基于核算法的局部线性重构
2016-12-16扬州大学广陵学院崔娟娟
扬州大学广陵学院 崔娟娟
基于核算法的局部线性重构
扬州大学广陵学院 崔娟娟
对于模式识别和机器学习领域,图像的特征抽取是最基本的问题之一,而核主成分分析是其中一种经典算法。但是,核方法都存在一个问题,当训练样本数非常多的时候计算代价很大,导致识别效率低下。针对这一问题,本文提出一种基于核算法的局部线性重构,其主要思想就是从大量的训练样本中选出一部分最具有代表性的样本代替大量的训练样本,利用代表样本构造核空间,将所有样本非线性投影到核空间中,使得样本线性可分。后续的实验证明了本算法的有效性。
主成分分析;特征抽取;分类
1.引言
众所周知,抽取最有效的图像是模式识别的首要任务,运用抽取到的特征将原始数据映射到某一低维空间后,能得到最反映数据本质的特征,其中最经典是主成分分析(Principal Component Analysis,PCA)和Fisher线性鉴别分析,但是这两种方法只能保证抽取出来的各个分量之间不相关却不能保证这些分量之间互相独立,因此基于核的非线性特征抽取就变得更加合理。核方法的基本思想就是通过将实际问题通过非线性转换到高维甚至是无穷维特征空间,使其在核空间中线性可分或者是近似可分。但是这些基于核的非线性特征抽取基本上都存在两类问题:(1)核参数以及核函数的选择问题;(2)计算代价太大,处理效率低下。
本文提出一种基于局部线性重构的核主成分分析算法,通过从大量的训练样本中选取一部分具有代表性的样本,利用这些样本构造核空间,然后将所有样本非线性投影到核空间中,使得样本线性可分。选取样本点的算法是参考Cai[1]的局部线性重构投影的思想,因为每组样本集肯定存在空间的流行结构,而每个样本点又能被其近邻重构,通过这种思想选取出的样本点不仅具有很高的代表性有保持了样本之间的流行结构,这样构造出的算法大量减少了计算机的计算代价。
2.基于局部线性重构的核主成分分析
2.1选取最有代表性的样本子集
本节主要介绍利用局部线性重构的思想从大量的训练样本空间选取部分具有代表性的样本。由于在高维空间均匀采集的数据样本存在低维的流行结构,而每个样本点又能被其近邻重构,那么肯定存在一组最具有代表性的自己能够线性重构所有的训练样本集。

式中µ为系数常量,公式中等号右边第一项要求最优子集对自身的重构,第二项要求子集对训练样本集的重构,要求重构误差最小。



在进行样本重构时要求重构误差最小,那么重构误差可以重新定义为:
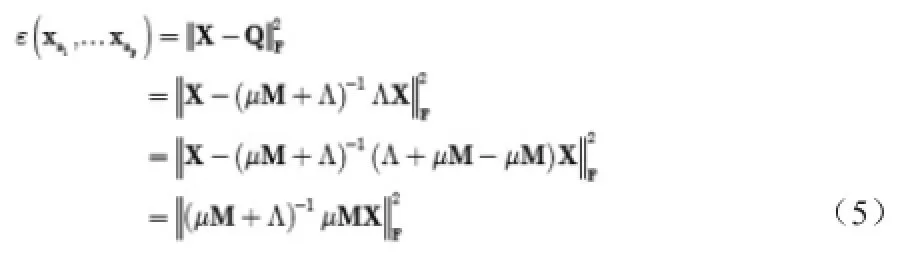
假设最优样本子集包含p个样本,那么目标函数可以重新定义为:
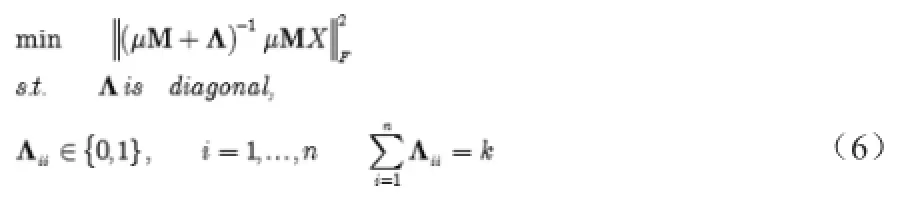
由于线性局部重构的组合性质,直接优化是很难实现的,本文引入贪婪算法机制来解决式6的优化问题。相关优化算法详见参考文献1。
2.2本文算法
由定义1可以看出,当训练样本量非常大时,假设n>5000,将所有的训练样本全部投影到核空间计算量非常庞大,所涉及的计算量复杂度是O(n3),因此通过选取代表性的点可以减少大量的计算。
这样就得到一个近似的特征空间:

那么判别式就可以重新定义为:


3.Yale库上的实验结果及分析
本节我们将会在两个不同的人脸库上验证本节算法。关于的参数µ,一般选取0.1,这对实验结果的影响不大,但是值为0.1时算法的性能最好。在支持向量机中常用的核函数有高斯核函数,多项式核函数,其中σ、c和d都是常数,本实验中我们只选用高斯核。
Yale人脸图像数据库共有165幅图像,包含15个人,每人有11幅图像,分别在不同表情、姿态和光照条件下拍摄,每张图的分辨率为100×80。图1为该人脸库中某人的11幅图像。

图1 Yale数据库中某人的26幅人脸图像
在实验中,每个人选取5个随机样本作为训练样本,也就是说训练样本总数为75人,剩余的样本都用来测试,共90张测试样本。投影轴数从1选到40依次增加,步长为2。代表性样本数从15到65,步长为10。最小距离分类器将被用于分类。
这里定义选择的代表性样本数为k,投影到核空间后的样本维数为k×k。本次试验我们分别对比了naïve KPCA,ESKPC和ALSKPCA三个算法在同等条件下的最高识别率。从图3可以看出随着k值的增加,两种算法的识别率也在不断升高,当k为45时,也就是说取45个样本时本算法已经开始收敛,而ESKPC则到55时才收敛,本算法收敛速度较快,效率较高。图2显示,在k=45的情况下,本算法的识别率也有明显优势,这是因为本算法在选取最优样本时加入了流形信息,选择的样本更合理,可以张成的空间范围更大。另外图4显示ESKPC的运算时间随着k的增大而不断增大,趋势非常明显,而本文算法在一定的范围内选择样本的速度更快,而且受到的影响也极小,基本没有变化。

图2 不同的投影轴数与识别率的关系图

图3 一次重构的识别率对比图

图4 选取不同的近邻数的识别率比较
[1]Active Learning Based on Locally Linear Reconstruction. Lijun Zhang, Chun Chen, Jiajun Bu, Deng Cai, Xiaofei He, Thomas S. Huang IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 10, pp. 2026-2038, 2011.
[2]S.T. Roweis and L.K. Saul, “Nonlinear Dimensionality Reduction by Locally Linear Embedding,” Science, vol. 290, no. 5500, pp. 2323-2326, Dec. 2000.
