.3 时间复杂度分析
分别对本文算法的训练和测试时间复杂度进行分析。
对于任意一个测试样本,生成哈希码的测试时间复杂度为O(mk),相对于一些非线性哈希算法如SH和KLSH,测试时间复杂度有所降低。虽然本文算法的训练时间相对于一些算法有所增加,但是测试时间很快,能够满足现实需要。
3 实验结果及分析
3.1 数据集与实验设置
实验选用2个比较常用的数据库CIFAR-10[16]和MNIST[12]来验证本文算法的有效性。
CIFAR-10含有60 000个样本,每个样本维度为320,该数据库包含飞机、汽车、鸟、猫、鹿、狗、青蛙、马、轮船和卡车10个分类,每类数据集有6 000个样本。MNIST是数字手写识别数据库,该数据库中包含70 000个维度为784的数据样本。本文随机选取5 000个样本作为训练集和1 000个样本作为测试集。数据库具体信息如表1。
所有实验均在3.06 GHz、6 GB内存的64 bit计算机环境下通过MATLAB 2013a软件平台仿真实现。

表1 2种数据库的具体信息
3.2 对比算法及评价标准

3.3 实验结果分析
图4为在数据库CIFAR-10和MNIST上,返回500幅检索图像时加权平衡算法WPCAH、WPCA-RR、WPCA-ITQ和基准算法PCAH、PCA-RR、PCA-ITQ的查准率随比特数变化的关系。由图4可以看出,对基准算法PCAH进行加权平衡,效果提升显著,而对迭代量化算法(ITQ)进行加权平衡效果提升不太明显,因为迭代量化过程也有平衡方差的作用。

(a)CIFAR-10数据库

(b)MNIST数据库图4 2个数据库上6种对比算法的查准率与比特数关系
图5显示了本文算法和比较算法在数据库CIFAR-10上哈希码分别为16、32、64和128 bit时的检索效果。由图5可以看出:本文算法在哈希码为16、64和128 bit时,查准率明显高于其他哈希算法;在32 bit时,其他算法有逼近本文算法的趋势。
图6表示在数据库MNIST上,哈希码为64和128 bit时查准率和查全率随检索样本数的关系。在数据库MNIST上,由于SKLSH算法的不具有可比性,因此未选用该算法作为对比算法。由图6可以看出,本文算法在64 bit和128 bit时查准率和查全率都明显高于其他哈希算法。

(a)16 bit (b)32 bit

(c)64 bit (d)128 bit图5 数据库CIFAR-10上5种算法在不同比特数下的 查准率与返回检索样本数的关系

(a)64 bit (b)128 bit
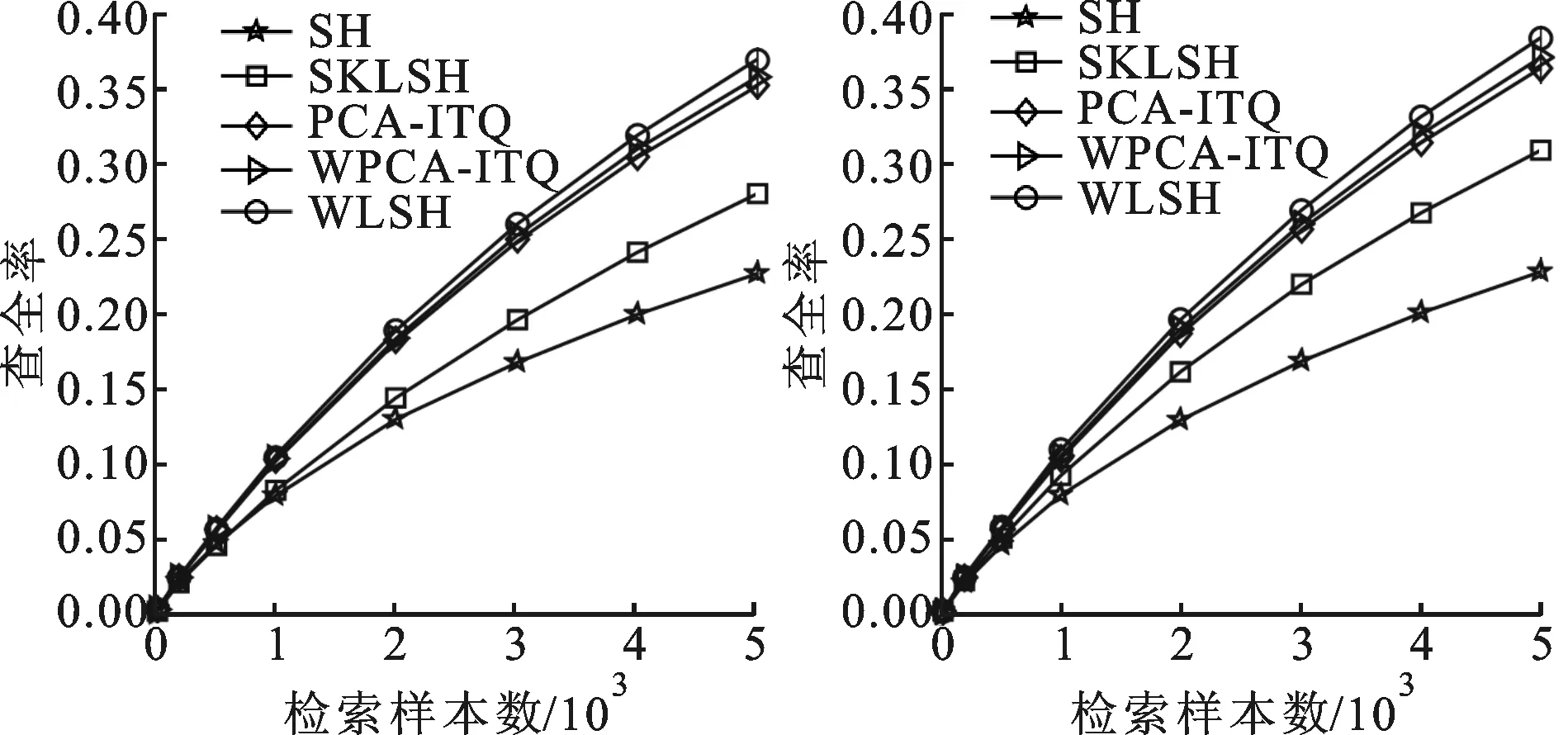
(c)64 bit (d)128 bit图6 数据库MNIST上5种算法在不同比特数下的 查准率和查全率与返回检索样本数的关系
图7表示了在图像库CIFAR-10和MNIST上,当返回500幅检索图像时的查准率随比特数变化的关系。图7同样反映了图5和图6的问题:当哈希码在32 bit时,其他算法有逼近本文算法的趋势;在32 bit之后,查准率随着比特数增加呈不断上升趋势。

(a)CIFAR-10数据库

(b)MNIST数据库图7 2种数据库上8种对比算法的查准率与比特数关系
4 结 论
本文提出了一种加权局部结构哈希算法——WLSH,相比于以往哈希算法,该算法同时考虑了原空间的局部结构信息和投影数据的各维方差大小,最大程度的减少了信息损失。在2个大的数据库上进行图像检索,实验结果表明,该算法在所有比特数上的查准率和查全率都高于其他相关算法。
但是,该方法在取得优异性能的同时也存在着一定的问题和不足,主要体现在两个方面:一是算法中参数过多,在一定程度上增加了算法的复杂性,降低了实时性;二是对数据进行主成分分析过程本身会造成一定的信息损失。这些问题都有待通过进一步的研究来解决和完善。
[1] 李武军, 周志华. 大数据哈希学习: 现状与趋势 [J]. 科学通报, 2015, 60(5/6): 485-490. LI Wujun, ZHOU Zhihua. Learning to Hash for big data: current status and future trends [J]. Chin Sci Bull, 2015, 60(5/6): 485-490.
[2] GIONIS A, INDYK P, MOTWANI R. Similarity search in high dimensions via Hashing [C]∥International Conference on Very Large Data Bases. New York, USA: ACM, 2000: 518-529.
[3] KULIS B, JAIN P, GRAUMAN K. Fast similarity search for learned metrics [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12): 2143-2157.
[4] 赵永威, 李弼程, 彭天强, 等. 一种基于随机化视觉词典组和查询扩展的目标检索方法 [J]. 电子与信息学报, 2012, 34(5): 1154-1161. ZHAO Yongwei, LI Bicheng, PENG Tianqiang, et al. An object retrieval method based on randomized visual dictionaries and query expansion [J]. Journal of Electronics & Information Technology, 2012, 34(5): 1154-1161.
[5] WEISS Y, TORRALBA A, FERGUS R. Spectral hashing [C]∥ Proceedings of the 22nd Annual Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT, 2008: 1753-1760.
[6] 马艳萍, 姬光荣, 邹海林, 等. 数据依赖的多索引哈希算法 [J]. 西安电子科技大学学报, 2015, 42(4): 159-164. MA Yanping, JI Guangrong, ZOU Hailin, et al. Data-oriented multi-index Hashing [J]. Journal of Xidian University, 2015, 42(4): 159-164.
[7] 王秀美, 丁利杰, 高新波. 一种相似度保持的线性嵌入哈希方法 [J]. 西安电子科技大学学报, 2016, 43(1): 94-98. WANG Xiumei, DING Lijie, GAO Xinbo. Linear embedding Hashing method in preserving similarity [J]. Journal of Xidian University, 2016, 43(1): 94-98.
[8] 刘贤焯, 王劲林, 朱明, 等. Hash表与B+树相结合的高效目录索引结构 [J]. 西安交通大学学报, 2013, 47(4): 105-111. LIU Xianzhuo, WANG Jinlin, ZHU Ming, et al. Effective directory index framework taking advantages of Hash table and B+tree [J]. Journal of Xi’an Jiaotong University, 2013, 47(4): 105-111.
[9] GONG Y C, LAZEBNIK S. Iterative quantization: a procrustean approach to learning binary codes for large scale image retrieval [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2916-2929.
[10]LIN G S, SHEN C H, SHI Q F, et al. Fast supervised Hashing with decision trees for high-dimensional data [C]∥ Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE Computer Society, 2014: 1971-1978.
[11]WANG Q F, SHEN B, WANG S M, et al. Binary codes embedding for fast image tagging with incomplete labels [C]∥ 13th European Conference on Computer Vision. Berlin, Germany: Springer-Verlag, 2014: 425-439.
[12]WANG J, KUMAR S, CHANG S F. Semi-supervised Hashing for scalable image retrieval [C]∥ IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 3424-3431.
[13]XIA Y, HE K M, KOHLI P, et al. Sparse projections for high-dimensional binary codes [C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 3332-3339.
[14]LIU W, WANG J, KUMAR S, et al. Hashing with graphs [C]∥Proceedings of the 28th International Conference on Machine Learning. New York, USA: Association for Computing Machinery, 2011: 1-8.
[15]SCHONEMANN P. A generalized solution of the orthogonal Procrustes problem [J]. Psychometrika, 1966, 31(1): 1-10.
[16]LENG Cong, CHENG Jian, YUAN Ting, et al. Learning binary codes with Bagging PCA [C]∥Proceedings of European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases. Berlin, Germany: Springer Verlag, 2014: 177-192.
[17]LIU X L, HE J F, DENG C, et al. Collaborative Hashing [C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE Computer Society, 2014: 2147-2154.
[18]RAGINSKY M, LAZEBNIK S. Locality-sensitive binary codes from shift-invariant kernels [C]∥23rd Annual Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2009: 1509-1517.
[19]JEGOU H, DOUZE M, SCHMID C, et al. Aggregating local descriptors into a compact image representation [C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE Computer Society, 2010: 3304-3311.
(编辑 刘杨)
A Weighted Hashing Algorithm Based on Local Structured Information for Image Retrieval
ZHANG Shengjie1,ZHA Yufei1,LI Yunqiang1,LI Huanyu2,YANG Yuan2
(1. School of Aeronautics and Astronautics Engineering, Air Force Engineering University, Xi’an 710038, China;2. School of Air Control and Navigation, Air Force Engineering University, Xi’an 710051, China)
A weighted local structured Hashing (WLSH) method is proposed to address the problem in the field of image retrieval that most existing Hashing methods only consider the global information and treat each projected dimension equivalently, which leads to a problem that the binary codes cannot efficiently preserve the data similarity. The proposed method considers local structure information of original image data and the variance of each projected dimension simultaneously. An affinity weight matrix is built to describe the relationship between data points and to acquire local structure information of the original image data. Then, an iterative quantization is used to find an optimal orthogonal transformation matrix and to minimize the quantization error. Finally, a weighted matrix is used to balance the variances and to guarantee equivalent information of each Hashing bits, thus the data similarity is effectively preserve. Experimental results based on some large scale datasets show that the precision and recall of the WLSH algorithm are improved by 3% and 2% over principal component analysis-iterative quantization, respectively.
projection functions; local structure information; iterative quantization; balance the variance; image retrieval
2016-01-18。
张胜杰(1994—),男,硕士生;査宇飞(通信作者),男,副教授,硕士生导师。
国家自然科学基金资助项目(61472442);陕西省青年科技新星计划资助项目(2015KJXX-46)。
时间:2016-07-23
http:∥www.cnki.net/kcms/detail/61.1069.T.20160723.1817.002.html
10.7652/xjtuxb201610012
TP391
A
0253-987X(2016)10-0078-08
